【MindSpore易点通】通过Print方法保存输出数据
2022/09/22开发者分享
【MindSpore易点通】通过Print方法保存输出数据
背景信息
当开发人员遇到数据量较大的张量或字符串输出时,默认情况下,程序会将输出的数据打印到屏幕上,海量的数据无法用人眼直接识别有价值的数据,此时mindspore.ops.Print方法应运而生,该方法通过context接口中print_file_path参数将其保存在文件中。输出数据将保存在指定路径的文件中。之后可使用mindspore.parse_print()方法加载保存的数据。
一、保存print数据
1、示例代码
import numpy as npimport mindspore.ops as opsfrom mindspore import Tensor, contextfrom mindspore.ops import operations as Pimport mindspore.nn as nnimport mindspore
#保存数据
context.set_context(mode=context.GRAPH_MODE, print_file_path='./save_print_data', device_target="Ascend")
class PrintDemo(nn.Cell):
def __init__(self):
super(PrintDemo, self).__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=4, stride=1 ,has_bias=False, weight_init='normal', pad_mode='valid')
self.conv2 = nn.Conv2d(in_channels=6, out_channels=2, kernel_size=2, pad_mode="valid")
self.conv3 = nn.Conv2d(in_channels=2, out_channels=6, kernel_size=2, pad_mode="valid")
self.print = P.Print()
#打印出每层计算输出结果
def construct(self, input_data):
x = self.conv1(input_data)
self.print('self.conv1', x)
x = self.conv2(x)
self.print('self.conv2', x)
x = self.conv3(x)
self.print('self.conv3', x)
return x
def test():
input_data = Tensor(np.ones([1, 1, 32, 32]), mindspore.float32)
net = PrintDemo()
net(input_data)
return net(input_data)
test()
2、代码解析:context设置
为context.set_context方法添加print_file_path参数来设置保存输出数据的路径:
mindspore.context.set_context(mode=context.GRAPH_MODE,
device_target="Ascend",print_file_path='./xxx_data')
二、解析print数据
1、示例代码
data = mindspore.parse_print('./xxx_data')
for i in range(0,len(data)):
if isinstance(data[i], str):
print(data[i])
continue
else:
tmp = data[i].asnumpy()
data[i] = tmp
print(data)
2、代码解析
mindspore.ops.Print方法所保存的数据为二进制文件,不便于开发人员使用,故需要进一步的文件解析。在mindspore中提供了该文件的解析方法如下所示:
data = mindspore.parse_print('./xxx_data')
此时该文件解析后的数据格式为:list['输入名称(str)', Tensor],示例代码运行的结果如下所示:
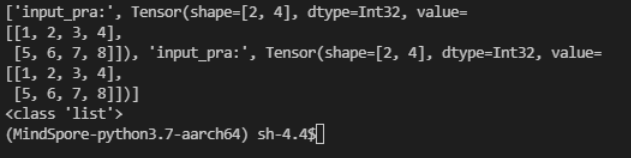
由于输入将转变为Tensor数据类型输出,不便于开发人员进行数据计算操作,故对此数据类型转换为numpy数据类型:
data = mindspore.parse_print('./xxx.data')for i in range(0,len(data)):
if isinstance(data[i], str):
print(data[i])
continue
else:
tmp = data[i].asnumpy()
data[i] = tmp
print(data)