联邦学习 | 如何在不泄露本地数据的情况下都获得一个有效的模型?
联邦学习 | 如何在不泄露本地数据的情况下都获得一个有效的模型?

作者:AI安全Mr.Jin |来源:知乎
著名杂志《经济学人》刊登过一篇封面文章,将数据比作“新世纪的石油”。毫无疑问,在数字经济时代,能否充分挖掘、使用数据,决定了企业的命运。不论是传统的机器学习,还是当今迅猛发展的人工智能,其核心都是数据驱动。
数据固然是好东西,但很多有价值的数据都涉及个人隐私或者保密协议。早在2018年,欧盟就正式施行了通用数据保护条例GDPR(General Data Protection Regulation)。在2021年7月份,亚马逊就因为违反GDPR条例被罚款7.46亿欧元。除了国外,我国对数据的保护也日益重视,2021年8月20日,第十三届全国人民代表大会常务委员会第三十次会议通过《中华人民共和国个人信息保护法》,这标志着个人数据的保护已经上升到了法律的层面。

《中华人民共和国个人信息保护法》部分
在数据保护条例的约束下,数据流通必然受到限制,从而形成“数据孤岛”现象:许多个人/企业有自己收集的数据,单靠他们本身持有的数据不足以完成一个数据挖掘任务,但他们又不想把自身的数据分享给其它个个体。为了解决数据孤岛难题,学术界和工业界的先驱们提出了多种隐私计算方法,其中就包括联邦学习。
联邦学习的英文是Federated learning,咱先从字面意思猜测一下这是个什么技术。“学习(learning)”,指的就是机器学习了(machine learning),一般是利用一批数据去训练一个模型,使模型对于和训练数据同一类的数据,可以正确地分类或者输出一个数值;“联邦(federated)”,一般指两个以上的个体组成的一个群体。结合起来,就是:很多个体(机器)一起进行的机器学习。为啥要很多人一起来训练一个模型呢?自己训自己的不就行了吗?

网络图片,侵删
对于某些场景来说还真不行。你比如,大家平时聊天都有发一句话跟一个表情的习惯,现在某输入法想给手机用户训练一个表情包推荐模型,也就是你打一句话,系统就给你推荐一个或多个相关的表情包。对于每个人来说,他/她平时使用的表达方式在一段时间内一般是不变的。也就是说,如果每个人的手机基于自己的历史数据去训练一个表情包推荐模型,那么这个模型只能对你经常说的话给出推荐,当你说一些“新语言”的时候,表情包推荐模型可能失效了,那么肿么办呢?你或许会说,那就把很多人的数据放一起训练啊!那我再问一句:你愿意把你的聊天记录发给被人看吗?

网络图片,侵删
于是联邦学习就出现了:每个参与者拥有自己的数据,并且不希望把自己的数据泄露出去,但他们又想共同训练一个好用的模型。最初的联邦学习算法[1]如下:

图1 联邦平均聚合算法[1]
如上图所示,在联邦学习开始前,我们要明确联邦学习过程中的参与方:中心服务器Server和客户端Client。在上面的例子里,一般输入法部署的云服务器就是Server,每个用户的手机就是Client。如图2所示,Server拥有表情包推荐模型(初始模型权重[2]为 w0 ),每个Client拥有自己的本地数据和模型(模型结构与Server的模型结构一致,权重是随机的)。
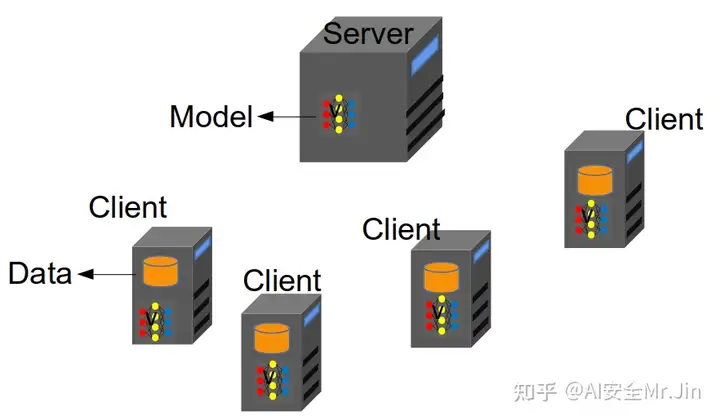
图2 联邦学习参与方组成
接下来开始 t 轮训练,每一轮:Step 1,Server随机从 K 个客户端中选出 St 个,并且把它在这一轮的模型权重 wt (第一轮的模型权重是 w0 )发送给选中的Client:
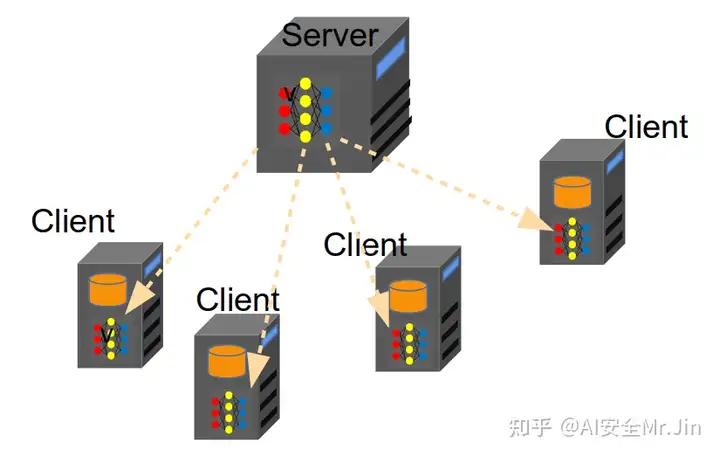
图3 Server下发模型
Step 2,每个被选中的Client把Server下发的模型参数更新到自己本地的模型上,并利用本地数据进行训练(也就是图1的ClientUpdate部分)。训练得到新的模型权重 wt+1k ,并且把 wt+1k 发送给Server:
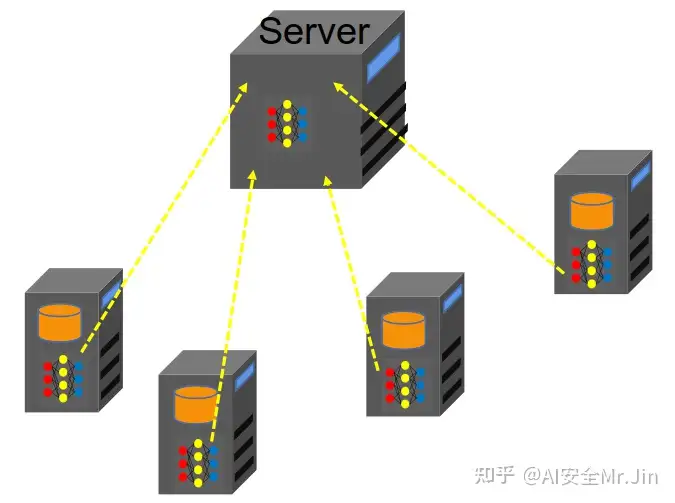
图4 Client回传训练好的模型权重给Server
Step 3,Server接收到每个Client发送的权重后,根据下面的公式进行聚合(图1的求和公式下标 t 应该改为 t ): wt+1=∑k=1Knknwt+1k 其中 nk 是每个客户端训练数据的数量, n=∑k=1Knk 。需要注意的是,对于 k∉St , =wt+1k=wt ;而且在很多场景中,一般是这样计算 wt+1 的(这个问题我在这里做过解释 联邦学习的经典算法FedAvg中,到底是选择所有客户端模型进行聚合,还是仅聚合被选中的客户端模型?): wt+1=∑k∈Stnknwt+1k(n=∑k=1C∗Knk) 接下来,Server会把聚合好的模型 wt+1 下发给所有Client(其实就相当于Step 1的行为):
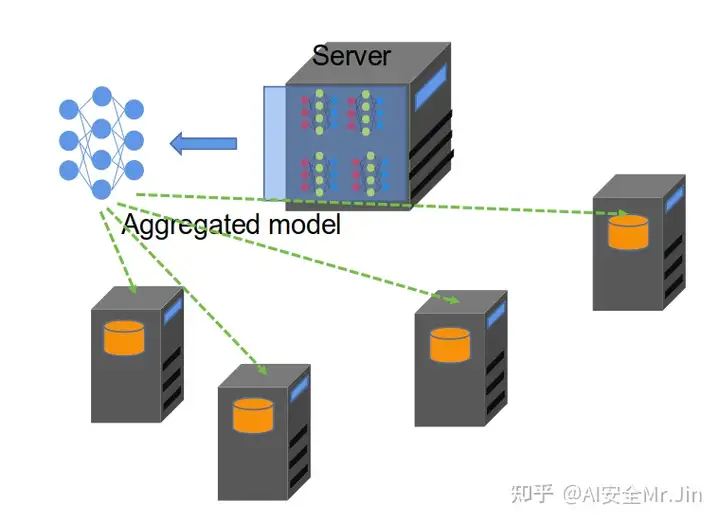
图5 Server下发聚合模型
一般经过多轮迭代之后,聚合模型就能收敛了,于是所有Client在不泄露本地数据的情况下都获得了一个有效的模型。
以上就是联邦学习的基本场景——横向联邦了,除了横向联邦,还有纵向联邦。如果你感兴趣的话,记得点赞转发加关注哦~
敬请期待下一篇~
参考
- 1.Federated Learning of Deep Networks using Model Averaging https://arxiv.org/pdf/1602.05629v1.pdf
- 2.模型权重指的是模型超参的值

MindSpore官方资料
官方QQ群 : 486831414
Gitee : https : //gitee.com/mindspore/mindspore