评测
![]()
概览
大语言模型(LLM)的迅猛发展催生了对其能力边界与局限性的系统化评估需求,模型评测已成为AI领域不可或缺的基础设施。主流的模型评测流程就像考试,通过模型对试卷(评测数据集)的答题正确率,来对模型的能力进行评估。常见数据集如ceval包含中文的52个不同学科职业考试选择题,主要评估模型的知识量;GSM8K由人类出题者编写的8500道高质量的小学数学题组成,主要评估模型的推理能力等。当然由于大模型能力的发展,这几个数据集都面临数据污染和饱和问题,这里仅作为说明。同时业界也涌现了很多非问答式的前沿的模型评测方法,这不在本教程的考虑范围内。
MindSpore Transformers的服务化评测推荐AISBench Benchmark套件,AISBench Benchmark是基于OpenCompass构建的模型评测工具,兼容OpenCompass的配置体系、数据集结构与模型后端实现,并在此基础上扩展了对服务化模型的支持能力。同时支持30+开源数据集:AISBench支持的评测数据集。
当前,AISBench支持两大类推理任务的评测场景:
精度评测:支持对服务化模型和本地模型在各类问答、推理基准数据集上的精度验证以及模型能力评估。
性能评测:支持对服务化模型的延迟与吞吐率评估,并可进行压测场景下的极限性能测试。
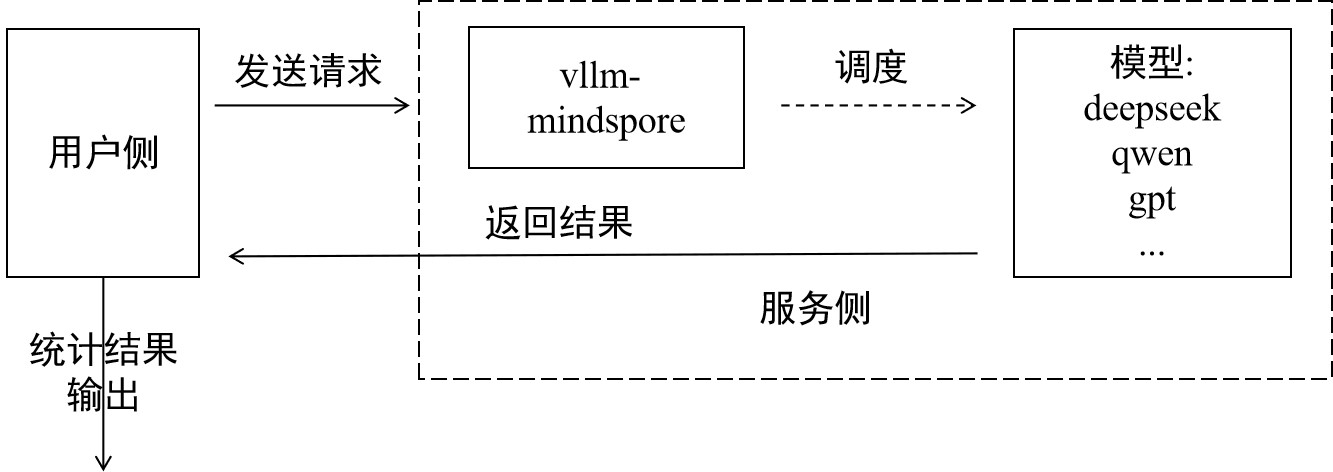
两项任务都遵循同一套评测范式,用户侧发送请求,并对服务侧输出的结果做分析,输出最终评测结果,如下图:
前期准备
前期准备主要完成三件事:安装AISBench评测环境,下载数据集,启动vLLM-MindSpore服务。
Step1 安装AISBench评测环境
因为AISBench对torch、transformers都有依赖,但是vLLM-MindSpore的官方镜像中有msadapter包mock的torch,会引起冲突,所以建议为AISBench另起容器安装评测环境。如果坚持以vLLM-MindSpore镜像起容器安装评测环境,需要在启动容器后执行以下几步删除容器内原有torch和transformers:
rm -rf /usr/local/Python-3.11/lib/python3.11/site-packages/torch*
pip uninstall transformers
unset USE_TORCH
然后克隆仓库并通过源码安装:
git clone https://gitee.com/aisbench/benchmark.git
cd benchmark/
pip3 install -e ./ --use-pep517
Step2 数据集下载
官方文档提供各个数据集下载链接,以ceval为例可在ceval文档中找到下载链接,执行以下命令下载解压数据集到指定路径:
cd ais_bench/datasets
mkdir ceval/
mkdir ceval/formal_ceval
cd ceval/formal_ceval
wget https://www.modelscope.cn/datasets/opencompass/ceval-exam/resolve/master/ceval-exam.zip
unzip ceval-exam.zip
rm ceval-exam.zip
其他数据集下载,可到对应的数据集官方文档中找到下载链接。
Step3 启动vLLM-MindSpore服务
具体启动过程见:服务化部署教程,评测支持所有可服务化部署模型。
精度评测流程
精度评测首先要确定评测的接口和评测的数据集类型,具体根据模型能力和数据集选定。
Step1 更改接口配置
AISBench支持openai的v1/chat/completions和v1/completions接口,在AISBench中分别对应不同的配置文件。以v1/completions接口为例,以下称general接口,需更改以下文件ais_bench/benchmark/configs/models/vllm_api/vllm_api_general.py配置:
from ais_bench.benchmark.models import VLLMCustomAPIChat
models = [
dict(
attr="service",
type=VLLMCustomAPIChat,
abbr='vllm-api-general-chat',
path="xxx/DeepSeek-R1-671B", # 指定模型序列化词表文件绝对路径,一般来说就是模型权重文件夹路径
model="DeepSeek-R1", # 指定服务端已加载模型名称,依据实际VLLM推理服务拉取的模型名称配置(配置成空字符串会自动获取)
request_rate = 0, # 请求发送频率,每1/request_rate秒发送1个请求给服务端,小于0.1则一次性发送所有请求
retry = 2,
host_ip = "localhost", # 指定推理服务的IP
host_port = 8080, # 指定推理服务的端口
max_out_len = 512, # 推理服务输出的token的最大数量
batch_size=128, # 请求发送的最大并发数,可以加快评测速度
generation_kwargs = dict( # 后处理参数,参考模型默认配置
temperature = 0.5,
top_k = 10,
top_p = 0.95,
seed = None,
repetition_penalty = 1.03,
)
)
]
更多具体参数说明查看:接口配置参数说明。
Step2 命令行启动评测
确定采用的数据集任务,以ceval为例,采用ceval_gen_5_shot_str数据集任务,命令如下:
ais_bench --models vllm_api_general --datasets ceval_gen_5_shot_str --debug
参数说明
--models:指定了模型任务接口,即vllm_api_general,对应上一步更改的文件名。此外还有vllm_api_general_chat。--datasets:指定了数据集任务,即ceval_gen_5_shot_str数据集任务,其中的5_shot指问题会重复四次输入,str是指非chat输出。
其它更多的参数配置说明,见配置说明。
评测结束后统计结果会打屏,具体执行结果和日志都会保存在当前路径下的outputs文件夹下,执行异常情况下可以根据日志定位问题。
性能评测流程
性能与精度评测流程类似,不过更关心各请求各阶段的处理时间,通过精确记录每条请求的发送时间、各阶段返回时间及响应内容,系统地评估模型服务在实际部署环境中的响应延迟(如 TTFT、Token间延迟)、吞吐能力(如 QPS、TPUT)、并发处理能力等关键性能指标。以下以原始数据集gms8k进行性能评测为例。
Step1 更改接口配置
通过配置服务化后端参数,可以灵活控制请求内容、请求间隔、并发数量等,适配不同评测场景(如低并发延迟敏感型、高并发吞吐优先型等)。配置与精度评测类似,以vllm_api_stream_chat任务为例,在ais_bench/benchmark/configs/models/vllm_api/vllm_api_stream_chat.py更改如下配置:
from ais_bench.benchmark.models import VLLMCustomAPIChatStream
models = [
dict(
attr="service",
type=VLLMCustomAPIChatStream,
abbr='vllm-api-stream-chat',
path="xxx/DeepSeek-R1-671B", # 指定模型序列化词表文件绝对路径,一般来说就是模型权重文件夹路径
model="DeepSeek-R1", # 指定服务端已加载模型名称,依据实际VLLM推理服务拉取的模型名称配置(配置成空字符串会自动获取)
request_rate = 0, # 请求发送频率,每1/request_rate秒发送1个请求给服务端,小于0.1则一次性发送所有请求
retry = 2,
host_ip = "localhost", # 指定推理服务的IP
host_port = 8080, # 指定推理服务的端口
max_out_len = 512, # 推理服务输出的token的最大数量
batch_size = 128, # 请求发送的最大并发数
generation_kwargs = dict(
temperature = 0.5,
top_k = 10,
top_p = 0.95,
seed = None,
repetition_penalty = 1.03,
ignore_eos = True, # 推理服务输出忽略eos(输出长度一定会达到max_out_len)
)
)
]
具体参数说明查看:接口配置参数说明。
Step2 评测命令
ais_bench --models vllm_api_stream_chat --datasets gsm8k_gen_0_shot_cot_str_perf --summarizer default_perf --mode perf
参数说明
--models:指定了模型任务接口,即vllm_api_stream_chat,对应上一步更改的配置的文件名。--datasets:指定了数据集任务,即gsm8k_gen_0_shot_cot_str_perf数据集任务,有对应的同名任务文件,其中的gsm8k指用的数据集,0_shot指问题不会重复,str是指非chat输出,perf是指做性能测试。--summarizer:指定了任务统计数据。--mode:指定了任务执行模式。
其它更多的参数配置说明,见配置说明。
评测结果说明
评测结束会输出性能测评结果,结果包括单个推理请求性能输出结果和端到端性能输出结果,参数说明如下:
指标 |
全称 |
说明 |
|---|---|---|
E2EL |
End-to-End Latency |
单个请求从发送到接收全部响应的总时延(ms) |
TTFT |
Time To First Token |
首个 Token 返回的时延(ms) |
TPOT |
Time Per Output Token |
输出阶段每个 Token 的平均生成时延(不含首个 Token) |
ITL |
Inter-token Latency |
相邻 Token 间的平均间隔时延(不含首个 Token) |
InputTokens |
/ |
请求的输入 Token 数量 |
OutputTokens |
/ |
请求生成的输出 Token 数量 |
OutputTokenThroughput |
/ |
输出 Token 的吞吐率(Token/s) |
Tokenizer |
/ |
Tokenizer 编码耗时(ms) |
Detokenizer |
/ |
Detokenizer 解码耗时(ms) |
更多评测任务,如合成随机数据集评测、性能压测,可查看以下文档:AISBench官方文档。
更多调优推理性能技巧,可查看以下文档:推理性能调优。
更多参数说明请看以下文档:性能测评结果说明。
FAQ
Q:评测结果输出不符合格式,如何使结果输出符合预期?
在某些数据集中,我们可能希望模型的输出符合我们的预期,那我们可以更改prompt。
以ceval的gen_0_shot_str为例,我们想让输出的第一个token就为选择的答案,可更改以下文件下的template:
# ais_bench/benchmark/configs/datasets/ceval/ceval_gen_0_shot_str.py 66~76行
for _split in ['val']:
for _name in ceval_all_sets:
_ch_name = ceval_subject_mapping[_name][1]
ceval_infer_cfg = dict(
prompt_template=dict(
type=PromptTemplate,
template=f'以下是中国关于{_ch_name}考试的单项选择题,请选出其中的正确答案。\n{{question}}\nA. {{A}}\nB. {{B}}\nC. {{C}}\nD. {{D}}\n答案: {{answer}}',
),
retriever=dict(type=ZeroRetriever),
inferencer=dict(type=GenInferencer),
)
其他数据集,也是相应地更改对应文件中的template,构造合适的prompt。
Q:不同数据集应该如何配置接口类型和推理长度?
具体取决于模型类型和数据集类型的综合考虑。像reasoning类model就推荐用chat接口,可以使能think,推理长度就要设得长一点;像base模型就用general接口。
以Qwen2.5模型评测MMLU数据集为例:从数据集来看,MMLU这类数据集以知识考察为主,就推荐用general接口,同时在数据集任务时不选用带cot的,即不使能思维链。
若以QWQ32B模型评测AIME2025这类困难的数学推理题为例:推挤使用chat接口,并设置超长推理长度,使用带cot的数据集任务。
常见报错
1. 客户端返回HTML数据,包含乱码
报错现象:返回网页HTML数据
解决方案:检查客户端是否开了代理,检查proxy_https、proxy_http环境变量关掉代理。
2. 服务端报 400 Bad Request
报错现象:
INFO: 127.0.0.1:53456 - "POST /v1/completions HTTP/1.1" 400 Bad Request
INFO: 127.0.0.1:53470 - "POST /v1/completions HTTP/1.1" 400 Bad Request
解决方案:检查客户端接口配置中,请求格式是否正确。
3. 服务端报错404 xxx does not exist
报错现象:
[serving_chat.py:135] Error with model object='error' message='The model 'Qwen3-30B-A3B-Instruct-2507' does not exist.' param=None code=404
"POST /v1/chat/completions HTTP/1.1" 404 Not Found
[serving_chat.py:135] Error with model object='error' message='The model 'Qwen3-30B-A3B-Instruct-2507' does not exist.'
解决方案:检查接口配置中的模型路径是否可达。
附录:请求接口配置参数说明表
参数 |
说明 |
|---|---|
type |
任务接口类型 |
path |
模型序列化词表文件绝对路径,一般来说就是模型权重文件夹路径 |
model |
服务端已加载模型名称,依据实际VLLM推理服务拉取的模型名称配置(配置成空字符串会自动获取) |
request_rate |
请求发送频率,每1/request_rate秒发送1个请求给服务端,小于0.1则一次性发送所有请求 |
retry |
请求失败重复发送次数 |
host_ip |
推理服务的IP |
host_port |
推理服务的端口 |
max_out_len |
推理服务输出的token的最大数量 |
batch_size |
请求发送的最大并发数 |
temperature |
后处理参数,温度系数 |
top_k |
后处理参数 |
top_p |
后处理参数 |
seed |
随机种子 |
repetition_penalty |
后处理参数,重复性惩罚 |
ignore_eos |
推理服务输出忽略eos(输出长度一定会达到max_out_len) |
参考资料
关于AISBench的更多教程和使用方式可参考官方资料: