MindSpore HyperParallel 携手 LlamaFactory 解锁 FSDP 性能与易用之钥
MindSpore HyperParallel 携手 LlamaFactory 解锁 FSDP 性能与易用之钥
大模型训练走到今天,大家面对的不只是“能不能训起来”,更是“能不能稳、能不能快、能不能跨平台复用”。
MindSpore HyperParallel 与 LlamaFactory 的深度联动,进一步扩展了 FSDP 后端能力——在不侵入用户代码的前提下,通过自定义通信融合与显存复用等核心技术,提升 Ascend NPU 上的训练效率,千亿参数量模型使能HyperParallel FSDP后性能较Megatron系列有约10%提升。同时,同一套脚本无需修改,即可在第三方硬件上顺利运行。
近日在KADC的AI框架分论坛上,LlamaFactory作者也受邀分享了题为《LlamaFactory × MindSpore HyperParallel:重构大模型训练效率新范式》的报告,深入解读这一联合方案的技术细节与实践经验。

01 痛点:大模型训练的“既要又要”
在大模型训练的竞技场上,开发者始终面临一个“既要又要”的难题:既要支撑千亿级参数带来的巨大显存压力,又要追求极致的训练吞吐。传统数据并行策略(如DDP、Zero等)本质上是显存效率与通信开销之间的权衡,这三者通过显存与通信之间的 trade-off,使开发者可在不同硬件拓扑与模型规模下选择最优训练配置。
其中完全分片数据并行(FSDP) 则是通过将模型参数、梯度及优化器状态在所有计算设备间全量分片,使单卡静态显存占用理论降至1/N,在高带宽集群环境下能最大化显存利用率并支撑千亿级超大规模模型的高效扩展;但如何在保持易用性的同时进一步提升效率、并实现跨硬件平台的统一,依然是一个亟待解决的工程挑战。
02 项目背景:当“万能工厂”遇见“并行专家”
LlamaFactory 已成为开源社区最受欢迎的微调框架之一,其“全流程、易上手”的特性深入人心。同时,随着模型规模向万亿迈进,LlamaFactory 也正在积极探索兼顾易用性与高效性的底层分布式并行方案。
HyperParallel 是一个声明式超节点亲和并行库,旨在彻底简化分布式训练编程。致力于在分布式并行领域开创“Triton 范式”,让高效并行如编写串行代码一样自然。它将并行策略描述与计算逻辑解耦,并融合了超节点感知调度与全局资源协同,在显著降低编程复杂度的同时,实现接近理论极限的并行效率,用户只需声明“做什么”,系统自动实现“怎么做”,真正达成极简易用、开箱即优。
面对亟待解决的工程挑战,HyperParallel 与 LlamaFactory 正式携手,双方深度联动增强 FSDP 能力,为开发者提供了一套高性能、跨后端且近乎“零门槛”的分布式训练方案。
03 HyperParallel 如何让 FSDP 更高效
HyperParallel 并非单纯的接口包装,其核心竞争力在于对昇腾亲和的大规模通信的深度优化。以 Qwen 等模型为例,启用 HyperParallel FSDP 后,性能提升超过 10%,同时显存占用相比业界原有 FSDP 方案普遍节省 5%~10%。
3.1 通信融合(Comm-Fusion)与“零”拷贝(Zero-Copy)
Comm-Fusion:HyperParallel 在 FSDP 中引入参数组级通信融合机制:先对参数分片形态与布局做可融合校验,再将同模块参数打包为统一通信单元,在反向阶段按“ReduceScatter→(HSDP下)AllReduce”两段流水执行,并与后续层反向计算重叠。相比逐参数触发集合通信,这种做法可明显降低小包通信启动频次与调度开销,减少跨层同步点数量,提升网络利用率与训练吞吐稳定性。对复制态小参数则保留旁路规约路径,兼顾兼容性与性能收益。
Zero-Copy:核心是Buffer复用:将各参数本地分片在初始化阶段映射到一块连续 Flat Buffer,并同步重绑 DTensor 本地视图,使后续 AllGather / ReduceScatter / AllReduce 等融合通信可直接基于连续内存读写,减少临时拼接与重复拷贝。
3.2 参数预取(Prefetch)——让通信与计算完全重叠
HyperParallel 优化:
- 正向预取:在计算第 I 层前向时,使用另一条流提前对第 I + 1 层的未分片参数执行 AllGather,使得第 I + 1 层的参数在其前向计算开始前已经聚合完成,从而在第 I 层计算期间隐藏第 I + 1 层的通信开销。
- 反向预取:在执行第 I 层的反向计算时,另一条流会对第 I ‑ 1 层的参数进行 AllGather,使得在当前层梯度计算完成后,下一层的参数已经准备好
HyperParallel 在 fully_shard API 中提供了两组接口,允许用户显式指定需要进行预取的模块列表:
- set_modules_to_forward_prefetch(self, modules) 接口接受一个 HSDPModule 实例的列表(tuple 或 list),将这些模块登记到内部的 hsdp_scheduler 中。调度器将在前向计算之前对这些模块的未分片参数执行 AllGather,确保第 I 层前向时第 I + 1 层参数已准备好。
- set_modules_to_backward_prefetch(self, modules)同样接受 HSDPModule 实例列表,调度器将在第 I 层的反向计算期间对对应模块的参数执行 AllGather。
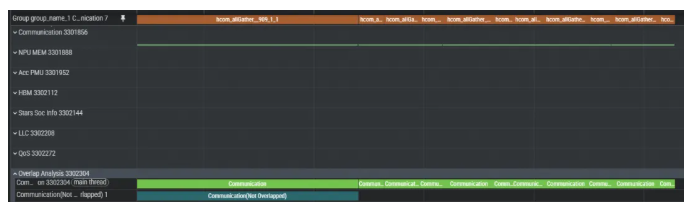
在对本层的参数做完AllGather通信后,将对后续层的参数分片的AllGather以异步的方式下发,达到参数聚合通信与正反向计算相掩盖的效果。
3.3 梯度通算掩盖
梯度规约掩盖(Gradient Reduce Overlap)指在反向传播过程中,梯度的 ReduceScatter 或 AllReduce 通信可以与当前层的反向计算相重叠。HyperParallel FSDP 默认在每个 HSDPModule 上开启此特性,无需额外配置;
内部调度器会在第I层的梯度计算完成后立即触发异步的ReduceScatter/AllReduce,并在第I-1层对第I层的通信句柄进行wait,及时释放完整梯度所占用的显存空间,提高整体训练效率。
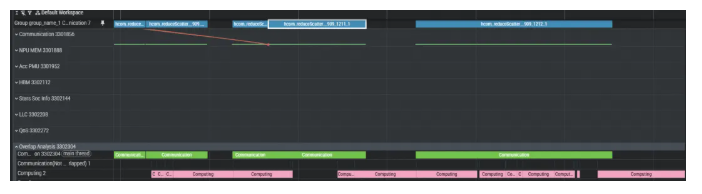
梯度作为计算图中的叶子节点,其通信规约与反向计算自然重叠,进一步缩短整体训练时间。
04 快速上手:一行配置,零侵入体验
当前HyperParallel的 FSDP2 后端已集成到 LlamaFactory,用户只需在原有工作流上添加一行配置即可启用,可参考 QuickStart(https://github.com/hiyouga/llamafactory-blog/blob/main/content/posts/mindspore-hyperparallel-quickstart.zh.md)
方法一:修改 YAML 配置文件
# examples/ascend/qwen3vlmoe_full_sft_fsdp2.yaml
# model
model_name_or_path: Qwen/Qwen3-VL-30B-A3B-Instruct
...
# method
stage: sft
do_train: true
finetuning_type: full
# HyperParallel
use_hyper_parallel: true
# dataset
...
方法二:启动命令追加
cd LlamaFactory
# 在命令行追加 --use_hyper_parallel True,无需修改 YAML
accelerate launch \
--config_file examples/accelerate/fsdp2_config.yaml \
src/train.py examples/ascend/qwen3vlmoe_full_sft_fsdp2.yaml \
--use_hyper_parallel=True
支持情况
- 训练阶段:支持SFT;
- 兼容Accelerate配置:Accelerate FSDP2 的配置兼容,如混合精度、显存优化等;
- 多硬件后端:重点优化昇腾Atlas A2、A3,基础功能支持第三方硬件。
05 社区协作与下阶段规划
在当前 FSDP2 后端接入的基础上,HyperParallel 与 LlamaFactory 的协作将于5月30日前聚焦多维混合并行能力扩展,以支持更大规模模型的高效训练,包括:
- Context Parallel (CP):沿序列维切分长上下文。
- Tensor Parallel (TP):对线性层做 colwise / rowwise 权重切分。
- Expert Parallel (EP):把 MoE 专家层分布到多卡。
- Activation Swap / Recompute:把激活换出到 CPU 或重算以省显存。
在上述能力推进的同时,我们将持续保证架构的易用性与可扩展性—依然通过配置文件或启动命令的方式启用 HyperParallel,并行与显存策略字段均遵循业界惯用法。
更完整的技术路线与时间规划,详见联合发布的 LlamaFactory X HyperParallel RoadMap。

06 欢迎加入 HyperParallel
我们诚挚邀请各位开发者、研究者加入 MindSpore HyperParallel 。无论是贡献代码、完善文档,还是提出改进建议,您的参与都将推动大模型分布式并行技术的边界。让我们一起,让大模型训练更简单、更快速、更智能!
