重生之大腿带我征服MindSpore(三):勇者的宿命,与并行女神的浪漫共舞
重生之大腿带我征服MindSpore(三):勇者的宿命,与并行女神的浪漫共舞
作者:C帅
单位/来源:昇思MindSpore社区论坛
大模型火热的当下,模型大小动辄百亿千亿,其大到需要基于成千上万张卡进行分布式训练。分布式训练本质上是将单卡的计算逻辑切分到多卡,而并行组需要让单卡与分布式在IR图上保证计算逻辑等价。本期将详细为大家带来数据并行、张量并行和流水线并行。
# 01
开场白
**【主持人致辞】:**大家好,欢迎大家莅临本期的《重生之大腿带我征服 MindSpore》栏目。今天,我们很荣幸地邀请到并行组的核心骨干-->C帅带领我们进行MindSpore自动并行相关模块的学习与实践,欢迎彬总!!
【C帅】: 谢谢大家~ 呵呵呵。
**【主持人& C帅】:**大模型火热的当下,模型大小动辄百亿千亿,其大到需要基于成千上万张卡进行分布式训练。分布式训练本质上是将单卡的计算逻辑切分到多卡,而并行组需要让单卡与分布式在IR图上保证计算逻辑等价。这里之所以说的 IR 图上等价,是因为计算算子的通信算子可能引入精度误差,但是图一定是需要等价的。
【主持人】:(内心OS:上次邀请的 SE 抢台词,这位怎么也抢?)
# 02
访谈环节
常见的分布式训练方式
**【Note】:**本文中提到的数据并行模型指的是在 MindSpore 半/全自动并行模式下的实现。
**【主持人】:**C帅,常见的分布式训练方式是什么呢?
**【C帅】:**常见的分布式训练方式主要是数据并行、张量并行、流水线并行。
数据并行:顾名思义就是在数据维度进行并行计算,这里的数据维度通常指的是 batch 维。可以理解我们拥有 data_paralleldata_parallel 个模型,每个模型计算 batch_sizebatch_size 条数据,那么我们的完整模型就等价于一次计算 data_parallel∗batch_sizedata_parallel∗batch_size 条数据。
模型并行:张量并行和流水线模型都属于模型并行。LLM 大多都是由很多层 Transformer 结构堆叠而成的,张量并行就是对层内的 tensor 进行切分,流水行并行就是对层间的 tensor 进行切分。因此他们又分别被叫做层内(inter-layer)模型并行和层间(intra-layer)模型并行。
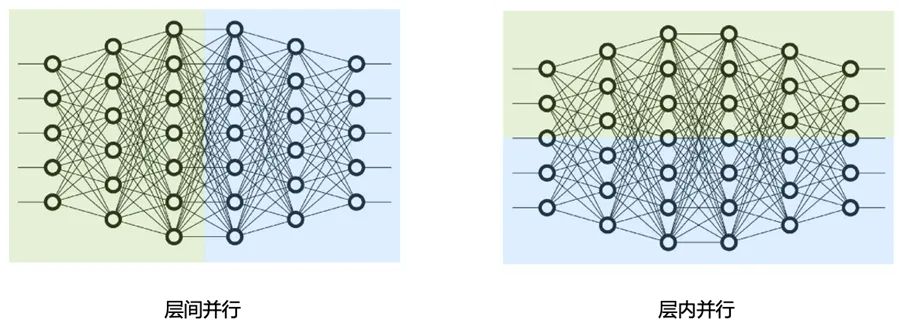
具体来说,张量并行就是对某一层内的所有 tensor 进行切分,这个切分可以是横着切,也可以竖着切。而流水行并行是根据层对 tensor 进行切分,比如1个4层的LLM 网络,可以把前面2层放在1个设备上,后2层放在另外一个设备上。
**【主持人】:**那是不是可以这样理解:
1)数据并行同时有多个模型在跑,模型并行只有一个模型
2)张量并行每个设备上的 tensor 都是不完整的,因为它会被横着切,或者竖着切。
3)流水行并行每个设备上都不会有完整模型的权重,因为它是根据不同层切分的。
**【C帅】:**对,你说的很对,现在你已经具备并行基础知识了,欢迎加入并行组。
**【主持人】:**本栏目谢绝打广告!!!
**【观众】:**嗯? 招聘广告也能植入?
数据并行以及MindSpore中的实现
数据并行原理
**【主持人】:**C帅,刚才这个介绍,我相信你只是为了方便大家理解,可以再详细地对数据并行的原理进行展开吗?我相信还有一些观众可能和我一样,只是一知半解的。
**【C帅】:**没有没有,能听懂已经很强了,真的。其实数据并行本质上就是因为数据集太大了,需要使用更多的算力加速训练。所以我们会有多个模型部署在不同的设备上,每个模型接受不同的输入,假设有 data_paralleldata_parallel 个设备,每个设备处理的输入大小是 (batch_size,hidden_size)(batch_size,hidden_size), 那么它的结果应该等价于模型部署在单卡上,一次接受 data_parallel∗batch_sizedata_parallel∗batch_size 条数据的结果。
举个简单的例子,假如我们 dp = 2,batch_size = 1,那相当于 npu 0、1 都接受bs = 1 大小的数据,接着分别在各自的设备上进行前、反向计算。最后计算的梯度的时候,需要执行一个梯度的 AllReduce Mean,最后每张卡基于这个梯度进行参数更新。
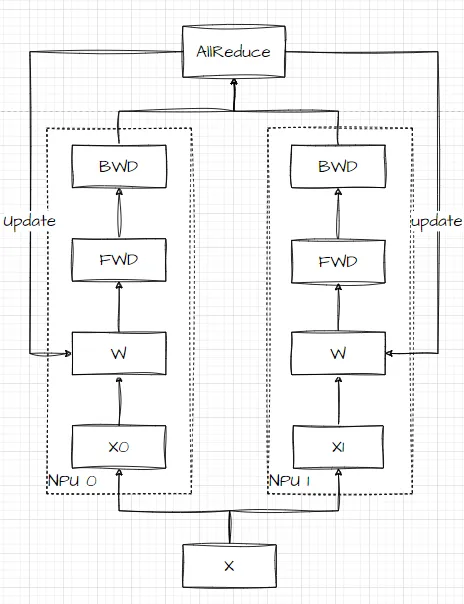
**【主持人】:**桥豆麻袋!为什么要把模型部署在不同的设备上,不是一个模型就行了嘛?这不是重复了吗?
**【观众】:**对呀对呀~
**【C帅】:**你看,我说什么来着,我就说大家都很专业嘛。这个就是鼎鼎大名的ZERO(Zero Redundancy Optimizer)。根据优化器状态、梯度、参数的切分,依次叠加,分别称作 Zero-1,Zero-2, Zero-3。
Zero-1 主要针对 adam 优化器的动量 m、v 做了切分,这两个部分在不切分的状态会占用 4+4=8Φ4+4=8Φ 的静态内存,开启切分的场景,那么这部分内存的占用就会降低到 8NΦN8Φ, 这里的 NN 代表切分数量,ΦΦ 代表模型参数量。
Zero-2 则在Zero1 的基础上继续对梯度进行切分,这里的梯度通常为2Φ2Φ, 切分后,其占用的内存量则为 2NΦN2Φ, 但是这部分在 MindSpore 通常不被统计到静态内存中,所以我们知道就行。
Zero-3 则在Zero2 的基础上进行对参数进行切分,根据参数初始化的类型(fp16,fp32) 决定其占用内存是 2Φ,4Φ2Φ,4Φ, 在考虑精度的场景,这里通常都是使用 fp32 进行初始化,也就意味着 4Φ4Φ --> 4NΦN4Φ。
对于 MindSpore 来说,静态内存的占用就可以从 (4+4+4)Φ(4+4+4)Φ 降低到 12nΦn12Φ。
MindSpore中的数据并行
**【主持人】:**C帅,ZERO 的不同 stage 竟然可以省下这么多内存,那么在 MindSpore 中我们要如何使能呢?
**【C帅】:**主要由 enable_parallel_optimizer 和 optimizer_weight_shard_size 控制。前者控制是否开启优化器切分,后者控制切分的份数,也就是可以切不满(op
**【主持人】:**zero-1、zero-2,zero-3? 是不是应该有3个变量啊?
**【C帅】:**从 MindSpore 目前的实现来看,是不存在和zero1/2 对应的实现方式的。MindSpore 开启优化器切分后,一定会去切分权重,这与 zero1/2的行为不符。zero3 可以实现类似的效果,即切优化器状态、切梯度、切权重。
另外,在开启梯度累加的时候,通常是不开启梯度切分的,因为其会影响性能,即设置 gradient_accumulation_shard=False。
# 03
课后作业
【主持人】:没想到啊,浓眉大眼的你,竟然留作业!
【C帅】:为了世界和平,为了大家的学业事业有成。
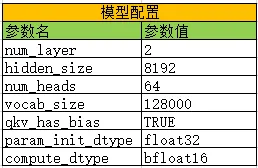
请大家以如下配置进行图相关的分析,主要内容如下:
【1】梯度计算(必修)
【2】数据处理(选修)
【3】loss计算(选修)
【某位不愿透露姓名的A帅】:我勒个去,上班还要做作业?
dp 图分析
基于上面的参数进行设置,我们可以得到类似附件中 18_validate_0761_dp.ir.txt 文件(txt 是因为不支持上传 ir 后缀的文件而修改的)
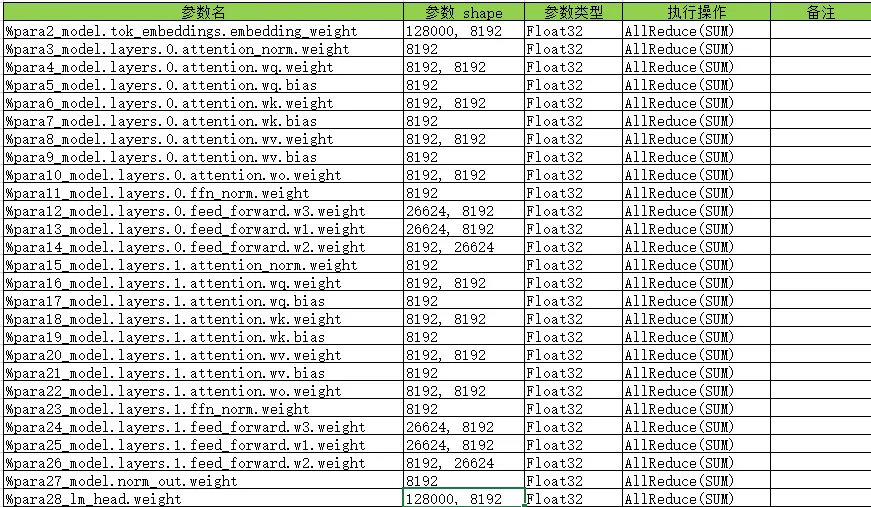
可以看到,两层的网络共有 27个参数,那么我们应该有 27个AllReduce。关于 norm_out.weight的AllReduce 可如下所示:
%20(dx) = AllReduce(%19) {instance name: grad_mirror_MirrorOperator} primitive_attrs: {group: "hccl_world_group", fusion: I64(8), op: "sum", no_eliminate: Bool(1), index: I64(0), group_rank_ids: (0, 1)} cnode_primal_attrs: {forward_node_name: "_MirrorOperator_91638", forward_unique_id: "91638", mirror_user_id: "model.norm_out.weight"}
这里AllReduce 节点都存在对应的 mirror_user_id。
除此之外,还有3个 AllReduce 的功能分别如下:
1.global norm 计算:
%288(CNode_2123) = AllReduce(%287) {instance name: PARALLEL_GLOBALNORM_IN_STAGES} primitive_attrs: {comm_reuse: Bool(1), group: "hccl_world_group", fusion: I64(0), op: "sum", rank_list: (0, 1), group_ranks: "WORLD_GROUP", index: I64(0), group_rank_ids: (0, 1), keep_value_node_input: Bool(1), no_eliminate: Bool(1)}
2.溢出标志位计算:
%202(flag_reduce) = AllReduce(%201) {instance name: allreduce} primitive_attrs: {comm_reuse: Bool(1), group: "hccl_world_group", fusion: I64(0), op: "sum", rank_list: (0, 1), index: I64(0), group_rank_ids: (0, 1), no_eliminate: Bool(1)}
3.溢出标志位代码:
这里是因为没有区分大小写,所以搜到了源码部分,可忽略:
flag_reduce = self.allreduce(flag_sum)
op 图分析
类似的,我们可以得到类似附近中的 18_validate_0761_op.ir.txt:
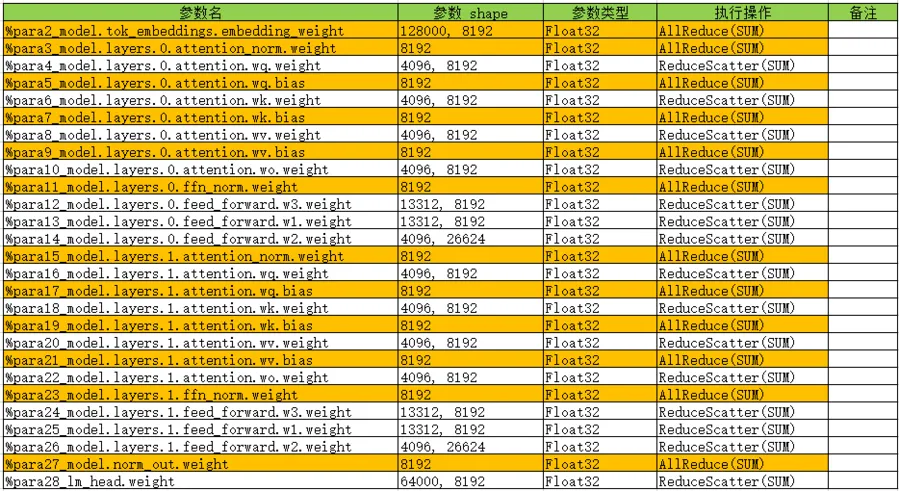
这里仍然是 27个参数,其中15个参数转变为 ReduceScatter,剩下12个参数仍然是AllReduce的原因是因为参数大小未超过阈值64KB,可以通过显式的设置 parallel_optimizer_threshold:0来强制开启。
关于 wv.weight 的 ReduceScatter 可如下所示:
%49(dx) = ReduceScatter(%48) {instance name: grad_parallel_optimizer_allgather_not_recompute} primitive_attrs: {group: "hccl_world_group", rank_size: I64(2), fusion: I64(1), op: "sum", no_eliminate: Bool(1), group_rank_ids: (0, 1)} cnode_primal_attrs: {forward_node_name: "AllGather_90868", forward_unique_id: "90868", mirror_user_id: "model.layers.0.attention.wv.weight"}
这里的 ReduceScatter 和前向的AllGather 是对应的,因为前向我们需要将切分的权重聚合后,才能进行正向的计算。
# 04
自由提问
为什么梯度附近会有一个 virtual div?
【小来】:C帅,您好。我对并行训练很感兴趣,自己也私底下跑了一些实验,在看 ir 图的时候发现在梯度附近,会插入一个 virtural div 算子,这个算子的作用是什么呢?
【C帅】:要理解这种情况,我们需要比较单卡和多卡的异同点,这里以dp=2, device_num=2 为例。
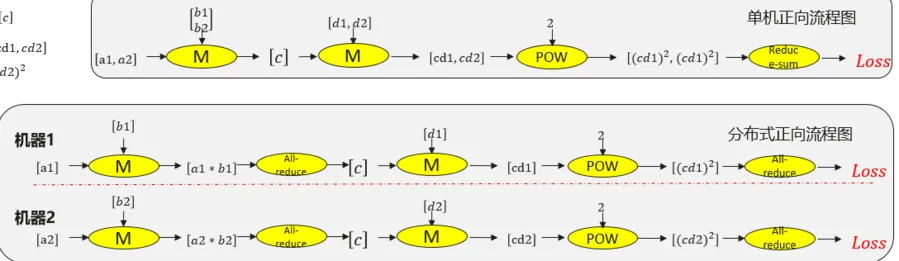
在 MindSpore 中,每张卡都会输出1个loss,如果dp=2的话,每张卡会输出一样的loss,共输出2个loss。这个可以理解吧?
【观众 && 小来】嗯嗯,可以理解。
【C帅】:那本来两张卡应该只算自己的loss,理论上loss 是不是只有原来的一半,这时候梯度进行相加,和单卡就是一样的。但是现在每张卡的 loss 都一样,每张卡的loss 都翻倍了,那你的梯度就要除以 2.
【小来】:哦。(此人晕过去了,无法继续提问,被跳过了)
为什么执行的是梯度的算子是 Sum 而不是 Mean
【小A】:对于 megatron 来说,其执行的是 AllReduce Mean,在ms 框架里面是 AllReduce Sum,那么这两个框架的精度能对上吗?
【C帅】:嗯,好问题。虽然 ms 框架侧做的是AllReduce Sum,但是会在loss后面会插入一个 div 算子,将每张卡的loss缩小为stage_per_device 倍,这样,就等价于 AllReduce Mean了。在本例种,这里就是2.这里的机制解析我已经传授给我的独家大弟子了,可以参考文章:https://www.hiascend.com/forum/thread-02113175249536152076-1-1.html
最后感谢热忱的C帅。