昇思人工智能框架峰会 | 基于MindSpore NLP玩转DeepSeek-OCR的开发实践,解锁文本压缩新范式
昇思人工智能框架峰会 | 基于MindSpore NLP玩转DeepSeek-OCR的开发实践,解锁文本压缩新范式
# 01
当文本遇见视觉,AI模型正重新定义信息压缩的边界
在人工智能快速发展的今天,DeepSeek团队于2025年10月推出的DeepSeek-OCR模型带来了一场文本处理范式的革命。这一创新模型不仅实现了10倍压缩率下97%的解码精度,更探索了通过视觉模态压缩长上下文的全新路径。而昇思MindSpore框架的day0支持能力,则为这一前沿技术的快速部署应用提供了坚实基础。
# 02
DeepSeek-OCR:重新定义文本压缩的边界
DeepSeek-OCR 是 DeepSeek AI 于 2025 年 10 月 发布的多模态模型,以探索视觉 - 文本压缩边界为核心目标,为文档识别、图像转文本提供创新方案。其采用 DeepEncoder 视觉编码器与 DeepSeek3B-MoE-A570M 混合专家解码器的双模块架构,从 LLM 视角重新定义视觉编码器功能,聚焦 “文档解码所需最少视觉 token” 这一核心问题,对研究 “一图胜千言” 原理具有重要意义。
模型的核心技术突破体现在三个方面:
高压缩比下的精度保持:****实验表明,当文本令牌数量在视觉令牌数量的10倍以内(即压缩比<10倍)时,模型可以实现97%的解码精度,即使在20倍压缩率下仍保有约60%准确率。
分层视觉编码设计:DeepEncoder采用三阶段处理流程——首先使用SAM-base进行局部感知(窗口注意力看清细节),然后通过卷积层进行16倍下采样,最后使用CLIP-large进行全局语义理解。这种设计能够在高分辨率输入下保持低激活内存。
多分辨率支持:模型提供Tiny/Small/Base/Large/Gundam五种配置,支持从512×512到1280×1280的不同分辨率输入,其中Gundam版本专门针对大尺寸复杂文档优化。
在实际性能方面,DeepSeek-OCR在OmniDocBench测试中表现卓越,仅使用100个视觉token即超越GOT-OCR2.0模型,800个视觉token优于MinerU2.0模型。支持PDF转图像、批量处理及Markdown格式输出。
# 03
Day0支持:MindSpore NLP快速支持DeepSeek-OCR
MindSpore NLP作为基于昇思MindSpore的开源NLP库,**其核心优势在于与Hugging Face生态的全面兼容。**这种兼容性设计使得任何基于Transformers架构的模型都能在昇思MindSpore框架上无缝运行,为DeepSeek-OCR的快速部署提供了技术基础。
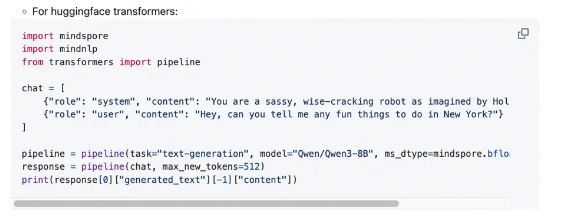
新增2行代码,即可实现基于昇思MindSpore的一键适配
具体而言,MindSpore NLP提供了与Hugging Face完全一致的API接口,开发者可以使用熟悉的AutoModel、AutoTokenizer等类直接加载和运行模型。这种设计极大降低了模型迁移的技术门槛,确保新发布的模型能够实现“day0”支持。
基于MindSpore NLP的兼容性特性,DeepSeek-OCR在昇思MindSpore上的部署变得异常简洁。整个过程主要包含三个关键步骤:
- 环境配置:安装MindSpore NLP及相关依赖库,确保昇思MindSpore版本兼容性
- 模型加载:使用MindSpore NLP+Transformers接口直接加载DeepSeek-OCR预训练权重
- 推理执行:调用统一的API进行文档理解和视觉-文本压缩任务
代码如下图所示:
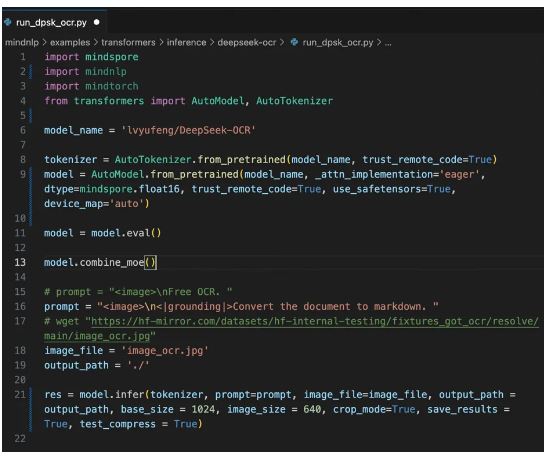
这种标准化流程消除了复杂的模型转换环节,使研究者能够专注于应用开发而非环境适配。无论是处理扫描文档、PDF转换还是长文本压缩,开发者都可以利用熟悉的Hugging Face编程习惯在昇思MindSpore生态中高效运行DeepSeek-OCR,完整案例详见:(https://github.com/mindspore-lab/mindnlp/tree/master/examples/transformers/inference/deepseek-ocr)。
如下图所示,运行脚本后,模型可识别扫描件中的文字,并转换为MarkDown文件。

# 04
基于Expert合并的小MoE模型加速:权重融合计算优化策略
DeepSeek-OCR的解码器采用混合专家(MoE)架构,激活参数约570M。针对MoE模型训练中的性能挑战,昇思MindSpore提供了基于Expert合并的优化方案,显著提升了小MoE模型的效率。
基于Expert合并的小MoE模型加速技术核心在于通过权重预融合策略,将传统动态路由计算转化为统一计算流,从根本上解决MoE架构中的Host端调度瓶颈问题。
1、传统MoE计算瓶颈分析
传统MoE模型采用“专家视角”的计算模式,其核心瓶颈体现在两个方面:
- 细碎算子调度开销:传统实现方式需要遍历每个专家,为每个专家独立执行前向计算。这种循环遍历模式导致大量小规模算子的频繁调度,特别是当专家数量增多时,Host端的算子下发和调度开销呈线性增长。
- 负载不均衡问题:由于不同专家处理的token数量差异显著,计算过程中容易出现负载不均衡。某些热门专家需要处理大量token,而其他专家可能处于空闲状态,这种不均衡进一步加剧了设备利用率的下降。
2、权重预融合技术原理
基于Expert合并的加速方案通过FFN权重预融合技术,将多个专家的计算任务合并为单一计算流:
- 权重合并机制:在模型初始化阶段,将所有专家的FFN层权重进行拼接融合,形成一个统一的超大型权重矩阵。以8专家MoE层为例,每个专家FFN层的输入维度为d_model,中间维度为d_ffn,合并后的权重矩阵形状从8个独立的d_model, d_ffn矩阵转变为统一的8×d_model, d_ffn矩阵。
- 统一计算流程:路由网络输出的选择权重不再用于动态激活不同专家,而是作为加权系数直接应用于融合后的计算结果。具体而言,模型首先通过融合权重矩阵执行一次统一的前向计算,然后根据路由权重对输出进行加权组合,避免了传统的专家遍历过程。
针对DeepSeekV2(DeepSeek-OCR LLM模块)的改进代码如下:
def new_forward_for_moe(self, hidden_states):
batch_size, sequence_length, hidden_dim = hidden_states.shape
selected_experts, routing_weights = self.gate(hidden_states)
router_scores = torch.zeros(size=(batch_size * sequence_length, self.config.n_routed_experts), device=hidden_states.device, dtype=hidden_states.dtype)
# we cast back to the input dtype
routing_weights = routing_weights.to(hidden_states.dtype)
router_scores = torch.scatter_add(router_scores, -1, selected_experts, routing_weights)
hidden_states = hidden_states.view(-1, hidden_dim)
if self.config.n_shared_experts is not None:
shared_expert_output = self.shared_experts(hidden_states)
hidden_w1 = torch.matmul(hidden_states, self.w1)
hidden_w3 = torch.matmul(hidden_states, self.w3)
hidden_states = self.act(hidden_w1) * hidden_w3
hidden_states = torch.bmm(hidden_states, self.w2) * torch.transpose(router_scores, 0, 1).unsqueeze(-1)
final_hidden_states = hidden_states.sum(dim=0, dtype=hidden_states.dtype)
if self.config.n_shared_experts is not None:
hidden_states = final_hidden_states + shared_expert_output
return hidden_states.view(batch_size, sequence_length, hidden_dim)
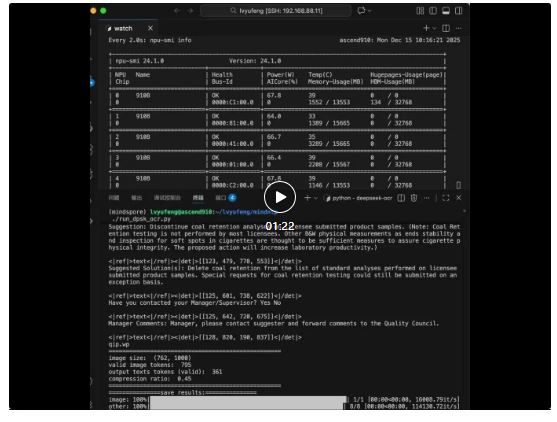
在昇思MindSpore+昇腾的软硬件协同环境中,这一技术大幅提升了DeepSeek-OCR的执行速度,相较于原版实现,推理token生成的性能提升3-4x,算力利用率由8%提升至30%+。这种基于Expert合并的加速思路,为小规模MoE模型的部署提供了一种新的优化范式,特别是在对推理延迟敏感的端侧和应用场景中具有重要价值。
优化后的推理效果如视频中所示:
# 05
总结
DeepSeek-OCR与昇思MindSpore在昇腾硬件上的深度结合,标志着文档智能处理进入了一个全新的发展阶段。这一技术组合不仅展现了前沿AI模型的创新潜力,更体现了从算法、框架到硬件的全栈优化价值。
展望未来,随着多模态大模型技术的持续演进和昇腾算力基础设施的不断完善,OCR模型与昇思MindSpore的深度结合将释放更大潜力。从简单的文档识别到复杂的知识抽取,从单页处理到跨文档分析,这一技术路径正在开启文档智能的新篇章,为企业数字化转型和AI普惠应用提供坚实的技术底座。