开源之夏|侯博森:基于昇思MindSpore的MVSNet跨框架迁移与实践
开源之夏|侯博森:基于昇思MindSpore的MVSNet跨框架迁移与实践

# 01
项目介绍
- 项目名称:基于MindSpore和多视角立体匹配技术的稠密重建模型
- 项目描述:本项目旨在将经典的多视角立体匹配模型 MVSNet 从 PyTorch 框架迁移至昇思MindSpore AI框架,实现完整的训练与推理部署功能,为昇思在三维重建领域提供新的解决方案,在计算机视觉领域的应用提供技术支撑。
- 项目源码链接:https://github.com/mindspore-courses/competition/tree/master/summer-ospp/MVSNet_MindSpore
# 02
MVSNet迁移思路拆解
1、架构分析与技术选型:
项目首先对 PyTorch 版 MVSNet 的核心模块,包括特征提取、代价体构建、正则化网络、深度回归等模块进行结构拆解与逻辑分析,梳理数据流向与依赖关系,针对 MindSpore 的 API 特性,对 PyTorch 特有操作进行等效替换,重构数据加载与预处理流程。
分步实现各功能模块的 MindSpore 适配,MVSNet的核心模块对标。
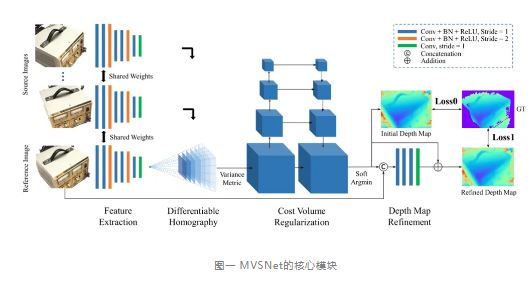
如上图,MVSNet的核心模块包括特征提取,代价体构建,正则话网络,深度回归等模块,该网络的输入是参考视角和源视角的图像和相机内外参数,输出是参考视角的深度图。在生成完所有参考视角深度图之后,方法将所有深度图融合为点云。
2、核心实现步骤:
步骤一:源码解读与数据准备
深入研读 PyTorch 版 MVSNet 源码,梳理网络结构、数据格式要求及训练流程逻辑,同时下载 DTU、TanksAndTemples 数据集,明确数据组织形式与读写需求。
步骤二: 数据加载模块适配
针对 MindSpore 不直接支持字典返回的特性,设计数据类型转换方案,将字典格式数据显式转为 NumPy 数组,通过 GeneratorDataset 指定数据名称,完成 DTU、TanksAndTemples 数据集的 MindSpore 适配。编写数据加载测试代码,验证数据读取的完整性与正确性。
步骤三: 核心模块迁移与单元测试
依次迁移每一个核心模块:
- 特征提取网络:基于 MindSpore 的 nn.Conv2d、nn.ReLU 等算子,实现 8 层共享参数 CNN 的等效迁移,确保输出 32 通道特征图;
- 代价体构建模块:通过 MindSpore 的矩阵运算 API 实现可微分单应性变换,完成视锥体采样与特征体构造,基于方差运算生成代价体;
- 正则化网络与深度回归:用 MindSpore 的 nn.Conv3d 实现 3D U-Net 正则化模块,通过 Softmax 与 Soft argmin 完成深度概率图生成与初始深度图计算,适配深度图优化的残差学习逻辑。
每个模块在迁移的时候需要对照API对照表进行一一对比,包括CNN的默认参数也需要确认是否一致,否则会对模型的效果产生很大的影响。完成任何一个模块,都要单独拿出来进行测试:给PyTorch和MindSpore的模块同时输入完全相同的数据,测试前向传播的结果是否一致。
步骤四: 整体训练与性能评估
训练转化完的模型并进行 DTU 数据集的测试,编写 eval.sh 评估脚本,支持深度图生成、点云融合与量化指标计算,与 PyTorch 版 MVSNet 在 DTU 数据集上进行性能对标,验证迁移模型的准确性。

# 03
跨框架迁移的挑战:问题定位与解决策略
PyTorch 与 MindSpore 数据集格式不兼容
PyTorch 的 Dataloader 返回字典格式数据,包含图像、相机参数等多类型信息,但 MindSpore 的 GeneratorDataset 不直接支持字典返回,且 DTU 数据集需要返回字符串、字典等格式数据,无法直接适配。
- 探索过程: 最初尝试直接复用 PyTorch 的数据读取逻辑,但运行时出现数据类型不匹配报错;随后尝试在 Dataloader 中直接转换数据类型,但导致部分相机参数信息丢失。
- 最终方案: 首先解析 PyTorch 字典中的各字段数据,将字符串类型参数转为 NumPy 数组,图像数据保持张量格式并兼容 MindSpore 要求;然后通过 GeneratorDataset 的 column_names 参数指定每个返回数据的名称,确保数据与网络输入接口对齐,这个其实是两个框架的特性区别,只需要稍微修改返回信息的逻辑即可。
# 04
关于开源、成长与选择
- 是什么机缘让你在开源之夏的诸多项目中选择了昇思MindSpore?
侯博森:一方面,昇思MindSpore 在性能优化、易用性上有着独特优势,且在三维视觉领域的生态建设仍有较大空间,希望通过自己的努力为昇思框架贡献力量;另一方面,MVSNet 作为三维重建领域的经典模型,其迁移工作具有明确的应用价值,能够为后续相关研究提供基础。除此之外,之前有一个工作叫做EPP-MVSNet,是基于MindSpore架构的多视角立体匹配网络,是昇思MindSpore团队已经发表在ICCV上的论文,在早些时候我注意到了这篇论文,但是因为当时对MindSpore并不熟悉所以没仔细研究,我作为三维视觉为研究方向的研究生,这一次刚好借这个机会仔细研究了一下。
- 这次跨框架迁移的经历,和你以前项目相比,感觉最大的不同是什么?
侯博森:这次经历与我过去的项目有着根本性的不同,核心在于这是一项专门的“跨框架迁移”工作。以往在单一框架内开发时,我主要专注于算法实现本身;而这次的核心任务,则是深入理解两个框架的设计逻辑,并系统性地解决它们在API接口、数据格式与算子行为上的兼容性问题。例如,我需要为PyTorch中的grid_sample等操作找到MindSpore中的功能等效实现,并为此自主整理了详细的API映射表。这也改变了我的工作方式:通用AI工具的辅助作用变得有限,更多时候需要我深入查阅官方文档、在社区中寻找线索并进行自主调试;同时,解决问题的途径也从依赖团队内部经验,转变为积极地从MindSpore开源社区中获取支持并与广大开发者交流。整个过程更像是一次深度的框架原理探索与实践,让我对如何在不同技术生态间进行转换和适配有了全新的认识。
- 在这个过程中,你对“开源”这个词的理解,有没有发生一些变化?
侯博森:有的,变化很大。以前觉得开源主要就是“把代码公开”。亲身参与后才真正感受到,它的核心在于“协作”与“共享”。我不是一个人在战斗,项目过程中我大量参考了社区的文档、示例代码,遇到棘手问题时会去论坛搜索,也和导师、其他开发者交流。同时,我也努力让自己的工作能更好地被他人使用,比如写清晰的注释、整理完整的文档。我的代码和经验以后也能帮助其他人,这种双向的、持续的价值流动,才是开源生态最有活力的地方。
- 对于未来也想参与开源,参与昇思MindSpore的学弟学妹,你有什么建议吗?
侯博森:我有几点比较深的体会。第一,别过度依赖“万能”的AI工具,沉下心阅读官方文档、教程是第一位的。第二,培养自主排查问题的能力,遇到报错先别慌,尝试用打印日志、写小单元测试等方式缩小范围,这个过程本身就是极好的学习。第三,勇敢且礼貌地利用社区,论坛、Issue列表、技术群都是宝库,但提问前最好先搜索,提问时把背景、现象、自己试过的方法说清楚。最后,要有“代码即文档”的意识,你写的清晰结构和注释,你整理的README,就是对下一位开发者最好的帮助。当你解决的问题和积累的经验能够回馈社区时,那种成就感远超单纯完成一个项目。