MindSpore Shard:深度解读算子级工具
MindSpore Shard:深度解读算子级工具
如果把训练大模型比作指挥去庞大的军队,那么MindSpore的shard接口就是你手中的指挥棒。它让你跳过繁琐的粗俗,直接告诉系统:“这个关键阵地(算子),我用这种细节的特定队形(切分策略)去攻克!”
本指南将带你深入理解 MindSpore 的算子级任务(Operator-level Parallelism),不仅知其然,更知其所以然。
01 为什么需要Shard?
在工具训练的世界里,通常有两种补充:
- 辅助驾驶(自动并行):你什么都不用管,系统决定帮你怎么切分模型。虽然方便,但成本模型(代价模型)并不总是完美的,有时它选择的“路”虽然理论代价低,但并不符合你的专家直觉。
- 纯手动挡(数据并行):你可以简单地把数据分给各张卡,模型本身不动。这对于超大模型来说,显存根本不够用。
碎片就像是半自动驾驶。你拥有“专家介入”的权力——对于那些你最了解、最关键的算子(比如巨大的矩阵乘法),你可以手动指定切分方式;而对于剩下的琐碎算子,则相当于MindSpore自动推导。
一句话总结:shard让你在“操控力”和“便利性”之间找到了完美的平衡。
02 深度揭密:从策略到执行的旅程
shard不是简单地给算子打个标签,它触发了MindSpore内部一套复杂的策略传播与图编译机制。让我们拆解一下这个过程。
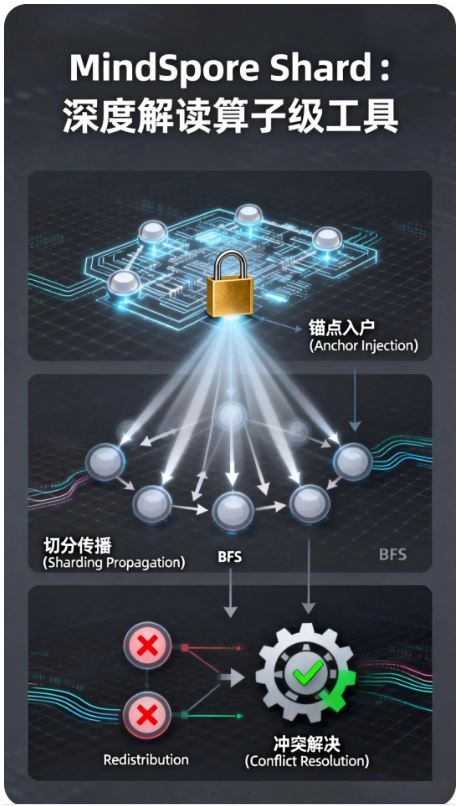
2.1第一阶段:锚点入户(Anchor Injection)
当你调用shard(fn, in_strategy)时,你实际上是在计算图上打出的几个坚不可摧的节点。
- 绝对权威:这些被shard标记的子,其输入和输出的张量布局(Layout)被永久锁定。在C++的图优化阶段,系统会识别这些原算语(prim::kPrimShard),并通过SetInputLayout并将SetOutputLayout策略绑定到对应的图节点上。
- 硬约束:在后续的所有优化过程中,无论系统觉得其他策略如何诱导(比如通信开销更小),它都绝不敢修改你指定的策略。这就相当于你在地图上钉钉下的子,路怎么修都,但有几点必须经过可以。
- 种子池(Seed Pool):这些成功设置了策略的算子会被存入一个特殊的集合(configured_ops),它们将成为下一阶段算法的根本驱动源。
2.2 第二阶段:切分传播(Sharding Propagation)
这是shard机制的核心魔法。系统不仅要满足你的要求,还要让整个图“跑通”。MindSpore使用了一种基于BFS(广度优先搜索)的传播算法来实现这一目标。
循环效应:
算法从种子池中的算子开始,向图的完成扩散(BFS):
- 顺流传播(Forward):遍历当前算子的输出边。如果上游算子B未配置策略,系统会根据上游算子A的输出布局,为B选择一个最匹配的输入策略。
- 逆流传播(Backward):遍历当前算子C的输入边。如果上游算子C未配置策略,系统会根据下游算子D的输入需求,反向推导C的策略输出。
最小代价决策(Greedy Cost Minimization):
在传播过程中,当系统需要为相邻的未配置算子选择策略时,它遵循一个核心原则:最小化重排布代价。
- 零通信优先:如果存在一种策略,使得数据不需要在卡间传输能够直接被下游使用(布局完全匹配),那么就不必犹豫地选择它。
- 最小通信次之:如果必须传输,则计算所有备选策略的重排布代价(Redistribution Cost),选择通信量最小的那个。
2.3 第三阶段:与桥梁建设的冲突解决(Conflict Resolution)
现实往往不完美。如果你的策略和模型的自然结构发生了冲突,或者你手动指定了两个相邻算子使用完全不同的策略,会发生什么?
- 自动插入转换器(Redistribution): MindSpore不会报错,而是会充当“和事佬”。 假设上游算子A是“行切分”数据,而你强转换行下游规定算子B必须接收“负责列切分”数据。 系统会自动在A和B之间插入一组通信算子(如AllToAll )。这组算子在运行时把AllGather数据Permute从卡A搬运到卡B,完成布局的。
- 代价权衡: 虽然系统能解决冲突,但转换是有代价的(时间、带宽)。shard的艺术就在于:不仅要指定策略,还要尽量减少这种不必要的转换。
03 实战心法:如何用好Shard?
理解了原理,我们来看看怎么用。这里不罗列代码,而是讲“心法”。
3.1 心法一:抓住“大鱼”,放过“虾米”
不要尝试再次给每个算子都分片。
- 大鱼:计算量大、参数多的算子(如MatMul,Conv2D)。这些是性能极限,值得你手动优化(比如做模型玩具)。
- 虾米:激活函数(ReLU)、逐元素操作(Add)。这些算子计算极快,通常紧随上游策略即可(数据工具),不需要你操心。
# [实战示例] 抓大放小
class Net(nn.Cell):
def __init__(self):
super().__init__()
self.dense = nn.Dense(64, 64) # 大鱼:矩阵乘法
self.relu = nn.ReLU() # 虾米:激活函数
def construct(self, x):
# 1. 只有 Dense 这种重计算算子值得我们手动切分
# 我们给它配置模型并行策略(假设4卡,参数切4份)
x = shard(self.dense, in_strategy=((4, 1),), parameter_plan={"self.dense.weight": (1, 4)})(x)
# 2. ReLU 很轻,不要管它。
# MindSpore 会自动推导:既然上游 Dense 输出了切分后的数据,ReLU 就直接复用这个策略,零通信代价!
x = self.relu(x)
return x
3.2 心法二:顺势而为,减少“搬运”
设计策略时,要顺应数据的流动方向。
- 坏情况:第一层用模型任务(切参数),第二层突然强行切回数据任务(切Batch),第三层又切回模型任务。这会导致每层之间都处于疯狂通信(AllToAll),训练极慢。
- 好案例:连续的几个层都保持模型工具,直到必须聚合时(比如损失计算前)再统一转回数据工具。
# [实战示例] 顺势而为
# 假设我们构建一个多层感知机 (MLP)
class MLP(nn.Cell):
def __init__(self):
super().__init__()
self.fc1 = nn.Dense(128, 128)
self.fc2 = nn.Dense(128, 128)
def construct(self, x):
# Good: 连续使用模型并行,中间不需要转来转去
# 第一层:输入(4,1) -> 权重(1,4) -> 输出(4,1) [注意:MatMul会自动推导输出策略]
x = shard(self.fc1, in_strategy=((4, 1),), parameter_plan={"self.fc1.weight": (1, 4)})(x)
# 第二层:继续接收(4,1)的输入。因为上游输出是(4,1),这里不需要任何通信!
x = shard(self.fc2, in_strategy=((4, 1),), parameter_plan={"self.fc2.weight": (1, 4)})(x)
return x
3.3 心法三:利用布局提升优势
不要在代码里写满(4, 1), (8, 1)这种数字天书。使用Layout给维度起名字。
把设备维度命名为dp(Data Parallel) 和mp(Model Parallel)。
代码里写的layout("dp", "mp"),一眼就能看出是“数据维走dp,模型维走mp”。
# [实战示例] 提升可读性
from mindspore.parallel import Layout
# 定义布局:8卡,4x2
layout = Layout((4, 2), ("dp", "mp"))
def attention_score(q, k):
return ops.matmul(q, k)
# 不用 Layout:
# shard(attention_score, in_strategy=((4, 1, 2), (4, 2, 1))) # 谁知道哪个维度对应什么?
# 使用 Layout:
# 假设 q: [Batch, Seq, Head], k: [Batch, Head, Seq]
# dp=Batch维度, mp=Head维度
in_strategy = (
layout("dp", "None", "mp"), # q: Batch切dp, Head切mp
layout("dp", "mp", "None") # k: Batch切dp, Head切mp
)
shard(attention_score, in_strategy=in_strategy) # 清晰明了!
04 常见误区与避坑
“自动”不是“全能”:
虽然叫AUTO_PARALLEL,但如果你分片得不合理(比如切分份数不能整除卡数),系统也没法帮“圆”回来,会直接报错。
PyNative 的遗憾:
目前shard强依赖于静态图编译技术(因为要分析全图做传播),所以在 PyNative 模式(动态图)下暂时无法使用。
牵一发而动全身:
你在网络中间修改了一个算子的策略,可能会导致整个网络的策略发生“蝴蝶效应”般的剧变。如果不确定,建议先在小规模子网中验证。