MindSpore绑核能力持续优化:让关键线程更稳,让大模型训练更快
MindSpore绑核能力持续优化:让关键线程更稳,让大模型训练更快
在大模型训练与推理持续演进的今天,性能优化的重点早已不只在 Device 侧。随着模型规模不断增大、执行链路愈发复杂,Host 侧逐渐成为影响整机效率的关键环节。
围绕 Host Bound 瓶颈,MindSpore 持续推进绑核能力演进:分布式进程级绑核 → 线程级精细化亲和 → 进程与线程协同隔离 → NUMA 级绑定 → 统一 JSON 配置;
且这套能力已在客户现场得到验证:
- 1024 卡线性度达到 99%
- 多组大规模配置线性度超过 97%
- 典型场景性能提升 10% ~ 18%
- 真实生产模型 4K 规模性能提升超过 20%
这意味着,MindSpore 绑核能力带来的不只是“更快”,更是“更稳”。

01 演进主线:从进程级到 NUMA 级的五个阶段
阶段1:分布式进程级绑核 —— 划定 CPU 资源边界
MindSpore 绑核能力的起点,是面向分布式场景的进程级绑核。
在多卡分布式训练中,多个训练进程会同时拉起。如果完全依赖操作系统自由调度,不同进程很容易落在重叠的 CPU 核心上运行,进而带来资源争抢、调度抖动和性能波动。
为此,MindSpore 首先提供了基于 msrun 的进程级绑核能力:
msrun --bind_core=True
这项能力的关键,不只是“支持绑核”,更在于它发生在分布式任务启动的最早阶段。
通常来说,绑核越早做越好。越早完成 CPU 亲和性设置,后续线程创建、调度继承和资源分布就越稳定。msrun 正处在分布式进程拉起的起点,在这一阶段完成绑核,相当于在任务启动之初就先划定了 CPU 资源边界。
这一步解决的是最基础的问题:先让每个分布式进程拥有相对稳定的 CPU 运行空间。
阶段2:线程级绑核 —— 从“给进程分 CPU”到“给关键线程保 CPU”
进程级绑核不够细,真正决定 Host 侧关键路径效率的是少数核心工作线程。它们直接影响编译、下发、数据处理等环节,能否持续稳定地向 Device 供给工作负载。若这些线程频繁迁移或与普通线程混跑,即使做了进程级绑核,系统仍会抖动。
因此,MindSpore 进一步演进出线程级绑核能力,通过 mindspore.runtime.set_cpu_affinity 对关键线程进行细粒度的CPU绑定; 覆盖的线程包括:
- main 主线程:编译和流程控制
- runtime 线程:静态图下发
- pynative 线程:动态图算子下发
- minddata 线程:数据处理
这一步的本质,是从“给进程分 CPU”,走向“给关键线程保 CPU”。
不是所有线程都需要最稳定的 CPU 环境,但关键线程一定需要。只有让这些线程尽可能少迁移、少受干扰,Host 侧关键路径才能真正稳下来。
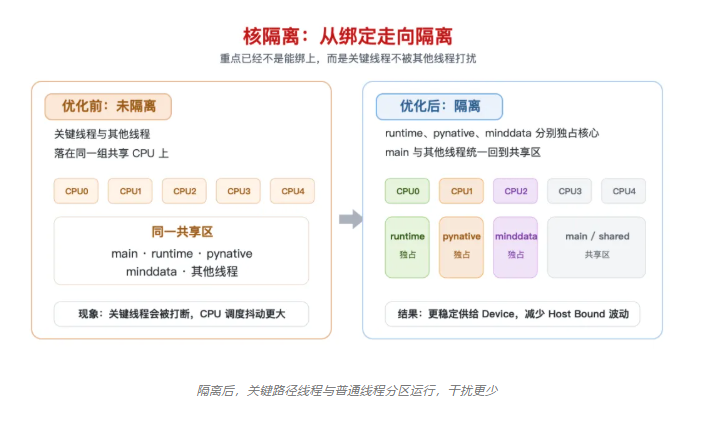
阶段3:从绑定走向隔离 —— 关键线程与普通线程分区运行
在线程级绑核基础上,MindSpore 进一步把资源管理思路从“绑定”推进到“隔离”。仅保证关键线程不迁移还不够,还需避免它们被其他线程抢占 CPU。
为此,MindSpore 进一步演进出进程级与线程级协同绑核能力,核心思路是:
先通过进程级绑核,为分布式进程划定 CPU 范围
再在进程内部识别关键工作线程
将runtime 等重要线程从主线程的混合执行环境中分离出来
为这些关键线程分配更独立、更干净的 CPU 核心
这背后遵循的是一个非常明确的原则:关键路径上的线程,应尽可能运行在低干扰核心上。关键线程运行在更独立的核心上时,Host 侧关键路径会更稳定,Device 侧因等待 Host 而产生的空闲也随之减少。
阶段4:NUMA 级绑定 —— CPU 与内存协同优化
在多路 CPU、NUMA 架构下,CPU 访问本地内存与远端内存成本不同。即使线程绑在合适的CPU核心,若频繁访问另一个 NUMA 节点上的内存,仍会有额外访存时延和带宽损耗,尤其在 HyperOffload 等场景中代价更大。
因此,MindSpore 的绑核能力继续扩展到了 NUMA 级别。它关注点不再只是“线程跑在哪个核上”,还包括“相关内存操作是否尽量在本地 NUMA 节点完成”。
这一步的意义,在于把 CPU 亲和优化扩展为 CPU 与内存协同优化,让MindSpore 在复杂服务器拓扑下,更系统地减少远端访存带来的额外损耗。
阶段5:统一 JSON 配置 —— 让复杂能力可落地
随着绑核能力从进程级演进到线程级、再到NUMA级,优化维度增加,配置复杂度也随之上升。若能力分散在命令行、接口和零散配置中,将难以被大规模使用。
因此,MindSpore 在能力增强的同时,也同步推进了易用性升级,通过 JSON 文件统一配置 CPU/NUMA 亲和关系,将原本相对分散的能力组织为更清晰、更可复用的工程化方案。
这种方式带来的价值非常直接:
- 配置入口统一,降低理解成本
- 表达能力更强,适合描述复杂线程与资源映射关系
- 便于纳入部署流程、环境复现和版本管理
MindSpore 在这一步解决的,是从“有没有高级绑核能力”到“能不能让用户顺畅、稳定地用到实际业务里”。
02 效果验证:客户现场的真实数据
绑核能力的价值,从来不只体现在某一个局部指标上,而是体现在大规模训练任务中的整体性能释放与稳定性提升。
场景1:万亿级 MoE 模型(客户现场 A)
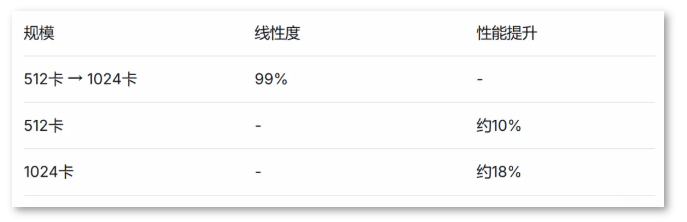
场景2:多组模型验证
- 256 卡 → 1024 卡,多组配置线性度均超过 97%
- 整体性能进一步提升 10% ~ 15%
- 性能抖动控制在 200ms 以内
对于大规模训练任务而言,这不仅意味着更高吞吐,也意味着更稳定的运行表现。
场景3:真实生产模型 4K 规模
- 性能提升 超过 20%
进一步体现出该能力在 Host Bound 明显场景下的实际价值。
场景4:另一客户现场 2K 规模
- 实施绑核后,性能收益 10% ~ 15%
这也说明,Host Bound 问题在不同规模集群中具有一定普遍性,而绑核正是缓解这一问题的有效手段之一。

整体来看,MindSpore 绑核能力已经不只是“让任务跑得更快”,而是在大规模训推场景下,帮助用户获得更高的扩展效率、更稳定的 Host 侧供给能力,以及更可控的整机性能表现。
03 结语
演进主线回顾
1、msrun --bind_core=True:在分布式进程拉起阶段尽早建立稳定 CPU 环境;
2、mindspore.runtime.set_cpu_affinity:为 Host 侧关键线程提供细粒度亲和控制;
3、进程级与线程级协同隔离:让关键线程运行在低干扰核心上;
4、NUMA 级绑定:保证 CPU 与内存访问的本地性;
5、JSON 统一配置:把复杂优化沉淀为可工程化、可复用的能力。
这不再是一堆零散功能的堆砌,而是一套面向Host Bound问题的系统化运行时优化能力。在 MindSpore 2.8 版本中,用户已支持灵活运用进程绑核、线程绑核、NUMA 本地内存等多层次亲和性设置。
自 2.9 版本起,将进一步支持通过 JSON 文件统一配置 CPU/NUMA 亲和关系,从分散配置迈向统一、可复用的工程化方案,让性能调优更系统、更便捷。欢迎共同期待即将到来的 2.9 版本,体验更高效的亲和性配置与更优的运行时性能。
核心价值
对于框架:形成面向 Host Bound 问题的系统化运行时优化能力;
对于用户:更稳定的 Host 侧、更少的 Device 空闲等待、更可控的整机性能释放。
04 互动与参考资料
如果你也被 Host 侧性能卡顿、CPU 调度混乱折腾过,不妨试试 MindSpore 的绑核能力~ 图片图片
想优化?跟着下面几步,几分钟就能配起来——
1️⃣ 查看 mindspore.runtime.set_cpu_affinity 接口说明,了解线程级绑核用法: https://www.mindspore.cn/docs/zh-CN/master/api_python/runtime/mindspore.runtime.set_cpu_affinity.html
2️⃣ 参考 JSON 统一配置指南,一键搞定 CPU/NUMA 亲和设置: https://www.mindspore.cn/tutorials/zh-CN/master/parallel/msrun_launcher.html#使用-json-统一配置-cpunuma-亲和--bind-numa-mindsporeruntimeset-cpu-affinity
🌐 欢迎加入昇思社区 :
https://discuss.mindspore.cn/ 与5.2万+开发者一起,让AI框架越来越好用。
也欢迎来评论区聊聊你的经验或困惑~