昇思MindSpore助力天翼云提供极致MoE大模型训练性能
昇思MindSpore助力天翼云提供极致MoE大模型训练性能
自DeepSeek V3横空出世以来,以其卓越的模型效果和极低的训练成本,引领着大模型训练发展潮流,对AI行业的发展方向带来前所未有的变革。以DeepSeek V3为代表的MoE模型,凭借其稀疏激活特性展现出强大潜力。然而,由于MoE模型独特的稀疏结构,以及额外的路由通信开销等原因,导致类DeepSeek的MoE模型在训练效率上相比稠密模型有一定损耗。
为此,昇思MindSpore与天翼云针对MoE模型训练效率开展了联合创新优化,在通信、并行策略、算子等维度对DeepSeek V3预训练进行了系统级性能优化,基于昇腾Atlas 900 AI集群 + 昇思MindSpore AI框架,在MindSpore Transformers大模型套件上进行极致性能优化,优化后相比开箱性能提升83%。
在通信优化方面,采用机间通信合并和细粒度计算通信掩盖有效减低通信时间;在并行策略优化方面,通过TP_EXTEND_EP 并行策略,减少TP切分带来的通信耗时;在算子优化方面,通过FlashAttention非对齐计算、高性能AlltoAll算子、图算融合升级等技术提升算子性能。
# 01
通信优化
1、机间通信合并
MoE架构的大模型专家数众多,如DeepSeek V3的专家个数高达256个,为缓解内存压力往往会开启专家并行(EP),将专家切分到不同的卡上。当EP超过单个节点内的NPU数量时,部署专家会被分散到多个节点上,导致机间通信数据量过大,成为训练性能的瓶颈。研究团队采用跨机AllGather 通信将所需的tokens同步到机内,并在机内进行tokens排序与AlltoAll通信,极大地减少了跨机通信量,降低了AlltoAll通信时间。机间通信合并前后流程如图1所示。
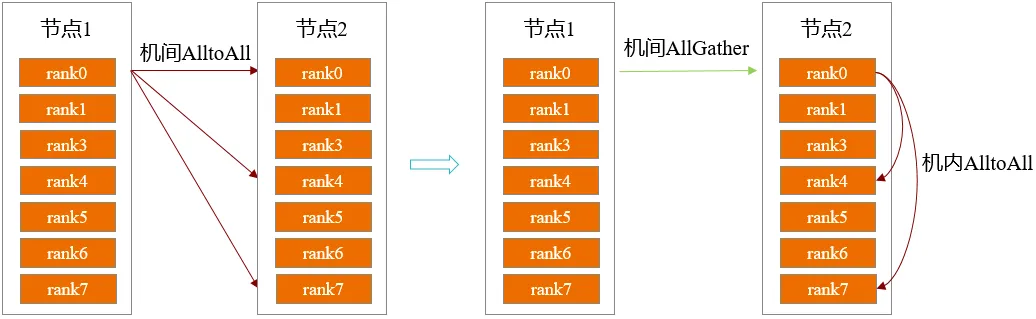
图1. 机间通信合并前后流程示意图
2、细粒度计算通信掩盖
研究团队通过性能调优工具分析实跑算子下发与执行时间,精准发掘出流水线并行、重计算、梯度计算中通信的可掩盖点,通过通信与计算掩盖实现通信算子耗时隐藏。
在流水线并行方案中,调整了micro batch之间的执行顺序,消除相邻前反向数据依赖,成功实现AlltoAll通信的掩盖。针对重计算过程中的通信掩盖问题,细粒度调度不同transformer层重计算过程中的计算与通信时序关系,实现多层通信相互掩盖。同时通过将GroupedMatmul梯度计算与反向过程中通信算子相互掩盖,减少反向过程中未掩盖通信。通信与计算相互掩盖如图2所示。
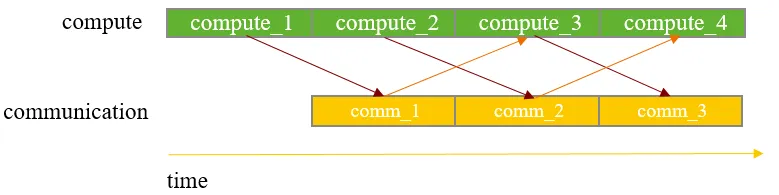
图2. 通信与计算相互掩盖示意图
# 02
并行策略优化
1、TP_EXTEND_EP 并行策略
传统的张量并行(Tensor Parallelism)会对Attention及FFN进行张量的切分,然而小专家场景张量并行切分后存在GroupedMatmul算子效率下降问题。为了避免小专家场景张量并行对专家参数切分导致AICore利用率过低从而造成GroupedMatmul算子效率劣化,研究团队设计了TP_EXTEND_EP 并行策略方案,即在FFN模块张量并行不切分专家权重,转而切分专家数,从而减少因切权重产生的AllGather、ReduceScatter算子,减少通信时间。如图3所示,假设TP=2、EP=2,专家个数为4,自定义并行策略前后分别如图左右两部分所示。以专家E1为例,在未TP_EXTEND_EP前, 专家E1的参数TP切分平均分布在rank0、rank1上,在TP_EXTEND_EP后, 专家E1的参数完整得保留在rank0上,从而减小因专家E1参数分布在不同卡上而产生的额外通信。使用TP_EXTEND_EP后, 通信算子的减少情况如图4所示,FFN前后的AllGather与ReduceScatter消失。
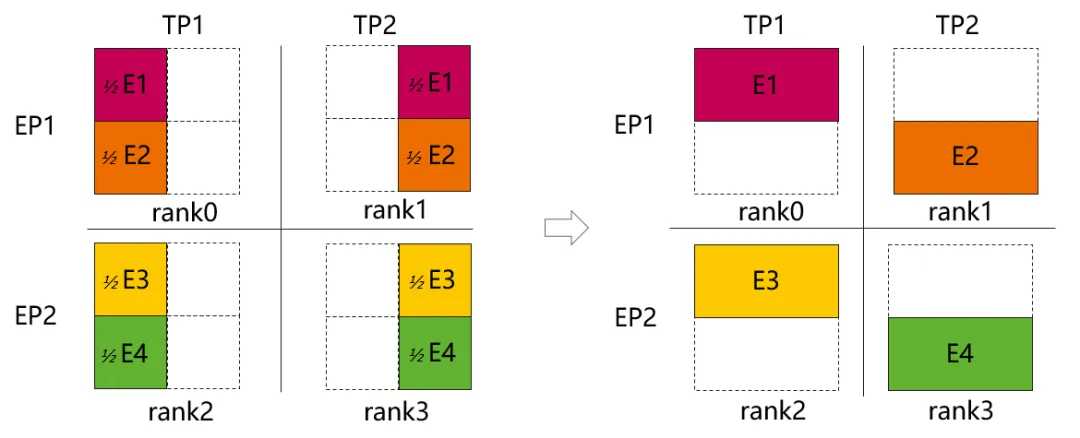
图3. TP_EXTEND_EP并行策略示意图。其中E1,E2,E3,E4分别代表4个专家。
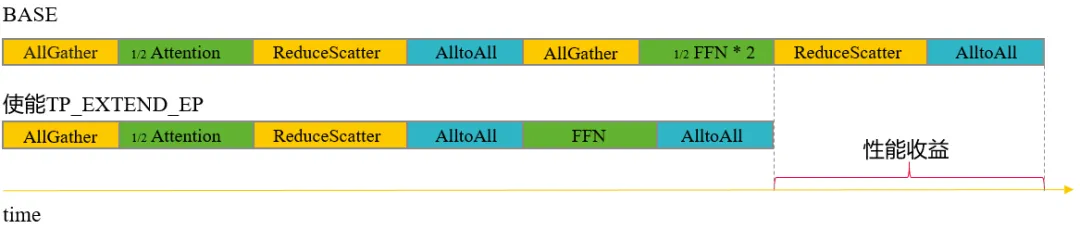
图4. TP_EXTEND_EP的算子执行流程示意图
# 03
算子优化
1、FlashAttention支持非对齐计算
当前MLA实现方式是基于张量填充的规整化处理方法,通过显式填充操作将V张量的头维度扩展到与Q、K对齐,该方法在保持传统FA算子计算规整性同时引入了额外的填充及切片操作。针对这一场景,研究团队根据数学等价推导,实现了支持Q、K、V头维度非对齐计算,省掉了填充操作,从而减少了计算量,提升了FA计算性能。
2、高性能AlltoAll算子
原AlltoAll算子需要通过AllGather将动态的send count数组进行一次交互。研究团队采用高性能AlltoAll算子则可以直接传入send count数组从而省去调度其间的AllGather动作,实现算子调度性能提升。
3、图算融合升级
针对大量零散的Memory Bound小算子,研究团队通过图算融合与周边算子进行自动融合,降低访存开销,提升整体算力利用率。在默认Vector类融合基础上,研究团队额外新增使能了:
1) Cube类融合:针对MOE大量出现的GMM、BMM等Cube类算子,通过Cube与Vector类算子融合,实现Cube核与Vector核的并发执行;
2) 并行融合:将网络多分支的相互无依赖的算子融合并编排在不同核并行执行,提升多核利用率。
基于昇思MindSpore与天翼云的深度协同,双方通过通信优化(机间合并/计算掩盖)、并行策略(TP_EXTEND_EP)及算子升级(非对齐FlashAttention/融合算子)三大核心技术,实现DeepSeek V3 MoE模型训练性能83%突破性提升,树立昇腾AI基础软硬件平台大模型训练效能标杆。
此次合作不仅验证了软硬件基础平台对复杂AI架构的全面支撑能力,更以“极致性能+极致成本”双突破为千行万业提供高效训练范式。未来,昇思MindSpore将携手更多伙伴,持续加速使能大模型创新,共筑智算未来。