开源之夏|方泱泱:基于昇思MindSpore的YOLOv12智能交通分析实践

# 01
项目介绍
- 项目名称:基于昇思MindSpore的YOLOv12实现智能交通分析
- 项目描述:本项目旨在使用昇思MindSpore AI框架复现YOLOv12模型,并构建一套完整的智能交通分析系统,提升在交通场景下的车辆检测性能与系统易用性。
- 项目源码链接:
https://github.com/mindspore-courses/competition/tree/master/summer-ospp
# 02
项目实现思路拆解
1、技术栈与系统架构
前端:HTML + CSS + JavaScript
后端:Python Flask
深度学习框架:昇思MindSpore
整体流程:
- 基于MindSpore YOLO迁移YOLOv12至MindSpore
- 使用COCO数据集训练与验证模型
- 开发交通分析模块(车道检测、车辆处理、流量管理)
- 构建Web可视化界面
2、关键实现步骤详解
步骤一:模型结构梳理与代码分析
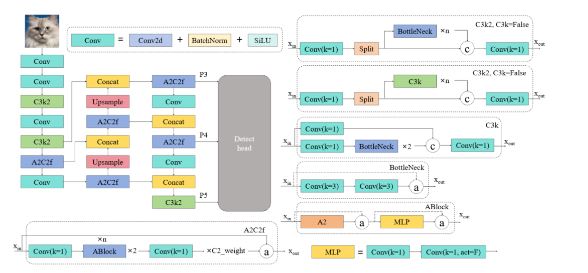
在结构设计上,YOLOv12较YOLOv11进行了重要调整。YOLOv11的骨干网络主要由Conv、C3K2、SPPF和C2PSA模块构成,其中C2PSA包含PSABlock子模块;而YOLOv12则使用A2C2f模块替换了YOLOv11中的部分C3K2模块及SPPF模块,并进一步减少了网络深度。
因此,要在mindyolo中添加上述模块,首先需理清其项目结构。mindyolo目录下主要包含configs、demo、deploy、docs、examples、mindyolo等子文件夹,其中configs和mindyolo是本次迁移的重点:
- configs:存放各模型的配置yaml文件;
- mindyolo:其子文件夹功能如下:
- csrc:COCO数据集处理脚本;
- data:数据集预处理代码;
- models:模型相关文件,包括检测头(heads)、网络层(layers)、损失函数(losses)以及完整的YOLO模型实现;
optim:优化器相关代码;
**utils:****各类工具函数。**
综上分析,本次模型迁移主要需修改configs与mindyolo/models目录下的文件。
步骤二:模型迁移关键步骤
- 配置文件构建:YOLO系列模型通过读取yaml配置文件定义其结构。为此,我们首先基于官方提供的yolov12.yaml以及mindyolo中已有的yolov11-base.yaml,构建出适用于基础结构的yolov12-base.yaml配置文件。进一步地,通过调整模型规模参数,同步生成了对应不同尺寸的yolov12n、yolov12s、yolov12m、yolov12l及yolov12x等系列配置文件。
- 新增模块实现:结合前文对模型结构的分析与ultralytics/nn/modules/block.py的参考,我们确定了需新增的三个核心模块:AAttn、ABlock与A2C2f。这些模块通过在mindyolo/layers/bottleneck.py中参照对应PyTorch代码进行转换与实现,从而完成了其在MindSpore框架下的适配。
- 复用检测头与损失函数:鉴于YOLOv12与YOLOv11在检测头及损失函数的设计上保持一致,本项目直接沿用了mindyolo中现有的yolov11_head.py与yolov11_loss.py实现,无需重复开发。
- 整合构建完整模型:在完成上述模块添加与配置准备后,我们在YOLOv12.py中整合各组件,系统性地构建出完整的YOLOv12模型架构。
- 修改model_factory.py:为确保模型能够正确解析yaml配置文件中的新模块,最后一步需在model_factory.py的parse_model函数中加入新增的AAttn、ABlock与A2C2f模块,从而使模型构建流程能识别并调用这些网络层。
步骤三:推理训练与性能验证
在完成模型迁移后,我们对其进行了完整的推理训练与性能验证。具体流程如下:
首先,对修改后的模型执行推理测试,以验证模块添加与配置文件修改的正确性,相关测试代码已通过运行验证。
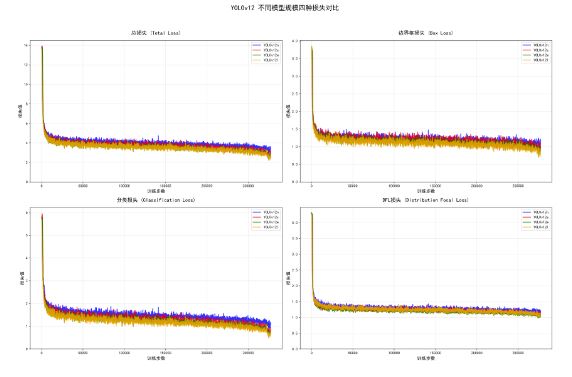
随后,采用YOLOv12论文中发布的超参数进行模型训练。训练损失曲线显示,经过600轮迭代后,各模型均趋于收敛,表明训练过程稳定有效。
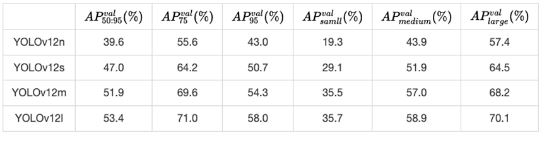
最后,基于训练所得的权重文件,我们在COCO验证集上进行了系统性能评估。实验设置保持一致:输入图像分辨率为640×640,批大小为32。不同规模的YOLOv12模型在该设置下的验证结果如下表所示,其精度与论文报告的性能基本一致,验证了迁移实现的有效性。
步骤四:智能交通分析应用模块开发
LaneDetector类:该类负责车道的定义、检测与分析功能,支持从JSON配置文件加载多边形车道区域,并自适应不同分辨率的视频输入。通过几何计算判定车辆所属车道,实时维护各车道的车辆数量与平均速度等统计信息,并基于此动态评估拥堵等级(正常/中度/严重)。其设计具备两项亮点:一是支持对应急车道等进行特殊标记,二是在配置文件缺失时可自动生成默认车道布局,提升了系统的灵活性与实用性。

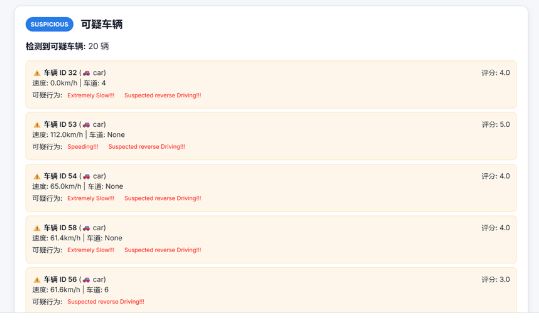
LaneVehicleProcessor类:作为系统的核心处理模块,此类集成了YOLO目标检测与ByteTrack多目标跟踪算法,逐帧处理视频并输出分析结果。它能够持续追踪车辆ID、类型、位置历史与实时速度,检测违规占用应急车道等行为,并对可疑车辆进行专门跟踪。所有分析结果均实时可视化叠加在视频帧上。该类的设计注重车辆状态的时序连续性,依托轨迹历史准确估算车速,同时生成包含统计数据和预警信息的完整输出,实现了从原始视频到结构化交通分析的全流程处理。
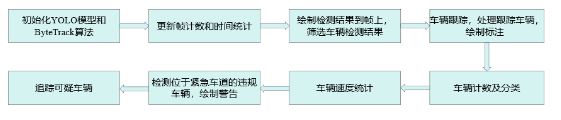
TrafficFlowManager类:该类专注于交通流量的监控与分析。其通过在每条车道设置入口与出口区域,实现对车辆完整行驶轨迹的追踪。功能上可精确记录车辆进出时间、计算行程时间、结合车道类型与实时路况估算车速,并自动判定流量等级(低/中/高)。同时,该类提供丰富的可视化支持,包括标记出入区域、实时显示流量统计、以及用颜色编码直观反映交通状况,并能生成详细的分析报告。该系统尤其适用于高速公路监控、城市交通管理与应急响应等场景,为决策提供数据支撑。

步骤五:Web界面与功能测试
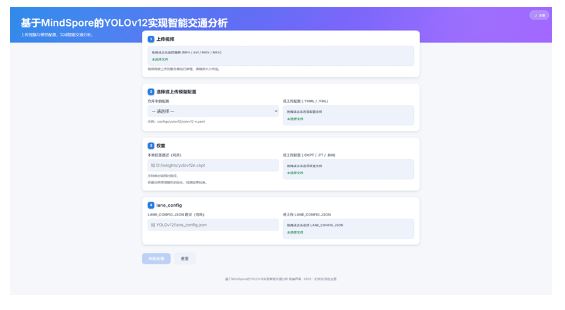
为直观展示智能交通分析功能,项目采用前后端分离架构开发了Web交互界面:前端基于HTML/CSS/JavaScript实现,后端使用Python Flask框架构建。系统主要包含两个核心界面:
视频上传与参数配置界面:用户可在此上传待分析的视频文件,并灵活选择模型配置文件(YAML)、权重文件以及预定义的车道配置(JSON),完成设置后提交至后端进行推理分析。
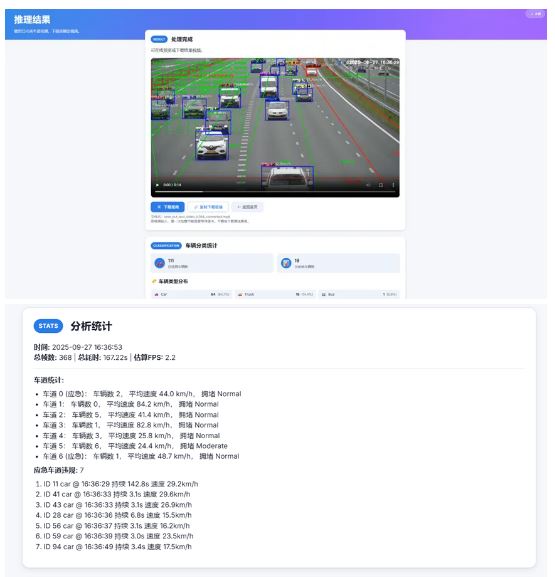
检测结果展示界面:该界面呈现分析处理后的视频结果,支持视频在线播放、下载及下载链接复制。同时,页面还提供结构化的数据分析面板,包括车辆类型统计、车道流量统计与可疑车辆追踪列表等多项信息,全面展示交通分析结果。
# 03
开发者说:关于开源、成长与选择
- 是什么机缘让你在开源之夏的诸多项目中选择了昇思MindSpore?在选择项目任务和撰写申请书的时候有哪些考虑和准备?
方泱泱:主要是在实验室师兄和老师的推荐下开始了解昇思MindSpore。在选择具体项目时,我特别看重与自身研究方向的契合度。“基于昇思MindSpore的YOLOv12实现智能交通分析”这个项目与我的目标检测背景完全匹配,和我以前做过的项目也有相似之处,因此我很快就确定了选题。在写申请书时,我详细梳理了实现思路,也结合以往的项目经验进行了说明,并且积极与导师沟通、反复修改,很幸运最终成功入选。 - 此次开发工作与你以前的项目开发经历有何不可异同?
方泱泱:相同之处在于,都是针对一个具体场景进行开发——以前更多面向建筑场景,这次则是交通场景。不同点则比较明显:首先,项目面向的对象不同,以前主要是个人或课程需求,而这次是面向整个开源社区,代码和文档都需要更强的可读性和复用性;其次,这次的项目要求更完整,不是仅仅实现一个演示原型,而是要构建一个真正可运行、可使用的系统,对工程化和实用性的要求更高。 - 通过这个项目任务,你对开源有了什么更深刻的理解吗?
方泱泱:有的,我的理解更加聚焦和深入了。我过去可能觉得开源主要就是“代码公开”,但现在我认识到,开源更核心的是“协作共建”,是集体智慧的流动与沉淀。另外,开源看似自由,实则对开发者提出了更高的责任要求——你写的代码不能只让自己看懂,还要让社区中不同背景的开发者也能理解和使用。比如我在写项目README时,就反复修改,希望即使是一个新手也能顺利复现整个过程。 - 作为学生参与开源项目,你认为最大的挑战是什么?又是如何克服的?
方泱泱:我觉得主要挑战有两方面:一是技术栈的断层,学校课程的知识体系和真实项目所用的技术栈往往有差距,需要自己快速补课;二是理解开源项目代码的系统性障碍,它不像教科书有标准答案,需要自己通过文档、提交历史、测试用例去反推逻辑。我的应对方法是:保持耐心,系统阅读官方文档,善用社区论坛提问,并且从小处着手,在行动中逐步构建认知,而不是试图一下子读懂所有源码。
- 作为过来人,有没有什么话想对过去的自己/学弟学妹/刚加入昇思MindSpore的开发者说呢?
方泱泱:我想分享三点:第一,可以通过对比学习快速上手,比如我是通过对比PyTorch和MindSpore的API差异来入门的;第二,放弃“准备好再开始”的完美主义,开源参与可以从修改文档、修复一个简单BUG开始,在动手的过程中学习,效率更高;第三,学会聪明地提问,描述问题时尽量附上代码片段、环境信息和已尝试的方法,这样更容易获得有效的帮助。