论文精讲 | ACMMM 2022|FSFL-小样本的模型无关联邦学习
论文精讲 | ACMMM 2022|FSFL-小样本的模型无关联邦学习

作者:官晓柳 |单位:武汉大学计算机学院
联邦学习因其不泄露隐私的协作学习能力而受到越来越多的关注。在参与者共享相同的模型结构的假设下,已经取得了令人鼓舞的进展。然而,当参与者独立地定制他们的模型时,模型就会出现通信障碍,这导致了模型的异构问题。此外,在实际场景中,参与者拥有的数据往往是有限的,使得仅在私人数据上训练的本地模型呈现出糟糕的性能。
因此,本文研究了一个新颖且颇具挑战性的问题,小样本的模型无关联邦学习,即FSFL(Few-Shot Model Agnostic Federated Learning),其中当地参与者从有限的私人数据集中设计他们的独立模型。考虑到私人的稀缺性数据,作者利用丰富的公共可用数据集弥合本地私人参与者之间的差距。
作者在联邦学习的标准基准数据集上验证了他的方法,并展示了它与以前的联邦学习方法如FedMD,FML,RCFL等相比的有效性。尤其是当公共数据集和私有数据集之间存在较大的域差距时,其方法显示出很强的鲁棒性。

论文标题:Few-Shot Model Agnostic Federated Learning
论文来源:ACMMM 2022
论文链接:https://dl.acm.org/doi/pdf/10.1145/3503161.3548764
代码链接:https://gitee.com/mindspore/contrib/tree/master/papers/FSMAFL
01 介绍
传统的联邦学习中主要有FedAvg,FedMD, FML等方法,但是存在的缺点是面临数据集之间的小域差距,它们不能保证令人满意的性能。在域自适应中,方法假设数据集集中在一方或多方上,不考虑数据隐私,这限制了对联邦学习系统的适用性,同时现有方法需要共享相同的模型结构。而这里提出的工作是第一个用于模型无关联邦学习设置的联邦学习域适应框架,尤其是在大的域差距条件下,而不需要大规模的数据收集。
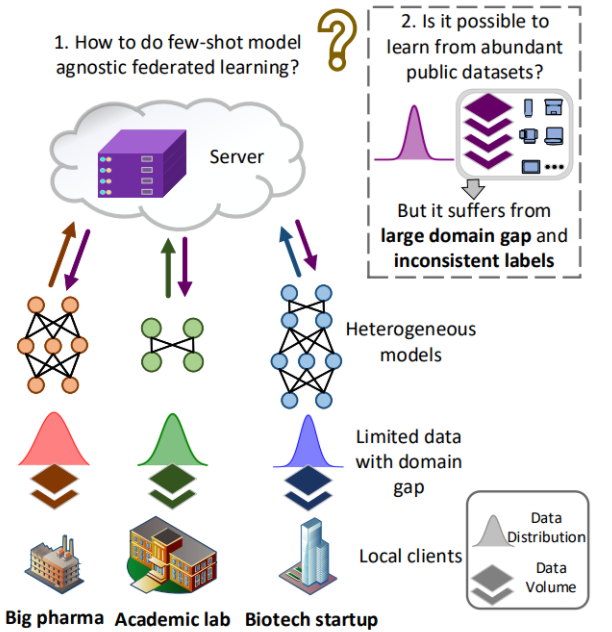
图1:展示了本地客户有限的训练数据,参与者独立设计他们的模型结构,以及利用丰富的公共数据进行模型通信但存在较大的域差距和标签的不一致问题
在这篇文章中,作者提出了如下的背景假设:在联邦学习过程中有K个参与者。每个私有数据集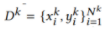 非常小,并且有一个大型公共数据集
非常小,并且有一个大型公共数据集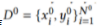 ,每个参与者都可以随时访问。此外,
,每个参与者都可以随时访问。此外, 代表数据集的图像和标签。对于第K个参与者的私有模型定义为
代表数据集的图像和标签。对于第K个参与者的私有模型定义为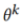 。因此,对于分类任务,我们可以将参与者模型解构为模型主干
。因此,对于分类任务,我们可以将参与者模型解构为模型主干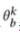 和样本分类器
和样本分类器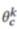 。
。
此外,参与者可以选择设计自己的模型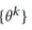 ,这意味着参与者不需要共享相同的模型架构。因此,模型主干的结构不同,相应的样本分类器也不同。此外,小样本模型无关联邦学习的目标是通过标签和域差距不一致的公共数据集向其他参与者学习来提高参与者模型
,这意味着参与者不需要共享相同的模型架构。因此,模型主干的结构不同,相应的样本分类器也不同。此外,小样本模型无关联邦学习的目标是通过标签和域差距不一致的公共数据集向其他参与者学习来提高参与者模型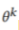 的性能。
的性能。
每个参与者模型首先对公共数据集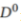 进行训练,然后对每个私人数据集
进行训练,然后对每个私人数据集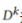 进行训练。作者为解决以上问题而提出的学习流程主要分为两个部分:
进行训练。作者为解决以上问题而提出的学习流程主要分为两个部分:
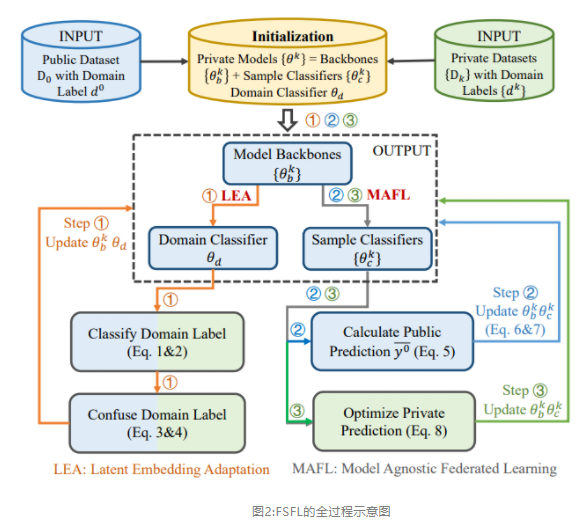
·LEA:潜在嵌入式适应,缩小公共与私有数据集的domain gap(2.1)
·MAFL:通过统一在共享的公共数据集上的模型预测输出来进行公私通信(2.2)
02 方法
2.1 Latent Embedding Adaptation(LEA)
我们设置了公共数据集域标签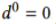 ,第K个参与者数据集被定义为域标签
,第K个参与者数据集被定义为域标签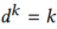 。
。
由于公共数据集的规模比私有数据集要大得多,这将导致公共数据集域和私有数据集域的样本规模不平衡。因此,公共数据集的数量被设置为与私有数据集相同,定义 。第一步中,
。第一步中,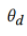 需要识别正确的数据和域标签之间的关系,其优化目标如下:
需要识别正确的数据和域标签之间的关系,其优化目标如下:
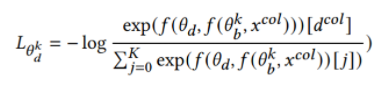
其中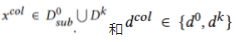 ,
,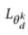 是域分类器
是域分类器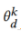 与第k个参与者
与第k个参与者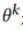 之间的损失,之后根据每个参与者更新后的模型进行平均参数操作,
之间的损失,之后根据每个参与者更新后的模型进行平均参数操作,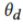 的更新如下:
的更新如下:
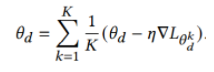
第二步,设置比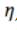 小的
小的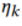 ,这样
,这样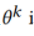 能够在保持原始识别能力的同时对齐两个数据集的特征,同时由于存在多域标签,在参与者模型更新中我们选择直接交换标签,因此
能够在保持原始识别能力的同时对齐两个数据集的特征,同时由于存在多域标签,在参与者模型更新中我们选择直接交换标签,因此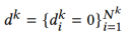 ,
,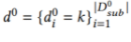 ,即
,即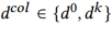 。第K个参与者模型骨干
。第K个参与者模型骨干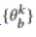 的目标如下:
的目标如下:
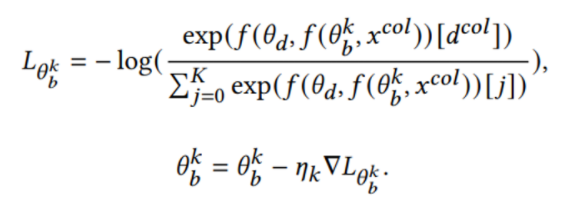
为了加强域分类器的能力,并调整公共和私有数据集之间的域差距,循环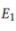 这一过程。
这一过程。
MindSpore代码实现LEA:

首先训练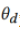 对数据域标签进行正确分类,然后更新私有模型
对数据域标签进行正确分类,然后更新私有模型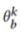 ,通过反转数据域标签和最小化域分类损失来混淆域标识符
,通过反转数据域标签和最小化域分类损失来混淆域标识符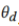 。
。
2.2 Model Agnostic Federated Learning(MAFL)
在模型异构联合学习中,参与者不能通过更新参数或梯度来优化模型,而是通过使用公共数据集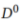 进行协同更新,每个模型
进行协同更新,每个模型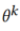 在公共数据集
在公共数据集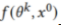 上共享预测,并计算每个参与者的平均预测作为以后更新的标签,计算如下:
上共享预测,并计算每个参与者的平均预测作为以后更新的标签,计算如下:
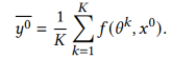
由于通信成本和复杂性,我们只使用了公共数据集的一部分,定义为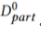 。因此,
。因此,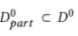 和
和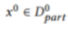 。然后,每个模型
。然后,每个模型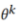 进行更新,并对
进行更新,并对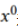 进行预测,以收敛平均预测
进行预测,以收敛平均预测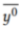 。
。
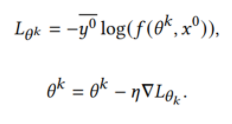
每个模型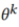 在私有数据集
在私有数据集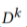 上训练
上训练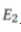 个epochs。在模型无关的联邦学习之后,参与者模型合并了从其他模型中学习到的知识,然后在他们的私有数据集上进行训练,以获得更好的性能。每个模型
个epochs。在模型无关的联邦学习之后,参与者模型合并了从其他模型中学习到的知识,然后在他们的私有数据集上进行训练,以获得更好的性能。每个模型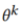 的目标如下:
的目标如下:
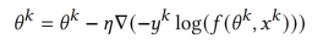
MindSpore代码实现MAFL:

私有模型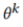 对公共数据集
对公共数据集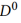 进行预测,得到平均预测
进行预测,得到平均预测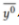 作为收敛目标进行优化,接下来,私有模型
作为收敛目标进行优化,接下来,私有模型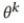 更新私有数据集
更新私有数据集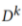 ,以平衡从他人和自身学到的知识。
,以平衡从他人和自身学到的知识。
2.3 学习流程
03 实验结果
这里展示了主要实验成果和数据,更多任务和实验消除分析的细节请参见论文。
3.1 与state of the art方法的比较实验
准确度(%)是基于EMNIST-Letter数据集。初始表示只做初始化,没有联邦学习过程:
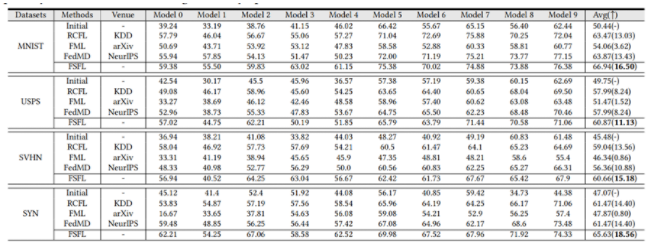
比较发现,与其他方法相比,我们的方法的性能最好。特别是在SYN数据集中,平均精度更新达到18.56%。
3.2 对公共数据库规模的敏感性实验
黄色、紫色和粉色实线代表了潜在嵌入自适应中公共和私人数据集从1到3的比例。嵌入式图表示公共数据集和私有数据集之间的差异:
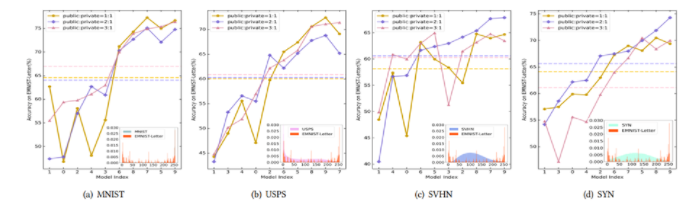
通过观察,MNIST、USPS、SYN和SVHN最适合的规模是公有数据集是私有数据集的3、3、2、2倍。作者想指出的是,当公共数据集的规模与私有数据集相同时,性能的改进是有限的。这是因为更大规模的公共数据集意味着模型可以更好地从模型无关联邦学习中学习。但是,大规模的公共数据集使得模型更难适应私有数据集。
3.3 对私有数据集规模的敏感性的实验
蓝色、绿色和橙色代表不同数量的私有数据集,分别为:72、36和18。虚线表示在不同规模的私有数据集条件下,没有联邦学习过程的初始平均精度。
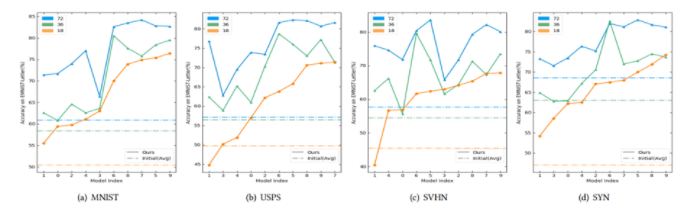
由图中发现我们的框架在不同设置下具有一致的改进,当私有数据集的规模较大时,改进更显著。
04 总结与展望
本文着重研究了一个新颖且颇具有挑战性的问题,小样本模型无关的联邦学习。作者提出了一个有效且创新的框架,具有两个重要的组成部分:模型无关的联邦学习和潜在域适应,它能够同时处理公共和私人数据集之间不一致的标签空间和大的域差距。通过理论泛化边界分析,证明了其框架的成功可行性。
同时作者也在潜在嵌入式适应的公共数据集和私有数据集的规模方面进一步探索了他的框架,显示了稳定的结果。
致谢
本研究成果得到了中国人工智能学会-华为MindSpore学术奖励基金的资助。

MindSpore官方资料
官方QQ群 : 486831414
Gitee : https : //gitee.com/mindspore/mindspore