MindSpore AI科学计算系列(13):Autodock Vina的工作原理
MindSpore AI科学计算系列(13):Autodock Vina的工作原理
分子对接(molecular docking)是分子模拟的重要方法之一,其本质是两个或多个分子之间的识别过程,其过程涉及分子之间的空间匹配和能量匹配。在生物制药中,针对一个致病蛋白,选择一个亲和性高的化合物小分子与其在靶点处对接从而使蛋白质失活,这种方法十分普遍。
那么如何有效选取一个合适的小分子化合物与目标蛋白质对接就成为了一个至关重要的问题。在传统的分子虚拟筛选中,人们会遍历整个小分子化合物的库,让库中的所有小分子与蛋白质去对接,获得大量的复合物,之后通过计算对接的结合能,求得小分子的得分。最后根据得分来对小分子进行排序,再选取分数较高的一部分小分子来进行之后的制药实验。整个流程的流程图大致如图1所示。

图1 小分子化合物虚拟筛选流程图
在整个流程中,有两个步骤是人们重点关注的对象,一个是分子对接,另一个则是针对对接所得复合物进行打分。Autodock Vina就是一款针对蛋白质-小分子配体的分子对接仿真软件。它的大致工作流程如图2所示。
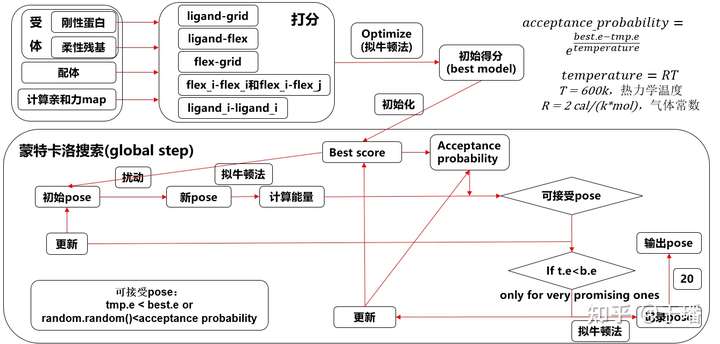
图2 Autodock Vina工作流程图
与数据库中的数据文件不同的是,Autodock Vina的输入不能是pdb文件而是pdbqt文件,里面包含了更多的原子间的关系。在输入时,我们需要输入蛋白质和小分子的pdbqt文件,同时也要输入Vina力场的中心坐标以及box size。之后软件会根据输入来计算力场的map并且保证配体和受体都在box中。Vina会根据两者的当前pose计算一个初始能量来作为打分结果,再通过拟牛顿法中的BFGS方法来使得当前pose的能量最小化。这个minimum energy会作为当前pose的最终得分,同时也会作为整个模型的best score的初始化得分。而当前pose也会作为模型的初始pose。
在完成初始化之后,软件会基于蒙特卡洛树搜索来搜索足够多的pose,每次会对初始pose随机施加旋转,平移和扭矩旋转等扰动,当然施加的扰动不会使得两者离得过远,要保证两者的距离不能超过2 。之后还会再一次使用BFGS法来计算新的pose的能量作为当前pose的打分。根据这个得分和best score的对比来判断当前pose是否为一个合理的可以接受的pose。如果当前pose的能量值(tmp.e 或者 t.e)小于best score(best.e 或者 b.e)则可以接受,如果tmp.e < best.e,则要根据acceptance probability来计算这个pose被接受的概率。
如果一个pose被认定为可接受pose,则它会作为下一次蒙特卡洛搜索的初始pose,基于此pose来施加扰动开启下一次的循环,而对于被接受pose中tmp.e < best.e的那一些pose,软件会将其记录下来,同时再一次使用拟牛顿法更细致地逼近能量方程来计算它的结合能,并将其作为整个模型的新的best score影响之后的筛选流程,这样也就能保证之后再找到的promising poses的结合能一定会小于当前pose。当整个搜索流程结束后,模型会输出它保存的20个最佳的pose,并根据其中结合能最小的那一个来计算其他pose与它的rmsd,并据此排序输出。当然,20是人为指定的数量,我们也可以要求软件输出更多或者更少的pose。
这就是Autodock Vina大致的工作流程,其中有很多细节没有说明,有机会的话在之后的文章中再进一步进行探讨。