Other Training Features
![]()
During the large-scale training of deep learning models, challenges such as memory limitations, effective utilization of computational resources, and synchronization issues in distributed training are encountered. To address these challenges, training optimization algorithms are employed to enhance training efficiency, accelerate convergence, and improve the final model performance.
MindSpore Transformers provides optimization algorithms like Recomputation, Gradient Accumulation, and Gradient Clipping for use during training.
Gradient Accumulation
Overview
MindSpore supported the gradient accumulation implementation interface mindspore.nn.wrap.cell_wrapper.GradAccumulationCell in versions after 2.1.1, which provides the gradient accumulation capability by splitting MiniBatch. MindSpore Transformers encapsulates it into a unified training process and enables it through yaml configuration. For the principle of gradient accumulation and the ability of framework measurement, please refer to MindSpore Document: Gradient Accumulation.
Configuration and Usage
YAML Parameter Configuration
To enable gradient accumulation, users only need to configure the gradient_accumulation_steps item under the runner_config item in the configuration file and set it to the required number of gradient accumulation steps:
# runner config
runner_config:
...
gradient_accumulation_steps: 4
...
Key Parameters Introduction
Parameter |
Description |
Value Description |
|---|---|---|
gradient_accumulation_steps |
The number of steps to accumulate gradients before performing backpropagation. Default: |
(int, required) - Default value: |
Other Ways to Use Gradient Accumulation
In addition to the configuration file, when launching the run_mindformer.py script, you can specify the --gradient_accumulation_steps argument to use the gradient accumulation feature.
Usage Restrictions of Gradient Accumulation
Enabling gradient accumulation will increase memory overhead. Please pay attention to memory management to prevent Out Of Memory.
Since the implementation of
GradAccumulationCellrelies on parallel features, gradient accumulation is currently only supported in semi-automatic parallel mode;In addition, in the pipeline parallel scenario, the meaning of gradient accumulation is the same as micro_batch and will not take effect. Please configure the
micro_batch_numitem to increase the training batch_size.
Gradient Clipping
Overview
The gradient clipping algorithm can prevent gradient explosion caused by excessively large negative gradients, thereby helping the model training converge more stably.
Configuration and Usage
YAML Parameter Configuration
In MindSpore Transformers, the default training process MFTrainOneStepCell integrates gradient clipping logic.
You can use the following example to enable gradient clipping:
# wrapper cell config
runner_wrapper:
type: MFTrainOneStepCell
...
use_clip_grad: True
max_grad_norm: 1.0
...
Key Parameters Introduction
Parameter |
Description |
Value Description |
|---|---|---|
use_clip_grad |
Controls whether gradient clipping is enabled during training, default value: |
(bool, optional) - Default: |
max_grad_norm |
Controls the maximum norm value of gradient clipping, default value: |
(float, optional) - Default: |
GroupedMatmul
Overview
For MoE (Mixture of Experts), there are fragmented expert computation operations and communications. The GroupedMatmul operator merges multi-expert computations to improve the training performance of MoE. By invoking the GroupedMatmul operator, multiple expert computations are fused to achieve acceleration.
The token_dispatcher routes different tokens (input subwords or subunits) to different experts, compute units, or branches for independent processing based on the computed routing strategy. It primarily relies on all_to_all communication.
Configuration and Usage
YAML Parameter Configuration
In scenarios where GroupedMatmul needs to be enabled for MoE, users only need to set the use_gmm option to True under the moe_config section in the configuration file. If the fused operator for token_permute is required, configure use_fused_ops_permute to True:
moe_config:
...
use_gmm: True
use_fused_ops_permute: True
...
FAQ
When using the gmm fusion operator, an error may occur if the workload is unbalanced, resulting in no tokens being assigned to an expert on a specific NPU. The error is as follows:
ValueError: For primitive[Reshape], the accumulate of x_shape must be equal to out_shape, but got x_shape: [const vector]{}, and output_shape: [const vector]{0, hiddensize}
In this case, you can configure enable_gmm_safe_tokens: True to ensure each expert is assigned at least 1 token, avoiding program errors.
moe_config:
...
enable_gmm_safe_tokens: True
...
MoE DropRate Logging
Overview
When training models using the MoE (Mixture of Experts) capacity scheme, certain tokens may be dropped to improve efficiency and performance. By enabling the DropRate logging feature, users can monitor the occurrence rate of these drop operations in real-time during training, helping them better understand model behavior and adjust training strategies accordingly. This feature allows users to view the DropRate for each layer during training. DropRate refers to the proportion of tokens dropped in a specific layer. Observing the trend of DropRate changes can help users evaluate whether the current training parameters are reasonable and whether the model is effectively utilizing expert resources.
Configuration and Usage
YAML Parameter Configuration
To enable the DropRate logging feature, users need to configure the callback_moe_droprate parameter under the moe_config section in the configuration file and set it to True. Add the MoEDropRateCallback configuration item in the callback section and set model-related parameters such as expert_num, capacity_factor, num_layers, and mtp_depth. For example:
moe_config:
...
callback_moe_droprate: True
...
callback:
...
- type: MoEDropRateCallback
expert_num: 4
capacity_factor: 1.5
num_layers: 8
mtp_depth: 1
...
Key Configuration Parameters
Parameter |
Description |
Value Specification |
|---|---|---|
callback_moe_droprate |
Whether to print MoE DropRate in callback. |
(bool, optional) - Default: |
expert_num |
Number of experts. |
(int, required) - Default: |
capacity_factor |
Capacity factor. |
(float, required) - Default: |
num_layers |
Number of model layers. |
(int, required) - Default: |
mtp_depth |
Number of MTP layers. |
(int, required) - Default: |
Rotary Position Embedding Fusion Operator
Overview
When RoPE (Rotary Position Embedding) is used as the position encoding in the network, this fusion operator can be enabled to improve overall performance. This feature provides a fused implementation of RoPE, enhancing network performance. For the operator interface, refer to: mindspore.ops.rotary_position_embedding
Configuration and Usage
YAML Parameter Configuration
To use the rotary_position_embedding fusion operator, users need to configure the use_fused_rope parameter under the model_config section in the configuration file and set it to True. Example:
model_config:
...
use_fused_rope: True
...
SwiGLU Fusion Operator
Overview
When SwiGLU is used as the activation function in the network, this fusion operator can be enabled to improve overall performance. This feature provides a fused implementation of SwiGLU, enhancing network performance. For the operator functionality, refer to: mindspore.ops.swiglu.
Configuration and Usage
YAML Parameter Configuration
To use the SwiGLU fusion operator, users need to configure the use_fused_swiglu parameter under the model_config section in the configuration file and set it to True. For example:
model_config:
...
use_fused_swiglu: True
...
CPU Affinity Binding Configuration
Overview
MindSpore provides thread-level CPU core binding to allocate specific CPU cores for key MindSpore modules (main thread, pynative, runtime, and minddata), preventing performance instability caused by CPU core contention among MindSpore threads.
Configuration and Usage
YAML Parameter Configuration
There are two places to configure CPU affinity under the context field: affinity_cpu_list and affinity_config. affinity_cpu_list is merged into affinity_config, it will not be elaborated here. When both are configured, affinity_config will take effect.
Configure items in the affinity_config field under the context field. affinity_config and all its sub-fields are optional. A string ending with .json can also be passed to transfer the JSON configuration file to the MindSpore API. For details, please refer to mindspore.runtime.set_cpu_affinity. The following is a two-device example showing both custom configuration and JSON file methods achieving the same binding effect (device0's main thread binds to CPU 0 and CPU 1, minddata thread binds to CPU 10 and CPU 11; device1's main thread binds to CPU 20 and CPU 21, minddata thread binds to CPU 30 and CPU 31):
context:
...
affinity_config:
device_0:
affinity_cpu_list: ["0-3", "8-11"]
module_to_cpu_dict:
main: [0, 1]
minddata: [6, 7]
device_1:
affinity_cpu_list: ["20-23", "28-31"]
module_to_cpu_dict:
main: [0, 1]
minddata: [6, 7]
...
# Or pass in a JSON file path
context:
...
affinity_config: "path_to_file.json"
...
Here is an example of the JSON configuration file. For detailed configuration, please refer to Using JSON to Unify CPU/NUMA Affinity:
{
"bind_config": {
"bind_cpu_mode": "cpu"
},
"bind_cpu": {
"device0": {
"main": "0-1",
"minddata": "10-11"
},
"device1": {
"main": "20-21",
"minddata": "30-31"
}
}
}
JSON file configuration uses absolute CPU IDs, for example,
"main": "10-12"in JSON directly binds to physical CPU IDs 10, 11, 12; custom configuration (affinity_cpu_list+module_to_cpu_dict) uses absolute CPU range + relative indexing mechanism, whereaffinity_cpu_listdefines the available range (absolute IDs) andmodule_to_cpu_dictuses indices within that range. For example,affinity_cpu_list: ["10-20"]andmodule_to_cpu_dict: {main: [0, 1, 2]}mean selecting indices 0, 1, 2 from range 10-20, binding to physical CPU IDs 10, 11, 12.
Key Configuration Parameters
Parameter |
Description |
Value Specification |
|---|---|---|
device_id |
The id of the device to be configured |
Replace the letter |
affinity_cpu_list |
Manually specifies the CPU affinity range for the process. Format: |
(list, optional) - Default: |
module_to_cpu_dict |
Customizes core binding for specific modules. Valid keys (module names) are |
(dict, optional) - Default: |
Positional Encoding
Overview
Positional encoding is a key mechanism introduced to incorporate sequence order information into the Transformer architecture. In MindSpore Transformers, positional encoding is configured via the position_embedding_type parameter, supporting various mainstream positional encoding schemes to enhance the model's awareness of token positions. The specific supported encoding types include:
RoPE (Rotary Position Embedding): Encodes positional information through rotation matrices, offering good extrapolation capabilities.
YaRN: An improved variant of RoPE that better handles long sequences.
Learned Absolute Positional Encoding: Treats positional information as trainable parameters.
No Positional Encoding: Does not use explicit positional encoding.
Configuration and Usage
YAML Parameter Configuration
Users configure the position_embedding_type parameter under the model_config section in the configuration file to set the positional encoding. The current optional values and meanings for position_embedding_type are as follows:
'none': No positional encoding is used in any layer.
'rope': RoPE positional encoding is used in all layers. To achieve an alternating pattern between RoPE layers and layers without positional encoding, the
nope_layer_intervalparameter can be configured as a positive integer.nope_layer_intervalrepresents the number of encoded layers between adjacent layers without positional encoding.'yarn': YaRN positional encoding is used in all layers.
'learned_absolute': Learnable absolute positional encoding is used in all layers.
Examples:
Use YaRN positional encoding in all layers:
model_config: ... position_embedding_type: 'yarn' ...
Insert four RoPE positional encoding layers between every two layers without positional encoding:
model_config: ... position_embedding_type: 'rope' nope_layer_interval: 4 ...
SlidingWindowAttention
Overview
SlidingWindowAttention is a sparse attention mechanism that solves the problem of quadratic increase in computational complexity with sequence length in standard Transformer models by restricting each token to only focus on other tokens within a local window. The core idea is to narrow the attention range from global to a fixed window size.
Configuration and Usage
YAML Parameter Configuration
While use the SlidingWindowAttention module, you need to configure the window_size and window_attn_skip_freq items under the model_config item in the configuration file.
The type of window_size is Tuple[int, int], where window_size[0] represents pre_tokens, and window_size[1] represents next_tokens. Both are integers not less than -1, where -1 is a special value representing "infinite window size". The default starting point is the bottom right corner, as shown in the following figure:
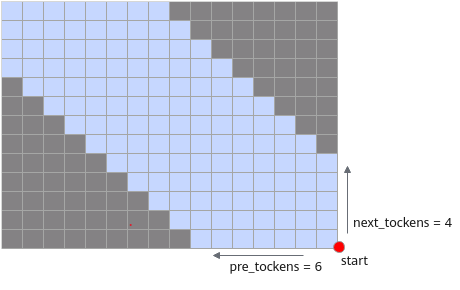
The type of window_attn_skip_freq is Union[int, List[int]], which represents the range of the number of neighboring tokens that a token can 'focus' on in each attention operation; window_size[0] represents the number of tokens followed forward, while window_size[1] represents the number of tokens followed backward. Any token set to -1 indicates an unlimited number of tokens to 'follow' forward or backward:
Equal Interval Mode: Specify an integer
Nto insert the full attention layer in a ratio of(N-1) : 1. After passing throughN − 1sliding window attention layers, a full attention layer is inserted.Custom mode: freely define the alternating order of attention layers through a Boolean value list. For example:
[1, 1, 1, 1, 0, 0, 0], where1represents the sliding window attention layer and0represents the full attention layer. This list determines the type of each layer in the network in order.
Example:
model_config:
...
window_size: [10, 0] # Each token focuses on 10 tokens forward and not backward
window_attn_skip_freq: 2 # There is a full attention layer every 2 layers
...