HyperOffload:设备内存优化技术深度解析
HyperOffload:设备内存优化技术深度解析
01 核心问题与解决思路
1.1 显存受限的本质问题
在模型训练与推理过程中,模型参数与中间 Activation 的显存占用往往超出设备显存容量限制。传统方案要求用户手动管理数据 placement 或使用模型并行分割策略,开发门槛较高且灵活性不足。
1.2 数据 Offload 优化策略
HyperOffload 采用"数据换时间"的优化思路:将不常用的数据暂时移到主机端,需要时再移回来。通过这种方式,虽然增加了数据传输开销,但显著降低了峰值显存占用,使原本无法在有限显存环境下执行的大模型得以运行。
1.3 图优化层三大任务
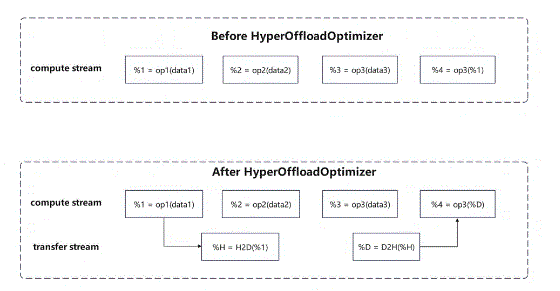
图优化层承担三项核心职责:首先是分析计算图,确定哪些数据适合 Offload;其次是决定 Offload 时机,包括何时将数据从设备移到主机、何时从主机移回设备;最后是修改计算图,插入必要的 Offload 操作节点,并调整执行顺序以实现计算与传输的重叠执行。
02 图优化层代码逻辑详解
2.1 优化器主流程
HyperOffloadOptimizer::Run() 是图优化层的核心入口,其执行逻辑遵循清晰的流水线式设计。
执行 SkipHyperOffloadOptimizer() 完成配置检查后,operations_.Init() 初始化操作管理队列,为每个执行节点预留操作存储空间。随后根据使能状态分别处理 Parameter Offload 和 Activation Offload 两类场景。
GenerateParameterOperations() 负责为远程 Parameter 在恰当位置插入加载与释放操作,GenerateActivationOperations() 则通过分析节点依赖关系,识别适合 Offload 的中间结果并插入对应的传输节点。
在完成节点插入后,AdjustHyperOffloadNodePosition() 调整 H2D 节点的物理位置,根据 prefetch_distance 配置让数据加载操作适当提前,使后续计算能够与数据传输并行执行。接下来 AddEventNodes() 注入 Send/Recv 同步事件,确保数据传输与计算执行之间的正确依赖关系。
最后,BuildExecutionOrder() 将所有 Offload 操作节点按照依赖关系整合进原始执行顺序,形成包含新增节点的完整执行序列;AssignHyperOffloadIds() 为所有 Offload 相关节点分配唯一标识符,用于运行时追踪数据流转状态。
2.2 GenerateParameterOperations 伪代码
# 为远程 Parameter 插入 H2D/D2H 操作节点
function GenerateParameterOperations():
for each node in exec_order:
# 遍历节点的所有输入
for i from 0 to node.inputs().size() - 1:
input_node = node.input(i)
# 处理 Load 节点包裹的 Parameter
if IsPrimitiveCNode(input_node, "Load"):
real_input = GetKernelWithReturnType(input_node, 0, false, "Load").first
if IsPrimitiveCNode(real_input, "Load"):
data_node = real_input.input(1) # Load 节点的第二个输入
if IsRemoteParameter(data_node): # 检查是否是远程 Parameter
# 插入 H2D 节点
to_device = BuildToDeviceNode(data_node)
UpdateNodeInput(node, i, to_device)
operations_.AddOperationBefore(node_index, to_device)
# 插入 D2H 节点(原地更新)
to_remote = BuildInplaceToHostNode(to_device, data_node, node)
operations_.AddOperationAfter(node_index, to_remote)
continue
# 直接处理 Parameter 引用
if IsRemoteParameter(input_node):
# 插入 H2D 节点
to_device = BuildToDeviceNode(input_node)
UpdateNodeInput(node, i, to_device)
operations_.AddOperationBefore(node_index, to_device)
# 插入 D2H 节点(原地更新)
param_node = GetRemoteParameter(graph, input_node)
to_remote = BuildInplaceToHostNode(to_device, param_node, node)
operations_.AddOperationAfter(node_index, to_remote)
2.3 GenerateActivationOperations 伪代码
# 识别需 Offload 的 Activation 并插入 D2H/H2D 节点
function GenerateActivationOperations():
# 1. 建立数据 → 使用者映射关系
user_info_list = CollectAllNodeUsers(exec_order)
# 2. 基于距离策略筛选 Offload 目标
strategy = DistanceBaseHyperOffloadStrategy()
offload_info_list = strategy.Run(exec_order, user_info_list)
# 3. 数量过滤
filter = OffloadInfoFilterByNumber()
offload_info_list = filter.Filter(offload_info_list)
# 4. 获取图输出节点
outputs = GetAllOutputWithIndex(graph.output())
# 5. 为每个目标插入 Offload 节点
for each offload_info in offload_info_list:
AddSingleActivationOperations(offload_info, outputs)
# 单个 Activation 的 Offload 节点插入
function AddSingleActivationOperations(offload_info, outputs):
data_node = offload_info.data_node
# 1. 处理 Tuple 类型的输出
if data_node.abstract is Tuple:
index_node = NewValueNode(offload_info.data_node.index)
data_node = graph.NewCNode([TupleGetItem, data_node, index_node])
# 2. 在数据产生位置之后插入 D2H 节点
to_host = BuildToHostNode(data_node)
data_idx = FindIndexInExecOrder(data_node)
operations_.AddOperationAfter(data_idx, to_host)
# 3. 为每个使用位置插入 H2D 节点
for each replace_info in offload_info.replace_info_list:
to_device = BuildToDeviceNode(to_host)
# 替换原节点输入
for each change_node in replace_info.replace_rest_nodes:
UpdateNodeInput(change_node, change_node.index, to_device)
# 在使用位置之前插入 H2D 节点
change_idx = FindIndexInExecOrder(change_node)
operations_.AddOperationBefore(change_idx, to_device)
# 4. 处理输出节点
if data_node in outputs:
to_device = BuildToDeviceNode(to_host)
UpdateNodeInput(output, output.index, to_device)
operations_.AddOperationAfter(last_index, to_device)
2.4 AdjustHyperOffloadNodePosition 伪代码
# 根据 prefetch_distance 调整 H2D 节点位置,实现数据预取
function AdjustHyperOffloadNodePosition():
# 1. 获取所有已插入的 H2D 节点
h2d_nodes = operations_.GetAllH2DNodes()
for each h2d_node in h2d_nodes:
# 2. 获取 H2D 节点关联的原始数据节点
data_index = 1 # 输入参数位置
input_node = h2d_node.input(data_index)
if IsD2HNode(input_node):
# H2D 节点的输入是 D2H 节点,取 D2H 的输入作为原始数据
data_node = input_node.input(data_index)
else:
data_node = input_node
# 3. 获取 prefetch_distance(优先使用节点属性,其次使用全局配置)
prefetch_distance = GetNodePrefetchDistance(data_node) or
GLOBAL_CONFIG.prefetch_distance
# 4. 将 H2D 节点向前移动指定距离,实现预取
operations_.MoveAhead(h2d_node, prefetch_distance)
2.5 BuildExecutionOrder 伪代码
# 将 Offload 操作节点插入到执行顺序中,构建新执行序列
function BuildExecutionOrder():
new_execution_order = []
# 1. 添加前置操作(独立于任何执行节点的操作)
for op in operations_.GetPreOperations():
new_execution_order.append(op)
# 2. 遍历原始执行顺序,交错插入 Offload 操作
for i from 0 to len(exec_order) - 1:
# 2.1 添加原始执行节点
new_execution_order.append(exec_order[i])
# 2.2 添加该位置对应的 Offload 操作(在 exec_order[i] 之后执行)
for op in operations_.GetOperations()[i]:
new_execution_order.append(op)
return new_execution_order
# 示例:Activation Offload 的节点插入
# 原始 exec_order: [A, B, C, D, E]
# 假设 A 的输出 X 被 E 使用,且 A 与 E 之间距离超过阈值,需要 Offload
#
# 节点关系:
# A(data: X) → E 使用 X
# D2H 插入在 A 之后,H2D 插入在 E 之前
#
# operations_ 队列:
# pre_operations: [] // 无前置操作
# operations[0]: [D2H1] // A 之后:D2H1(input: A)
# operations[1]: [] // B 之后
# operations[2]: [] // C 之后
# operations[3]: [] // D 之后
# operations[4]: [H2D1] // E 之前:H2D1(input: D2H1)
#
# 构建结果: [A, D2H1(A), B, C, D, E, H2D1(D2H1)]
#
# 数据流向:
# A(X) → D2H1(输入 A 的输出 X,输出 X 到主机) → E(从主机加载 X)
# ↘
# H2D1(输入 D2H1 的输出 X)
2.6 关键函数简述
Activation Offload 的处理流程包含四个关键环节。首先,CollectAllNodeUsers() 遍历计算图建立数据与使用者的映射关系,明确每个数据节点被哪些操作消费以及消费的先后顺序。然后 DistanceBaseHyperOffloadStrategy::Run() 基于使用距离判定 Offload 必要性:当数据产生位置与后续使用位置之间的间隔超过 select_distance 阈值时,判定该数据适合 Offload。判定结果经 OffloadInfoFilterByNumber::Filter() 数量过滤后,最终 AddSingleActivationOperations() 执行实际的节点插入操作:在数据产生处插入 D2H 节点将数据送回主机,在各使用处插入 H2D 节点重新加载数据。
事件注入环节,AddEventNodes() 为每个 D2H 和 H2D 节点配对 Send/Recv 事件,通过在不同执行流上调度发送与接收操作,实现计算与传输的时间重叠。
03 关键数据结构汇总
HyperOffloadInput — 优化器输入结构,包含待优化的计算图、原始执行顺序、Parameter Offload 开关、Activation Offload 开关、以及新节点回调函数。
HyperOffloadPlan — 优化器输出结构,包含优化后的计算图、包含 Offload 节点的新执行顺序、以及 HyperOffloadOperations 操作管理队列。
UserInfo — 封装数据节点与其全部消费者的映射关系,node 字段标识数据生产者,users 字段存储按执行顺序排列的消费者列表。
OffloadInfo — 描述单个数据的 Offload 方案,data_node 标识目标数据,replace_info_list 包含所有需要重写数据引用的节点信息。
HyperOffloadOperations — Offload 操作管理类,维护前置操作队列和每个执行位置对应的操作列表,支持 AddOperationBefore、AddOperationAfter、MoveAhead 等操作。
04 Python 使用示例
Python 层通过 @jit 装饰器的 auto_offload 参数暴露使用接口。Activation Offload 使用 @jit(auto_offload="activation") 启用,适用于网络中存在跨长距离复用的中间激活值场景。
from mindspore import jit
@jit(auto_offload="activation")
def forward(x):
m1 = x / 2
m3 = m1 * 2
m4 = m3 * 2
m5 = m3 + m4
return (m5 * 2) - m1
运行时参数可通过 mindspore.graph.compile_config 模块调整,包括 SELECT_DISTANCE(距离阈值)、SELECT_NUM(Offload 上限)、PREFETCH_DISTANCE(预取距离)、RELEASE_DISTANCE(释放距离)等配置项。
05 总结与适用场景
HyperOffload 聚焦于 Ascend 设备显存受限场景下的模型高效执行,其基于数据流分析的编译期优化与基于异步事件的运行时协同机制,为大模型训练与内存受限推理提供了切实可行的解决方案。该技术适用于参数量庞大的 Transformer 类模型、长序列处理任务以及显存容量有限的边缘推理场景,核心价值体现在透明集成性、灵活配置性以及异步并行带来的性能收益。后续可探索基于机器学习的自适应策略选择、跨设备分布式 Offload 协同等优化方向。
关于HyperOffload的更多链接,请参考
https://atomgit.com/mindspore/mindspore/tree/master/mindspore/ccsrc/utils/hyper_offload