HyperParallel声明式并行能力解读
01 张量排布表达:用Layout解锁分布式张量的“灵活姿态”
我们使用Layout来表达张量的分布式排布,内部包含3个成员:
- device_matrix: 描述集群中卡号的逻辑排布方式
- alias_name:device_matrix中每个轴的别名
- rank_list(可选):device_matrix对应的设备列表
比如:layout = Layout((4, 2), ("dp", "mp"), (0, 1, 2, 3, 4, 5, 6, 7))
HyperParallel引入DTensor结构管理分布式张量的状态。通过声明式接口DTensor.from_local方法表达从local tensor创建一个DTensor。
不同切分形态之间可以通过重排进行转换,示意如下:
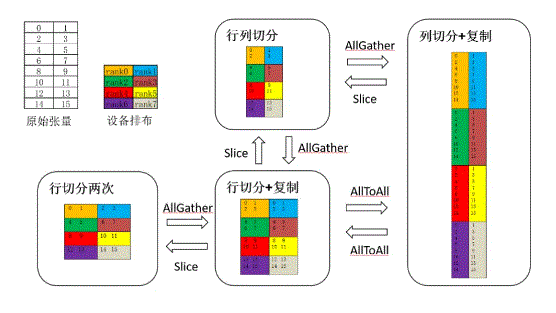
DTensor支持通过DTensor.redistribute接口与期望的分布式排布Layout,显式触发张量重排布流程。
02 算子级并行:HyperParallel的“核心引擎”,让多卡协同更高效
算子级并行即将算子的输入张量切分到多张卡上,使得每张卡计算一个分片,其汇总的结果是整个算子的计算结果。神经网络结构可以简单划分为三个部分:正向、反向、优化器。
为了能够简化分布式训练当中针对并行场景的配置与适配,HyperParallel提供了声明式接口Cell.shard,使用该接口时,为Cell的输入,输出,以及Cell内的参数配置张量的分布式排布方式。HyperParallel将屏蔽分布式任务的细节,自动处理Cell内部参数的切分以及DTensor的重排布。相较于Megatron模型逻辑与分布式逻辑耦合的写法,采用HyperParallel声明式编程方式能极大简化开发的复杂度。

HyperParallel库提供接口parallelize_value_and_grad正确处理声明式并行场景下反向梯度的运算,解决反向sens值处理难题,保障训练精度。
整体设计流程图如下:

03 自定义并行:灵活补位,适配个性化并行需求
自定义并行是对算子级并行能力的补充。在算子级并行中,框架自动完成了算子切分后为保持数学等价性每个设备所需执行的算子序列推导及生成相关的集合通信操作。而自定义并行则支持用户手写并行接入dtensor并行流程HyperParallel提供声明式接口hyper_parallel.custom_shard,允许用户需提供一个自定义函数,并描述其输入/输出张量的切分形态。自定义函数是站在local tensor视角进行编程,内部可以显式调用集合通信接口,而其输入/输出通过切分形态的描述与前后的算子级并行进行衔接。
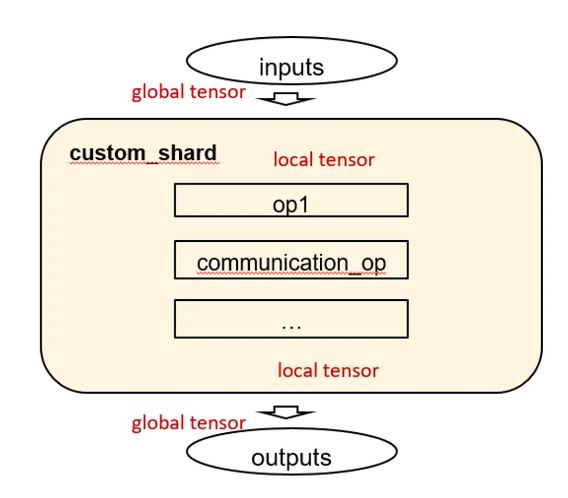
如图所示,框架将输入的global tensor转换成local tensor后进入自定义函数,自定义函数体内以local tensor视角进行编程并可以显式调用集合通信,最后框架再将自定义函数输出的local tensor转换成global tensor。
04 自定义并行:平衡通信与内存,破解冗余痛点
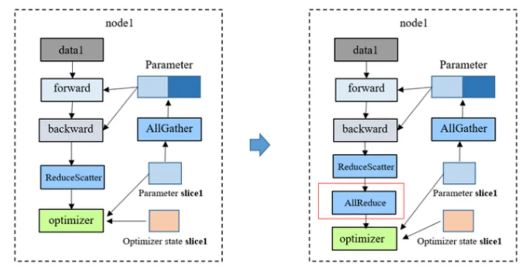
数据并行是常用的分布式方式,核心是拆分训练数据至各节点独立计算,再通过AllReduce同步梯度。但传统方式存在模型参数与优化器状态的存储、计算冗余,制约效率。
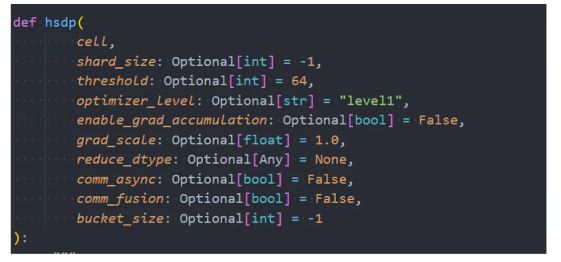
HyperParallel提供HSDP能力,通过使用声明式接口hyper_parallel.hsdp,配置shard_level为level1,level2,level3,以达到对标zero1, zero2, zero3级别的优化能力。
使用参考如下配置:
05 流水线并行:分阶段并行,释放多设备协同潜力
Pipeline(流水线)并行是将神经网络的算子按照一定规则切分为多个 Stage,并将Stage 映射到不同的设备上,这样,可以使不同的设备去计算神经网络的不同部分,从而降低单卡内的显存负载,使得大模型能够运行起来。
当前的流水线并行处理流程可分为以下四个步骤:
1.模型切分(Split Model): 将完整模型根据一定规则进行切分,将其裁剪为当前 Stage 需要计算的子模型。
2.Stage 实例化: 根据切分完的模型和相关的模型参数构造 Stage 实例。
3.Schedule 实例化: 指定具体的Schedule算法, 进行对应Schedule的实例化。
4.执行调度 (Schdule.step()): 根据不同的调度算法,执行对应的调度策略。
在声明式编程方式下,模型切分的规则由开发者设置,具体地,开发者需要考虑每个 stage需要计算的子模型,接着对这部分子模型进行实例化。参考脚本可如下所示:
class Transformer(nn.Cell):
def __init__(self, num layers):
super().__init__()
self.embedding = nn.Embedding(...)
self.layers = nn.CellDict()
for layer_id in range(num_layers):
self.layers[str(layer_id)] = TransformerBlock(...)
self.output = nn.Linear(...)
def construct(self, input_ids):
h = self.embedding(input_ids) if self.embedding else input_ids
for layer in self.layers.values():
h = layer(h)
output = self.output(h) if self.output else h
return output
def model_split_manual(model, stage_index):
"""假设mode[共有8层,共2个stage, 每个stage有4层"""
if stage_index == O:
for i in range(4, 8):
del model.layers[str(i)]
model.output = None
else:
for i range(4):
del model.layers[str(i)]
model.embedding = None
可以看到,模型在构造时,会根据不同的stage_index来进行模型的切分,其中stage0包含Embedding层以及0-3层TransformerBlock,stage1包含Output层以及4-7层TransformerBlock。
模型切分完成之后,需要进行PipelineStage类型的实例化。在其内部完成了P2P通信算子的构造,P2P通信buffer的创建和析构、正反向函数的构建以及正反向cache的自动管理,方便开发者关注流水线并行调度逻辑的开发;流水线并行调度通常包括MicroBatch的切分,MicroBatch的执行,以及输出output的处理。为了方便用户自定义执行序调度,PipelineSchedule提供了一套自定义调度的接口。
目前,HyperParallel已内置GPipe,1F1B, VPP等常用调度,也支持用户利用调度接口进行自定义调度。