鹏城实验室基于昇思MindSpore框架、昇腾硬件发布数学推理模型PCL-Reasoner-V1
鹏城实验室基于昇思MindSpore框架、昇腾硬件发布数学推理模型PCL-Reasoner-V1
一、技术概览
本次发布的PCL-Reasoner-V1模型,以Qwen2.5-32B-Base为起点,基于昇思框架与昇腾硬件,进行了高性能的监督微调。经过微调,模型在数学推理能力上取得了显著提升:其在权威基准评测集AIME24上准确率达85.7%,AIME25上达84.2%,在32B参数级别模型中稳居前列。我们已完整开源了PCL-Reasoner-V1的模型权重、微调数据及训练代码。该模型不仅是当下领先的32B数学推理模型之一,也为开发者提供了专业领域监督微调实践经验与后训练解决方案。相关代码现已同步开源至启智社区与昇思社区。用户可参照教程轻松部署体验,深入探索后训练的实践方法与奥秘!
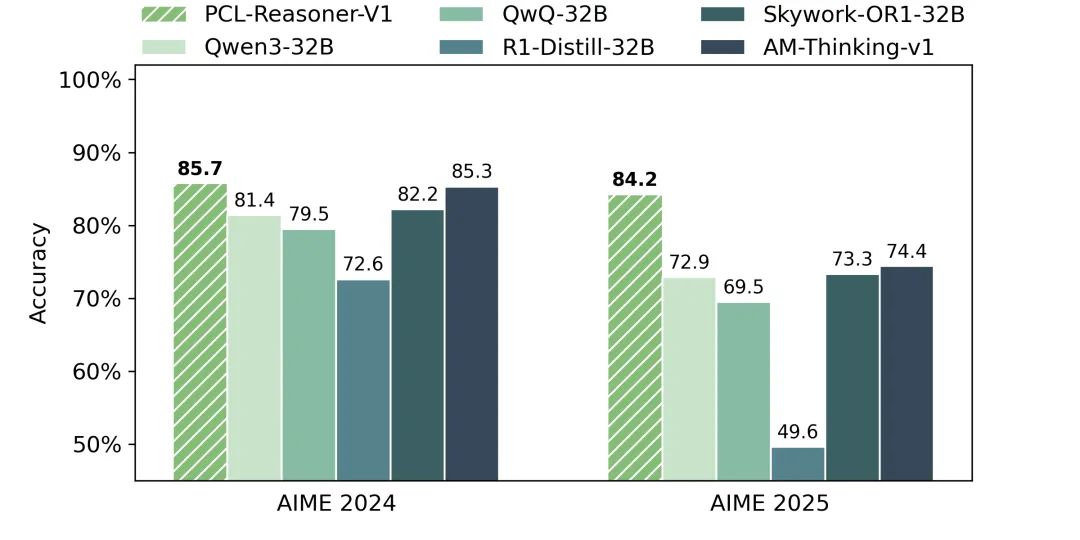
图1:业界模型在AIME24/25上的评测结果
1. 训练数据
我们联合华为分布式数据实验室开发了数据处理流水线,针对本次训练采用的AM-DeepSeek-R1-0528数学数据集进行清洗。在数据预处理阶段,我们首先进行了评测集污染检测,针对AIME24/25评测集,通过问题与答案双维度交叉筛查,采用相似度阈值(>70%)进行初筛,筛查出4道题目有较高相似度(如图2所示),结合人工复核,我们判断这4道较高相似题目均与评测集无实质性关联,从而判定该数据集数学模块不存在AIME24/25污染风险。其次,我们进行了训练样本过滤,基于单样本序列长度<32K tokens的标准进行筛选,最终纳入训练的有效数据总量为666K条。

图2:相似度较高的题目
2. 训练方法
为最大化算力利用效率,我们在监督微调中启用了数据打包(packing)功能。该功能能够将每个批次内不同长度的样本数据拼接整合到设定的序列长度(32K tokens)范围内。通过将多条短序列数据融合成一条长序列(如图3所示),有效避免了序列填充带来的冗余计算,显著加速了训练过程。实验结果表明,启用打包功能后,训练总时长缩短了3倍以上,微调效率大幅提升。
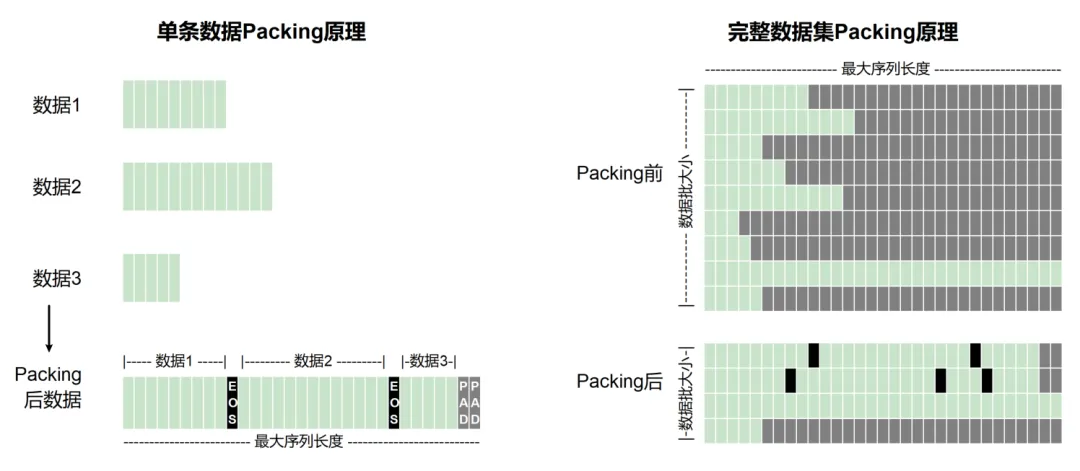
图3:Packing原理示意图
3. 评测结果
评测结果详见表列数据。为确保评估准确性,我们采用Avg@32指标(平均32次采样)进行了评测。模型在AIME24/25评测集上的生成结果文件已同步上传至pcl_reasoner_v1/eval/eval_res目录,供开发者用于模型验证与效果比对参考。
参数量
模型
AIME 24
AIME 25
>100B
DeepSeek-R1
79.8
70
DeepSeek-R1-0528
91.4
87.5
Qwen3-235B-A22B
85.7
81.5
OpenAI-o3
91.6
88.9
Gemini-2.5-Pro-0506
90.8
83
32B
Qwen3-32B
81.4
72.9
QwQ-32B
79.5
69.5
DeepSeek-R1-Distill-Qwen-32B
72.6
49.6
Skywork-OR1-32B
82.2
73.3
AM-Thinking-v1
85.3
74.4
PCL-Reasoner-V1(ours)
85.7
84.2
我们已成功构建基于昇思框架与昇腾硬件协同优化的全流程大模型监督微调技术栈。未来将持续深耕后训练优化及强化学习领域,着力在代码生成和AI for Science等前沿方向研发性能和通用性更好的大模型。
二、开源代码仓
https://openi.pcl.ac.cn/PCL-Reasoner/V1
三、复现流程
1. 安装环境
固件&驱动
24.1.rc3.5
CANN
7.7.T9.0.B057:8.1.RC1
Python
3.10
MindSpore
y2.6.0
MindSpore TransFormers
r1.5.0
2. 数据处理流程
2.1 数据集下载
用户可以从HuggingFace官方下载原始数据集。
数据集名称
数据集链接
AM-DeepSeek-R1-0528-Distilled
https://huggingface.co/a-m-team/AM-DeepSeek-R1-0528-Distilled
2.2 数据预处理
首先,我们对源数据进行检测和筛选,操作分为两个步骤,验证集污染检测与数据筛选。
●第一步,验证集污染检测:
我们采用基于all-MiniLM-L6-v2模型计算文本余弦相似度的方法,对数学部分原始数据针对AIME24/25评测集进行污染检测。该脚本执行后会在终端打印检测结果,并在指定的输出路径中保存相似度大于阈值的题目及其匹配的评测集题目。
python PCL-Reasoner-V1/pcl_reasoner_v1/data_preprocess/decontaminate.py \
--target_data /path/to/target_data \
--contaminant_source PCL-Reasoner-V1/pcl_reasoner_v1/data_preprocess/aime2425_questions.json \
--model_path /path/to/distilled/model_path \
--output_file_prefix /path/to/output_file_prefix
--threshold0.7
# 参数说明
target_data:需要被检测的数据
contaminant_source:污染源,即评测集数据
model_path:计算文本嵌入的模型
output_file_prefix:检测结果输出的路径
threshold:相似度阈值
●第二步,数据筛选:
运行数据处理脚本,进行数据长度筛选,选取问题加思维链长度小于32K tokens的数据,并将提示词添加到数据中。
python PCL-Reasoner-V1/pcl_reasoner_v1/data_preprocess/dataset_prehandle_and_split.py \
--json_file_paths /path/to/json_file_paths
# 参数说明
json_file_paths:需要处理的数据集,支持传入多个路径,用空格分隔
其次,我们将数据转换成packing格式,操作分为两个步骤,格式转换与数据拼接。
●第一步,格式转换:
在配置文件pcl_reasoner_v1/config/data_process_handling.yaml中指定data_files、vocab_file、merges_file等文件路径,指定pcl_reasoner_v1/packing_handler.py文件中自定义的AMDeepSeekDataHandler为数据handler:
train_dataset: ... path:"json"# 原始数据集文件格式 data_files: ["/path/to/data.jsonl"]# 原始数据集路径 input_columns:*input_columns handler: -type: AMDeepSeekDataHandler# 指定自定义的数据处理类 ... tokenizer: auto_register: qwen2_5_tokenizer.Qwen2Tokenizer ... vocab_file:"/path/to/vocab.json"# Qwen2_5默认tokenizer文件 merges_file:"/path/to/merges.txt"# Qwen2_5默认tokenizer文件 ...
(注意事项:以上模型配置为示例,仅列出用户高频修改的配置项,完整配置文件见代码仓)
运行数据处理脚本,生成Arrow格式数据文件:
export PYTHONPATH=/path/to/mindformers/:PYTHONPATH python /path/to/mindformers/toolkit/data_preprocess/huggingface/datasets_preprocess.py \
--config ./pcl_reasoner_v1/config/data_process_handling.yaml \
--save_path /path/to/handled_data/ \
--register_path ./pcl_reasoner_v1/
# 参数说明
config:数据格式转换的配置文件路径
save_path:转换后数据集的保存文件夹路径
register_path:自定义数据Handler注册目录路径
●第二步,数据拼接:
在配置文件pcl_reasoner_v1/config/data_process_packing.yaml指定packing后数据的存储路径:
# dataset
train_dataset:
data_loader:
...
path: /path/to/handled_data#预处理后数据集的路径
...
(注意事项:以上模型配置为示例,仅列出用户高频修改的配置项,完整配置文件见代码仓)
运行数据packing脚本,生成packing后数据文件:
export PYTHONPATH=/path/to/mindformers/:PYTHONPATH
python /path/to/mindformers/toolkit/data_preprocess/huggingface/datasets_preprocess.py \
--config ./pcl_reasoner_v1_config/data_process_packing.yaml \
--save_path /path/to/packed_data/ \
--register_path ./pcl_reasoner_v1/
# 参数说明
config:数据拼接的配置文件路径
save_path:拼接后数据集的保存文件夹路径
register_path:自定义数据Handler注册目录路径
3. 训练流程
3.1 权重准备
用户可以从HuggingFace官方下载预训练权重
模型名称
权重链接
Qwen2.5-32B-Base
https://huggingface.co/Qwen/Qwen2.5-32B
MindFormers 1.5.0及以上版本已支持safetensors格式的权重直接加载及保存,无需转换成ckpt,下文中微调将使用safetensors格式权重运行。
3.2 训练配置
下面仅列出用户高频修改的配置项,完整配置文件见pcl_reasoner_v1/config/finetune_pcl_reasoner_v1_32k.yaml
基本配置:
run_mode: 'finetune' # 设置训练模式为“finetune”
load_checkpoint: '/path/to/Qwen-32B-base/' # 权重文件路径
load_ckpt_format: 'safetensors' # 设置权重格式为“safetensors”
auto_trans_ckpt: True # 设置在线权重切分至分布式权重
数据集配置:
train_dataset: &train_dataset
data_loader: type: CommonDataLoader # offline path: "/path/to/dataset/pack_data_lt_32K_full" # 数据文件路径 load_func: 'load_from_disk' # 设置数据加载方式为“load_from_disk” shuffle: True # 数据打乱功能使能 packing: pack # 数据格式为pack adaptor_config: compress_mask: True mock_config: seq_length: 32768 # 数据pack后长度为32k size: 25909 # 数据集大小/数据并行切分
并行配置:
parallel_config:
data_parallel: &dp 8 # 数据并行切分为8
model_parallel: 8 # 模型并行切分为8
pipeline_stage: 2 # 流水线并行切分为2
use_seq_parallel: True # 序列并行使能
optimizer_shard: True # 优化器并行使能
micro_batch_num: 16 # micro bathsize设置为16
(注意事项:以上模型配置为示例,仅列出用户高频修改的配置项,完整配置文件见代码仓)
3.3 启动微调
在启动脚本run_pcl_reasoner_v1_finetune.sh指定配置文件pcl_reasoner_v1/config/finetune_pcl_reasoner_v1_32k.yaml,并根据用户的实际情况对卡数、服务器IP等配置进行修改:
noderank=$1
bash /path/to/mindformers/scripts/msrun_launcher.sh "run_mindformer.py \--config /path/to/finetune_pcl_reasoner_v1_32k.yaml \--run_mode finetune" \--worker_num 128 \--local_worker_num 8 \--master_addr XX.XX.XX.XX\--master_port XXXX\--node_rank$noderank \--log_dir/path/to/log \--join False \--cluster_time_out 1200 \> run.log 2>&1# 参数说明config:配置文件路径run_mode:运行模式(预训练/微调/推理)worker_num: 总卡数local_worker_num: 单机的卡数master_addr:主节点地址master_port: 主节点端口log_dir: 日志路径join:是否等待所有worker退出cluster_time_out:集群等待时间
然后,使用bash run_pcl_reasoner_v1_finetune.sh指令启动微调训练,在多个节点上启动时,需指定node_rank(以下指令以0节点为示例):
bash run_pcl_reasoner_v1_finetune.sh 0
在拉起任务后,通过以下指令查看运行日志:
tail -f path/to/log/worker_127.log
4. 评测流程
为了保障评测结果的公平性,我们采用了QwQ开源的评测代码(QwQ/eval at main · QwenLM/QwQ),可以根据代码仓中README.md指导进行环境安装及模型评测。
我们采用的评测超参如下所示:
采样超参
取值
temperature
0.6
top_k
40
top_p
0.95
max_tokens
129024
chat_template
./pcl_reasoner_v1/eval/am_thinking.jinja
另外,我们也针对评测时不同模型回答长度统计正确率,可以看出AIME24/25评测集对回答长度要求较高,而且较为简单的AIME24上,64K tokens的回答长度可以满足,而较为难的AIME25上则需要回答长度长达128K tokens:
max_tokens
16K
32K
64K
128K
AIME 24
42.0
77.9
85.7
85.7
AIME 25
33.4
75.6
83.9
84.2