Graph-Kernel Fusion Acceleration Engine
![]()
Background
Mainstream AI computing frameworks such as MindSpore provide operators to users that is usually defined in terms of understandable and easy use for user. Each operator carries a different amount of computation and varies in computational complexity. However, from the hardware execution point of view, this natural, user perspective-based division of operator computation volume is not efficient and does not fully utilize the computational power of hardware resources, which is mainly reflected in the following aspects:
Computationally overloaded and overly complex operators, which usually makes it difficult to generate well-cut high-performance operator, thereby reducing equipment utilization.
Operators that are too small in computation may also cause latency in computation and thus reduce equipment utilization, as the computation cannot effectively hide the data moving overhead.
Hardware Devices are usually multi-core, many-core architectures. When the operator shape is small or other reasons cause insufficient computational parallelism, it may cause some cores to be idle, thus reducing the device utilization. In particular, chips based on Domain Specific Architecture (DSA for short) are more sensitive to these factors. It has been a big challenge to maximize the performance of hardware operator while making the operator easy to use.
In terms of AI framework design, the current industry mainstream adopts a separate layer implementation approach of graph and operator layers. The graph layer is responsible for fusing or regrouping the computational graph, and the operator layer is responsible for compiling the fused or regrouped operators into high-performance executable operators. The graph layer is usually processed and optimized by using Tensor-based High-Level IR, while the operator layer is analyzed and optimized by using computational instruction-based Low-Level IR. This artificial separate-layer process significantly increases the difficulty of performing collaborative optimization in both graph and computational layers.
MindSpore has adopted the technique of graph-kernel fusion to better solve this problem in the past few years. Typical networks in different categories such as NLP and recommendation show significant gains in training speed after enabling graph-kernel fusion. One of the main reasons is the presence of a large number of small operator combinations in these networks, which have more opportunities for fusion optimization.
Graph-Kernel Fusion Architecture and Overall Process
The overall architecture of graph-kernel fusion is shown in the figure below. The main idea in the graph layer is to turn on the composite operator, then perform cross-boundary aggregation and optimization, and finally perform Kernel operator splitting. The main steps include:
Composite Expansion: Expand the composite operator into the basic operator and form the Composite subgraph to facilitate subsequent cross-boundary optimization and operator splitting.
Cross-OP Aggregation: Aggregate adjacent elementary operators or Composite subgraphs to form larger aggregated subgraphs for subsequent cross-boundary optimization and operator splitting.
High-Level Optimization: Based on the aggregated subgraphs obtained in the above two steps, we can perform a large number of cross-boundary optimizations, such as algebraic simplification, common subexpression extraction (CSE).
Kernel Partition: Based on the computational features and the performance of the fusion operator, the operator splitting is performed on the aggregated computational subgraph.
The optimized computational graph is passed to MindSpore AKG as a subgraph for further back-end optimization and target code generation.

By following these steps, we can obtain two aspects of performance gains:
Cross-boundary performance optimization gains between different operators.
The optimal granularity of the fusion operator is obtained by reorganizing and splitting the entire computational graph.
Fusion Operator Acceleration Optimization (MindSpore AKG)
As mentioned earlier, in scenarios such as HPC and deep neural network training, graph-kernel fusion optimization can bring exponential performance improvements. However, with the increasing capability of graph-kernel fusion, the development of fusion operator becomes a bottleneck point to continue to improve the graph-kernel fusion capability. The automatic generation technology of fusion operators can solve the problem of high programming threshold for developing fusion operators based on DSA, allowing programmers to focus on the implementation logic of operators during operator development without focusing on back-end optimization, which greatly improves their development efficiency. Especially for scenarios with complex back-end hardware architectures and the presence of complex operators and fusion operators, automatic operator generation techniques are more critical.
Therefore, MindSpore AKG accelerates optimization and automatic generation of fusion operator based on Polyhedral Compilation Technology (Polyhedral Model), can help fused operators optimized by MindSpore graph-kernel fusion module to automatically generate high-performance kernel on heterogeneous hardware platforms (GPU/Ascend) and improve MindSpore training performance.
Architecture and Overall Process
The overall framework of MindSpore AKG is shown in the figure above:
IR Normalization
The input of MindSpore AKG is the fused subgraph optimized by MindSpore graph-kernel fusion module, and the operator in the subgraph is expressed by various descriptions such as TVM’s Compute/IR Builder/Hybrid. The DSL is then converted to Halide IR (Halide, a common language used to develop high-performance image processing and Array computation, which can be used as an intermediate expression for decoupling algorithms and optimization) and IR normalization.
After the initial simplification and optimization is completed, the Halide IR is transformed into the scheduling tree required by the Poly module.
Poly module scheduling optimization
Using the Pluto scheduling algorithm in Polyhedral technology to achieve automatic fusion of loops, automatic rearrangement and other transformations to automatically generate an initial schedule that satisfies parallelism and data locality for the fusion operator.
To quickly adapt to different hardware backends, the optimization pass in the Poly module is divided into hardware-independent generic optimizations and hardware-related specific optimizations, which are stitched and combined according to hardware features at compilation time, to achieve fast adaptation of heterogeneous hardware backends. The pass such as Auto-slicing, auto-mapping and auto-memory boosting will give different optimizations depending on the nature of the hardware architecture.
Backends optimization
In order to further improve the performance of the operator, we developed corresponding optimization passes for different hardware backends, such as data alignment and instruction mapping in Ascend backend, vectorized access and insertion of synchronization instructions in GPU backend, and finally generated the corresponding platform code.
Main Features
Polyhedral Scheduling Generation
The polyhedral model is a common circular nested optimization method in the field of computer-compiled optimization, and its theoretical basis is Presburger arithmetic. The polyhedral model allows us to analyze the read-write dependencies of statements in a program and then provides theoretical support for subsequent cyclic transformations. The core of polyhedral model cyclic optimization is its scheduling algorithm, which can define optimization objectives based on hardware architecture characteristics (such as parallelism and data locality) and convert the cyclic optimization problem into an integer programming problem for solving. In MindSpore AKG, the integer linear programming-based ISL scheduler is mainly used to perform a new scheduling transformation on the input program. The ISL scheduler is dominated by the Pluto algorithm and supplemented by the Feautrier algorithm, which seeks optimality between program parallelism and locality.
Auto-Tiling
What is tiling
Tiling is a widely used method of loop transformation that changes the order in which statement instances are accessed. As shown in the code below, each cycle of this 1024 x 1024 loop can be thought of as a visit to a single point on this two-dimensional space. A 4 x 4 tiling of this loop can change the order of access to the loop points from traversing a large matrix to traversing a small 4 x 4 matrix multiple times.
The value and challenge of tiling
Tiling and memory mapping of data allows access to data via smaller and faster caches. When the amount of computational data is larger than the cache space, it is necessary to adapt the hardware characteristics of the target architecture by storing the original data onto the cache after tiling. To find a good tile, developers need to have an understanding of the memory hierarchy and code logic of the hardware, to be able to analyze what data is logically reused and needs to be put into the cache, and even to have an understanding of the caching mechanism of the hardware (e.g. CPU) and the parallelism mechanism of the hardware (e.g. GPU), so that the tile can improve the utilization of hardware resources and the performance of the code.
MindSpore AKG automatic tiling solution
MindSpore AKG provides Auto-Tiling module, and the main process contains:
Modeling input analysis. Auto-Tiling transforms the logic of the input operator into a scheduling tree with the help of the Poly module, and the axis space extracts model to analyze the scheduling tree and extracts the overall axis space that can be tiled and scheduled.
Pruning the axis space. Auto-Tiling uses two constraint generation models to analyze the operator logic and hardware information to generate the corresponding operator constraints and hardware constraints, respectively. These constraints are divided into strong and weak constraints according to the range of the affected operator, which act on the axis space, and the axis space is reduced to obtain a constrained axis space.
Solving the axis space. Auto-Tiling generates different objective optimization functions based on the operator and hardware information. The solution model is based on the objective optimization function and is able to find a unique solution on the constrained axis space to generate the final tiling scheduling configuration.
Auto-Mapping
Auto-Mapping refers to automatically mapping data and instance in the execution order to multi-threaded processing units, such as the GPU’s Thread Block and Thread, on the hardware backend of a multi-threaded architecture. With Auto-Mapping, we can:
Reduce code complexity
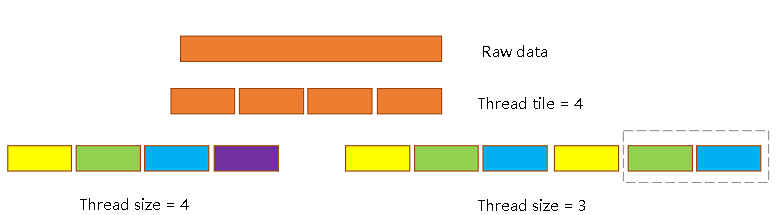
As shown in the figure below, with a shape of 8 * 12 operator, Auto-Tiling will try to take the tiling in (a) to reduce the circular boundary judgments shown in blue in (b).

Next, Auto-Mapping also tries to allocate a Thread size that can be divided by the tiled data to improve the utilization of Threads, as in the following example with a Thread of 4.
Optimize Block/Thread/Tile ratio
Auto-Mapping takes into account the hardware characteristics of the GPU when assigning Block size, Thread size and Tile size. Performance optimization is performed by adjusting the ratio of the three to improve the three aspects of utilization, memory throughput rate, and access speed.
Data Movement
For a wide variety of hardware backends, the architectural design usually contains multiple layers of buffers, and the memory space and computation speed supported by each buffer varies greatly, as well as the suitable type of computation. Therefore, when programmers put the programs into different hardware backends for execution, they also need to consider the division of operator into different on-chip memories and the flow of data in different on-chip Buffer, in addition to the computation instructions, to match the different storage structures and enhance the parallelism of the programs.
MindSpore AKG is based on Polyhedral technology to implement DMA data flow identification and generation based on multi-layer Buffer structure. Automatic data movement can further optimize the performance of the operator by analyzing the data flow and giving an indication of what buffers the data should be placed in and the order in which the data should be moved between buffers.
Taking the more complex Davinci architecture with on-chip memory hierarchy as an example, the steps of MindSpore AKG automatic data movement generation are as follows:
Traverse through the Halide IR of the operator input in turn, identify the type of each compute node, and analyze the compute module to be used for each statement according to the different types.
Classify on-chip cache Buffer according to on-chip cache model and specific chip parameters of the target chip.
Based on the computation units used in each statement, and the data dependencies between variables (Each computation unit, will read data from different on-chip Buffer and write the computation result back to different on-chip cache, and its dependency can be divided into three kinds of write-after-read WAR, read-after-write RAW, and write-after-write WAW), generate the operator data flow information.
For fusible scenarios, the data flow of the operators are optimized to obtain complete information on the data flow of the operators.
Output a Halide IR containing the complete data flow information of the operator.
Algorithm Optimization Scheme
The following is an example of two types of calculations to describe how MindSpore AKG uses the above features for automatic generation and optimization of complex operators.
Reduction Computation
The reduction computation, i.e., the cumulative operation on selected dimensions or all dimensions of the Tensor. The common operators are Sum, ReduceMax/Min, ReduceAnd/Or, etc. The Reduction scenario for a large shape is usually divided into two steps:
Divide the data into small tiles and perform tiling on each tile separately.
Perform tiling again on the tiling results for each tile, to obtain the final results.
MindSpore AKG optimizes the reduction operation by automatic axis fusion + polyhedral scheduling optimization + AKG-Reduce template library, and implements the two-step reduction into one kernel by atomic addition.
The process is shown in the figure above:
Operator expression: Firstly, the operator expression is resolved. In the stage of IR normalization, the identification and separation of reduction and non-reduction axes are performed, and the two types of axes are fused into two axes respectively by automatic axis fusion, while relevant information such as Tensor shape, reduction direction is recorded.
Poly module: The Pluto algorithm is used to perform scheduling transformations, calculate the optimal tiling parameters by analyzing the previously recorded information, and perform data movement to shared memory and registers.
Instruction launching and code generation: From the scheduling tree to the launch phase of Halide IR, interface call statements are inserted and called during the code generation phase. Call the AkgReduce template library for high-performance in-block accumulation of threads. Call the AkgAtomicReturn atomic addition interface to add up the intermediate results of each thread block to get the final result and ensure the correctness of the calculation.
General matrix multiply and Convolution
MindSpore AKG uses the GPU’s Tensor Core hardware computational unit and combines it with polyhedral compilation scheduling optimization and high-performance inline PTX libraries to accelerate general matrix multiply computations in mixed precision scenarios.
On this basis, MindSpore AKG uses the Implicit GEMM to handle mixed accuracy convolution calculations. The two four-dimensional input matrices of the convolution are converted into two-dimensional matrices during the movement from global memory to shared memory, which in turn translates into matrix multiplication calculations for optimization. This method can solve the data redundancy caused by Image to Column (Image to Column is a common convolutional optimization method, referred to as Im2col, which converts each feature map into a contiguous column, and the converted matrix will occupy more global memory).
Taking the optimization of convolutional computation as an example, the process is as follows:
Analyze the operator DSL and Halide IR, parse the GEMM expressions and record the data type, shape, and layout of the matrix. The convolution operator has a more complex shape (usually four dimensions of NHWC), and in this step MindSpore AKG abstracts its four dimensions and associates them to the two virtual axes corresponding to the general matrix multiply.
Targeted scheduling optimization in Poly module, including multiple tiles, Warp level mapping, multi-tier memory boost (Data reusing on shared memory and high-speed multiplication and addition by using TensorCore on registers), etc. For the convolution operator, it is also necessary to consider the two extra dimensions H and W when performing multiple tiles as well as calculating the tiling parameters.
Execute back-end optimization pass based on Halide IR, including data prefetching to save waiting time between handling and computation, data completion and rearrangement to eliminate bank conflicts, vectorization instructions to improve the efficiency of data loading and writing, etc.
Call the akg::wmma high-performance interface (contains finer-grained optimizations at the PTX level) to generate the final CUDA Kernel.
Users and developers can understand the optimization process of fusion or complex operators by running the test cases of MindSpore AKG. Taking the code related to convolution operators as an example:
The four-dimensional convolution (without Pad operation) is calculated as follows, where \(N = 32, H = W = 28, Co = 128, Ci = 64, Hk = Hw = 5\).
\[Output(n, h, w, o)=\sum_{c=1}^{Ci} \sum_{rh=1}^{Hk} \sum_{rw=1}^{Wk} (Image(n, h+rh, w+rw, c)*Filter(o, rh, rw, c))\]Based on its formula, the operator DSL can be written by using tvm.compute:
n, in_h, in_w, in_c = data.shape out_c, k_h, k_w, in_c = weight.shape _, _, s_h, s_w = stride o_h = (in_h - k_h) // s_h + 1 o_w = (in_w - k_w) // s_w + 1 rc = tvm.reduce_axis((0, in_c), name="rc") rh = tvm.reduce_axis((0, k_h), name="rh") rw = tvm.reduce_axis((0, k_w), name="rw") output = tvm.compute( (n, o_h, o_w, out_c), lambda n, h, w, o: tvm.sum( data[n, (h * s_h + rh), (w * s_w + rw), rc] * weight[o, rh, rw, rc], axis=[rc, rh, rw]), name=output_name ) return output
The following initial scheuling is generated, containing seven for loops, which is computationally inefficient:
// attr [compute(out, 0x55c9185ce710)] realize_scope = "" realize out<float16>([0, 32], [0, 28], [0, 28], [0, 128]) { produce out { for (n, 0, 32) { for (h, 0, 28) { for (w, 0, 28) { for (o, 0, 128) { out(n, h, w, o) = 0h for (rc, 0, 64) { for (rh, 0, 5) { for (rw, 0, 5) { // attr [[iter_var(rc, range(min=0, ext=64)), iter_var(rh, range(min=0, ext=5)), iter_var(rw, range(min=0, ext=5))]] reduce_update = "" out(n, h, w, o) = (out(n, h, w, o) + (input_1(n, (h + rh), (w + rw), rc)*input_2(o, rh, rw, rc))) } } } } } } } } }
After Poly module scheduling optimization, multiple back-end optimization pass and code generation, the program parallelism and data localization of the arithmetic is greatly improved, and the final CUDA kernel executed on the GPU is obtained as follows:
// Introduce the akg_mma_lib high-performance library #include "akg_mma_lib/wmma.hpp" extern "C" __global__ void conv_tc_auto_float16_32_32_32_64_float16_128_5_5_64_1_1_0_0_0_0_1_1_float16_kernel0( half* __restrict__ input_1, half* __restrict__ input_2, half* __restrict__ out) { // Buffer assignment akg::wmma::fragment<nvcuda::wmma::accumulator, 16, 16, 8, float> out_local[4]; half input_2_shared_transfer[32]; __shared__ half input_2_shared[13056]; half input_1_shared_transfer[16]; akg::wmma::fragment<nvcuda::wmma::matrix_b, 16, 16, 8, half, nvcuda::wmma::col_major> input_2_local[2]; akg::wmma::fragment<nvcuda::wmma::matrix_a, 16, 16, 8, half, nvcuda::wmma::row_major> input_1_local[2]; #pragma unroll for (int cc5 = 0; cc5 < 5; ++cc5) { // Preload the data to be used for this calculation from global memory to shared memory // Vectorized reading with float4 pointers #pragma unroll for (int cc7 = 0; cc7 < 4; ++cc7) { ((float4*)input_2_shared_transfer)[((cc7 * 8) + 0) / 8] = ((float4*)input_2)[(((((cc7 * 51200) + ((((int)threadIdx.x) / 8) * 1600)) + (cc5 * 320)) + ((((int)threadIdx.x) % 8) * 8)) + 0) / 8]; } #pragma unroll for (int cc71 = 0; cc71 < 4; ++cc71) { ((float4*)input_2_shared)[(((((cc71 * 2176) + ((((int)threadIdx.x) / 128) * 1088)) + ((((int)threadIdx.x) % 8) * 136)) + (((((int)threadIdx.x) % 128) / 8) * 8)) + 0) / 8] = ((float4*)input_2_shared_transfer)[((cc71 * 8) + 0) / 8]; } #pragma unroll for (int cc72 = 0; cc72 < 2; ++cc72) { ((float4*)input_1_shared_transfer)[((cc72 * 8) + 0) / 8] = ((float4*)input_1)[(((((((cc72 * 1048576) + ((((int)threadIdx.x) / 16) * 65536)) + ((((int)blockIdx.y) / 14) * 2048)) + (cc5 * 2048)) + ((((int)blockIdx.y) % 14) * 128)) + ((((int)threadIdx.x) % 16) * 8)) + 0) / 8]; } #pragma unroll for (int cc73 = 0; cc73 < 2; ++cc73) { ((float4*)input_2_shared)[(((((cc73 * 2176) + ((((int)threadIdx.x) % 16) * 136)) + ((((int)threadIdx.x) / 16) * 8)) + 0) + 8704) / 8] = ((float4*)input_1_shared_transfer)[((cc73 * 8) + 0) / 8]; } __syncthreads(); #pragma unroll for (int cc6_outer = 0; cc6_outer < 4; ++cc6_outer) { // Preload the data to be used for the next calculation from global memory into registers #pragma unroll for (int cc74 = 0; cc74 < 4; ++cc74) { ((float4*)input_2_shared_transfer)[((cc74 * 8) + 0) / 8] = ((float4*)input_2)[(((((((cc74 * 51200) + ((((int)threadIdx.x) / 8) * 1600)) + (cc5 * 320)) + (cc6_outer * 64)) + ((((int)threadIdx.x) % 8) * 8)) + 0) + 64) / 8]; } #pragma unroll for (int cc75 = 0; cc75 < 2; ++cc75) { ((float4*)input_1_shared_transfer)[((cc75 * 8) + 0) / 8] = ((float4*)input_1)[(((((((((cc75 * 1048576) + ((((int)threadIdx.x) / 16) * 65536)) + ((((int)blockIdx.y) / 14) * 2048)) + (cc5 * 2048)) + ((((int)blockIdx.y) % 14) * 128)) + (cc6_outer * 64)) + ((((int)threadIdx.x) % 16) * 8)) + 0) + 64) / 8]; } // Call high performance interfaces for data movement, initialization and mma calculation #pragma unroll for (int cc11 = 0; cc11 < 8; ++cc11) { #pragma unroll for (int cc123 = 0; cc123 < 2; ++cc123) { (void)akg::wmma::load_matrix_sync(input_2_local[cc123], &(input_2_shared[((((((int)threadIdx.x) / 64) * 2176) + (cc123 * 1088)) + (cc11 * 136))]), 8); } #pragma unroll for (int cc124 = 0; cc124 < 2; ++cc124) { (void)akg::wmma::load_matrix_sync(input_1_local[cc124], &(input_2_shared[((((((((int)threadIdx.x) % 64) / 32) * 2176) + (cc124 * 1088)) + (cc11 * 136)) + 8704)]), 8); } #pragma unroll for (int cc21 = 0; cc21 < 2; ++cc21) { #pragma unroll for (int cc22 = 0; cc22 < 2; ++cc22) { if (((cc5 == 0) && (cc6_outer == 0)) && (cc11 == 0)) { (void)akg::wmma::fill_fragment(out_local[((cc21 * 2) + cc22)], 0.000000e+00f); } (void)akg::wmma::mma_sync(out_local[((cc21 * 2) + cc22)], input_1_local[cc21], input_2_local[cc22], out_local[((cc21 * 2) + cc22)]); } } } // Move the data to be used for the next calculation from registers to shared memory __syncthreads(); #pragma unroll for (int cc76 = 0; cc76 < 4; ++cc76) { ((float4*)input_2_shared)[(((((cc76 * 2176) + ((((int)threadIdx.x) / 128) * 1088)) + ((((int)threadIdx.x) % 8) * 136)) + (((((int)threadIdx.x) % 128) / 8) * 8)) + 0) / 8] = ((float4*)input_2_shared_transfer)[((cc76 * 8) + 0) / 8]; } #pragma unroll for (int cc77 = 0; cc77 < 2; ++cc77) { ((float4*)input_2_shared)[(((((cc77 * 2176) + ((((int)threadIdx.x) % 16) * 136)) + ((((int)threadIdx.x) / 16) * 8)) + 0) + 8704) / 8] = ((float4*)input_1_shared_transfer)[((cc77 * 8) + 0) / 8]; } __syncthreads(); } #pragma unroll for (int cc111 = 0; cc111 < 8; ++cc111) { #pragma unroll for (int cc126 = 0; cc126 < 2; ++cc126) { (void)akg::wmma::load_matrix_sync(input_2_local[cc126], &(input_2_shared[((((((int)threadIdx.x) / 64) * 2176) + (cc126 * 1088)) + (cc111 * 136))]), 8); } #pragma unroll for (int cc127 = 0; cc127 < 2; ++cc127) { (void)akg::wmma::load_matrix_sync(input_1_local[cc127], &(input_2_shared[((((((((int)threadIdx.x) % 64) / 32) * 2176) + (cc127 * 1088)) + (cc111 * 136)) + 8704)]), 8); } #pragma unroll for (int cc211 = 0; cc211 < 2; ++cc211) { #pragma unroll for (int cc221 = 0; cc221 < 2; ++cc221) { (void)akg::wmma::mma_sync(out_local[((cc211 * 2) + cc221)], input_1_local[cc211], input_2_local[cc221], out_local[((cc211 * 2) + cc221)]); } } } __syncthreads(); } #pragma unroll for (int cc4 = 0; cc4 < 2; ++cc4) { #pragma unroll for (int cc6 = 0; cc6 < 2; ++cc6) { (void)akg::wmma::store_matrix_sync(&(input_2_shared[((((((((int)threadIdx.x) % 64) / 32) * 4352) + (cc4 * 136)) + ((((int)threadIdx.x) / 64) * 32)) + (cc6 * 16))]), out_local[((cc4 * 2) + cc6)], 272, nvcuda::wmma::mem_row_major); } } // Move the calculation results out to the output buffer in global memory __syncthreads(); #pragma unroll for (int cc41 = 0; cc41 < 4; ++cc41) { ((float4*)out)[(((((cc41 * 802816) + ((((int)threadIdx.x) / 32) * 100352)) + (((int)blockIdx.y) * 256)) + ((((int)threadIdx.x) % 32) * 8)) + 0) / 8] = ((float4*)input_2_shared)[((((cc41 * 2176) + ((((int)threadIdx.x) / 16) * 136)) + ((((int)threadIdx.x) % 16) * 8)) + 0) / 8]; } __syncthreads(); }
MindSpore AKG supports the generation of forward and backward fusion scenarios for reduction, general matrix multiply and convolution operators, ensuring the performance of fusion operators while saving inter-operator I/O and memory consumption.