【昇思MindSpore技术公开课】第十讲 MoE 课程回顾
【昇思MindSpore技术公开课】第十讲 MoE 课程回顾
昇思MindSpore公开课大模型专题第二季课程火爆来袭!未报名的小伙伴抓紧时间扫描下方二维码参与课程,并同步加入课程群,有免费丰富的课程资源在等着你。课程同步赋能华为ICT大赛2023-2024,助力各位选手取得理想成绩!

大模型发展即将进入下一阶段但目前仍面临众多难题。为满足与日俱增的实际需求,大模型参数会越来越大,数据集类型越来越多,从而导致训练难度大增,同时也提高了推理成本。为了实现大模型的高效训练和推理,混合专家模型MoE便横空出世。
1**、**MoE结构的发展
1.1 Vanilla MoE
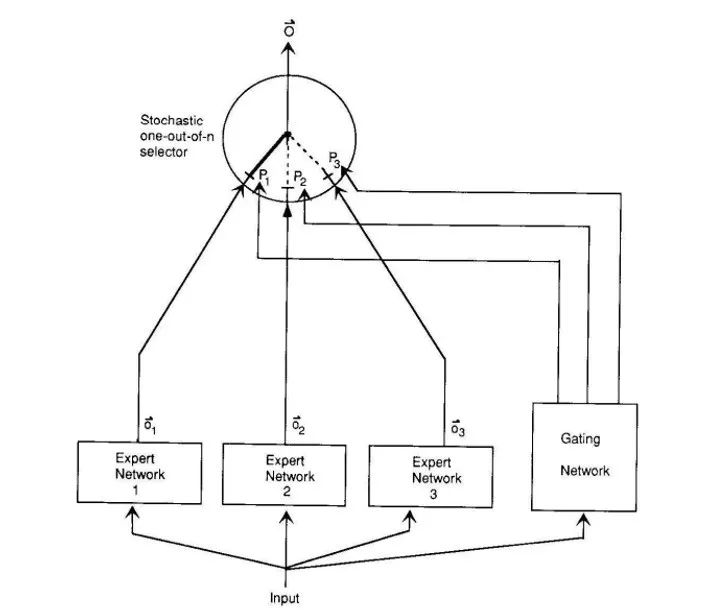
Export Network,用于学习不同数据,一个Gating Network用于分配每个Expert的输出权重。
1.2 Sparse MoE
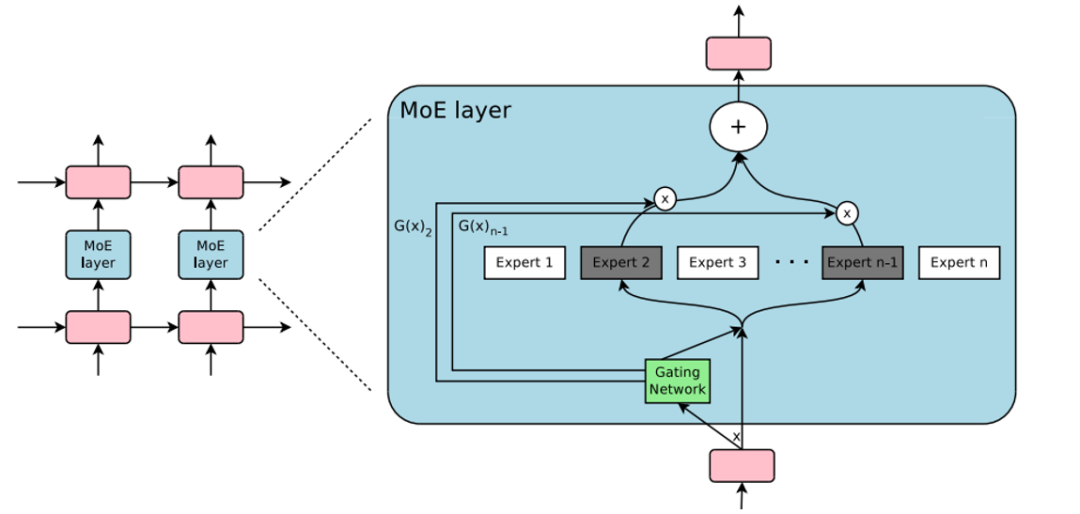
Experts的输出是稀疏的,只有部分的Experts的权重> 0,其余=0的Expert直接不参与计算。
**Expert Balancing问题:不同Experts在竞争的过程中,会出现“赢者通吃”的现象。**前期变现好的Expert会更容易被Gating Network选择,导致最终只有少数的几个Experts真正起作用。
1.3 Transformer MoE
1)GShard
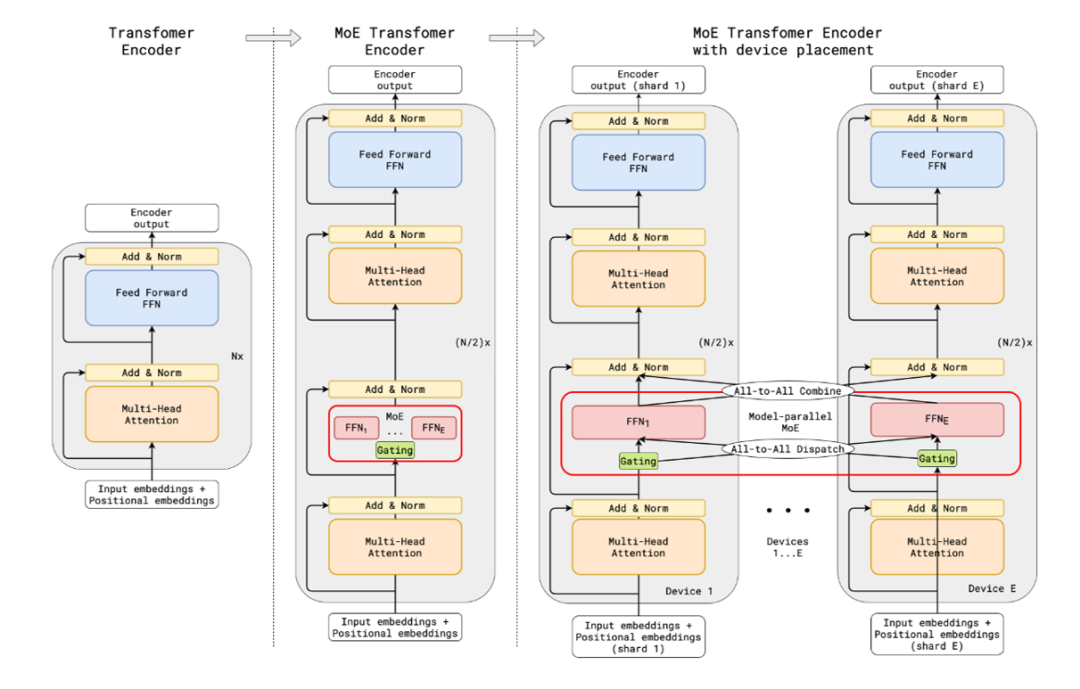
- Transformer的Encoder和Decoder中,每隔一个(every other)FFN层,替换成Position-wise MoE层。
- Top-2 Gating Network。
2)Switch Transformer
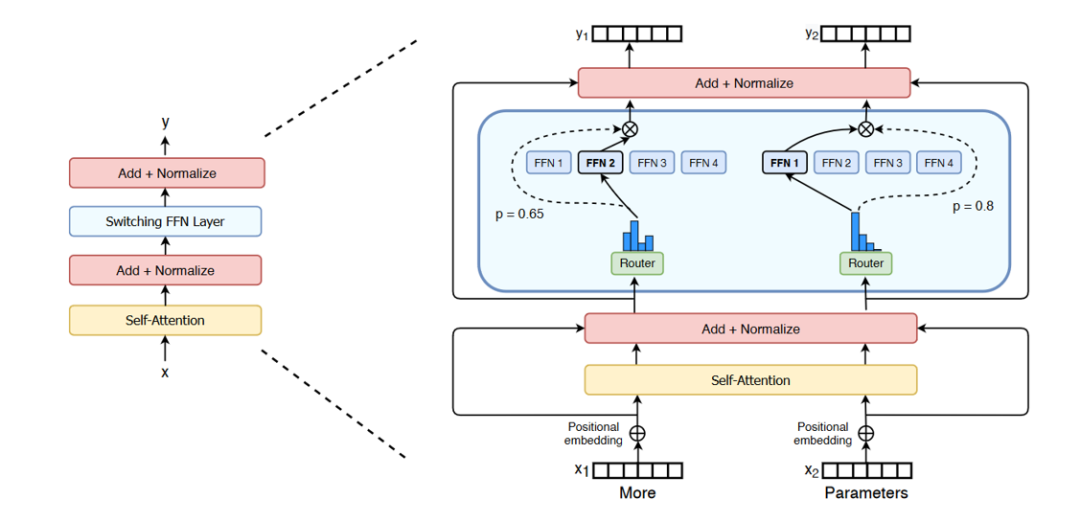
简化了MoE的Routing算法,Gating Network每次只Route 到1个Expert。
3)GLaM
- Gshard结构
- Scale参数量
- 降低训练推理成本
**2、**MoE的分布式通信和昇思MindSpore优化
2.1 MoE的分布式通信和昇思MindSpore优化
MoE结构和普通的Dense模型的差异在于,其需要额外的AllToAll通信,来实现数据的路由(Gating)和结果的回收。而AllToAll通信会跨Node(服务器)、跨pod(路由),进而造成大量的通信阻塞问题。
2.2 昇思****MindSpore的MoE优化
大模型训练主要瓶颈在于片上内存与卡间通信。常用的内存优化手段:MoE并行、优化器异构,常用的通信优化手段、多副本并行。 1)MoE并行:将不同的专家切分到不同的卡上,由于MoE的路由机制,需要使用AllToAll通信,将token发送到正确的卡上。对AllToAll的优化:分级AllToAll、Group-wise AllToAll等。 2)优化器异构:大模型训练常使用的adam系列优化器,其占用的内存往往是模型参数本身的2倍或以上,可以将优化器状态存储在Host内存上。 3)多副本并行:将串行的通信、计算拆分成多组,组件流水,掩盖通信时间。
昇思MindSpore已使能上述优化,大幅提升了万亿参数稀疏模型的训练吞吐。
3**、**Mixtral 8x7B MoE大模型
3.1 Mixtral的基础模型Mistral

1)RoPE
2)RMSNorm
3)Transformer decoder
4)Grouped Multi-Query Attention
5)Sliding Window Attention: 优化随着序列长度增加而增长的显存占用和计算消耗
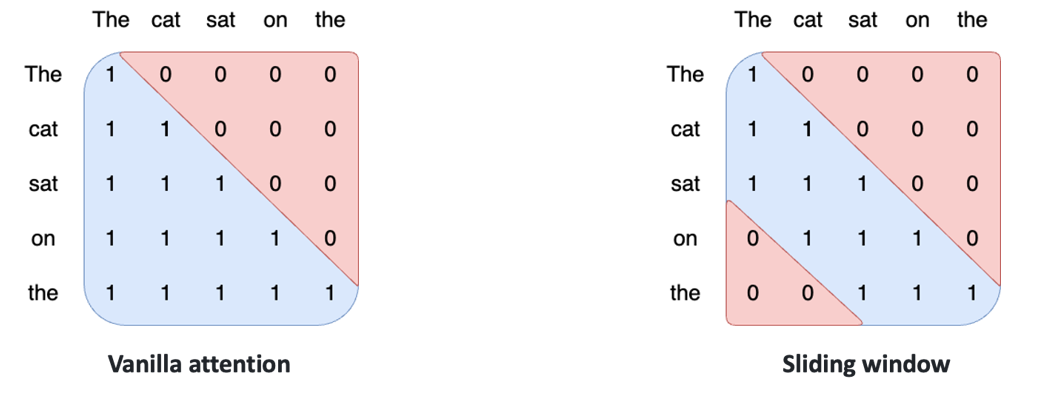
3.2 Mixtral
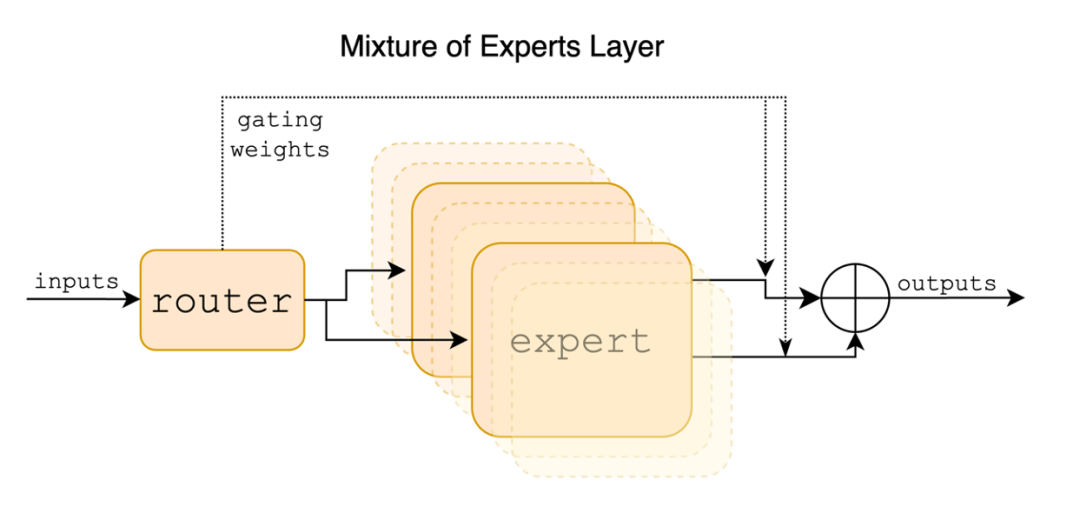
1)8个Expert(类GPT-4)
2)Top2 Gating

class MoeLayer(nn.Cell):
def _init_(self,experts: List[nn.Cell], gate: nn.Cell, moe_args): MoeArgs):
super()._init_()
assert len(experts)>0
self,experts = nn.cellList(experts)
self.gate = gate
self.args = moe_args
def construct(self,inputs:mindspore.Tensor):
gate_logits: self.gate(inputs)
weights,select_edexperts = ops.topk(gate_logits,self.args.num _experts_per_tok)
weights = ops.softmax(weights,axis=1, dtype=mindspore.float32).to(inputs.dtype)
results = ops.zeros_like(inputs)
for i,expert in enumerate(self.experts):
non zero = ops.nonzero(selected_experts == i)
if 0 not in non_zero.shape:
batch_idx,nth_expert= non_zero.tensor_split(2,1)
results[batch_idx] = results[batch_idx] + weights[batch_idx, nth_expert, None] * expert(
inputslbatch idx]
}
return results

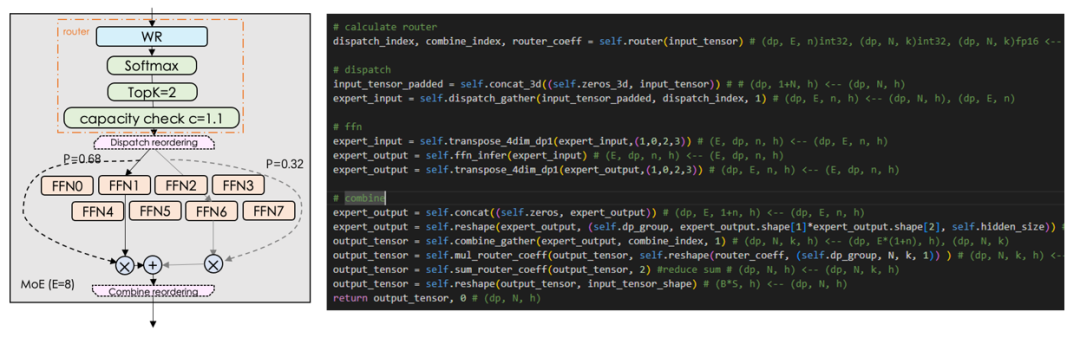
1)基于MindFormers实现Mixtral-8x7B MoE模型。
- 关键结构: GQA,RoPE,RMSNorm,Silu。
- MoE配置: 8 Experts,TopK=2,capacity c=1.1。
- 加载开源的Mixtral权重和tokenizer,推理结果对齐HF。
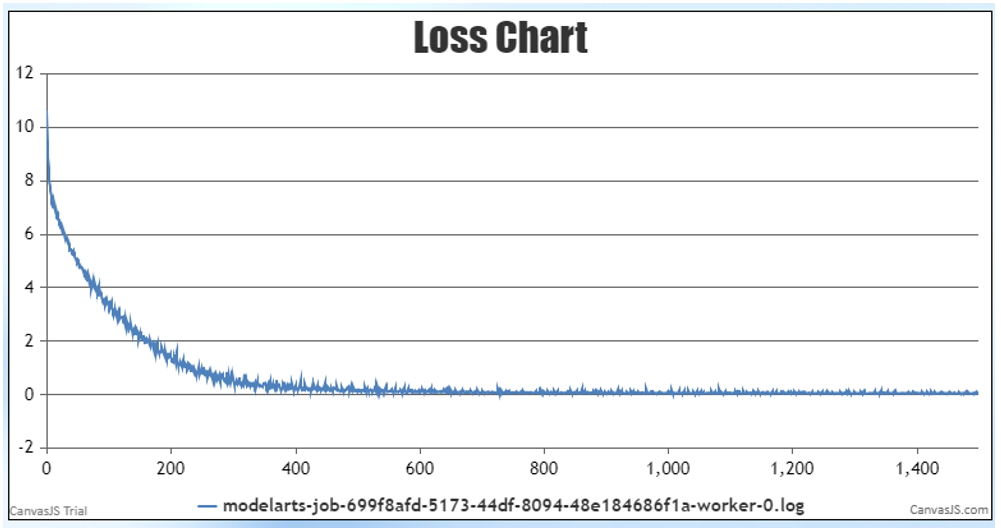
2)4机32卡EP,PP等多维混合并行,基于自有数据集试验性训练收敛符合预期。200 epoch loss 10 --> 0.02。
EP=8,MP=1时性能最佳,约1147 tokens/s/p。
4**、MoE和Lifelong learning**
4.1 终身学习/持续学习的性质
性质
定义
知识记忆(knowledge retention)
模型不易产生遗忘灾难
前向迁移(forward transfer)
利用旧知识学习新任务
后向迁移(backward transfer)
新任务学习后提升旧任务
在线学习(online learning)
连续数据流学习
无任务边界(No task boudaries)
不需要明确的任务或数据定义
固定模型容量(Fixed model capacity)
模型大小不随任务和数据变化
4.2 MoE模型+终身学习
性质
知识记忆(knowledge retention)
√
前向迁移(forward transfer)
√
后向迁移(backward transfer)
-
在线学习(online learning)
×
无任务边界(No task boudaries)
√
固定模型容量(Fixed model capacity)
√
MoE的特点:
- 多个Expert分别处理不同分布(domain/topic)的数据
- 推理仅需要部分Expert
LLM的终身学习:
- 世界知识底座持续学习。
- Expert可插拔
- Gating Network可增删。
4.3 MoE+终身学习的典型工作
1)Lifelong-MoE
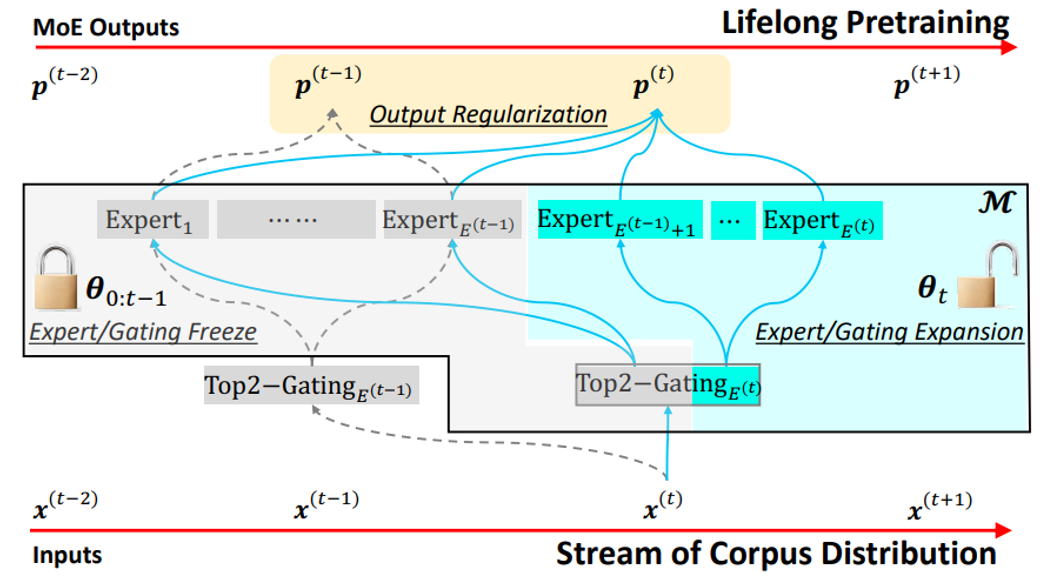
- 扩展Expert和Gating Network的维度
- 冻结旧的Expert和Gating Network维度
- 使用正则克服遗忘灾难
2)Pangu-sigma
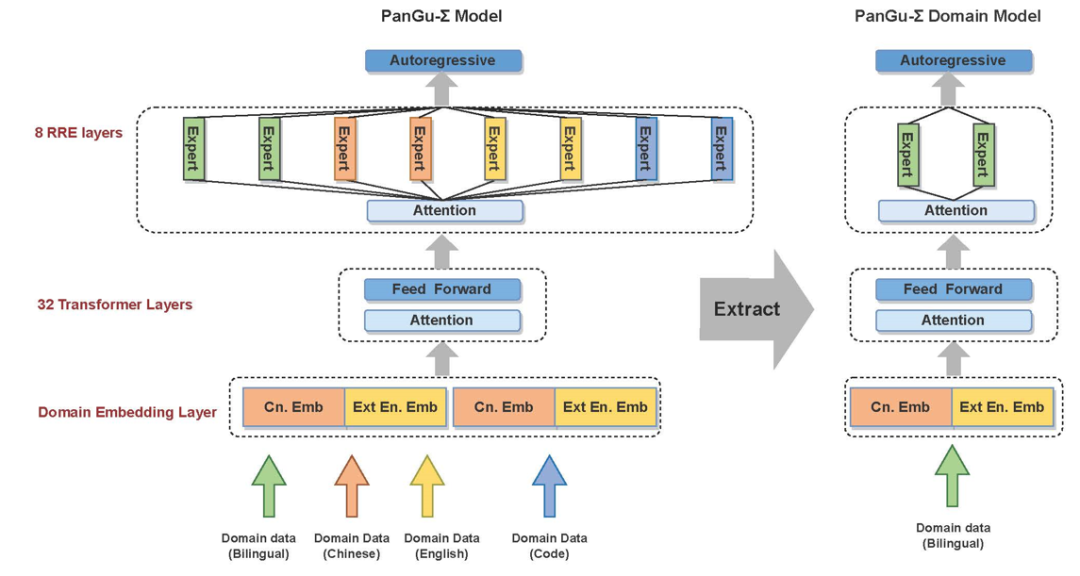
Random Routed Experts:
- 第一层,根据任务分配给不同的专家组(多个Expert构成一个专家组,供一个task/domain使用)
- 第二层,使用组内随机Gating,让专家组的Expert可以负载均衡。
这样可以保证某个领域对应的Expert可以直接被抽取出来作为单个模型使用。
5**、**Mixtral 8x7B Demo
Mistral-MindSpore:
https://github.com/lvyufeng/mistral-mindspore
Mindformer(MoE预训练):