开源首发,昇思MindSpore支持盘古Pro一键部署,内附手把手教程
开源首发,昇思MindSpore支持盘古Pro一键部署,内附手把手教程
近日,华为于2025年5月28日发布的大语言模型盘古Pro 正式开源。依托对MoE的完备支持,昇思MindSpore支持盘古Pro MoE的开源首发,并已将MindSpore版的盘古Pro MoE推理代码上传至开源社区,实现分钟级、一键式的vLLM服务化部署。
模型卡片:
混合专家模型(Mixture of Expert)能够以较低的计算成本支持更大的参数规模,已成为大语言模型的重要发展方向。2025年5月28日,华为发布了总参数量 720 亿、激活参数量160亿的盘古Pro MoE模型。盘古Pro MoE模型使用了创新的分组混合专家模型(Mixture of Grouped Experts, MoGE)架构,在专家选择阶段对专家进行分组,并约束各组分别激活等量专家,从而实现专家负载均衡和提升昇腾平台计算效率。
昇思MindSpore此前已支持DeepSeek-V3/R1、Qwen3-235B、GLM-Z1、MiniCPM4等40余款主流大语言模型,具备对混合专家模型的完备支持能力,并支持通过vLLM进行服务化部署,有效提升系统吞吐率。通过算子融合、模型并行等优化,以及对盘古Pro MoE模型的权重、激活和KVCache的量化支持,当前使用vLLM+MindSpore在昇腾Atlas 800I A2已完成部署验证,同时支持昇腾Atlas 300I Duo。
# 01
技术特性
1、支持vLLM 0.8.3 V0/V1版本的核心特性
昇思MindSpore社区开发了vLLM-MindSpore开源插件,支持使用vLLM部署MindSpore推理模型。该方案在vLLM连续性批调度、KVCache分页管理、Chunked Prefill、Prefix Cache等服务特性的基础上,叠加MindSpore即时编译、图算融合、混合量化等推理加速能力,实现了昇腾AI处理器上大模型推理的极致性能与快速部署。
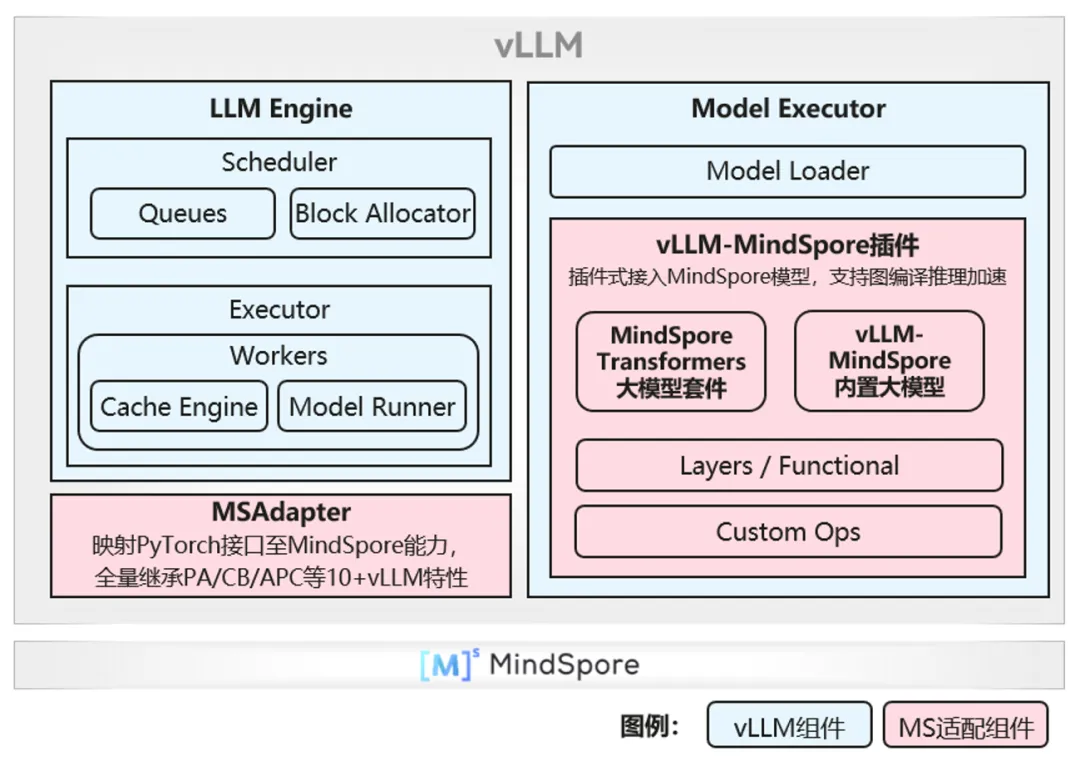
当前vLLM-MindSpore主干分支已适配vLLM v0.8.3版本,支持V0/V1架构。
2、量化推理
昇思MindSpore社区与华为诺亚实验室、泰勒实验室联合打造了模型量化压缩算法套件金箍棒(https://gitee.com/mindspore/golden-stick),支持SmoothQuant、AWQ、GPTQ等业界主流后量化算法以及多种自研量化算法。为了提升量化推理效率和降低精度损失,使用自研混合精度量化算法,自动搜索最优量化策略,可实现盘古网络几乎精度无损的8bit量化(A8W8),也可进一步对量化后的权重进行精度补偿,实现4bit量化。
除了对模型参数和激活值量化以外,还可对KVCache进行了量化,以节省显存和提升Batch Size。金箍棒套件支持静态量化与动态量化两种KVCache模式。由于vLLM暂未支持KVCache动态量化参数的管理,因此在是使用vLLM部署盘古Pro MoE时,仅可使用KVCache静态量化。
3、多种自注意力算子及向量排布
昇思MindSpore在盘古Pro MoE推理模型中支持了多种Attention算子,可在不同应用场景下获取最优计算性能:使能Prefix Cache、Chunked Prefill的场景,可选用Paged Attention算子;其它场景,Prefill阶段可选用PromptFlashAttention算子,Decode阶段可选用IncreFlashAttention算子。
此外,在大Batch Size场景,昇思MindSpore支持自适应选择NZ格式的Matmul算子,实现单算子性能提升40%。在昇腾300I Duo上的自注意力计算部分也采用NZ格式,因此vLLM-MindSpore插件还支持了NZ格式的KVCache管理。
4、并行推理
昇思MindSpore支持TP、EP、DP、SP等多种并行策略,此次使用TP(Attention) + EP(MoE)加速盘古Pro MoE模型推理,后续还将引入DP、SP等并行加速策略。
# 02
部署指南
盘古Pro MoE模型推理建议使用1台(8卡) Atlas 800I A2(64G)服务器(基于BF16权重)。昇思MindSpore提供了盘古Pro MoE推理专用的Docker容器镜像,供开发者快速体验。
1、下载模型权重
执行以下命令将模型权重的自定义下载路径 /home/work/PanguProMoE 添加到白名单:
export HUB_WHITE_LIST_PATHS=/home/work/PanguProMoE
执行以下 Python 脚本,从魔乐社区下载昇思 MindSpore 版本的 盘古Pro MoE模型权重文件至指定路径 /home/work/PanguProMoE 。下载的文件包含模型配置、模型权重和分词模型,占用约 150GB 的磁盘空间:
from openmind_hub import snapshot_download
snapshot_download(
repo_id="MindSpore-Lab/Pangu-Pro-MoE",
local_dir="/home/work/PanguProMoE",
local_dir_use_symlinks=False
)
注意事项:
- /home/work/PanguProMoE 可修改为自定义路径,需要确保该路径有足够的磁盘空间(约 150GB)。
- 下载时间可能因网络环境而异,建议在稳定的高速网络环境下下载,10MBps网速下,预计下载时间4小时。
2、下载昇思 MindSpore盘古Pro MoE推理容器镜像
执行以下 Shell 命令,拉取昇思 MindSpore 盘古Pro MoE推理容器镜像:
docker pull swr.cn-central-221.ovaijisuan.com/mindsporelab/pangu_pro_moe_mindspore-infer:800-A2-20250623
3、启动容器
执行以下命令,创建并启动容器:
docker run -it --privileged --name=pangu_pro_moe --net=host \
--shm-size 500g \
--device=/dev/davinci0 \
--device=/dev/davinci1 \
--device=/dev/davinci2 \
--device=/dev/davinci3 \
--device=/dev/davinci4 \
--device=/dev/davinci5 \
--device=/dev/davinci6 \
--device=/dev/davinci7 \
--device=/dev/davinci_manager \
--device=/dev/hisi_hdc \
--device /dev/devmm_svm \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v /usr/local/Ascend/add-ons:/usr/local/Ascend/add-ons \
-v /usr/local/sbin:/usr/local/sbin \
-v /usr/local/sbin/npu-smi:/usr/local/sbin/npu-smi \
-v /etc/hccn.conf:/etc/hccn.conf \
-v /home:/home \
swr.cn-central-221.ovaijisuan.com/mindsporelab/pangu_pro_moe_mindspore-infer:800-A2-20250623 \
/bin/bash
后续所有操作均在容器内进行。
4、启动推理服务
执行以下shell命令启动推理服务:
vllm-mindspore serve "/home/work/PanguProMoE" --trust-remote-code --tensor-parallel-size=8 --gpu-memory-utilization=0.9 --max-num-batched-tokens=2048 --max-num-seqs=512 --block-size=128 --max-model-len=32768
执行以下命令,发送推理请求进行测试:
curl http://localhost:8000/v1/completions -H "Content-type: application/json" -d '{"model": "/home/work/PanguProMoE", "prompt": "[unused9]系统:[unused10][unused9]用户:请简单介绍一个北京的景点[unused10][unused9]助手:", "max_tokens": 1024, "temperature": 0.0}' &
本文档提供的模型代码和镜像,当前仅限用于测试和体验昇思MindSpore盘古Pro MoE模型的推理服务化部署,不建议用于生产环境。如遇使用问题,欢迎反馈至Issue(https://gitee.com/mindspore/mindformers/issues/new)。
基于昇思MindSpore对MoE架构的深度优化与vLLM的极致融合,盘古Pro MoE的开源标志着大模型在高效部署领域取得重大突破。本次开源不仅验证了昇腾AI处理器对千亿级稀疏大模型的全面支撑能力,更通过容器化封装、量化压缩与并行策略优化,实现分钟级一键开箱部署,为开发者提供开箱即用的MoE模型服务化体验。未来,昇思将持续支持主流大模型演进,并根据开源情况面向全体开发者提供镜像与支持。