昇思MindSpore2026年第一季度运作报告
昇思MindSpore2026年第一季度运作报告
概述
2026年第一季度,昇思MindSpore开源社区以技术创新为驱动,持续扩大生态影响力,在框架升级、开发者生态建设、行业应用落地等方面取得显著进展。
在技术突破方面,本季度重磅推出MindSpore 2.8版本,核心带来为超节点设计的HyperParallel架构;同时与SGLang社区深度合作,正式支持MindSpore后端,为大模型服务化提供高性能解决方案。
在社区合作方面,助力智谱训练并开源首个自主算力底座的SOTA图像生成模型GLM-Image;联合中国电信AI研究院开源首个全自主创新千亿参数MoE大模型TeleChat3-105B;携手浙江大学张强团队发布知识图谱驱动的SciToolAgent,相关成果登上《Nature Computational Science》。
在社区运作方面,社区通过举办“万码奔腾贺新春”活动开放稀缺算力,并同时开展《开源之夏》栏目共吸引103位学子参与,《昇思同路人》持续传递开发者故事,《创新训练营》优秀案例不断涌现。从大模型全流程课程到量子计算实战,昇思MindSpore正携手全球开发者,共同打造人工智能创新之源!
以下是2026年第一季度昇思MindSpore社区进展的详细报告。
社区运作
截至3月底,MindSpore 开源社区稳健运营、生态持续扩容,始终坚守开放协作、技术普惠、共建共治的核心原则,聚焦 AI 框架技术迭代、生态协同与开发者生态建设,社区组织架构高效运转、技术贡献与活跃度双提升,筑牢 AI 开源生态的坚实底座,推动全场景 AI 框架技术与产业应用深度融合。
社区单位会员达 354 家,累计贡献者5.2万+;
社区累计产生ISSUE共89.7K、PR共115.2K。
本季度社区治理体系高效运转,开源发展委员会、技术委员会常态化推进决策与技术统筹,各 SIG 小组协同发力,技术贡献与社区活跃度稳步攀升。技术委员会开展 2 次 TC 例会,统筹技术规划与版本演进。
社区 6 个活跃 SIG 小组协同发力,78 名 SIG 成员深度参与贡献;
累计提交 issue 310 个,合入 PR 1102 个;
新增代码行数超 45.9 万行,SIG 专项会议累计召开 24 场。
社区大事件
1、智谱联合昇腾+昇思,开源首个自主创新算力底座训练的多模态SOTA模型
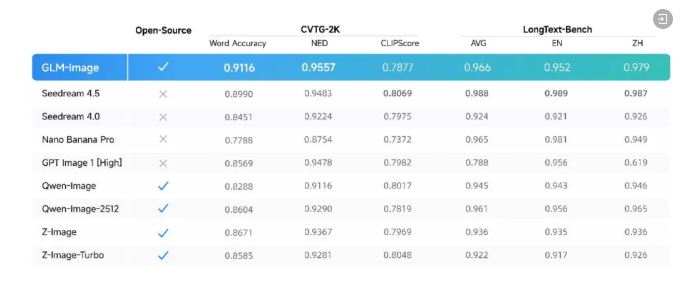
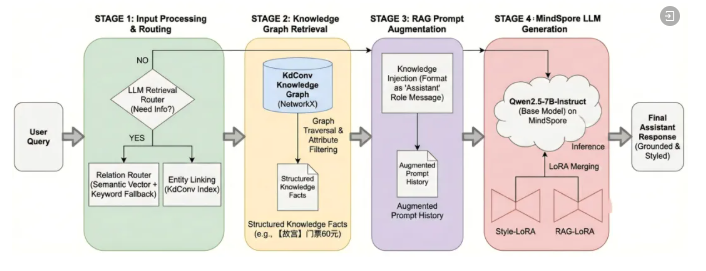
智谱正式发布图像生成模型GLM-Image,采用「自回归+扩散解码器」混合架构,是首个开源的工业级离散自回归图像生成模型,在文字渲染榜单CVTG-2K和LongText-Bench上达到开源SOTA水平。模型基于昇腾NPU和昇思MindSpore框架完成全流程训练,验证了自主创新算力底座也能训练出SOTA模型。昇思通过动态图多级流水下发、多流并行执行和高性能融合算子等优化,实现端到端训练性能提升。
2、国内首个全自主创新千亿参数细粒度MoE语义大模型开源
TeleChat3-105B-A4.7-Thinking是 TeleChat系列国内首个开源的全自主创新千亿参数细粒度MoE语义大模型,由中国电信人工智能研究院(TeleAI)研发训练,在问答、写作、数学、代码、Agent等多维度,特别在代码能力、复杂任务通用问答、细粒度MoE等方面效果显著。同时采用创新训练方式,加快模型训练初期收敛速度,增强训练稳定性。

3、浙江大学张强团队联手昇思MindSpore,成果登上Nature子刊
张强团队发布知识图谱驱动的SciToolAgent,这是一款面向多学科的通用AI智能体,能在生物、化学、材料等领域自动化调用和管理数百种科学工具。该成果基于昇思MindSpore与昇腾硬件协同创新,相关研究论文发表于《Nature Computational Science》期刊。

4、昇思MindSpore 2.8版本正式发布
1月29日,MindSpore 2.8版本正式发布,核心推出HyperParallel架构,通过HyperShard声明式并行、HyperOffload多级智能卸载和HyperMPMD非规则异构并行三大技术,将超节点视为超级计算机进行编程调度。
基础框架方面,增强动态图能力,支持Dispatch自动算子分发、saved_tensors_hook激活值管理和算子级注册机制,并开放自定义算子、PASS和后端能力。
推理能力上,与SGLang社区合作支持MindSpore后端,适配Radix Cache等特性,升级vLLM至0.11.0并接入ACLGraph图下沉功能。科学计算方面,支持蛋白质结构预测模型Protenix,通过重计算和算子优化实现高性能训练推理。
社区动态
1、昇腾社区课程发布 | MindSpore带你探索大模型
1月13日,昇腾社区发布了MindSpore大模型全流程应用课程,涵盖环境搭建、预训练、微调、推理部署与调优。课程提供免费云端实验环境,支持HuggingFace、vLLM等主流生态,深入MCore架构,传授断点续训、高可用、性能调优、模型蒸馏等企业级实战技能,完成后还可获官方认证。

2、春节来OpenI复现论文,享受多卡高性能算力!
2月14日至2月23日,OpenI启智社区将携手昇思MindSpore、头歌以及中国算力网、超算互联网、并行科技等算力伙伴,为高校师生和科研机构开发者开放一批高性能算力资源,支持大家安心复现论文、高效跑实验。

3、稀缺高性能算力限时开放,5大技术活动任你玩! 昇思MindSpore联合OpenI启智社区等多家单位于2月14日至3月3日举办了“2026万码奔腾贺新春”活动。活动包含论文复现挑战、Skills炼金术、春节AI主题创作、工具链评测、年度技术复盘五大主题。本次活动旨在降低开发者技术门槛、推动国产软硬件生态创新,并进一步增强社区凝聚力。


社区案例
1、开源之夏系列活动
在人才培养与社区文化建设方面,昇思MindSpore同样成果显著。在由中科院软件所发起的“开源之夏”活动中,昇思社区发布的项目共吸引103位同学提交申报,经过4个月开发期,最终22位学子成功结项。
优秀成果涵盖量子计算、大模型推理优化、跨框架迁移、智能交通分析等多个前沿方向(以下为部分优秀案例,可点开链接了解详情):

贾阔源:基于vLLM-MindSpore,探索Beam Search解码实战 陈思源:基于MindSpore Quantum,开启量子-经典混合计算实践 侯博森:基于昇思MindSpore的MVSNet跨框架迁移与实践 孙文杰:基于MindSpore Quantum的对称性规约与分岔分析算法 方泱泱:基于昇思MindSpore的YOLOv12智能交通分析实践 黄玉含:QuCOOP量子-经典混合优化框架实践 李振兴:基于RAG的MindSpore代码助手与智能问答系统实践
2、社区“昇思同路人”系列活动
与此同时,社区“昇思同路人”栏目持续记录着开发者的成长故事:
第十期 讲述肖雄子彦如何搭建“学创一体”桥梁,引领学子从技术“消费者”蜕变为生态“共建者”;
第十一期 讲述张威如何在校园里为昇思点燃一片“技术森林”,让技术实现“幂次方”增长;
第十二期 则聚焦马欣老师的教育深耕与匠心育人,阐述AI框架如何赋能教育。
3、昇思创新训练营系列活动
此外,昇思创新训练营优秀案例系列分享了开发者基于MindSpore微调大模型、构建智能旅游助手的全流程实践,项目代码已开源,欢迎开发者体验!
这些鲜活的案例共同勾勒出昇思MindSpore社区以技术育人为核、以同路人为荣的浓厚氛围。
技术分享
1 大模型训练:HyperParallel架构发布
本季度正式推出为超节点设计的HyperParallel架构,包含三大核心技术:
HyperShard声明式并行:用户只需声明输入、输出和参数的切分方式,框架自动完成分布式策略推导与资源调度,实现“编写即单卡,运行即分布式”的体验。
HyperOffload多级智能卸载:在编译期静态分析计算图,将长生命周期张量自动卸载至主机内存,降低峰值显存占用,支持更长序列训练。经测试,模型训练吞吐平均提升超过10%。
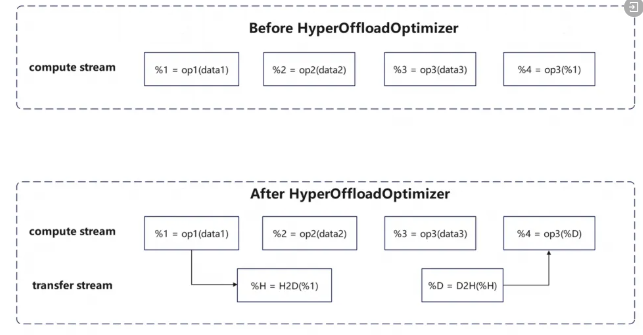
HyperMPMD非规则异构并行:应对模型结构不规则与硬件异构性挑战,实现灵活高效的资源调度。
2 大模型推理:SGLang后端集成与vLLM升级
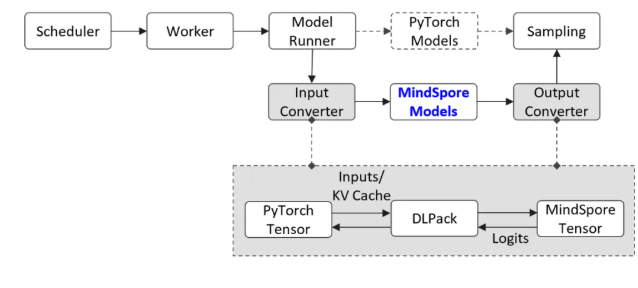
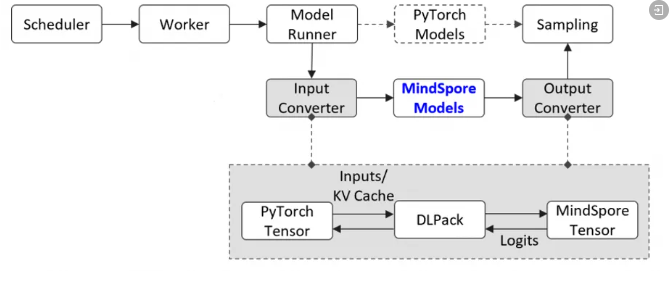
与SGLang社区深度合作,正式合入MindSpore推理后端代码,该方案通过封装MindSpore模型复用SGLang原生组件,借助DLPack实现张量零拷贝转换,打通双框架协同,支持数据并行、PD分离、投机解码等特性。
升级适配vLLM v0.11.0,接入昇腾ACLGraph图下沉功能。实测DeepSeek-V3/R1 W4A8量化推理服务中,整网吞吐提升约5%,算子下发时延由30ms降至10ms。
通过DLPack实现MindSpore与PyTorch张量零拷贝转换,跨框架协同效率大幅提升。
3 基础框架演进:动态图增强与自定义能力开放
动态图能力增强:新增Dispatch自动算子分发、saved_tensors_hook激活值管理、算子级注册机制,提升多设备协同易用性与显存优化灵活性。
自定义能力全面开放:提供自定义算子(极简C++接口,自动享受内存复用与异步调度)、自定义PASS(开放图优化接口,支持算子融合等变换)、自定义后端(标准化接口快速适配新型硬件),从“封闭工具箱”向“开放创新平台”演进。
4 科学计算套件:蛋白质结构预测模型Protenix深度优化
支持AlphaFold3的高性能开源复现模型Protenix v0.5,在昇腾硬件上完成训推全流程适配。
训练方面:通过重计算优化,最大支持序列长度从64提升至768,动态显存峰值从20152MB降至7025MB。
推理方面:融合算子优化后单卡推理性能提升超100%;长序列推理通过分块计算将单卡推理长度极限提升至3000以上;端到端加速比达57%。
5 开发者工具与实战指南
数据流水线与混合精度优化:针对昇腾AI处理器,总结“三板斧”——数据流水线并行(num_parallel_workers)、自动混合精度(amp_level="O2")、数据下沉(dataset_sink_mode=True),有效解决IO瓶颈,提升训练速度。
半自动并行工具Shard:深度解读shard接口的三阶段机制(策略锚定→BFS传播→冲突重排),帮助用户在自动并行与手动调优间取得平衡。
优化器架构:MindSpore优化器通过静态图编译与整图下沉将参数更新闭环在设备侧,支持融合算子、解耦权重衰减、ZeRO优化器并行等特性,实现从单卡到千亿级模型的极致性能。
自动并行实战:一键配置并行模式(数据并行/半自动/全自动),无需修改网络结构,让开发者聚焦模型创新。
开放麦:提供零基础AI艺术生成器教程,基于VAE构建完整代码,涵盖训练、保存、生成与可视化流程。
💡 更多技术解读,欢迎访问昇思社区官网:https://discuss.mindspore.cn/
感谢每一位朋友、开发者的支持
在此感谢社区伙伴们、可爱的小孢子们以及昇思MindSpore SIG组成员们,因为大家的共同努力及辛勤奉献,昇思MindSpore才能不断成长与发展!同时我们对可能出现的不完善之处向您表示诚挚的歉意,并衷心感谢您的理解与支持。
未来,昇思MindSpore AI框架将持续致力于打造人工智能创新之源,凝聚产业力量,扎根AI根技术,使能大模型与科学智能,成为AI创新的首选框架。