MindSpore Transformer模型库,几行代码玩转Transformer大模型,性能超越Megatron 20%
MindSpore Transformer模型库,几行代码玩转Transformer大模型,性能超越Megatron 20%
作者:金雪锋
文章来源:https://zhuanlan.zhihu.com/p/552995868
最近MindSpore将发布1.8.1版本,在那个版本我们会推出Transformer和推荐两个模型加速库,本文介绍一下Transformer这个库,提前预告一下。
Transformer模型和自监督预训练模式的提出,给NLP、CV等多个人工智能应用领域开辟了新的方向。通过增加模型参数量和数据规模,预训练模型在实际领域的表现还在持续地提升。
另一方面,参数量的提升给模型训练带来了新的挑战。GPT-3、T5等大规模Transformer模型通常至少需要上百张GPU卡进行长达数月的训练,耗费几百万美金的训练成本。如何更加高效地、分布式地训练这些“巨无霸”们,是目前整个业界都在思考的一个问题。
目前,众多企业以及开源机构推出了专门的Transformer模型训练库,其中以NVIDIA基于Pytorch的Megatron-LM训练库在各方面性能上较为领先。我们推出了基于MindSpore的Transformer模型训练库,相比Megatron,具有更高的开发效率、内存使用效率以及更高的性能,并同时支持多种后端。
1、性能结果
我们分别在8p、16p和32p A100集群上测试了百亿规模GPT(hiddensize=5120, num_layers=35, num_heads=40)性能,模型并行路数设置为8,数据并行数分别为1、2、4,Global Batch为1024。Megatron配置Micro Batch Size=2(Megatron已达到上限),MindSpore配置Micro Batch Size=8,相比Megatron,昇思MindSpore的内存利用率更高,可以训练更大的Batch Size。
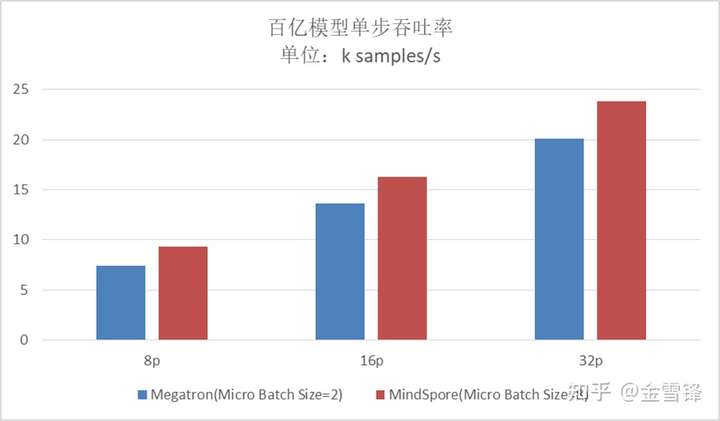
吞吐率对比
如上图所示:
8P Megatron的最大吞吐率为7.4 k samples/s;MindSpore 最大吞吐率为9.3k samples/s, 超过Megatron 25%;
16P Megatron的最大吞吐率为13.6k samples/s,MindSpore最大吞吐率为16.9k samples/s,超过Megatron 24%;
32P Megatron的最大吞吐率为20.1k samples/s,MindSpore最大吞吐率为23.8k samples/s,超过Megatron 18%。
这些性能提升主要得益于MindSpore强大的图算融合技术以及更加精细的自动并行调度能力。
2、更高的开发效率
MindSpore Transformer利用MindSpore内置的并行技术,能够自动进行拓扑感知,高效地融合数据并行和模型并行策略;实现单卡到大规模集群的无缝切换。
低门槛的并行易用性 受益于MindSpore的并行能力。MindSpore Transformer能够从单卡一键拓展到多卡训练。
context.set_auto_parallel_context(parallel_mode="stand_alone") # 单卡
context.set_auto_parallel_context(parallel_mode="data_parallel") # 数据并行
context.set_auto_parallel_context(parallel_mode="semi_auto_parallel") # 半自动并行
用户可以在启动脚本中传入"--parallel_model=data_parallel"参数来使能上述功能。
丰富的并行特性,一键使能 如下代码展示了MindSpore Transformer库中进行模型并行的设置。MindSpore预定义了一套最基础的通过配置model_parallel模型并行数和data_parallel数据并行数,可以直接实现Tranformer类网络的模型并行,实现大模型训练。
parallel_config = TransformerOpParallelConfig(model_parallel=config.model_parallel, # 模型并行
data_parallel=config.data_parallel, # 数据并行
recompute=True, # 开启重计算
optimizer_shard=True) # 开启优化器并行
transformer = Transformer(hidden_size=config.hidden_size,
batch_size=config.batch_size,
ffn_hidden_size=config.hidden_size * 4,
src_seq_length=config.seq_length,
tgt_seq_length=config.seq_length,
encoder_layers=config.num_layers,
attention_dropout_rate=config.dropout_rate,
hidden_dropout_rate=config.dropout_rate,
decoder_layers=0,
num_heads=config.num_heads,
parallel_config=config.parallel_config)
同时,由于MindSpore框架本身有丰富的并行基础能力,这使得MindSpore Transformer整体实现比较简单,代码量7000行即可实现Megatron几万行的代码量,同时MindSpore Transformer与其他框架的库相比,在代码的灵活度和通用性上更好,更加有利于大模型的自定义和泛化。
此外,MindSpore Transformer库同时提供多种并行技术:流水线并行、优化器并行和专家并行。用户可以持续关注仓库的最新进展。
3、展望
大模型训练一直是业界的热点之一,国内外的大模型也在不断地推陈出新,MindSpore Transformer 库也将会持续不断的更新和演进。未来我们计划增加更多的预训练语言模型,例如MoE、多模态等大模型,欢迎关注和使用。
代码仓链接: