业界首个动态模型亲和的“AI实时编译器”—MindSpore DVM,强力推荐
业界首个动态模型亲和的“AI实时编译器”—MindSpore DVM,强力推荐
动态张量计算已成为 AI 模型(尤其是大语言模型)的常态:输入序列长度、batch size、控制流路径均在运行时才可确定。传统 AI 编译器依赖离线 shape 推导与静态 kernel 生成,难以应对此类动态性;而运行时编译(JIT)虽能利用真实信息,但编译链路过长,对服务时延影响显著。
为解决这一矛盾,我们与港科广陈雷老师团队、湖南大学赵捷老师团队合作,提出最新成果:《DVM:A Bytecode Virtual Machine Approach for Dynamic Tensor Computation》。

本文以动态张量计算为场景,提出一种基于字节码虚拟机的实时编译方案 DVM——在保留运行时信息优势的前提下,让动态模型编译足够轻、足够快、甚至可隐藏在计算过程中。
01 动态模型为什么难编译
以大语言模型为例,输入序列长度通常在运行时方可确定,单个算子的 shape 可能呈现成千上万种组合。若为每种 shape 单独编译 kernel,编译时间与设备内存开销将不可接受;若采用 bucketing(将不同 shape 填充至若干固定尺寸桶中),则会引入冗余计算;若使用 micro‑kernel,则仍需应对搜索空间爆炸、shape 范围未知及融合算子组合增长等问题。
更为棘手的是算子融合。大量优化机会仅存在于运行时:例如,两个张量表达式在符号层面无法判定是否可融合,但实际运行时 shape 恰好相等,此时本可减少一次全局内存访问;又如动态图中的分支、循环及数据依赖决定真实执行路径。传统编译器为保障正确性,往往采取保守策略,或在遭遇新路径时触发重新编译。
其根本矛盾在于:动态模型极度依赖运行时信息,而传统运行时编译(JIT)的代价过高。
02 DVM 的核心思路:
不生成机器码,生成字节码
重新审视“运行时编译”这件事,问题其实不在于“运行时”本身,而在于传统编译链路太长——生成机器码、做大量图分析、benchmark 多个候选 kernel,对服务时延极不友好。
DVM 选择另一条路:将算子程序在 CPU 侧编码成字节码,然后在 Ascend NPU 侧由虚拟机解释成虚拟指令直接执行。
与传统 AI 编译器的本质区别:
传统 AI 编译器将“编译”理解为生成接近硬件的 kernel。无论是 ahead-of-time 还是 just-in-time 编译,最终产物均为机器码、设备 kernel 或厂商库调用。该模式适用于静态模型——其 shape、图结构、融合模式在编译前相对确定,编译器可投入较多时间进行全局优化。
动态模型的关键问题在于:大量信息在编译前不可知。
传统方法的三种应对策略及其局限:
1.为每种 shape 单独编译 kernel:运行效率较高,但遇到新 shape 时需重新编译,导致服务时延抖动,且 kernel 缓存膨胀。
2.dynamic shape kernel 或 bucketing:将一批 shape 合并处理,减少编译次数,但可能引入 padding 或保守代码,牺牲部分性能。
3.预置 micro‑kernel 或多版本 kernel:运行时动态选择,但依赖 shape 空间可控;一旦融合组合或维度数量复杂化,候选数量极易失控。
而 DVM 既不试图提前准备所有可能的 kernel,也不在运行时走完整的机器码生成流程。它在获取真实 shape 与真实执行路径后,仅执行一项轻量级操作:生成 tile 级别的字节码。设备侧不加载新 kernel,而是由已存在的虚拟机 kernel 解释执行这些字节码。
与传统 AI 编译器的五点差异:

简而言之,DVM 不是把传统编译器缩小一点,而是改变了问题的边界:传统 AI 编译器追求“提前生成足够好的 kernel”,DVM 追求“在真实运行时快速描述这次计算,并让硬件立即执行”。
DVM 的字节码不同于传统语言虚拟机中的标量级指令,而是 tile 级高层指令。其优势包括:
1.字节码更短,编码和解码成本更低。
2.tile 可以对齐 NPU 的 SIMD 和本地内存结构。
3.解释执行的开销可以和设备上的计算、访存流水重叠起来。
Ascend NPU 的 AI Core 包含 Scalar、Vector、Cube、DMA 等不同执行流。DVM 将字节码解码主要运行在 Scalar 单元,而向量计算、矩阵计算及数据搬运可并行推进。换言之,DVM 并非简单地“用解释执行换取性能”,而是将解释执行的开销隐藏在硬件流水线中。
03 DVM 的两大组件
状态机的另一个重要作用,是把上下文管理从 Agent 自己维护的内容里独立出来一部分。以下是三个和上下文管理相关设计。
3.1 运行时算子编译器
负责将单个算子(或一组融合后的算子)变成字节码程序,包括:
- shape tiling:根据本地内存大小、AI Core 数量、指令宽度等,将计算空间切成适合硬件执行的块;
- bytecode encoding:将每个 tile 的 load、compute、store 编码成字节码,交给设备侧虚拟机执行;
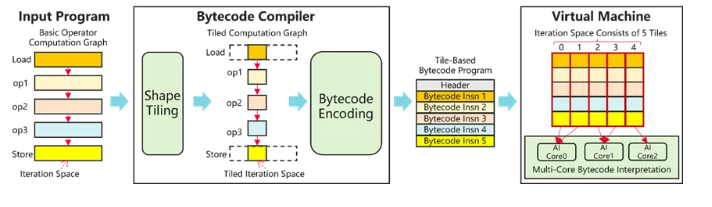
3.2 算子融合器
算子融合器则负责寻找融合机会。DVM 支持两类融合:
- pattern‑based fusion:如向量算子之间、矩阵算子后接 element‑wise 算子;
- stacking‑based fusion:多个 meta‑kernel 在时间或空间上堆叠调度,减少调度开销,提高 AI Core 利用率; 对于静态图,DVM 基于符号推导判断融合条件;对于动态图,采用 streaming fusion——在模型运行时根据真实 shape 和真实执行路径即时做融合决策。这使得很多在抽象图上不存在的优化机会,在真实执行时能被捕获。
04 实验结果
我们在算子、子图、模型三个层级评估 DVM。
- 算子层:动态矩阵乘法(matmul)。
- 子图层:LayerNorm、addmm,以及包含动态控制流的 if-else-add。
- 模型层:BERT、MMoE,以及 Qwen3‑14B 与 Llama3.1‑8B 的微调场景。
对比基线包括 PyTorch Eager、TorchInductor(recompile 模式与 dynamic 模式)及 MindSpore graph O0。DVM 基于 Ascend NPU 在 PyTorch 和 MindSpore 后端上的实现分别记为 PT‑DVM 与 MS‑DVM。
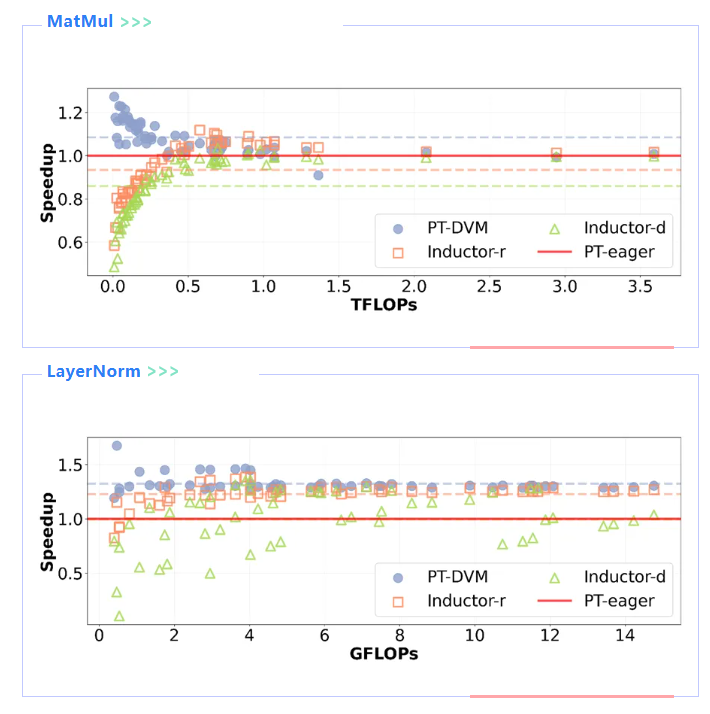
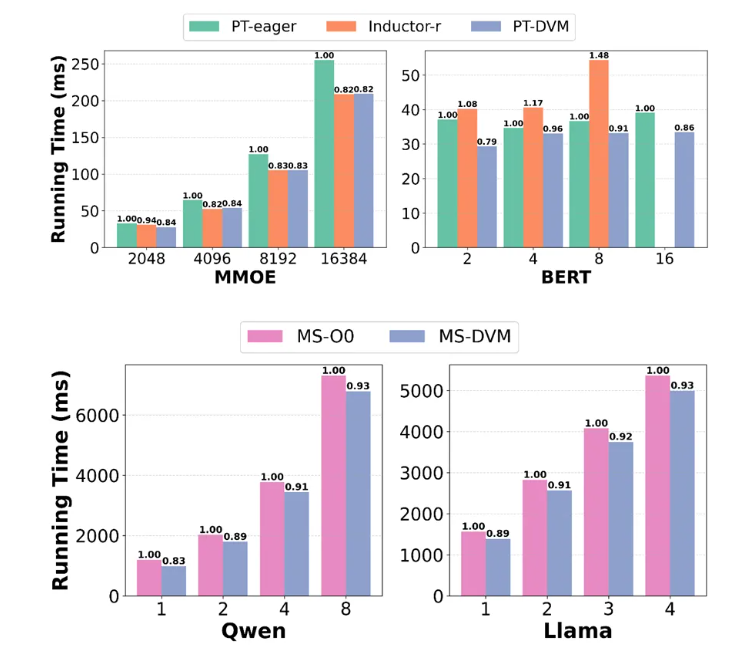
1、性能结果
DVM 在全部评估场景中均取得更优的运行效率。相比各基线,DVM 最高获得 11.77 倍性能提升。具体而言:
- 在 LayerNorm 上,PT‑DVM 相较 TorchInductor dynamic 的最大加速比为 11.77 倍。
- 在 addmm 上,得益于更灵活的融合策略,PT‑DVM 在 98% 的采样实例中优于所有基线。
- 在 Qwen3‑14B 与 Llama3.1‑8B 上,MS‑DVM 相较 MindSpore graph O0 取得 1.07 至 1.21 倍的提升。
文中基于状态机的 harness 设计,正是这一新范式下一种可调节且对 Agent 行为亲和的具体实现方式。
2、编译开销
DVM 的编译开销很轻。对于 matmul,PT‑DVM 单个算子实例的最大编译时间约为 0.11 ms,而 TorchInductor 的对应编译流程耗时可达数十至数百ms。对于 LayerNorm 与 if-else-add,TorchInductor 的编译时间可达数十秒级,DVM 的运行时编译时间则始终维持在很小比例。总体而言,DVM 的最大编译时间相比基线最高提速 5 个数量级。
上述结果表明,实时编译并非不适用于动态模型,关键在于能否提供一条足够轻的运行时编译路径。
05 为什么这件事值得关注?
动态模型优化长期处于两难:要么提前做大量编译和缓存,牺牲部署灵活性;要么运行时遇到新 shape 或新路径再编译,牺牲服务稳定性;要么放弃部分优化机会,牺牲硬件效率。
DVM 试图打破这个三角困境:
- 它不需提前枚举所有 shape;
- 也不需要缓存大量融合 kernel;
- 并把真实运行时信息变成优化输入,通过字节码虚拟机将编译成本压低;
目前 DVM 重点面向 Ascend NPU,但我们认为它最有价值的是一种新的编译器设计思路:对于动态 AI 计算,编译器不一定非要在运行前把一切都决定好。只要运行时编译足够轻,运行时反而可能是最好的优化时机。
06 开源与参与
DVM 的定位并非否定离线编译或传统 JIT 的价值。相反,过去的 AI 编译器系统已经证明了图优化、算子融合、kernel generation 的巨大价值。DVM 关注的是另一问题:当模型动态性持续增强,编译器如何继续获取上述优化收益?
我们的解决路径是:把编译链路拆轻,把执行方式贴近硬件,把 shape 和路径信息留到真正出现时再使用。
在动态模型日益成为主流的背景下,这一方向值得持续探索。DVM 已同时支持 MindSpore 与 PyTorch 后端,开源地址如下:
🔗 AtomGit 仓库:https://atomgit.com/mindspore/dvm
如果你也在处理动态 shape、动态控制流或动态融合的编译挑战,欢迎试用 DVM,参与 DVM 生态共建,并常来MindSpore开源社区交流。