昇思MindSpore技术论坛分享回顾 | AI编译技术的瓶颈在哪里?
昇思MindSpore技术论坛分享回顾 | AI编译技术的瓶颈在哪里?

深度学习编译技术的瓶颈在哪里?
下一代技术是什么?
4月23日,由昇思MindSpore社区发起的昇思MindSpore技术论坛第三期 ——【AI编译技术专题】线上交流会成功举办。会议邀请了上海交通大学、希姆计算、燧原科技等院校、企业以及昇思MindSpore的技术专家一共交流。
下面让我们一起来回顾一下分享的精彩的内容吧。

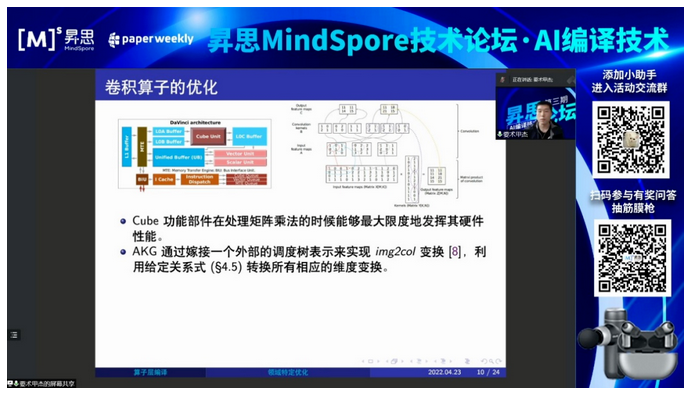
作为华为的一个重要开源软件,昇思MindSpore框架正在成为深度学习和其它领域的重要基础软件,但基于昇思MindSpore编写的应用程序如何部署在底层硬件上,是该软件生态必须要解决的一个问题。
本次内容以深度学习编译应用为切入点,介绍昇思MindSpore框架“图算”一体的自动张量编译软件栈,从图层、算子层和“图算”交互等几个方面介绍该软件栈的基本工作流程以及相应工程和学术研究进展,并展示了该软件栈与其它相关工作进行实验对比的结果。
通过本活动的交流,期望给昇思MindSpore生态圈的快速发展起到推动作用,并期望与相关同行和专家进行深入交流和深入合作。

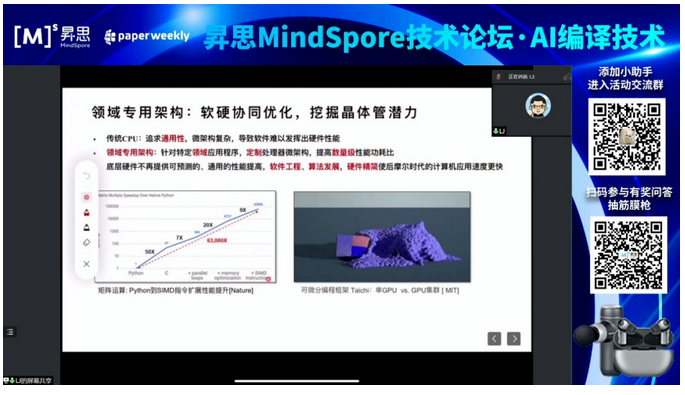
框架对于AI的算法和硬件架构的协同设计是至关重要的。未来的趋势是协同优化应该交给框架去做,让框架把算法中的精度问题、计算性能、延迟等问题,甚至一些新的工艺、工具链需要解决的问题融合在一起。
未来我们从工艺到EDA工具等等这些「卡脖子」的问题是非常有希望在存算一体这种新的赛道上,在这一新赛道上是可以构建出一套国产自主的从芯片设计到编译框架、软件框架整个生态的链条。
本次活动介绍了处理器的发展趋势和挑战、稀疏算法与架构,以及稀疏软件(编译)框架的尝试。

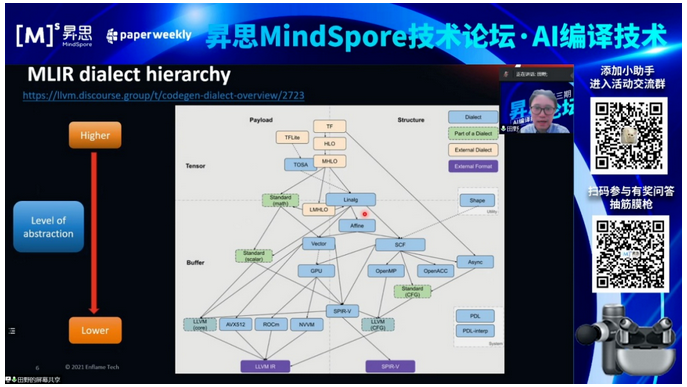
MLIR(多级中间表示)是语言(如 C)或库(如 TensorFlow)与编译器后端(如 LLVM)之间的中间表示 (IR) 系统。允许不同语言的不同编译器堆栈之间的代码重用以及其他性能和可用性优势。燧原利用MLIR框架的优势开发了自己的图编译器。
本次介绍了在技术实践方面的内容,包含如何使用API接口简洁的构建图层IR,op fusion的泛化支持,以及op validation和dynamic shape支持等介绍。


随着工艺水平的进步和处理器体系结构的发展,处理器的速度已远远超过了存储器的速度,从而导致了"存储墙"的出现.为了解决"存储墙"问题,减少存储访问延迟,当前的计算机大都采用层次存储系统。
层次存储系统中各级存储器的有效利用依赖于程序存储访问的局部性特性,因此针对层次存储系统的局部性优化技术成为了充分发挥计算机系统性能,解决"存储墙"问题的关键技术之一。
在本次活动中主要介绍了希姆计算AI编译器面临的主要技术挑战,以及围绕数据局部性展开的编译优化工作。


本次分享介绍了AI编译器的特点、发展历史以及AI编译器面向未来的挑战,并介绍了面向这些挑战,昇思MindSpore的5大实践,包括:
完整的AI编译器解决方案,完善的Python静态化方案,AI亲和的中间表示MindIR,充分发挥硬件性能的图算融合+算子自动生成的方案,针对大规模并行的完整编译方案。

· 更多活动 ·
**2022年4月30日(明天)**昇思MindSpore社区携手知名媒体PaperWeekly发起昇思MindSpore技术论坛第四期线上交流会。
本期分两个论坛进行 上午(9:00~12:00) 【AI数据和安全可信专题】
下午(14:00~17:20) 【昇思MindSpore科研创新和产业实践专题】
届时来自上海交通大学、哈尔滨工业大学、依瞳科技、南方数码等知名院校、企业的专家,以及昇思MindSpore的技术专家将共同讨论AI可信与产业落地的问题。


MindSpore官方资料
官方QQ群 : 486831414
Gitee : https : //gitee.com/mindspore/mindspore