论文干货——【CSD】基于对比自蒸馏的超分辨率模型压缩与加速
论文干货——【CSD】基于对比自蒸馏的超分辨率模型压缩与加速

1 研究背景
背景
图像超分辨率的目的是放大给定图像,使其分辨率更高,得到更加清晰地细节纹理。它可以显著提升下游任务如车辆检测、场景理解等高层视觉任务的性能,是图像处理和计算机视觉领域共同关切的前沿课题。
但目前大部分图像超分辨率方法都关注于构建复杂的网络结构,带来了大量的参数两和计算量,使得模型在轻量级设备中难以部署。
论文研究方向
本文的主要目标是设计一种通用的超分辨率模型加速和压缩方法,压缩现有超分辨率模型参数量并实现运行时间上的加速,构建以自蒸馏为核心的算法框架。
2 团队介绍
所在团队由吴文俊科学技术奖自然科学奖、上海市科技进步特等奖获得者谢源教授领衔。
团队长期从事机器学习、计算机视觉与模式识别等方面的科研工作,有扎实的研究基础和丰富的成果积累(AI与CV顶会年均产出48篇,AI与CV顶刊年均产出35篇),并形成了一系列自有知识产权的国际领先的科研成果。
3 论文主要内容简介
论文提出了一种基于对比自蒸馏的图像超分辨率模型压缩和加速方法。
通过构造自蒸馏框架,学生网络和教师网络共享部分参数,实现隐式知识蒸馏,为运行时动态加载提供基础。区别于分类任务,简单地进行隐式知识蒸馏无法有效约束学生网络。
在此基础上,论文通过引入基于对比学习的损失函数,对学生网络和教师网络的关系进行显式约束,并通过引入负样本为学生网络解空间提供下界约束。
论文通过大量、详实的实验在实践中验证了方法的正确性和有效性。在相近计算量情况下,使用论文设计的方法训练的模型具有更高性能。同时,论文设计的方法可以拓展到大量现有超分辨率模型上,使现有SOTA方法能适应端侧设备轻量化需求。
4 代码链接
论文链接
https://arxiv.org/abs/2105.11683
基于昇思MindSpore实现代码开源链接
https://gitee.com/mindspore/models/tree/master/research/cv/csd
5 算法框架技术要点
算法框架包括两部分,即基于自蒸馏架构的学生-教师网络,以及对比损失。
学生-教师网络包括浅层特征提取模块,深层特征提取模块及上采样模块。学生网络和教师网络共享每一层部分通道,通过宽度系数进行控制。
除了传统的重建损失以外,论文将学生网络的输出作为锚点,教师网络输出作为正样本,双三次插值图像作为负样本,输入到预训练的VGG网络中并计算对比损失。
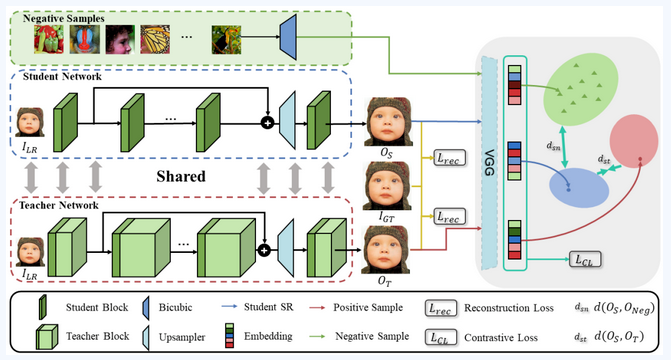
(图一:算法框架)
6 实验结果
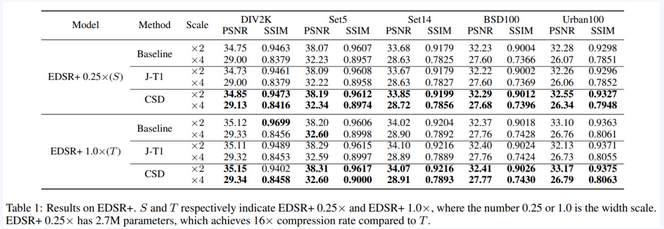
(图二:论文在EDSR模型上压缩后性能)
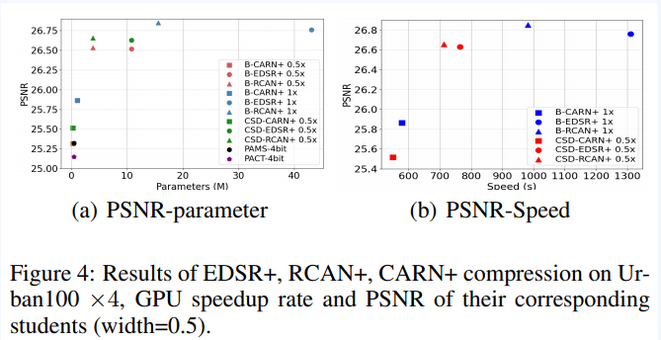
(图三:论文在不同模型结构上压缩加速效果)

(图四:可视化效果)
7 MindSpore代码实现
代码主要包括一下模块:数据加载,网络结构(以EDSR模型为例),损失函数以及训练器。
(1)数据加载:
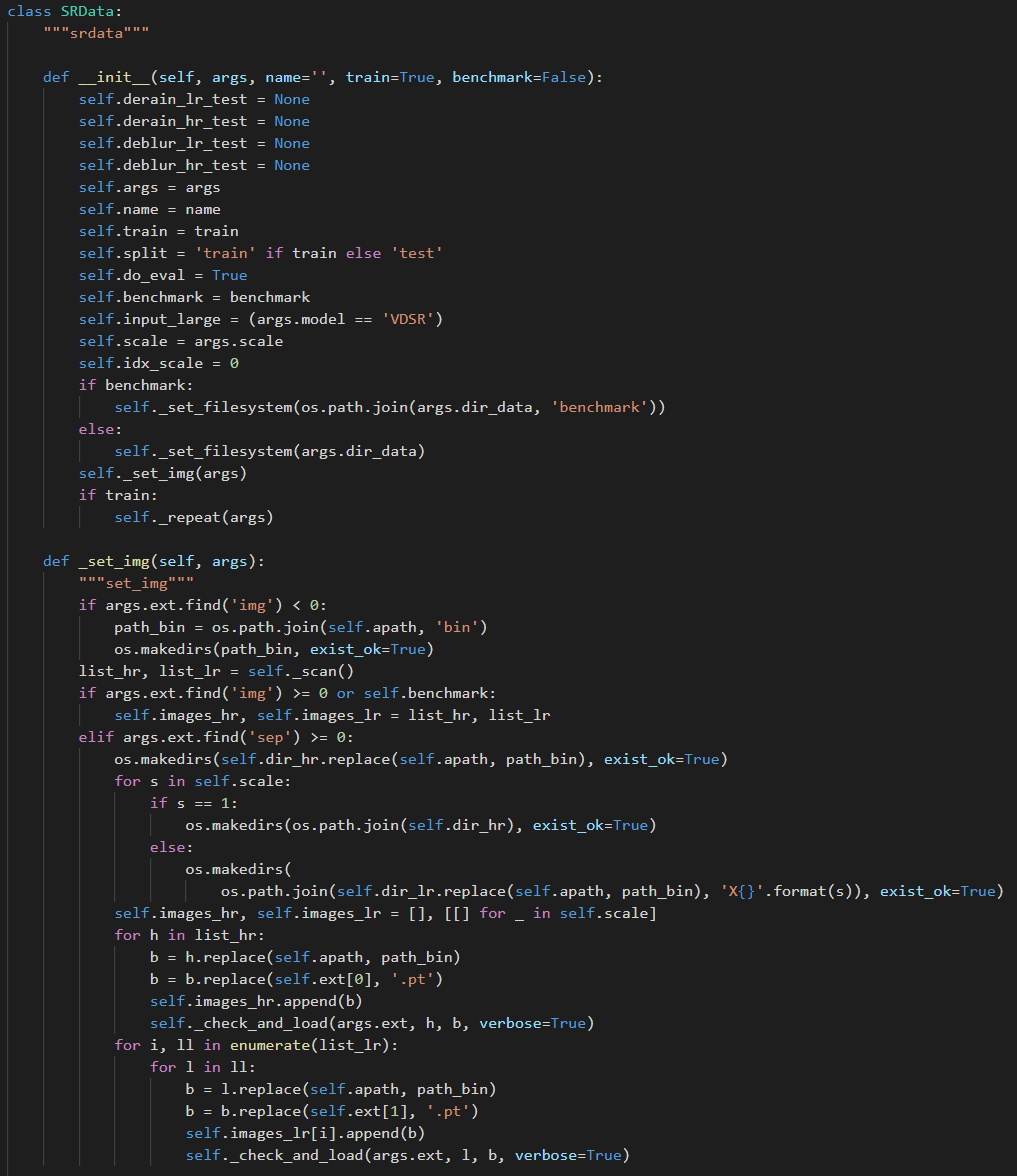
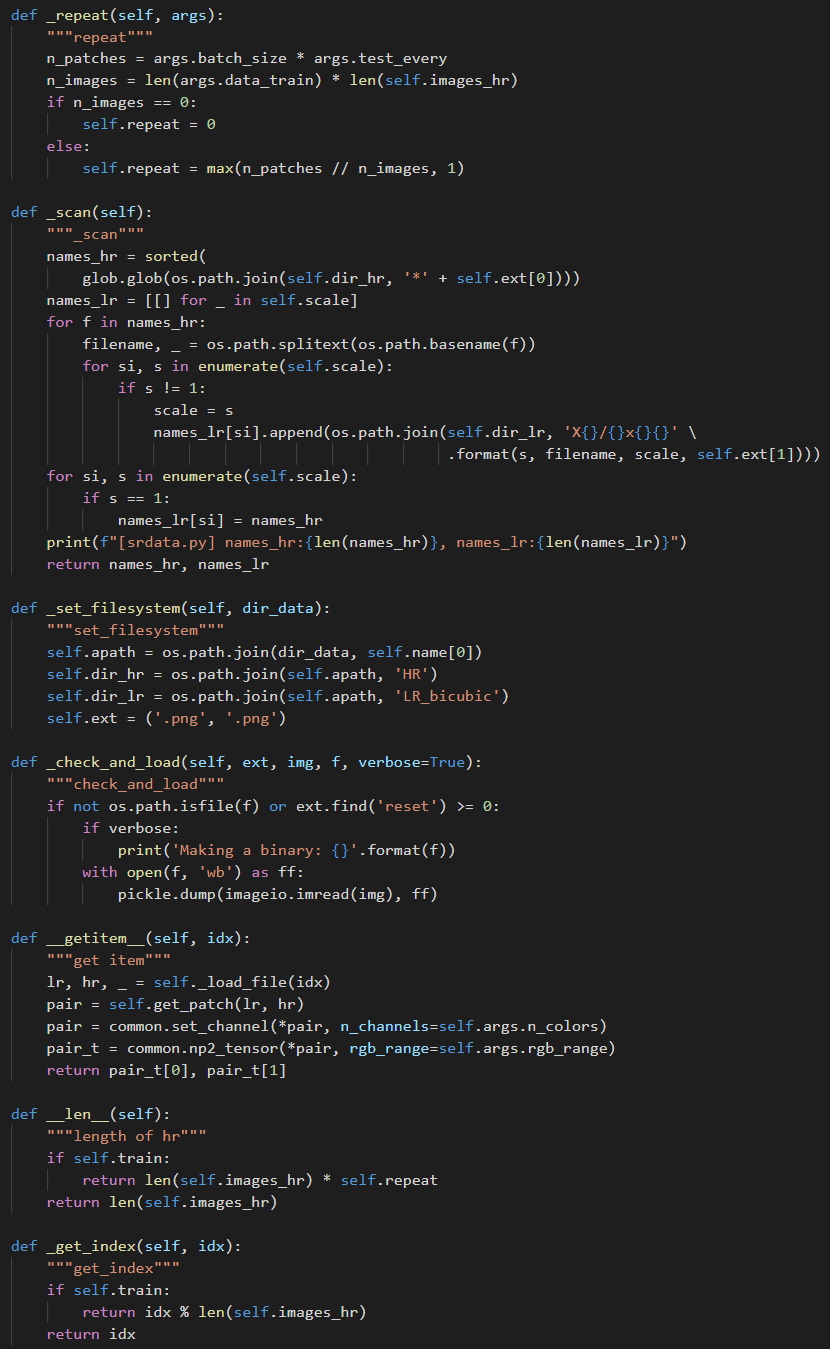
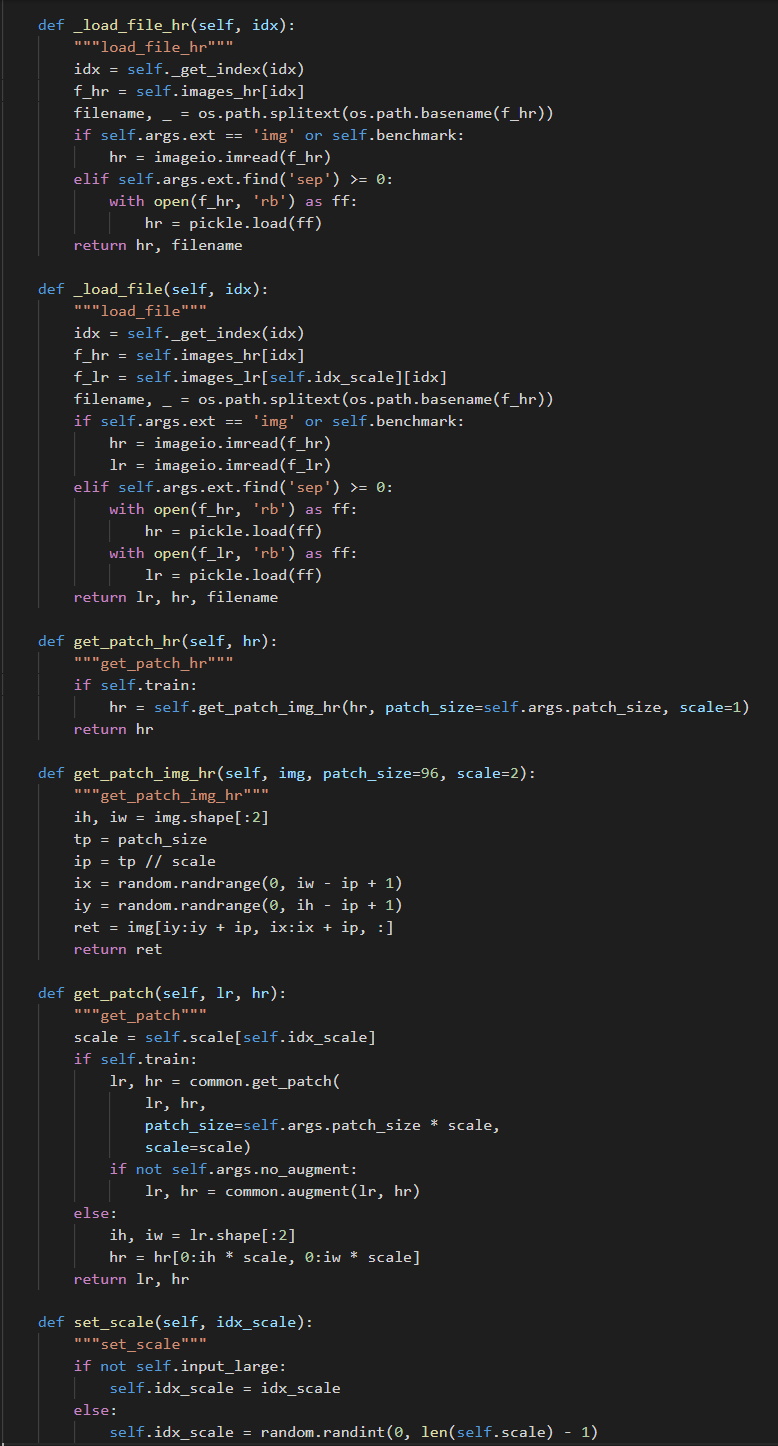
(图五:数据集类)
(2)网络结构:
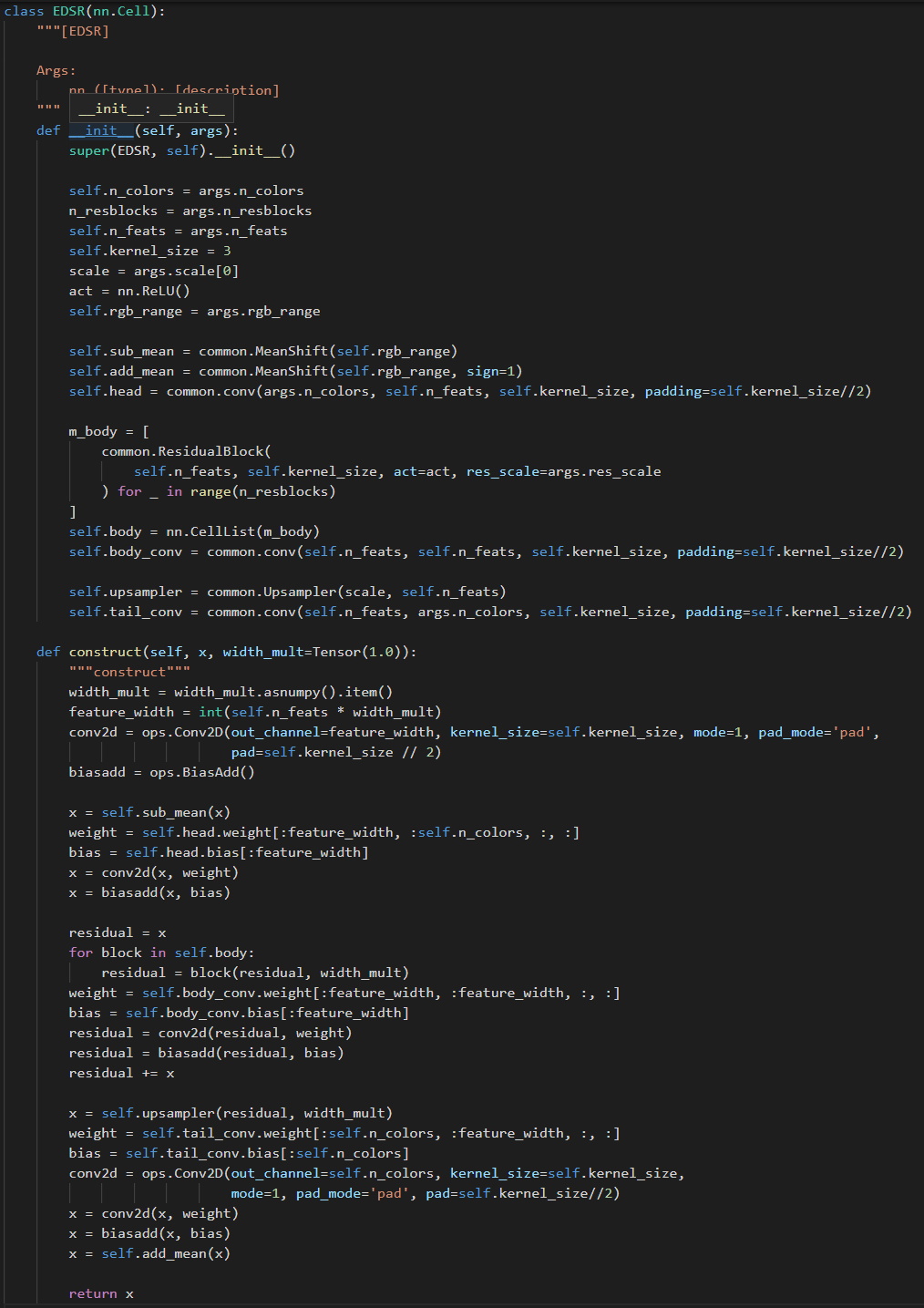
(图六:可调整宽度的EDSR模型)
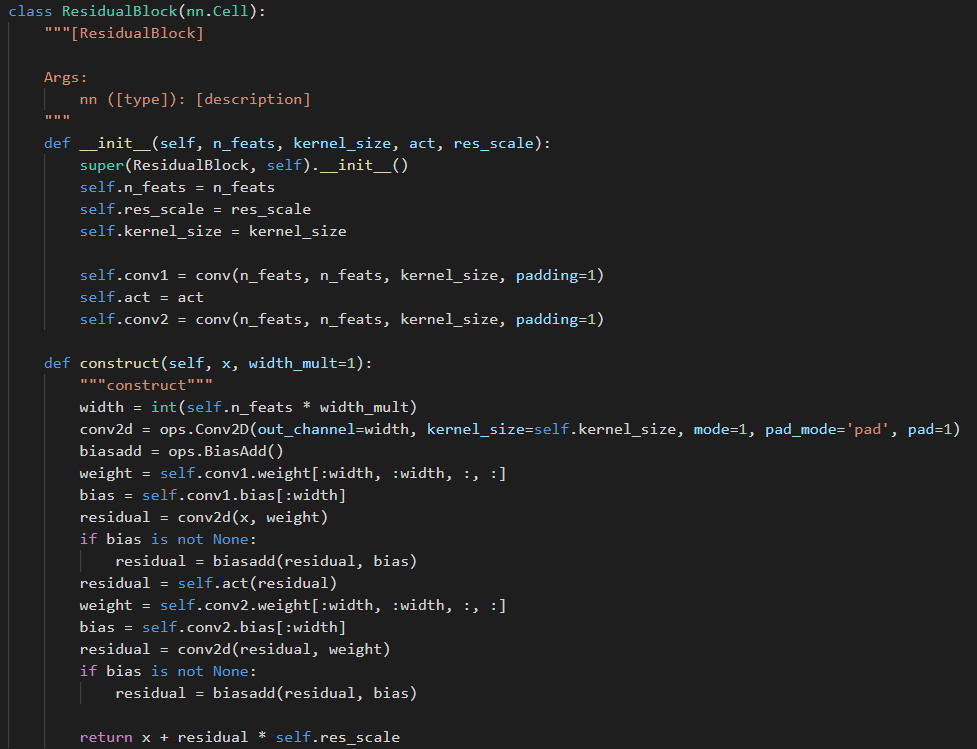
(图七:宽度可调整的残差块)
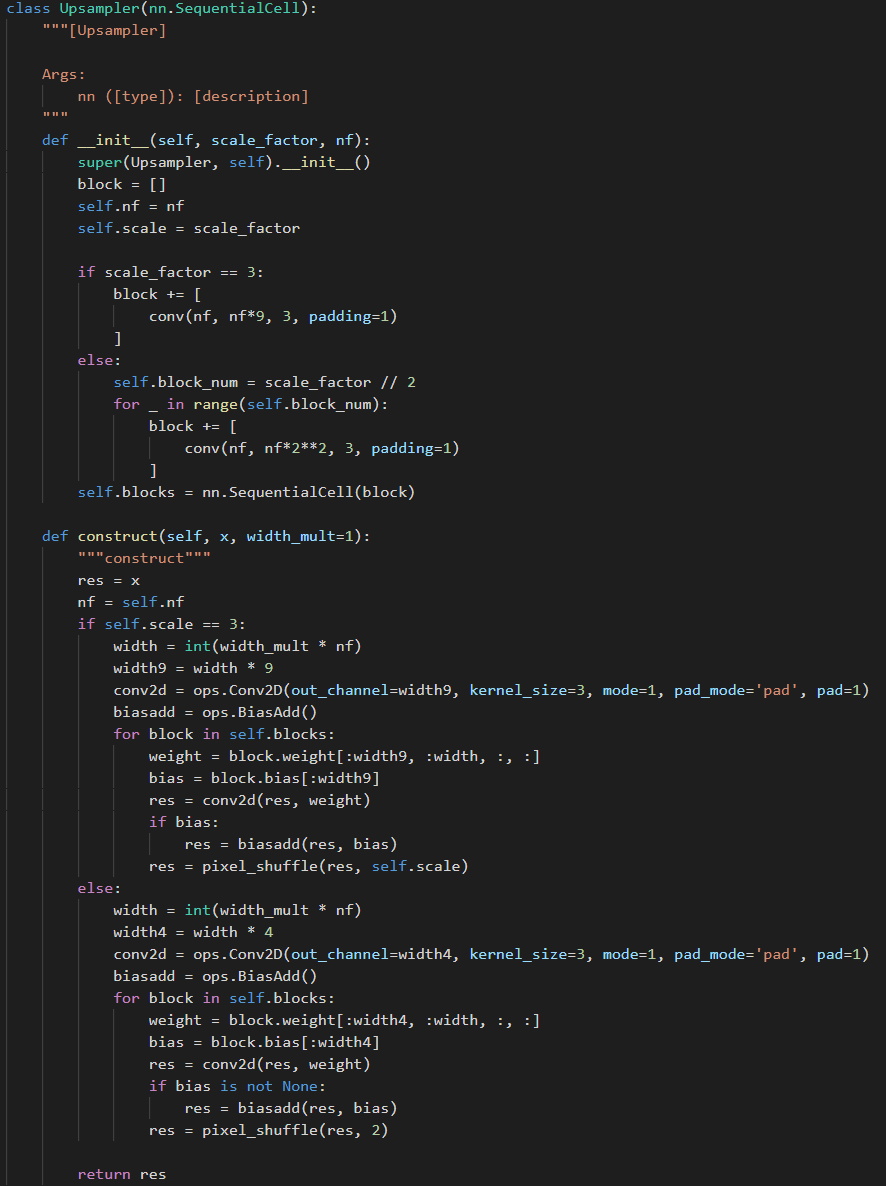
(图八:宽度可调整的上采样块)
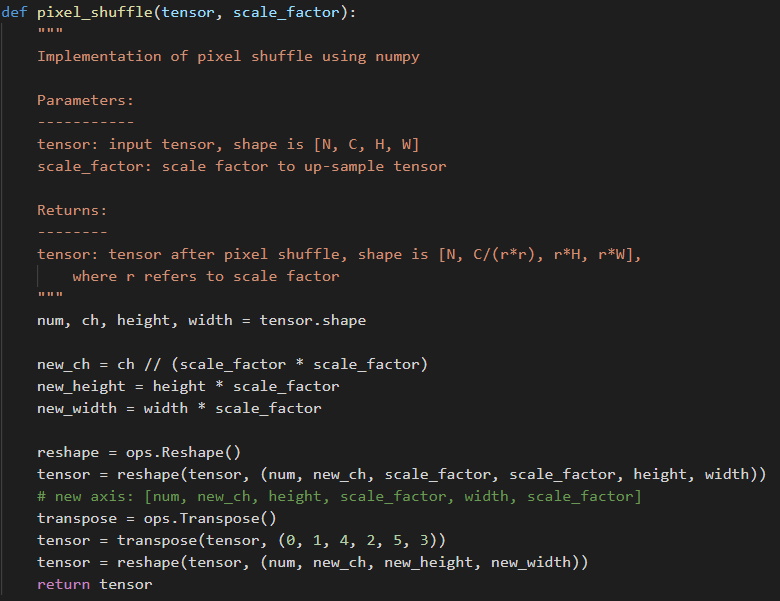
(图九:pixel-shuffle操作)
(3)损失函数:
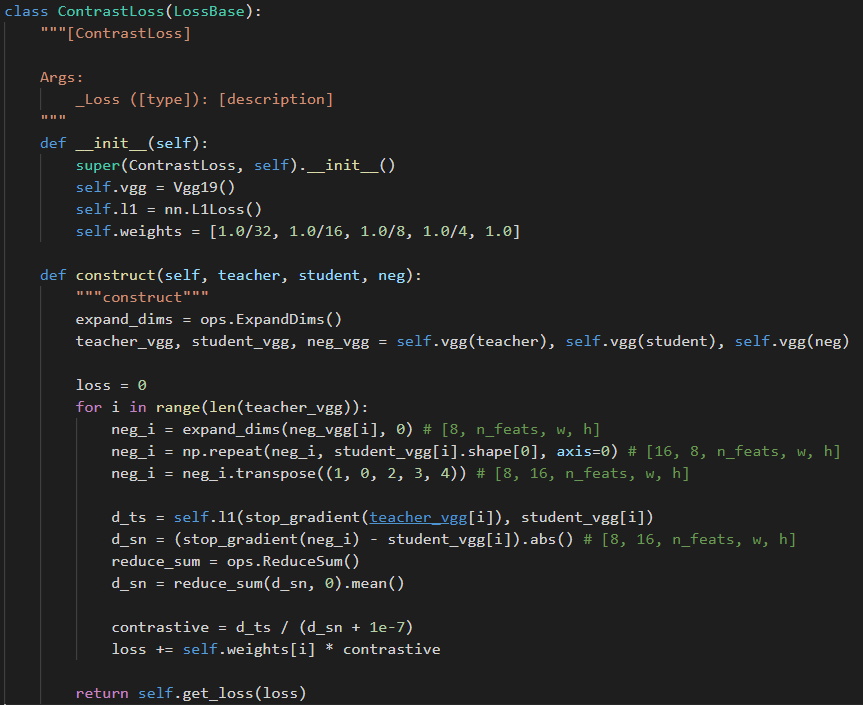
(图十:对比损失)
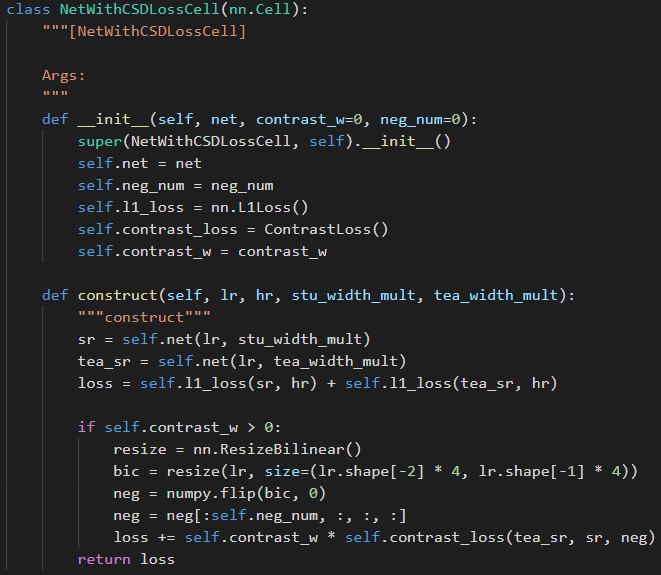
(图十一:完整损失函数)
(4)训练器:
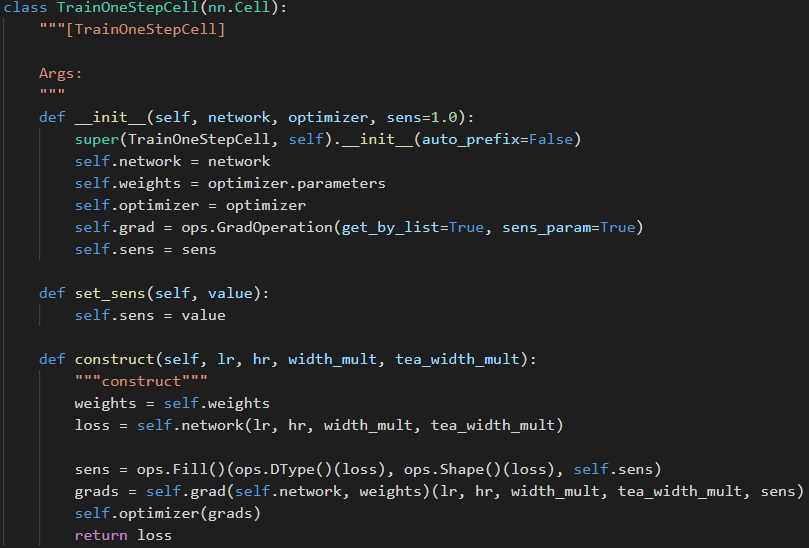
(图十二:单步训练过程)
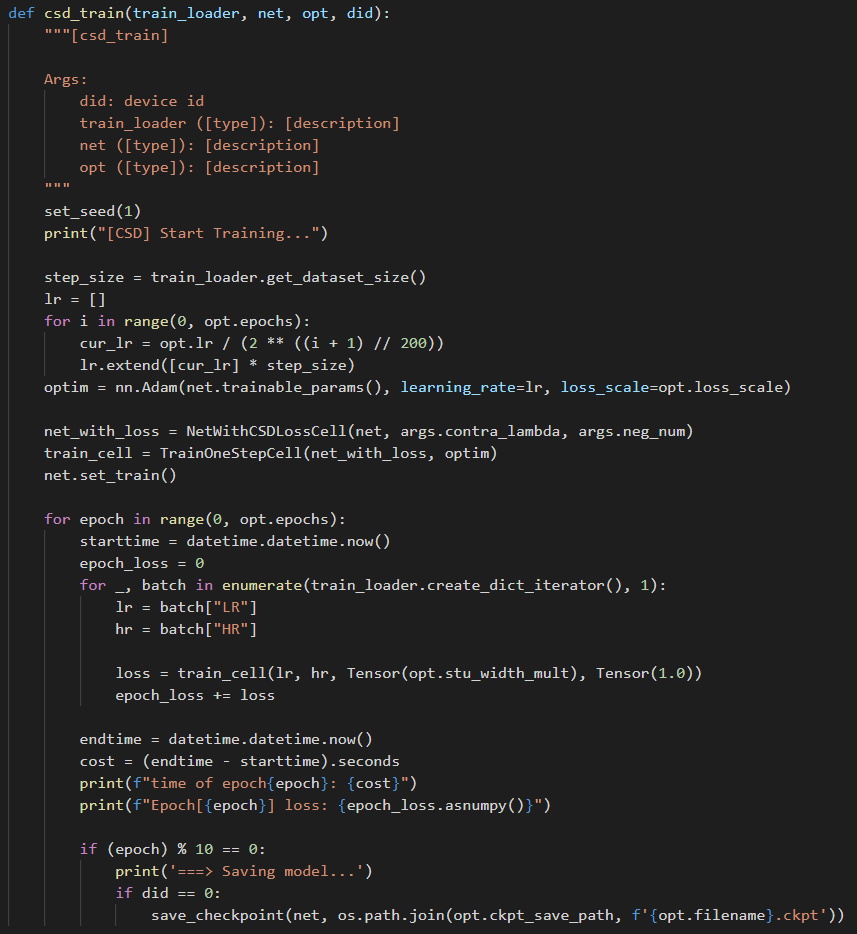
(图十三:完整训练过程)
8 总结与展望
本文设计了一个针对超分辨率任务的通用模型压缩和加速方法,通过构建自蒸馏架构,模型可根据实际计算资源进行动态部署。同时引入正负样本有效约束了解空间,对教师网络和学生网络进行显式知识蒸馏。
文中所提出的方法可同时进行压缩和加速,具有通用性,可广泛应用于大部分深度学习超分辨率模型,但未在其他低层视觉任务上进行探索。未来工作将着力探索本文所提出的方法对其他图像复原类任务的有效性。

MindSpore官方资料
官方QQ群: 486831414
Gitee: https : //gitee.com/mindspore/mindspore