HyPerParallel-FSDP实战揭秘,一套接口使能双框架FSDP
HyPerParallel-FSDP实战揭秘,一套接口使能双框架FSDP
大模型训练中,随着模型参数向万亿级迈进,显存压力呈指数级增长。传统的数据并行要求集群中的每张 GPU 都维护完整的模型和优化器副本,这在面对超大模型时极易触发显存瓶颈。 FSDP(全分片数据并行)技术通过将模型参数、梯度和优化器状态跨节点进行分片,有效利用网络通信换取显存空间,从根本上解决了单卡显存受限的问题。然而,在不同框架上分别编写和维护分布式训练逻辑,造成了极高的工程开销。 为此,HyperParallel 库屏蔽了底层通信与算子差异,为 PyTorch 和MindSpore 双生态提供一致的FSDP接口,降低用户平台间迁移成本。
01 技术背景介绍
在大模型分布式训练中,数据并行策略主要有以下几种: DDP 通过全量复制模型副本实现同步,虽实现简便易于调测但却带来严重的显存冗余现象,仅适用于小规模参数场景; 完全分片数据并行(FSDP) 通过将模型参数、梯度及优化器状态在所有计算设备间全量分片,使单卡静态显存占用理论降至 1/N,在高带宽集群环境下能最大化显存利用率并支撑千亿级超大规模模型的高效扩展; 混合分片数据并行(HSDP) 则作为DPP与FSDP的折中演进,采用节点内分片、节点间复制的二维网格设计,旨在跨机带宽受限的网络中平衡显存效率与通信开销。通过显存与通信之间的trade-off,实现了在不同硬件拓扑与模型规模下的最优训练配置。
02 HyperParallel-FSDP技术介绍
# 1. Define a simple Transformer with configurable number of layers (using TransformerEncoderLayer)
class SimpleTransformer(Module):
def __init__(self, num_layers=4, d_model=256, nhead=8, dim_ff=512):
super().__init__()
self.layers = ModuleList([
TransformerEncoderLayer(d_model, nhead, dim_ff, dropout=0.1, activation="gelu")
for _ in range(num_layers)
])
self.norm = LayerNorm(d_model)
def forward(self, src):
out = src
for layer in self.layers:
out = layer(out)
return self.norm(out)
NUM_LAYER = 4
# 2. Transormer instance.
transformer = SimpleTransformer(num_layers=NUM_LAYER)
本章节后续对HyperParallel-FSDP的介绍,基于上述这个简单的transformer网络进行介绍。
2.1 跨平台统一接口
HyperParallel-FSDP 采用与 PyTorch FSDP 完全兼容的接口设计,一个接口即可应用FSDP能力,同时支持MindSpore与PyTorch双框架:
from hyper_parallel.core.fully_shard.api import fully_shard
fully_shard(transformer)
核心优势: 零上手成本:接口命名、参数形式与 PyTorch FSDP 保持一致,现有 PyTorch 用户可无缝迁移 平台切换:通过指定环境变量 export HYPER_PARALLEL_PLATFORM="torch"或
export HYPER_PARALLEL_PLATFORM="mindspore"
将HyperParallel应用到不同的框架上。 默认配置:默认配置兼容Torch FSDP2,提供ZeRO-3级别的显存优化能力
2.2 分片策略
DeviceMesh是一种用于定义分布式训练的设备拓扑的数据结构。 HyperParallel的DeviceMesh 与 PyTorch 接口完全兼容,当前同样支持MindSpore与PyTorch双框架。 fully_shard接口接受DeviceMesh类型的入参,指导权重如何在设备矩阵上切分。 FSDP(一维 Mesh):
FSDP(Fully Sharded Data Parallelism)通过将模型参数、梯度、优化器状态在所有设备间分片,显著降低单卡显存占用。理论上,N张卡配置下静态显存占用可降至单卡的 1/N。在高带宽集群环境下能有效缓解显存压力。当fully_shard引用的mesh为1D Mesh时,则进入FSDP模式。
from hyper_parallel import init_device_mesh
from hyper_parallel.core.fully_shard.api import fully_shard
# 1D Mesh - FSDP 模式
mesh_1d = init_device_mesh(device_type="npu", mesh_shape=(8,))
# Apply fully_shard to each sublayer first
for layer in transformer.layers:
fully_shard(layer, mesh_1d)
# Then apply fully_shard to the root module
transformer = fully_shard(transformer, mesh=mesh_1d)
在实践中,需要特别注意先对模型的子层应用fully_shard接口,再对最顶层模型应用fully_shard接口。这样才能真正起到降低显存的效果。 每个子层在前向计算时只会 All‑Gather该子层自己的参数组,而不会涉及其它层的参数。前向结束后,子层会立即丢弃已聚合的完整权重,仅保留各自的分片。这样,任何时刻显存中只有某一层完整的参数存在。 -错误示例(仅对根模块进行 fully_shard)
# ❌ WRONG USAGE – only shard the top‑level module
fsdp_transformer = fully_shard(transformer, mesh=mesh_1d)
请勿这么做,否则会导致整个模型在前向前一次性 All‑Gather,显存峰值与完整模型相同,严重影响FSDP的显存优化效果。 HyperParallel-FSDP 默认采用 ZeRO-3 策略,参数、梯度、优化器状态均在所有设备间分片。完整的通信生命周期如下:

HSDP(二维 Mesh):
HSDP(Hybrid Sharded Data Parallelism)是 FSDP与DDP的一个折中方案,通过2D设备网格实现。在分片维度上进行权重切分,在复制维度上保持冗余。HSDP 适用于多机多卡场景且跨机带宽受限的场景,可在通信开销与显存效率之间取得折中。
from hyper_parallel import init_device_mesh
# 2D Mesh - HSDP 模式
mesh_2d = init_device_mesh(device_type="npu", mesh_shape=(2, 8), mesh_dim_names=("replicate", "shard"))
当fully_shard接受的DeviceMesh是一个二维的mesh时,则会进入HSDP模式。 HSDP 结合了分片与复制的优势,适用于多机多卡场景。以 mesh_shape=(2, 8) 为例(2 个 replicate 组,每组 8 卡分片):
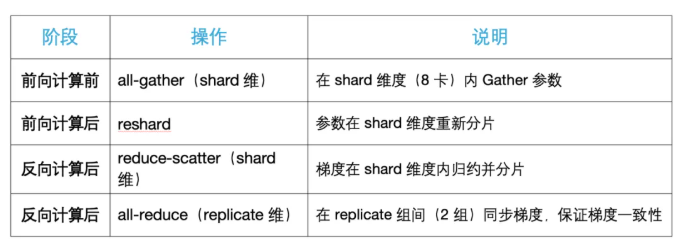
在实践中,一般将shard维配置在机内,shard 维度负责在每一步前向/反向计算中进行 All‑Gather 与 Reduce‑Scatter,这些通信在模型训练期间会频繁出现,机器内带宽相对较高,可以显著降低延迟和带宽瓶颈;在机器间仅做一次AllReduce用以同步冗余参数之间的梯度。
在对Module应用fully_shard接口后,会动态地修改Module的类型,使其具有一批FSDP相关的设置接口
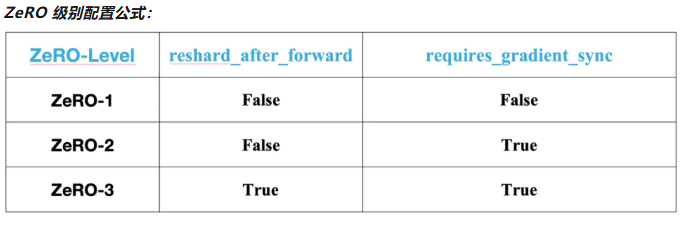
- set_reshard_after_forward(False):禁用前向后自动 reshard,参数在前向后不释放完整参数占用的显存,增大显存开销但却可以节省通信开销
- set_requires_gradient_sync(False):禁用梯度通信同步(不进行 all-reduce/reduce-scatter),增大显存开销但却可以节省通信开销
通过这两个接口的组合配置,可以达到ZeRO-1, ZeRO-2, ZeRO-3(默认) 级别的显存优化能力。
2.3 参数预取
参数预取(Prefetch)是一种在计算与通信之间实现流水线重叠的技术。
工作原理 : 正向预取:在计算第 I 层前向时,使用另一条流提前对第 I + 1 层的未分片参数执行 All‑Gather,使得第 I + 1 层的参数在其前向计算开始前已经聚合完成,从而在第 I 层计算期间隐藏第 I + 1 层的通信开销。
反向预取:在执行第 I 层的反向计算时,另一条流会对第 I ‑ 1 层的参数进行 All‑Gather,使得在当前层梯度计算完成后,下一层的参数已经准备好。
代码实现 :
HyperParallel 在 fully_shard API 中提供了两组接口,允许用户显式指定需要进行预取的模块列表:
- set_modules_to_forward_prefetch(self, modules)
接口接受一个 HSDPModule 实例列表(tuple 或 list),将这些模块登记到内部 hsdp_scheduler 中。调度器将在前向计算之前,对这些模块的未分片参数执行 All‑Gather,确保第 I 层前向时第 I + 1 层参数已准备好。
- set_modules_to_backward_prefetch(self, modules)
同样接受 HSDPModule 实例列表,调度器将在 第 I 层的反向计算期间 对对应模块的参数执行 All‑Gather。
以设置正向流程中的预取为例,每个Layer会去预取下一层Layer的模型参数:
def _post_order_traverse(module: torch.nn.Module):
"""Post-order traversal of model submodules (recursive implementation).
Yields child modules before their parents.
"""
for child in module.children():
yield from _post_order_traverse(child)
yield module
# Utility: traverse all sub-modules in post-order before applying sharding
for layer in transformer.layers:
fully_shard(layer, mesh=mesh_1d)
# Apply fully_shard to the root transformer after its children are sharded
fully_shard(transformer, mesh=mesh_1d)
modules_in_post_order = list(_post_order_traverse(transformer))
# Number of subsequent layers to prefetch during forward pass
num_to_forward_prefetch = 2
if num_to_forward_prefetch > 0 and num_to_forward_prefetch < len(modules_in_post_order):
for i, layer in enumerate(modules_in_post_order):
# Determine the slice end index without exceeding list length
j_end = min(len(modules_in_post_order), i + 1 + num_to_forward_prefetch)
# Select the next N layers as prefetch targets
layers_to_prefetch = modules_in_post_order[i + 1:j_end]
if layers_to_prefetch:
# Register these modules for forward prefetching on the current layer
layer.set_modules_to_forward_prefetch(layers_to_prefetch)

在对本层的参数做完AllGather通信后,将对后续层的参数分片的AllGather以异步方式下发,达到参数聚合通信与正反向计算相掩盖的效果。
2.4 梯度通算掩盖
梯度规约掩盖(gradient reduce overlap)指在反向传播过程中,梯度的 ReduceScatter 或 AllReduce 通信可以与当前层反向计算相重叠。HyperParallel‑FSDP 默认在每个 HSDPModule 开启此特性,无需额外配置;
内部调度器会在第I层的梯度计算完成后立即触发异步的ReduceScatter/AllReduce,并在第I-1层对第I层的通信句柄进行wait,及时释放完整的梯度所占用的显存空间,提高整体训练效率。
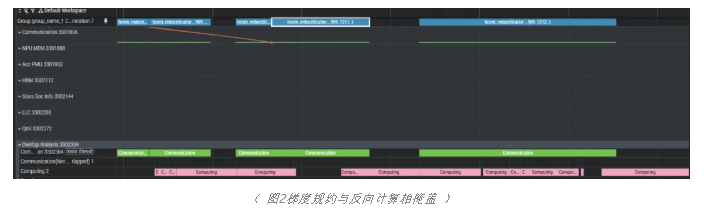
参数的梯度在计算图中处于叶子节点的位置,对其梯度的通信规约和反向计算相掩盖。
2.5 混合精度
混合精度训练通过 MixedPrecisionPolicy 配置实现。
用户可在 fully_shard 接口中传入mp_policy=MixedPrecisionPolicy(... ) 来开启BF16/FP16训练。
FSDP 在保持与 Torch FSDP2MixedPrecisionPolicy
的使用方式一致的同时,额外支持 分片梯度的高精度累加:当模型参数采用低精度(如 BF16)时,梯度在各分片上仍以 FP32 累加,确保数值稳定性。
03 总结与展望
HyperParallel FSDP 提供了三个核心优势:

后续开发计划 :
- HyperParallel-FSDP 通信按需融合
- HyperParallel-FSDP结合TP/EP/CP,完善HyperShard基础能力
- HyperParallel-FSDP在MindSpore平台性能优化特性
04 完整Demo样例
为了方便开发者快速上手或进行框架迁移,我们整理了 MindSpore 与 PyTorch 在实现 Fully Sharded Data Parallel (FSDP) 时的完整代码样例。你可以通过对比,直观地看到两者在训练流程定义上的异同。
MindSpore 版本 :
复制代码链接:
https://gitcode.com/mindspore/hyper-parallel/blob/master/examples/mindspore/fully_shard/fsdp_demo.py
Pytorch 版本 :
复制代码链接:
https://gitcode.com/mindspore/hyper-parallel/blob/master/examples/torch/fully_shard/fsdp_demo.py
复制链接后即可直接在浏览器打开查看源码,也可本地下载运行调试,快速上手分布式并行训练实践~
05 与 HyperParallel 共建开源社区
HyperParallel 致力于保障分布式训练的稳定性与精度可复现,这离不开每一位开发者的智慧。如果你也追求极致的算力释放,欢迎加入我们的 SIG(特别兴趣小组):
参与讨论:加入 Parallel Training System SIG 论坛(https://www.mindspore.cn/sig/Parallel%20Training%20System),参与架构设计讨论。
代码共建:直接在 GitCode 上提交 Issue 或 Pull Request。
(https://gitcode.com/mindspore/hyper-parallel/)无论是代码实现、文档完善、示例补充还是 Bug 反馈,您的每一份贡献都将帮助更多研究者和开发者受益。