经验分享|昇思MindSpore孔锐:学习是为了不断拓宽成长的半径
经验分享|昇思MindSpore孔锐:学习是为了不断拓宽成长的半径

本期项目经验分享来自孔锐同学,承担的项目是【基于昇思MindSpore,实现QMIX强化学习网络】。


项目名称
基于昇思MindSpore,实现QMIX强化学习网络
项目描述
QMIX是什么
QMIX[1]是一种经典的基于值函数的多智能体强化学习算法,多智能强化学习在不同领域的研究和实践中正在产生越来越大的影响,因此为MindSpore Models仓库添加多智能体强化学习相关的模型对加速相关研究工具的补全很有必要。
QMIX遵循集中式训练分布式执行(Centralized Training Distributed Execution)的框架。同值分解网络(Value Decomposition Networks)相同,QMIX希望全局观察的Q函数($Q_{\text{tot}}$)和对每个智能体的Q函数采用$\mathop{\arg\max}$算子得到的结果相同。
即:
$$
\underset{\mathbf{u}}{\operatorname{argmax}} Q_{t o t}(\boldsymbol{\tau}, \mathbf{u})=\left(\begin{array}{c}\operatorname{argmax}_{u^{1}} Q_{1}\left(\tau^{1}, u^{1}\right) \\\vdots \\\operatorname{argmax}_{u^{n}} Q_{n}\left(\tau^{n}, u^{n}\right)\end{array}\right)
$$
为此,QMIX要求$Q_{\text{tot}}$同每个智能体的$Q$函数保有一种单调关系:
$$
\frac{\partial{Q_{\text{tot}}}}{\partial{Q_a}}\geq 0, \,\forall q\in \mathcal{A}
$$
QMIX的网络结构
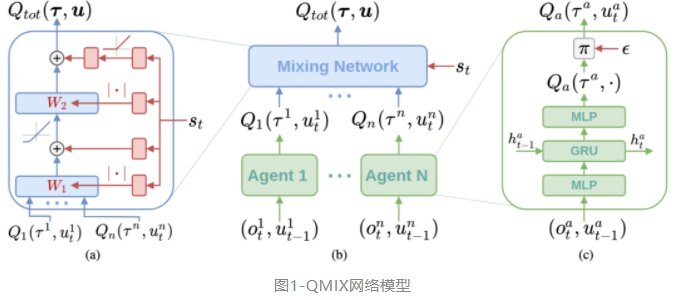
为保证所需要的这种单调关系,QMIX设计了一种特别的网络框架,包括:
Agent network,智能体网络。如图1(c)所示,每个智能体拥有一个单独的网络用来表征其值函数$Q_a(\tau^a, u^a)$,网络架构同DRQN类似,用来接收当前时间步的局部观察$o_t^a$和最后一步采取的动作$u_{t-1}^a$。中间层的GRU网络会将每一个时间步的隐向量输出到下一个时间步,利用观察历史。
Mixing network,混合网络。如图1(a)所示,混合网络是一种以智能体网络的输出作为输入的前馈神经网络,其输出为全局的Q值估计$Q_{\text{tot}}$。为了保证最终整个网络满足公式\ref{eq_momomix}中的单调性质,QMIX令混合网络的权重为非负,而混合网络的权重为可训练的参数,是超网络的输出。
Hypernetworks,超网络。超网络的输入为当前的全局状态,其输出为混合网络某一层的参数。每一个超网络都由单层神经网络和一个激活函数组成,保证最后输出值非负。将输出的向量的维度修改后作为混合网络的权重。混合网络的bias也以类似方法输出,只不过最终的输出值不需要保证非负。
QMIX最终通过一种端到端的方式进行训练,模型总体的损失函数表示为:
$$
\mathcal{L}(\theta)=\sum_{i=1}^{b}\left[\left(y_{i}^{t o t}-Q_{t o t}(\boldsymbol{\tau}, \mathbf{u}, s ; \theta)\right)^{2}\right]
$$
其中$y^{\text{tot}} = r+\gamma \max_{u^\prime}Q_{\text{tot}}(\tau^\prime, u^\prime, s^\prime,;\theta^{-})$为Q值目标。
$\theta^{-}$为类似DQN中的目标网络的参数。这样在训练过程中,模型根据全局的观察和损失训练网络参数,而到了测试阶段,各个智能体根据自身观察选择使得Q值最大的动作。根据QMIX的结构设计,这一动作组合也会使得多个智能体的全局Q值最大。
项目开发
**
开发方案描述
**
模型开发流程
在七月份稍稍熟悉了当前MindSpore的工具链后,很快就被MindSpore Reinforcement[2]吸引。作为原生自MindSpore的强化学习框架,拥有者良好的基础算子支持和简洁的API接口,非常适合使用MindSpore进行强化学习算法的实现。用户只需要将模型的逻辑封装到指定的类中,继承Actor, Learner和Trainer抽象类,MindSpore Reinforcement的框架代码就可以提供和环境的高效交互。
这里我们以QMIX模型为例子,简要展示基于MindSpore进行强化学习模型开发的流程。官方的开发例子可以参考:(https://www.mindspore.cn/reinforcement/docs/zh-CN/master/dqn.html)。
Trainer
Trainer作为训练类,负责模型和环境的交互逻辑,调用Actor产生动作同环境交互后产生的样本,收集训练样本交由Learner更新模型。Trainer主要需要继承父类接口实现三个方法,分别是:
· trainable_variables,返回可训练参数
· train_one_episode,训练过程中每一个episode需要处理的逻辑
· evaluate,策略的评估逻辑
```python
class QMIXTrainer(Trainer):
def __init__(self, msrl, params):
# 省略了具体的初始化过程
nn.Cell.__init__(self, auto_prefix=False)
self.msrl = msrl
self.params = params
super(QMIXTrainer, self).__init__(msrl)
def trainable_variables(self):
trainable_variables = {
"agents": self.msrl.learner.agents,
"mixer": self.msrl.learner.mixer
}
return trainable_variables
@ms_function
def init_episode_buffer(self):
# 初始化replay buffer的辅助函数
return buffer
@ms_function
def train_one_episode(self):
# ...
# self.env是通过self.msrl访问配置好的环境
obs, state, avail_action = self.env.reset()
# ...
while (not done) and (episode_step < self.episode_limit):
# 通过self.msrl调用Actor类act方法,合并了act和step两个步骤,phase为
# trainer.COLLECT
next_obs, done, reward, action, hidden_state, \
next_state, next_avail_action = self.msrl.agent_act(trainer.COLLECT,
(concat_obs, hidden_state, avail_action, self.step))
# ...
# 将转移存储到当前回合的buffer当中
episode_buffer["obs"][episode_step] = concat_obs
episode_buffer["state"][episode_step] = next_state
episode_buffer["action"][episode_step - 1] = action
episode_buffer["reward"][episode_step - 1] = reward
episode_buffer["done"][episode_step - 1] = done
episode_buffer["hidden_state"][episode_step] = hidden_state
episode_buffer["avail_action"][episode_step] = avail_action
episode_buffer["filled"][episode_step - 1] = Tensor(
1, ms.int32).expand_dims(axis=0)
episode_step += 1
# ...
self.step += episode_step
# 将收集到的数据加入replay buffer
self.msrl.replay_buffer_insert(episode_buffer.values())
if self.greateq(self.msrl.buffers.count, self.batch_size):
# 调用Learner类更新模型参数
loss = self.msrl.agent_learn(self.msrl.replay_buffer_sample())
step_info = self.env.get_step_info()
info = (loss, reward_sum, episode_step, step_info)
return info
@ms_function
def evaluate(self):
# 策略评估,在eval_env当中进行测试
# 具体过程同train_one_step中一致,将phase改为trainer.EVAL
step_info = self.eval_env.get_step_info()
return step_info
```
Actor
Actor类需要实现act方法和get_action方法,决定在和环境交互时如何根据得到的观测返回动作。
```python
class QMIXActor(Actor):
def __init__(self, params):
super().__init__()
self.collect_policy = params['collect_policy']
self.eval_policy = params['eval_policy']
self.collect_env = params['collect_environment']
self.eval_env = params['eval_environment']
def get_action(self, phase, params):
# get action from policy
obs, hidden_state, avail_action, step = params
if phase in (trainer.INIT, trainer.COLLECT):
action, hidden_state = self.collect_policy(
(obs, hidden_state, avail_action), step)
elif phase == trainer.EVAL:
action, hidden_state = self.eval_policy(
(obs, hidden_state, avail_action))
else:
raise Exception("Invalid phase")
return action, hidden_state
def act(self, phase, params):
# select policy to execute in the corresponding environment
obs, hidden_state, avail_action, step = params
if phase in (trainer.INIT, trainer.COLLECT):
action, hidden_state = self.collect_policy(
(obs, hidden_state, avail_action), step)
next_obs, reward, done, next_state, next_avail_action = self.collect_env.step(action)
elif phase == trainer.EVAL:
action, hidden_state = self.eval_policy(
(obs, hidden_state, avail_action))
next_obs, reward, done, next_state, next_avail_action = self.eval_env.step(action)
else:
raise Exception("Invalid phase")
result = (next_obs, done, reward, action, hidden_state, next_state,
next_avail_action)
return result
```
这里我们使用的policy类作为中间层,将策略和网络解耦合,可以更加灵活地决定智能体的行为逻辑。数据收集策略使用基于epsilon-decay的epsilon-greedy策略,评估策略使用greedy策略。
```python
class QMIXPolicy:
class CollectPolicy(nn.Cell):
"""The collect policy implementation (how to obtain actions)"""
def __init__(self, network, params):
super().__init__()
self.agent_num = params["environment_config"]["num_agent"]
self.epsi_start = Tensor([params['epsi_start']], ms.float32)
self.epsi_end = Tensor([params['epsi_end']], ms.float32)
all_steps = params['all_steps']
self.delta = (self.epsi_start - self.epsi_end) / all_steps
self.network = network
self.categorical_dist = msd.Categorical()
self.rand = ops.UniformReal()
def construct(self, params, step):
# epsilon decay
epsilon = ops.maximum(self.epsi_start - self.delta * step,self.epsi_end)
obs, hidden_state, avail_action = params
q_vals, hidden_state = self.network(obs, hidden_state)
# soft mask non-available actions
q_vals[avail_action == 0] = -1e10
# epsilon-greedy action selection
best_action = self.categorical_dist.mode(q_vals)
random_action = self.categorical_dist.sample((), avail_action)
cond = self.rand((self.agent_num, 1)).reshape([self.agent_num]) < epsilon
selected_action = self.categorical_dist.select(cond, random_action, best_action)
selected_action = selected_action.expand_dims(1)
return selected_action, hidden_state
class EvalPolicy(nn.Cell):
def __init__(self, network):
super().__init__()
self.network = network
self.categorical_dist = msd.Categorical()
def construct(self, params):
obs, hidden_state, avail_action = params
q_vals, hidden_state = self.network(obs, hidden_state)
q_vals[avail_action == 0] = -1e10
# greedy action selection
best_action = self.categorical_dist.mode(q_vals)
selected_action = best_action.expand_dims(1)
return selected_action, hidden_state
def __init__(self, params):
# agent网络
self.agents = RNNAgent(params)
# mixer网络
self.mixer = QMixNet(params)
# 数据收集策略
self.collect_policy = self.CollectPolicy(self.agents, params)
# 模型评估策略
self.eval_policy = self.EvalPolicy(self.agents)
```
Learner
Learner类处理从buffer当中采集到的数据样本,计算loss后更新模型。我们首先需要定义Loss Cell
```python
class LossCell(nn.Cell):
def __init__(self, params, agents, mixer, target_mixer):
super().__init__()
self.gamma = params['gamma']
self.batch_size = params['batch_size']
self.agents = agents
self.mixer = mixer
self.target_mixer = target_mixer
self.gatherd = ops.GatherD()
def construct(self, obs_batch, current_state_batch, next_state_batch, action_batch, avail_action_batch, reward_batch, mask, filled_batch, q_val_target, hidden_state_batch):
# 在这里省略了loss的计算逻辑
return loss
```
Learner中我们需要实现learn方法,调用loss cell计算loss进行参数更新
```python
class QMIXLearner(Learner):
def __init__(self, params):
super().__init__()
optimizer = nn.RMSProp(train_params, learning_rate=params['lr'])
qmix_loss_cell = LossCell(params, self.agents, self.mixer,self.target_mixer)
self.train_step = nn.TrainOneStepCell(qmix_loss_cell, optimizer)
self.train_step.set_train(mode=True)
def learn(self, experience):
obs_batch, state_batch, action_batch, reward_batch, done_batch,\
hidden_state_batch, avail_action_batch, filled_batch = experience
# 省略中间的处理逻辑
# ...
# 计算loss
loss = self.train_step(obs_batch, current_state_batch, next_state_batch, action_batch, avail_action_batch, reward_batch, mask, filled_batch, q_val_target, hidden_state_batch)
return loss
```
更优雅的训练过程
参数自动配置
模型精度达标后主要的工作在对代码的可读性和算法模型的扩展性上,为SMAC环境编写了自动的配置函数,消除了对于不同环境手动配置的繁琐和在代码当中进行硬编码的风险,直接根据环境信息配置模型和buffer。
```python
def env_info(env_name):
env_params = {'sc2_args': {'map_name': env_name}}
temp_env = StarCraft2Environment(env_params, 0)
info = temp_env.env_info
return info
class ParamConfig():
def __init__(self, env_name):
ENV_NAME = env_name
env_param = env_info(ENV_NAME)
state_dim = env_param["state_shape"]
obs_dim = env_param["obs_shape"]
action_dim = env_param["n_actions"]
agent_num = env_param["n_agents"]
episode_limit = env_param["episode_limit"]
self.algorithm_config = {
'actor': {
'number': 1,
'type': QMIXActor,
'policies': ['collect_policy', 'eval_policy'],
},
'learner': {
'number': 1,
'type': QMIXLearner,
'params': self.learner_params,
'networks': ['agents', 'mixer']
},
'policy_and_network': {
'type': QMIXPolicy,
'params': self.policy_params
},
'collect_environment': {
'number': 1,
'type': StarCraft2Environment,
'params': self.collect_env_params
},
'eval_environment': {
'number': 1,
'type': StarCraft2Environment,
'params': self.eval_env_params
},
'replay_buffer': {
'number':1,
'type':ReplayBuffer,
'capacity':5000,
'data_shape': [(episode_limit + 1, agent_num,
obs_dim + agent_num + action_dim),
(episode_limit + 1, state_dim),
(episode_limit + 1, agent_num, 1),
(episode_limit + 1, 1), (episode_limit + 1, 1),
(episode_limit + 1, agent_num, 64),
(episode_limit + 1, agent_num, action_dim),
(episode_limit + 1, 1)],
'data_type': [
ms.float32, ms.float32, ms.int32, ms.float32, ms.bool_,
ms.float32, ms.int32, ms.int32
],
'sample_size':BATCH_SIZE,
}
```
CallBack
在多智能体强化学习的模型训练过程中智能体的行为变化和最终的性能结果同样重要,为了更好地观察诸多的关键指标,为模型开发了新的CallBack类,将模型训练过程中的性能表现利用mindinsight可视化输出。
```python
```class RecordCb(Callback):
def __init__(self, summary_dir, interval, eval_rate, times):
self._summary_dir = summary_dir
def __enter__(self):
self.summary_record = ms.SummaryRecord(self._summary_dir)
return self
def __exit__(self, *exc_args):
self.summary_record.close()
def begin(self, params):
params.eval_rate = self._eval_rate
def episode_end(self, params):
# 省略更多信息的记录逻辑
# ...
loss = params.loss
# loss check already been done in LossCallback
self.summary_record.add_value("scalar", 'loss', loss)
reward = params.total_rewards
self.summary_record.add_value("scalar", 'reward', reward)
self.summary_record.record(params.cur_episode)
```
完成以后训练过程的训练表现就可以通过mindinsight很好地进行观察
**ospp:**请简单介绍一下自己和你的开源经历吧。
**孔锐:**大家好,我是孔锐,来自南京大学,目前是一名研一新生,研究方向是强化学习。最开始接触开源社区是本科期间因为课业要求和研究需要,被老师们和学长推荐着了解了不少开源项目。在大三的时候因为参加paddle hackathon对深度学习框架的源码产生了很浓厚的兴趣,之后一直在留意参与到这些社区的机会。越深入了解深度学习框架的发展越是感叹社区的欣欣向荣,向往能够为开源社区添砖加瓦。
**ospp:**你是从什么渠道了解开源之夏的,为什么选择参与开源之夏?
**孔锐:**很早之前就有听过同学说起过开源之夏。在上半年的时候,我错过了GSoC的ddl,但是当时正好一直在留意开源活动,刚好发现了现在这个和自身兴趣和研究经历都比较相关的项目。在官网上也去了解了往年的活动情况,又和项目导师进行了仔细的沟通,确认了开源之夏确实是我理想中的开源活动,所以就果断报名参加了。
**ospp:**开源之夏相比于过往你参与的活动和赛事有什么不同之处?
**孔锐:**规模上要更大,覆盖了不少最新的技术和框架,来自不同背景的同学都能找到适合自己的项目。另一方面为每个项目都安排了单独的导师,像MindSpore还建立了社区层次上的交流群,参赛过程中交流和学习的机会要更多,也更容易推进项目进度。
参与开源社区
**ospp:**介绍一下你眼中的昇思 MindSpore 社区吧。
**孔锐:**在参赛的过程中需要经常查看MindSpore的文档和源码,MindSpore 社区的底层实现和API的设计的风格都相当优秀,兼顾了性能和优雅,文档的覆盖也保证了大多数开发过程中遇到的问题能够得到帮助和解决。除此以外,MindSpore社区的大家都非常热情,不管是在代码托管平台还是各个讨论区、社交媒体讨论群,都经常能见到对具体技术问题的热烈讨论。MindSpore对我来说是一个非常有活力有激情的社区。
**ospp:**项目进行中社区和导师给你带来了怎样的帮助?
**孔锐:**项目的开发过程中得到了很多来自导师的帮助,每次修改开发方案都会得到来自导师的支持和建议,给了我去完善实现细节的定力,得以顺利完成项目。还要感谢陈志鹏学长,他在项目的验收阶段的规范性和突发问题的处理上给了我很多帮助,他的耐心帮助对模型质量验收至关重要。最后要感谢MindSpore社区以及开源之夏社区提供的平台和机会,使得我能够亲身参与到如此活跃的开源社区开发当中。
**ospp:**你是在什么阶段开始接触开源的?这次开源之夏的参与体验让你对开源和开源社区有了什么新的理解?
**孔锐:**接触开源刚好是在刚刚完成基础知识构建和即将进行科研生活的分界线上,算是一个逐渐聚拢自己好奇心的阶段。这次的参与体验对我来说最大的收获是看到了如何在科研学习的过程中反馈社区的可能性,正是在学习框架、使用框架、了解框架的过程中认识到很多的优秀设计,内化到自己的代码中给社区提供更丰富更具体的使用样例。在我看来这是每个深度使用者都可以参与开源社区的简单方式,也正是在这个过程中能够进一步给社区提供高质量issue和pr。
**ospp:**你认为在校学生怎样才能更好地参与开源并融入开源社区?
**孔锐:**如上所说,参与开源社区应该从使用开始,就将反馈当作使用过程中的一环。还有就是培养持久专注的好奇心,通过更多的渠道了解喜欢的开源项目,把握参与社区组织的活动的机会,从实践中有针对性地提升自己的动手能力。
收获与寄语
**ospp:**经过了解你已经顺利推免继续读研,这次参与的开源活动对你未来的学习生活有什么积极影响,未来你还会继续参与开源之夏吗?
**孔锐:**在参与这次项目的过程中了解到了非常不错强化学习框架的设计模式,最近正在尝试将这种设计模式融入到自己的实验框架代码当中。另外也是查缺补漏,了解到当前能力的短板部分,我认为有很多超出原先视域的知识是极其重要的。未来有机会也希望能够继续参与开源之夏,希望能够参与到一些和自身研究方向相关又更有挑战性的项目当中!
**ospp:**对未来自己在开源社区的发展有什么规划吗?
**孔锐:**准备对自己常用的开源项目做个清单整理下,保持对项目社区的持续关注,未来希望能够成为长期贡献者,更加积极地参与到开源社区的构建当中,多多总结输出。
**ospp:**给其他准备参与开源之夏的学弟学妹们一些建议吧。
**孔锐:**hhh建议大家早早参加开源之夏,这是一个非常好的平台,对低年级的同学来说,在满足项目的基础能力要求的前提下,深入参与并且保持和导师与社区的沟通对于提升自身能力是次宝贵的机会。细节上最重要的建议还是在选择项目之前多去了解,综合考虑自身兴趣、自身能力和个人成长规划后进行选择才能找到最适合自己的项目,合适的选题是成功的一半。在项目开发的过程中如果遇到了困难,个人尝试失败以后要能够主动联系导师和社区寻求帮助,主动解决问题。
写在最后
参赛过程中最大的感想是:优秀的框架和良好的社区支持对于开发者是一件很幸福的事。开发前期遇到的最大问题其实是最开始的时候不太熟悉MindSpore上强化学习算法的开发流程,和其他任务下监督学习的训练范式存在很大不同,强化学习往往需要更加灵活的监督信号的引入,learning target需要和环境进行频繁交互。按照先前模型开发经验自己写出来的训练接口因为没有相应的算子支持,交互效率非常低。
幸运地是后来仔细了解了MindSpore Reinforcement,学习了优秀的框架支持和API逻辑。在这里要感谢MindSpore Reinforcement的开发团队,提供的框架在很多本来繁琐的问题上都给出了优秀的实现方案,解决了模型训练的后顾之忧。从社区前辈们的实现里也学到了很多实践当中的重要细节和优良编码风格。中途因为对框架理解不到位遇到的开发问题都能够得到MindSpore社区的及时支持,不管是完善的文档和还是活跃的问答社区,都给了我很大的帮助。