Benchmark
![]()
Overview
The rapid development of Large Language Models (LLMs) has created a systematic need to evaluate their capabilities and limitations. Model evaluation has become essential infrastructure in the AI field. The mainstream model evaluation process is like an exam, where model capabilities are assessed through the accuracy rate of the model's answers to test papers (evaluation datasets). Common datasets such as CEVAL contain 52 different subject professional examination multiple-choice questions in Chinese, primarily evaluating the model's knowledge base. GSM8K consists of 8,501 high-quality elementary school math problems written by human problem setters, primarily evaluating the model's reasoning ability, and so on. Of course, due to the development of large model capabilities, these datasets all face issues of data contamination and saturation, which is only mentioned here for illustration. At the same time, many non-question-answering cutting-edge model evaluation methods have emerged in the industry, which are not within the scope of this tutorial.
For service-oriented evaluation of MindSpore Transformers, the AISBench Benchmark suite is recommended. AISBench Benchmark is a model evaluation tool built on OpenCompass, compatible with OpenCompass's configuration system, dataset structure, and model backend implementation, while extending support for service-oriented models. It supports 30+ open-source datasets: Evaluation datasets supported by AISBench.
Currently, AISBench supports two major categories of inference task evaluation scenarios:
Accuracy Evaluation: Supports accuracy verification and model capability assessment of service-oriented models and local models on various question-answering and reasoning benchmark datasets.
Performance Evaluation: Supports latency and throughput evaluation of service-oriented models, and can perform extreme performance testing under pressure testing scenarios.
Both tasks follow the same evaluation paradigm. The user side sends requests and analyzes the results output by the service side to output the final evaluation results, as shown in the figure below:
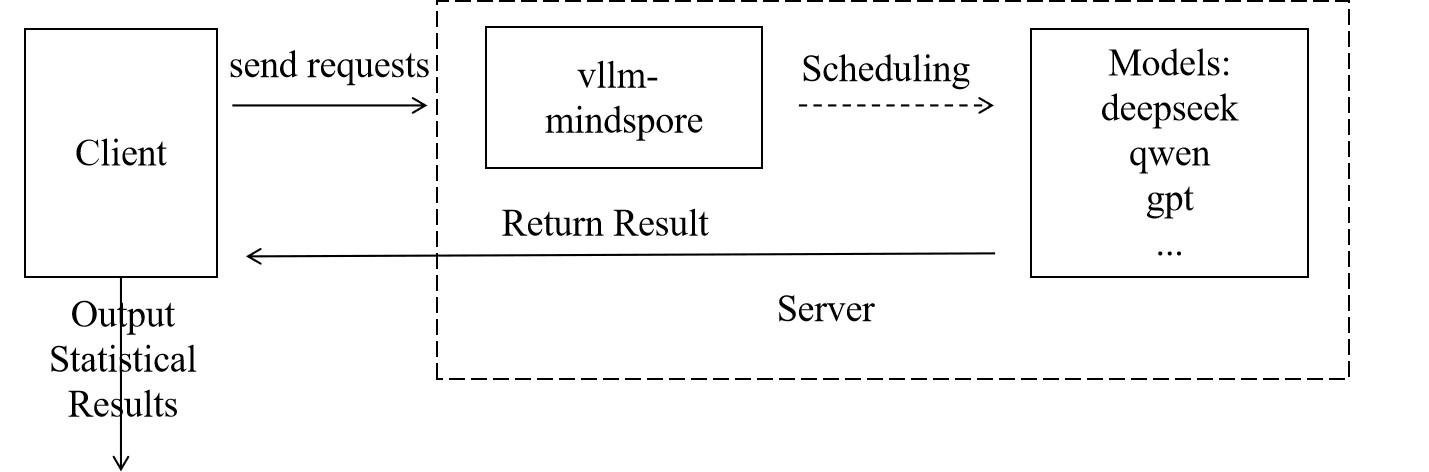
Preparations
The preparation phase mainly completes three tasks: installing the AISBench evaluation environment, downloading datasets, and starting the vLLM-MindSpore service.
Step 1 Install AISBench Evaluation Environment
Since AISBench has dependencies on both torch and transformers, but the official vLLM-MindSpore image contains a mocked torch implementation from the msadapter package which may cause conflicts, it is recommended to set up a separate container for installing the AISBench evaluation environment. If you insist on using the vLLM-MindSpore image to create a container for installing the evaluation environment, you need to perform the following steps to remove the existing torch and transformers packages inside the container after launching it:
rm -rf /usr/local/Python-3.11/lib/python3.11/site-packages/torch*
pip uninstall transformers
unset USE_TORCH
Then clone the repository and install from source:
git clone https://gitee.com/aisbench/benchmark.git
cd benchmark/
pip3 install -e ./ --use-pep517
Step 2 Dataset Download
The official documentation provides download links for each dataset. Taking CEVAL as an example, you can find the download link in the CEVAL documentation,, and execute the following commands to download and extract the dataset to the specified path:
cd ais_bench/datasets
mkdir ceval/
mkdir ceval/formal_ceval
cd ceval/formal_ceval
wget https://www.modelscope.cn/datasets/opencompass/ceval-exam/resolve/master/ceval-exam.zip
unzip ceval-exam.zip
rm ceval-exam.zip
For other dataset downloads, you can find download links in the corresponding dataset's official documentation.
Step 3 Start vLLM-MindSpore Service
For the specific startup process, see: Service Deployment Tutorial. Evaluation supports all service-deployable models.
Accuracy Evaluation Process
Accuracy evaluation first requires determining the evaluation interface and dataset type, which is specifically selected based on model capabilities and datasets.
Step 1 Modify Interface Configuration
AISBench supports OpenAI's v1/chat/completions and v1/completions interfaces, which correspond to different configuration files in AISBench. Taking the v1/completions interface as an example, referred to as the general interface, you need to modify the following file ais_bench/benchmark/configs/models/vllm_api/vllm_api_general.pyconfiguration:
from ais_bench.benchmark.models import VLLMCustomAPIChat
models = [
dict(
attr="service",
type=VLLMCustomAPIChat,
abbr='vllm-api-general-chat',
path="xxx/DeepSeek-R1-671B", # Specify the absolute path of the model serialization vocabulary file, generally the model weight folder path
model="DeepSeek-R1", # Specify the service-loaded model name, configured according to the actual VLLM inference service loaded model name (configured as an empty string will automatically obtain)
request_rate = 0, # Request sending frequency, send 1 request to the server every 1/request_rate seconds, if less than 0.1, send all requests at once
retry = 2,
host_ip = "localhost", # Specify the IP of the inference service
host_port = 8080, # Specify the port of the inference service
max_out_len = 512, # Maximum number of tokens output by the inference service
batch_size=128, # Maximum concurrent number of request sending, can speed up evaluation
generation_kwargs = dict( # Post-processing parameters, refer to model default configuration
temperature = 0.5,
top_k = 10,
top_p = 0.95,
seed = None,
repetition_penalty = 1.03,
)
)
]
For more specific parameter descriptions, refer to Interface Configuration Parameter Description.
Step 2 Start Evaluation via Command Line
Determine the dataset task to be used. Taking CEVAL as an example, using the ceval_gen_5_shot_str dataset task, the command is as follows:
ais_bench --models vllm_api_general --datasets ceval_gen_5_shot_str --debug
Parameter Description
--models: Specifies the model task interface, i.e., vllm_api_general, corresponding to the file name changed in the previous step. There is also vllm_api_general_chat--datasets: Specifies the dataset task, i.e., the ceval_gen_4_shot_str dataset task, where 4_shot means the question will be input repeatedly four times, and str means non-chat output
For more parameter configuration descriptions, see Configuration Description.
After the evaluation is completed, statistical results will be displayed on the screen. The specific execution results and logs will be saved in the outputs folder under the current path. In case of execution exceptions, problems can be located based on the logs.
Performance Evaluation Process
The performance evaluation process is similar to the accuracy evaluation process, but it pays more attention to the processing time of each stage of each request. By accurately recording the sending time of each request, the return time of each stage, and the response content, it systematically evaluates key performance indicators of the model service in actual deployment environments, such as response latency (such as TTFT, inter-token latency), throughput capacity (such as QPS, TPUT), and concurrent processing capabilities. The following uses the original GSM8K dataset for performance evaluation as an example.
Step 1 Modify Interface Configuration
By configuring service backend parameters, request content, request intervals, concurrent numbers, etc. can be flexibly controlled to adapt to different evaluation scenarios (such as low-concurrency latency-sensitive or high-concurrency throughput-prioritized). The configuration is similar to accuracy evaluation. Taking the vllm_api_stream_chat task as an example, modify the following configuration in ais_bench/benchmark/configs/models/vllm_api/vllm_api_stream_chat.py:
from ais_bench.benchmark.models import VLLMCustomAPIChatStream
models = [
dict(
attr="service",
type=VLLMCustomAPIChatStream,
abbr='vllm-api-stream-chat',
path="xxx/DeepSeek-R1-671B", # Specify the absolute path of the model serialization vocabulary file, generally the model weight folder path
model="DeepSeek-R1", # Specify the service-loaded model name, configured according to the actual VLLM inference service loaded model name (configured as an empty string will automatically obtain)
request_rate = 0, # Request sending frequency, send 1 request to the server every 1/request_rate seconds, if less than 0.1, send all requests at once
retry = 2,
host_ip = "localhost", # Specify the IP of the inference service
host_port = 8080, # Specify the port of the inference service
max_out_len = 512, # Maximum number of tokens output by the inference service
batch_size = 128, # Maximum concurrent number of request sending
generation_kwargs = dict(
temperature = 0.5,
top_k = 10,
top_p = 0.95,
seed = None,
repetition_penalty = 1.03,
ignore_eos = True, # Inference service output ignores eos (output length will definitely reach max_out_len)
)
)
]
For specific parameter descriptions, refer to Interface Configuration Parameter Description
Step 2 Evaluation Command
ais_bench --models vllm_api_stream_chat --datasets gsm8k_gen_0_shot_cot_str_perf --summarizer default_perf --mode perf
Parameter Description
--models: Specifies the model task interface, i.e., vllm_api_stream_chat corresponding to the file name of the configuration changed in the previous step.--datasets: Specifies the dataset task, i.e., the gsm8k_gen_0_shot_cot_str_perf dataset task, with a corresponding task file of the same name, where gsm8k refers to the dataset used, 0_shot means the question will not be repeated, str means non-chat output, and perf means performance testing--summarizer: Specifies task statistical data--mode: Specifies the task execution mode
For more parameter configuration descriptions, see Configuration Description.
Evaluation Results Description
After the evaluation is completed, performance evaluation results will be output, including single inference request performance output results and end-to-end performance output results. Parameter descriptions are as follows:
Metric |
Full Name |
Description |
|---|---|---|
E2EL |
End-to-End Latency |
Total latency (ms) from request sending to receiving complete response |
TTFT |
Time To First Token |
Latency (ms) for the first token to return |
TPOT |
Time Per Output Token |
Average generation latency (ms) per token in the output phase (excluding the first token) |
ITL |
Inter-token Latency |
Average interval latency (ms) between adjacent tokens (excluding the first token) |
InputTokens |
/ |
Number of input tokens in the request |
OutputTokens |
/ |
Number of output tokens generated by the request |
OutputTokenThroughput |
/ |
Throughput of output tokens (Token/s) |
Tokenizer |
/ |
Tokenizer encoding time (ms) |
Detokenizer |
/ |
Detokenizer decoding time (ms) |
For more evaluation tasks, such as synthetic random dataset evaluation and performance stress testing, see the following documentation: AISBench Official Documentation.
For more tips on optimizing inference performance, see the following documentation: Inference Performance Optimization.
For more parameter descriptions, see the following documentation: Performance Evaluation Results Description.
FAQ
Q: Evaluation results output does not conform to format, how to make the results output conform to expectations?
In some datasets, we may want the model's output to conform to our expectations, so we can change the prompt.
Taking ceval's gen_0_shot_str as an example, if we want the first token of the output to be the selected answer, we can modify the template in the following file:
# ais_bench/benchmark/configs/datasets/ceval/ceval_gen_0_shot_str.py Line 66 to 67
for _split in ['val']:
for _name in ceval_all_sets:
_ch_name = ceval_subject_mapping[_name][1]
ceval_infer_cfg = dict(
prompt_template=dict(
type=PromptTemplate,
template=f'以下是中国关于{_ch_name}考试的单项选择题,请选出其中的正确答案。\n{{question}}\nA. {{A}}\nB. {{B}}\nC. {{C}}\nD. {{D}}\n答案: {{answer}}',
),
retriever=dict(type=ZeroRetriever),
inferencer=dict(type=GenInferencer),
)
For other datasets, similarly modify the template in the corresponding files to construct appropriate prompts.
Q: How should interface types and inference lengths be configured for different datasets?
This specifically depends on the comprehensive consideration of model type and dataset type. For reasoning class models, the chat interface is recommended as it can enable thinking, and the inference length should be set longer. For base models, the general interface is used.
Taking the Qwen2.5 model evaluating the MMLU dataset as an example: From the dataset perspective, MMLU datasets mainly test knowledge, so the general interface is recommended. At the same time, when selecting dataset tasks, do not choose cot, i.e., do not enable the chain of thought.
Taking the QWQ32B model evaluating difficult mathematical reasoning questions like AIME2025 as an example: Use the chat interface with ultra-long inference length and use datasets with cot tasks.
Common Errors
1.Client returns HTML data with garbled characters
Error phenomenon: Return webpage HTML data
Solution: Check if the client has a proxy enabled, check proxy_https and proxy_http and turn off the proxy.
2.Server reports 400 Bad Request
Error phenomenon:
INFO: 127.0.0.1:53456 - "POST /v1/completions HTTP/1.1" 400 Bad Request
INFO: 127.0.0.1:53470 - "POST /v1/completions HTTP/1.1" 400 Bad Request
Solution: Check if the request format is correct in the client interface configuration.
3.Server reports error 404 xxx does not exist
Error phenomenon:
[serving_chat.py:135] Error with model object='error' message='The model 'Qwen3-30B-A3B-Instruct-2507' does not exist.' param=None code=404
"POST /v1/chat/completions HTTP/1.1" 404 Not Found
[serving_chat.py:135] Error with model object='error' message='The model 'Qwen3-30B-A3B-Instruct-2507' does not exist.'
Solution: Check if the model path in the interface configuration is accessible.
Appendix: Interface Configuration Parameter Description Table
Parameter |
Description |
|---|---|
type |
Task interface type |
path |
Absolute path of the model serialization vocabulary file, generally the model weight folder path |
model |
Service-loaded model name, configured according to the actual VLLM inference service loaded model name (configured as an empty string will automatically obtain) |
request_rate |
Request sending frequency, send 1 request to the server every 1/request_rate seconds, if less than 0.1, send all requests at once |
retry |
Number of retries when request fails |
host_ip |
IP of the inference service |
host_port |
Port of the inference service |
max_out_len |
Maximum number of tokens output by the inference service |
batch_size |
Maximum concurrent number of request sending |
temperature |
Post-processing parameter, temperature coefficient |
top_k |
Post-processing parameter |
top_p |
Post-processing parameter |
seed |
Random seed |
repetition_penalty |
Post-processing parameter, repetition penalty |
ignore_eos |
Inference service output ignores eos (output length will definitely reach max_out_len) |
References
The above only introduces the basic usage of AISBench. For more tutorials and usage methods, please refer to the official materials: