【MindSpore易点通】如何将MindSpore单机单卡代码拓展为分布式代码
【MindSpore易点通】如何将MindSpore单机单卡代码拓展为分布式代码
本文介绍如何将MindSpore单机单卡代码拓展为分布式代码,并在Ascend芯片上实现单机多卡训练。
一、配置运行信息和并行模式
在训练代码中添加如下接口,分别配置运行信息和并行模式,并依次调用。
1.get_rank:获取当前设备在集群中的ID;
2.get_group_size:获取集群总数;
3.context.set_context:配置当前执行环境;
4.init:使能分布式通信,并完成相关初始化操作;
5.context.set_auto_parallel_context:设置自动并行模式,该用例使用数据并行模式。
import os
import argparse
from mindspore import context
from mindspore.context import ParallelModefrom mindspore.communication.management import init, get_rank, get_group_size
def network_init(argvs):
devid = int(os.getenv('DEVICE_ID', '0'))
context.set_context(mode=context.GRAPH_MODE,enable_auto_mixed_precision=True, device_target=argvs.device_target,save_graphs=False, device_id=devid)
# Init distributed
if argvs.is_distributed:
if argvs.device_target == "Ascend":
init()
else:
init("nccl")
argvs.rank = get_rank()
argvs.group_size = get_group_size()
def parallel_init(argv):
context.reset_auto_parallel_context()
parallel_mode = ParallelMode.STAND_ALONE
degree = 1
if argv.is_distributed:
parallel_mode = ParallelMode.DATA_PARALLEL
degree = get_group_size()
context.set_auto_parallel_context(parallel_mode=parallel_mode,gradients_mean=True, device_num=degree, parameter_broadcast=True)
if __name__ == "__main__":
parser = argparse.ArgumentParser(description='MindSpore CIFAR-10 Example')
parser.add_argument('--device_target', type=str, default="Ascend",choices=['Ascend', 'GPU', 'CPU'],help='device where the code will be implemented (default: CPU)')
parser.add_argument('--is_distributed', type=int, default=1,help='Distribute train or not, 1 for yes, 0 for no. Default: 1')
parser.add_argument('--rank', type=int, default=0,help='Local rank of distributed. Default: 0')
parser.add_argument('--group_size', type=int, default=1,help='World size of device. Default: 1')
parser.add_argument('--pre_trained', type=str, default=None,help='Pretrained checkpoint path')
args = parser.parse_args()
network_init(args)
parallel_init(args)
二、卡间初始化权重保持一致
卡间权重不一致,将为训练带来极大的阻碍,为使集群中每张Ascend芯片上模型的初始化权重保持一致,可以通过以下两种方式进行设置:
1.固定随机种子
在脚本开头添加如下代码:
import mindspore
mindspore.set_seed(0)
2.广播参数
在context.set_auto_parallel_context接口中设置parameter_broadcast=True,即训练开始前自动广播0号卡上数据并行的参数权值到其他卡上,默认值为False
context.set_auto_parallel_context(parallel_mode=parallel_mode,gradients_mean=True, device_num=degree, parameter_broadcast=True)
三、数据并行模式加载数据集
与单机不同,加载训练数据时,数据集接口中需要传入num_shards和shard_id参数,分别对应卡的数量和逻辑序号。通过配置运行信息和并行模式中的get_group_size和get_rank获取。
if do_train:
cifar_ds = ds.Cifar10Dataset(dataset_dir=data_home, shuffle=True,num_shards=device_num, shard_id=rank, usage='train')else:
cifar_ds = ds.Cifar10Dataset(dataset_dir=data_home,shuffle=False, usage='test')
四、运行脚本
目前MindSpore分布式执行采用单卡单进程运行方式,即每张卡上运行1个进程,进程数量与使用的卡的数量一致。其中,0卡在前台执行,其他卡放在后台执行。用来保存日志信息以及算子编译信息。下面以使用8张卡的分布式训练脚本为例,演示如何运行脚本:
export RANK_SIZE=8
current_exec_path=$(pwd)
echo ${current_exec_path}
echo 'start training'
for((i=0;i<=$RANK_SIZE-1;i++));
do
echo 'start rank '$i
mkdir ${current_exec_path}/device$i
cd ${current_exec_path}/device$i
export RANK_ID=$i
dev=`expr $i`
export DEVICE_ID=$dev
python ../MindSpore_8P.py
--device_target='Ascend'
--is_distributed=1 > train.log 2>&1 &
done
启动shell脚本进行分布式训练(8卡):
sh run_distribute.sh
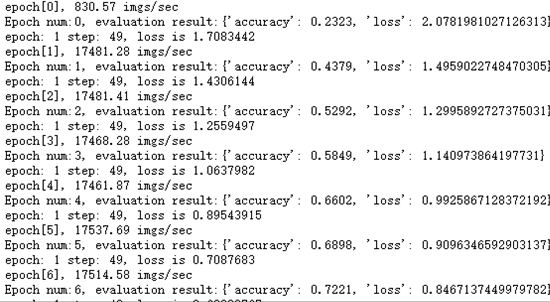
启动shell脚本后,将在后台运行分布训练, 执行tail -f device0/train.log 命令,可查看实时运行结果。如下图所示: