开源之夏|贾阔源:基于vLLM-MindSpore,深入探索Beam Search解码优化实战

开源之夏|贾阔源:基于vLLM-MindSpore,深入探索Beam Search解码优化实战
# 01
项目介绍
- 项目名称: 基于 vLLM-MindSpore 实现 Beam Search 算法功能
- **项目描述:**本项目旨在 vLLM-MindSpore 中完整实现 Beam Search 解码算法。项目解决了该框架在高质量文本生成任务(如机器翻译、摘要)中缺乏高效解码策略的痛点。通过重构采样逻辑和算子适配,显著提升了推理吞吐量和引擎初始化速度。
- **项目源码链接:**https://gitee.com/mindspore/vllm-mindspore/pulls/1084/files
# 02
技术实现:如何重新设计采样链路?
1、架构选型
- 开发方式: 深入 vLLM v0 架构的 model_executor 层进行二次开发,重点在于理解原版逻辑并结合 MindSpore 特性进行更优的等价迁移。
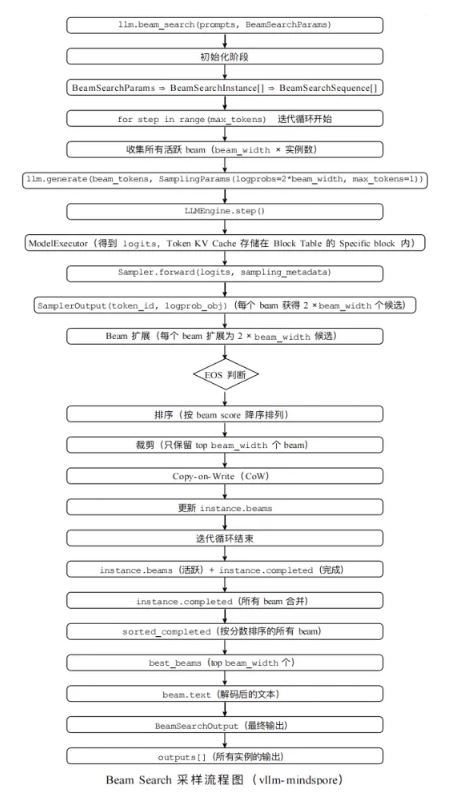
- 整体流程: (参考 vLLM v0 Beam Search 采样流程)
- 初始化与收集: 构建 BeamSearchInstance,在迭代开始时收集所有活跃 Beam。
- 前向推理: 调用 LLMEngine.step() 和 ModelExecutor 获取 Logits。
- 采样与扩展: 利用 Sampler 计算 Logprobs,将每个 Beam 扩展为 2 * beam_width 个候选。
- 管理与更新: 执行 EOS 判断、排序裁剪,并更新 Block Table 状态。
2、实现步骤
步骤一:环境搭建与避坑
- 参考官方 vllm_mindspore 安装指南。
- 避坑指南: 务必注意 MindSpore 版本与 vllm_mindspore 的对应关系。我初期因文档版本滞后遇到大量环境报错,教训是**遇到一些长时间无法解决问题应及时加入 SIG 组向专家求助,**避免消耗宝贵的开发时间。
步骤二:深入源码分析与路径定位
- 深入阅读vLLM源码: 系统梳理了vLLM的Beam Search采样链路, 彻底理清了从BeamSearchInstance到BeamSearchOutput的数据链路。
- 研读 vLLM-MindSpore 源码: 理解其当前的工作原理和适配进度,通过对比分析,精确定位了 model_executor/layers/sampler.py 中缺失的关键逻辑,明确了下一步代码实现的方向。
步骤三:核心采样逻辑重构
- 基于对源码的理解,重写 _greedy_sample 以支持多 Beam 并行采样,并优化了 _get_ranks 中的张量操作逻辑。
1. _greedy_sample: 从“单点阻塞”到“并行切片”
vLLM 原生实现 (PyTorch):
# 原始代码片段
num_parent_seqs = len(seq_ids)
assert num_parent_seqs == 1, ("Greedy sampling should have only one seq.") # <--- 致命限制
parent_ids = list(range(num_parent_seqs)) next_token_ids = [samples_lst[sample_idx]] # 只能取 1 个
- 问题点: 原生代码显式通过 assert 禁止了 Greedy Sampling 处理多父序列的情况。它假设 Greedy 采样只用于简单的单序列生成。当 Beam Search (e.g., beam_width=4) 传入一个包含 4 个 seq 的 group 时,这里会直接报错中断。
- 局限性: 无法支持 Beam Search 的“分叉”逻辑(即一个 Group 产生多个候选)。
优化实现 (MindSpore):
# 优化后代码片段
# Beam search: can have multiple sequences per group
if num_parent_seqs == 1:
# ... 标准处理 ...
else:
# Beam search: multiple parents parent_ids = list(range(num_parent_seqs))
# <--- 核心优化:并行切片 next_token_ids =samples_lst[sample_idx:sample_idx +
num_parent_seqs]
- 优化逻辑: 移除了断言,并引入了切片操作 samples_lstsample_idx:sample_idx + num_parent_seqs。
- 技术价值:
- 解锁功能: 使得采样器能够一次性处理 Beam Search 产生的多个候选分支,填补了 vLLM 原生逻辑在 Greedy 模式下不支持多 Beam 的空白。
- **零循环开销:**通过切片而非 Python for 循环逐个获取 token,保持了 Python 层面的执行效率。
2. _get_ranks: 消除中间张量,适配 NPU 内存模型
vLLM 原生实现 (PyTorch):
# 原始代码片段
# 1. 高级索引:创建中间张量 vals,形状 [N]
vals = x[torch.arange(0, len(x), ...), indices]
# 2. 广播比较:vals[:, None] 触发 unsqueeze 和广播result = (x > vals[:, None])
# 3. 手动删除:暗示了对显存的担忧
del vals
- 问题点: vals 是一个显式创建的中间张量。在 GPU/CPU上,分配内存 -> 写入数据 -> 读取数据 -> 释放内存 这一连串动作会打断计算流水线。
优化实现 (MindSpore):
# 优化后代码片段
# 1. 算子融合思路:直接使用 gather 配合 unsqueeze
chosen_values = x.gather(1, indices.unsqueeze(1)) # 直接生成 [N, 1]
# 2. 广播比较
rank_counts = (x > chosen_values).sum(1)
- 优化逻辑:
- 移除中间态: 使用 gather 算子直接提取并保持维度,一步生成了 N, 1 的 chosen_values。这避免了先生成 N 再 reshape 的过程。
- NPU 亲和性: gather 是 MindSpore 和 Ascend NPU 高度优化的算子。相比于 PyTorch 风格的复杂索引,显式调用 gather 更容易命中底层的高性能算子核(Kernel),减少算子编译和调度的开销。
- 技术价值: 减少了显存申请和释放的频率,降低了内存碎片风险,提升了计算图的执行效率。
3. get_logprobs: 保持批处理优势,精准适配算子
vLLM 原生实现 (PyTorch):
# 原始代码片段
query_indices_gpu = torch.tensor(query_indices, device=logprobs.device)
# ...
top_logprobs, top_token_ids = torch.topk(...) top_logprobs = top_logprobs.to('cpu') # 频繁的数据搬运
- 现状: 原生代码虽然逻辑也是批处理的,但它深度依赖 PyTorch 的 device 管理机制和 torch.topk。
优化实现 (MindSpore):
# 优化后代码片段
# ...
# 1. 索引扩展逻辑 (保持逻辑正确性)
query_indices.extend([query_idx + parent_id for parent_id in parent_seq_ids])
# ...
# 2. 使用 mint 接口适配 MindSpore
if largest_num_logprobs > 0:
top_logprobs, top_token_ids = mint.topk(logprobs, largest_num_logprobs, dim=-1) # ...
- 优化逻辑:
- 逻辑复用与适配: 保留了 query_indices.extend 这一高效的 Lazy Collection(延迟收集) 策略,确保所有 Beam 的 Logprob 计算合并为一次大 Batch 操作。
- 算子替换: 将 torch.topk 替换为 mint.topk。mint 是 MindSpore 专门为对齐 PyTorch 接口设计的模块,它底层调用的是 MindSpore 的高性能算子。
- 索引修正: 在移植过程中,重点解决了 Beam Search 下 parent_id 带来的索引偏移问题,确保在 MindSpore 的 Tensor 内存布局下,能够准确找到父 Beam 对应的 Logits。
- 技术价值: 这里的优化更多体现为 “架构适配”。没有因为框架切换而退化为逐个循环计算,而是坚持并正确实现了全 Batch 并行计算,确保了 Beam Search 在生成 Top-K 候选词时,Host(CPU)与 Device(NPU)的交互次数降到最低。
步骤四:组件注入与系统集成(Monkey Patch 策略)
- 为了将上述优化代码无缝集成到 vLLM 架构中,采用Monkey Patch 策略。
# 用于 beam search 的增强实现
vllm.model_executor.layers.sampler._greedy_sample = _greedy_sample
# logprob / ranking / result 构造函数(Beam Search 依赖)vllm.model_executor.layers.sampler.get_logprobs = get_logprobs
vllm.model_executor.layers.sampler._get_ranks = _get_ranks
实现方式:在vllm_mindspore的初始化阶段,通过 Python 的动态特性,将原⽣vllm.model_executor.layers.sampler中的关键函数(如_greedy_sample 、get_logprobs 、 _get_ranks )替换为我们针对 MindSpore 增强后的实现。
优势:这种⽅式保证了 vLLM 上层调度逻辑⽆需修改,即可在底层⾃动调⽤优化后的MindSpore 算⼦,实现了架构的解耦与功能的平滑扩展。
步骤五:全方位的功能验证与测试
- 测试脚本: 参考 tests/st/python/test_beam.py。
- 测试维度:
功能一致性: 验证 Beam Search 输出结果与预期一致 11。
参数变化: 覆盖不同温度(Temperature)、长度惩罚(Length Penalty)下的生成效果。
Batch 处理: 验证在 Batch Size 为 4/8 下的稳定性与正确性。
Beam Width 对比: 测试 Beam Width 为 2、4、8 时的性能表现。
3、核心贡献
- 功能实现: 在 vLLM-MindSpore 中完整实现了 Beam Search 解码算法。
- 性能突破:
- 推理吞吐量(Throughput)从 84.2 tokens/s 提升至 91.1 tokens/s(提升约 8.2%)。
- 引擎初始化时间从 29.92秒缩短至 22.70秒(提升约 24.1%)。
- 代码合入: 核心代码及测试用例已提交至社区 PR #1084 。
# 03
攻克技术难关:从环境配置到算法优化
难题一:环境配置与版本依赖的“隐形坑”
**问题描述:**项目初期严格按照文档搭建环境,却频繁报错,无法启动最基础的推理服务。这严重挤占了开发排期,让我一度陷入自我怀疑。
**探索过程:**我尝试了手动源码编译、更换 Python 版本等多种常规方法,但均未奏效。
**最终方案:**没有继续“闭门造车”,而是选择加入 SIG 组向项目组的前辈咨询。经沟通得知,是当时文档中的 MindSpore 版本号未及时更新以适配 vllm_mindspore。这次经历让我深刻意识到:做开源项目,及时沟通比独自死磕更重要。
难题二:vLLM 原生采样逻辑的深入分析与优化
**问题描述:**在实现核心的 _greedy_sample 和 _get_ranks 函数时,我并没有简单地翻译 PyTorch 代码。通过深入阅读源码,我发现 vLLM 原生的 _get_ranks 实现存在内存冗余——它在计算 logprobs 时会创建一个与 vals 等大小的 N 中间张量,这在 NPU 上会带来不必要的显存开销。
探索过程:
- 源码定位: 我深入分析了 model_executor/layers/sampler.py,理清了数据在 gather 操作前后的维度变化。
- 逻辑推演: 我思考能否利用广播机制来替代显式的中间张量创建,从而减少内存占用。
最终方案:
- 代****码重构: 我在 MindSpore 中重新实现了 _get_ranks,巧妙结合 gather 和 unsqueeze 操作,直接生成形状为 N, 1 的 chosen_values 张量用于广播比较。
- 效果验证: 这一改动配合对多 Beam 并行采样的支持,不仅确保了功能正确,更在 测试中帮助推理吞吐量提升了约 8.2%。这证明了深入理解原框架逻辑并进行针对性优化,比单纯的代码迁移更有价值。
# 04
开发者说:从学生到开源贡献者
- 是什么机缘让你在开源之夏的诸多项目中选择了昇思MindSpore?在选择项目任务和撰写申请书的时候有哪些考虑和准备?
贾阔源:选择 MindSpore 主要是出于职业规划的考量。我意识到大模型推理优化是未来的关键技术方向,并计划后期向大模型领域转型。恰逢 MindSpore 社区发布了 vLLM-MindSpore 课题,这与我的学习目标高度契合。
在选题上,为了确保能上手,我选择了逻辑相对直观的“Beam Search 采样”作为切入点。在撰写申请书时,我深知一份详实的项目计划书是展示开发者理解程度的关键,因此在提交申请前,我积极浏览了大量网站,查阅了关于 vLLM 技术原理的解读和 Beam Search 算法的详细讲解,为项目的顺利开展做足了理论准备。 - 此次开发工作与你以前的项目开发经历有何不可异同?
贾阔源:最大的不同在于工程规模与代码量级。相比于以往小规模的算法 Demo,vllm-mindspore 是基于业界主流推理引擎 vLLM 的庞大开源项目,代码量十分巨大。
我面临的挑战不再是简单的逻辑实现,而是要深入理解海量源码:不仅要理解 vLLM-MindSpore 的工作机制,更要理清 vLLM 原生 Beam Search 的数据流转链路、组件 API 调用,以及明确 vLLM 与 MindSpore 适配层各自承担的职责边界。在阅读源码和确认“正确”的开发策略上,我花费了比以往任何项目都多的功夫。 - 通过这个项目任务,你对开源有了什么更深刻的理解吗?
贾阔源:我对“聚沙成塔”有了更直观的感受。面对如此庞大的工程项目,我深刻认识到个人开发者的力量往往是薄弱的,它不像简单的算法那样易于独自开发。
开源项目需要开发者们齐心协力,共同维护社区,积极交流。每一位开发者贡献的一行行优雅代码,汇聚起来最终构成了功能齐全、合作共赢的开源项目。这种协作精神是开源社区最宝贵的财富。 - 作为学生参与开源项目,你认为最大的挑战是什么?又是如何克服的?
贾阔源:最大的挑战在于如何驾驭庞大的开源代码库,以及如何制定合适的开发策略。初次面对巨量代码时,很容易迷失方向,难以找到功能缺失的切入点。
克服方法: 我花了大量时间沉下心来认真阅读源码,不再急于求成。同时,我通过不断的测试来验证自己的理解,在测试中查找功能漏洞或不完善的地方,逐步理清逻辑链路,最终将这些理解转化为高质量的 PR 提交。 - 作为过来人,有没有什么话****想对过去的自己/学弟学妹/刚加入昇思MindSpore的开发者说呢?
贾阔源:我想送给大家三个关键词:源码、测试、交流。
认真阅读源码:这是理解大型项目的基石。
多做测试:只有通过不断的测试验证,才能发现潜在的漏洞,确保功能的健壮性。
多交流:开源社区非常友好,多向前辈们请教,能让你少走很多弯路。