昇思创新训练营优秀创新案例系列分享第二期:基于 MindSpore 微调大模型的智能旅游助手
昇思创新训练营优秀创新案例系列分享第二期:基于 MindSpore 微调大模型的智能旅游助手
1、前言
昇思MindSpore作为开源的AI框架,为开发人员带来端边云全场景协同、极简开发、极致性能的体验。为鼓励基于昇思MindSpore进行创新,昇思开源社区对昇思创新训练营优秀创新案例进行转载及解读。本篇文章主要介绍了开发者如何基于昇思MindSpore进行大模型微调及使用RAG技术,完成一个能够为游客提供个性化旅游信息的智能助手的全流程实践。项目代码已开源,欢迎各位开发者体验。
2、项目意义和价值
当前旅游信息普遍存在分散化、真伪难辨等问题,难以满足游客日益多元和细分的需求。同时,景点信息具有高度动态性,依赖人工采集,维护成本高昂、效率低下。在旅游高峰期,服务人员短缺导致游客咨询响应滞后,严重影响服务体验。
本项目旨在构建高效、可信的智能旅游信息服务体系,帮助游客快速获取精准、实时的旅游信息,显著缩短行程规划时间,提升出行决策效率。通过智能化服务手段,有效缓解景区旺季人工咨询压力,提升高峰期的服务承载能力与响应速度,保障游客体验。
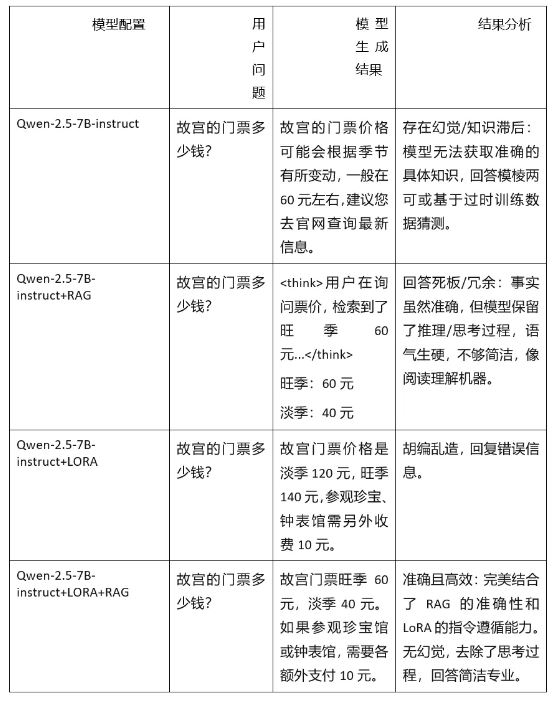
实验对比显示,原生及仅微调模型均受限于知识滞后或严重幻觉,无法准确回答具体信息;“原生+RAG”虽能修正事实错误但回复机械生硬。相比之下,最终的“微调+RAG”方案效果最佳,完美结合了知识库的准确性与微调的自然对话风格,实现了无幻觉、简洁高效的精准问答。
- 项目名称:基于 昇思MindSpore 微调大模型的智能旅游助手
- 团队成员:郭琳琳、李绍毅、王梦莹
- 项目代码链接: https://github.com/MUMU46/Travel-Assistant-based-on-mindspore
效果展示
项目方案介绍
1、方案流程设计
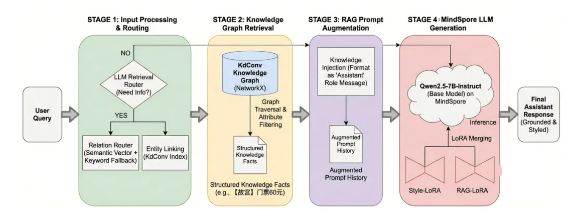
- **数据准备:**基于 KdConv数据集构建旅游问答指令数据与知识库。
- **模型微调:**采用 MindSpore框架 + MindSpore NLP 套件,对 Qwen-2.5-7B-Instruct 模型进行 LoRA 微调。
- **知识增强:**结合 RAG 框架接入旅游景点知识库,减少幻觉。
- 应用交互:支持游客与模型进行多轮对话,获取个性化旅游攻略。
2、模型微调模块架构解析
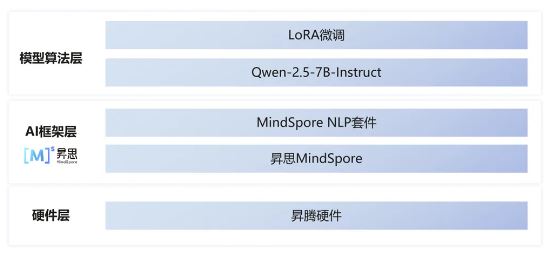
模型微调模块是基于MindSpore进行了模型微调后,使得模型具备旅游景点知识问答的能力,在此着重介绍下在模型微调模块的架构。
- 硬件层:依托华为云ModelArts平台昇腾算力。
- AI框架层:昇思MindSpore框架提供了函数式+面向对象融合编程、动静统一、高效数据引擎、自动并行等能力, MindSpore NLP套件将这些优势特性与实际需求匹配,实现简便的模型开发,高效的数据预处理,以及预训练模型的快速调用。
- 模型算法层:通过MindSpore NLP套件调用Qwen-2.5-7B-instruct模型,并基于标注好的旅游景点知识实现LoRA微调。
运行指南
1、环境准备

2、数据集准备
本项目从 KdConv数据集提取实体与属性构建知识库,并构建问答指令数据集用于 LoRA 微调:
将原始训练数据转换为{instruction, input, output}格式。
样本格式:{
"instruction": "... 指令提示词 ...",
"input": "... 背景知识 + 用户问题 ...",
"output": "... assistant 回答 ..."
}
# input_file: 输入数据路径,默认为”./train.json”
# output_file:预处理后数据保存路径,默认为”./train_data.jsonl”
cd data_preprocess
python data_pre.py --input_file xxx --output_file xxx
3、模型微调
# model_path:模型名称或预训练权重路径
# data_file:标注数据路径
# output_dir:微调后LoRA Adapter权重保存路径
python train_qwen.py --model_path xxx --data_file xxx --output_dir xxx
4、RAG检索增强
# model_path: 使用的模型名路径
# lora_path:lora微调权重文件路径
# knowledge_file:知识库文件路径
python main.py --model_path xxx --lora_path xxx --knowledge_file xxx
项目实现代码详情
1、数据预处理
采用THUCNews(清华大学中文新闻数据集)作为原始语料库,保障了数据的规模、多样性和高质量。,并利用大模型对更大规模的新闻高效率情感标注(推荐使用deepseek的api)。
- 把 train.json 的每个实体(name)与 messages 中的 attrs(attrname/attrvalue)抽取成知识图谱三元组。
- 把对话轮次转换为模型训练用的 jsonl:{instruction, input, output} 格式(input 包含 knowledge + history,output 为 assistant 回复)。

2、模型微调(train_qwen.py)
参数设置 epoch=5,batch_size=4,learning_rate=5e-5;LoRA 配置 rank=8,dropout=0.1,lora_alpha=32。
3、RAG 检索增强(main.py,graph_rag.py)
1)构建知识图谱
使用 NetworkX 构建轻量级知识图谱(KG),其中每条知识表示为三元组:
构建流程如下:
- 遍历 train.json 中的全部实体
- 对 messages 中每条 attrs 创建图谱节点与边
- 缓存构建好的图谱,避免重复构建开销
2)实体检索与关系检索设计
用户输入示例:
“北京石刻艺术博物馆几点开放?”
该问题包含:
**实体元素:**北京石刻艺术博物馆
**关系元素:**开放、几点
本项目实现了关系词典 Router(Rule-based Router):
RELATION_KEYWORDS = {
"门票": "门票", "票价", "多少钱", "价格",
"开放时间": "开放", "几点", "时间",
"Information": "介绍", "简介"
}
基于词匹配可以快速确定:
实体 → “北京石刻艺术博物馆”
关系 → “开放时间”
再从图谱中匹配实体邻居节点即可获取对应属性。
同时传统关系词典也存在以下问题:
- 无法覆盖用户多样化表达
- 新关系无法自动扩展
- 无法适配复杂语义近似(如“要不要买票” ≈ “门票”)
因此再结合使用 MiniLM 句向量模型实现高质量语义匹配:
def build_relation_index(relations: dict, embedder: RelationEmbedder,
index_file=INDEX_FILE, meta_file=META_FILE, emb_npy=EMB_NPY)
3)Graph RAG 检索流程
关系向量路由器与实体–关系图谱共同组成了完整 RAG。
- 用户 query 的检索逻辑如下:
- 使用实体词典抽取 query 实体
- 使用 Relation Embedding Router 输出最接近的关系
- 若实体与关系均存在 → 图谱精确检索
- 若仅存在实体 → 返回该实体常见属性(Information、门票、开放时间等)
- 若均无 → 返回空
4)RAG LLM 生成回答
系统提供prompt:
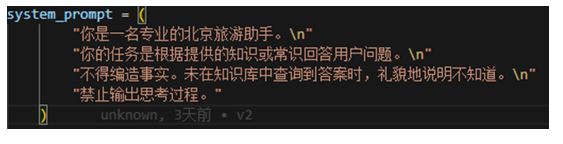
检索前还会进行是否需要检索的判断:
让LLM自己判断用户的该问题是否需要检索。Prompt如下:

项目总结
项目基于MindSpore构建智能旅游助手,实现了多轮对话与精准景点问答,具备RAG增强检索与高效LoRA微调能力,实现了 RAG + LoRA 技术路径的完整落地,预期可提升游客自助服务体验,为智慧旅游提供轻量化、可落地的AI解决方案。
通过构建这个“北京旅游咨询助手”,不仅掌握了工具的使用,更在全栈大模型应用开发上有了质的提升。项目涵盖了从 数据清洗与构造、模型微调(LoRA 训练)、到 推理服务的完整闭环。深刻理解了数据质量对模型效果的决定性作用,以及如何通过微调让通用大模型“学会”特定领域的说话风格(如导游风格)。
通过这次实战,验证了在昇腾硬件(Ascend)和昇思MindSpore AI框架上进行前沿大模型开发是完全可行的。在当前大环境下,掌握 AI 基础设施的开发能力是一项非常有竞争力的技能。
在本项目中,使用了MindSpore NLP 库对 Qwen2.5-7B 模型进行LoRA 微调与推理部署。整个过程有助于深化对 AI 框架的理解,主要体会有以下几点:
- 极低的迁移成本 (MindSpore NLP 的易用性),完全兼容了Hugging Face 的 transformers 库。
- 代码风格熟悉:在 train_qwen.py 中,像 AutoTokenizer, AutoModelForCausalLM, TrainingArguments, Trainer 这些核心 API 的使用方式几乎与 PyTorch 版本一致。这使得原本熟悉的 PyTorch 开发经验能够快速迁移到 MindSpore 上,极大地降低了学习门槛。
- PEFT兼容:MindSpore NLP 兼容了 PEFT(Parameter-Efficient Fine-Tuning),通过 LoraConfig 和 get_peft_model 几行代码就能实现 LoRA 微调,无需复杂的底层修改。
- 强大的算力支持与显存优化
在未来,希望扩展知识库、集成天气/交通/人流指数等 API,以及进一步引入 RLHF 等策略优化方法,进一步完善优化项目。