mindspore.dataset
At the heart of MindSpore data loading utility is the mindspore.dataset module. It is a dataset engine based on pipline design.
This module provides the following data loading methods to help users load datasets into MindSpore.
User defined dataset loading: allows users to define Random-accessible(Map-style) dataset or Iterable-style dataset to customize data reading and processing logic.
Standard format dataset loading: support loading dataset files in standard data formats, including MindRecord, TFRecord .
Open source dataset loading: supports reading open source datasets , such as MNIST, CIFAR-10, CLUE, LJSpeech, etc.
In addition, this module also provides data sampler, transformations, batching, as well as basic configurations such as random seed, parallelism setting and other features, to be used in conjunction with the dataset loading.
Data Sampler: Provides various common sampler, such as RandomSampler, DistributedSampler, etc.
Data Transformations: Provides multiple dataset operations to perform data augmentation, batching.
Basic Configuration: Provides pipeline configuration for random seed setting, parallelism setting, data recovery mode, etc.
Descriptions of common dataset terms are as follows:
Dataset, the base class of all the datasets. It provides data processing methods to help preprocess the data.
SourceDataset, an abstract class to represent the source of dataset pipeline which produces data from data sources such as files and databases.
MappableDataset, an abstract class to represent a source dataset which supports for random access.
Iterator, the base class of dataset iterator for enumerating elements.
Introduction to data processing pipeline
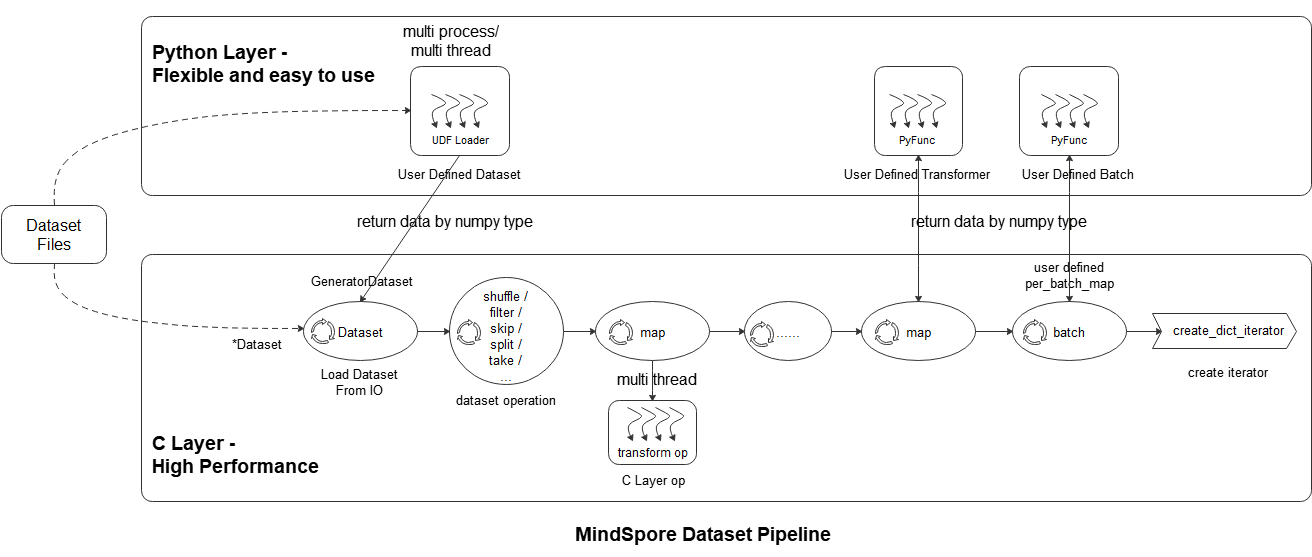
As shown in the above figure, the mindspore dataset module makes it easy for users to define data preprocessing pipelines and transform samples in the dataset in the most efficient (multi-process / multi-thread) manner. The specific steps are as follows:
Loading datasets: Users can easily load supported datasets using the Dataset class (Standard-format Dataset, Vision Dataset, NLP Dataset, Audio Dataset, or load Python layer customized datasets through User Defined Dataset,
Dataset operation: The user uses the dataset object method .shuffle / .filter / .skip / .split / .take / … to further shuffle, filter, skip, and obtain the maximum number of samples of datasets.
Dataset sample transform operation: The user can add data transform operations (vision transform, nlp transform, audio transform ) to the .map operation to perform transforms. During data preprocessing, multiple map operations can be defined to perform different transform operations to different fields. The data transform operation can also be a user-defined Python function.
Batch: After the transforms of the samples, the user can use the .batch operation to organize multiple samples into batches, or use self-defined batch logic with the parameter per_batch_map applied.
Iterator: Finally, user can use the method .create_dict_iterator or .create_tuple_iterator to create an iterator, which can output the preprocessed data cyclically.
Quick start of Dataset Pipeline
For a quick start of using Dataset Pipeline, download Load & Process Data With Dataset Pipeline to local and run in sequence.
- class mindspore.dataset.AGNewsDataset(dataset_dir, usage=None, num_samples=None, num_parallel_workers=None, shuffle=Shuffle.GLOBAL, num_shards=None, shard_id=None, cache=None)[source]
AG News dataset.
The generated dataset contains three columns:
[index, title, description], and the data type of all three columns is string type.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
usage (str, optional) – Acceptable usages include
'train','test'and'all'. Default:None, all samples will be read.num_samples (int, optional) – Number of samples (rows) to read. Default:
None, reads the full dataset.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (Union[bool, Shuffle], optional) –
Data shuffling mode in each epoch. The bool type or enumeration type can be transferred for specifying. Default:
Shuffle.GLOBAL. If shuffle isFalse, no shuffling will be performed. If shuffle isTrue, it is equivalent to setting shuffle toShuffle.GLOBAL. Set the mode of data shuffling by passing in enumeration variables:Shuffle.GLOBAL: Shuffle both the files and samples.Shuffle.FILES: Shuffle files only.
num_shards (int, optional) – Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the max sample number of per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . This argument can only be specified when num_shards is also specified. Default:
None.cache (DatasetCache, optional) – Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir does not contain data files.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If num_parallel_workers exceeds the max thread numbers.
- Tutorial Examples:
Examples
>>> import mindspore.dataset as ds >>> ag_news_dataset_dir = "/path/to/ag_news_dataset_file" >>> dataset = ds.AGNewsDataset(dataset_dir=ag_news_dataset_dir, usage='all')
About AG News dataset:
AG News is a collection of over 1 million news articles. The news articles were collected by ComeToMyHead from over 2,000 news sources in over 1 year of activity. ComeToMyHead is an academic news search engine that has been in operation since July 2004. The dataset is provided by academics for research purposes such as data mining (clustering, classification, etc.), information retrieval (ranking, searching, etc.), xml, data compression, data streaming, and any other non-commercial activities. AG's news topic classification dataset was constructed by selecting the four largest classes from the original corpus. Each class contains 30,000 training samples and 1,900 test samples. The total number of training samples in train.csv is 120,000 and the number of test samples in test.csv is 7,600.
You can unzip the dataset files into the following structure and read by MindSpore's API:
. └── ag_news_dataset_dir ├── classes.txt ├── train.csv ├── test.csv └── readme.txtCitation:
@misc{zhang2015characterlevel, title={Character-level Convolutional Networks for Text Classification}, author={Xiang Zhang and Junbo Zhao and Yann LeCun}, year={2015}, eprint={1509.01626}, archivePrefix={arXiv}, primaryClass={cs.LG} }
- class mindspore.dataset.AmazonReviewDataset(dataset_dir, usage=None, num_samples=None, num_parallel_workers=None, shuffle=Shuffle.GLOBAL, num_shards=None, shard_id=None, cache=None)[source]
Amazon Review Polarity and Amazon Review Full datasets.
The generated dataset contains three columns:
[label, title, content], and the data type of all three columns is string.- Parameters:
dataset_dir (str) – Path to the root directory that contains the Amazon Review Polarity dataset or the Amazon Review Full dataset.
usage (str, optional) – Usage of this dataset, can be
'train','test'or'all'. For Polarity dataset,'train'will read from 3,600,000 train samples,'test'will read from 400,000 test samples,'all'will read from all 4,000,000 samples. For Full dataset,'train'will read from 3,000,000 train samples,'test'will read from 650,000 test samples,'all'will read from all 3,650,000 samples. Default:None, all samples will be read.num_samples (int, optional) – Number of samples (rows) to be read. Default:
None, reads the full dataset.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (Union[bool, Shuffle], optional) –
Data shuffling mode in each epoch. The bool type or enumeration type can be transferred for specifying. Default:
Shuffle.GLOBAL. If shuffle isFalse, no shuffling will be performed. If shuffle isTrue, it is equivalent to setting shuffle toShuffle.GLOBAL. Set the mode of data shuffling by passing in enumeration variables:Shuffle.GLOBAL: Shuffle both the files and samples.Shuffle.FILES: Shuffle files only.
num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the max sample number of per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir does not contain data files.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If num_parallel_workers exceeds the max thread numbers.
- Tutorial Examples:
Examples
>>> import mindspore.dataset as ds >>> amazon_review_dataset_dir = "/path/to/amazon_review_dataset_dir" >>> dataset = ds.AmazonReviewDataset(dataset_dir=amazon_review_dataset_dir, usage='all')
About AmazonReview Dataset:
The Amazon reviews full dataset consists of reviews from Amazon. The data span a period of 18 years, including ~35 million reviews up to March 2013. Reviews include product and user information, ratings, and a plaintext review. The dataset is mainly used for text classification, given the content and title, predict the correct star rating.
The Amazon reviews polarity dataset is constructed by taking review score 1 and 2 as negative, 4 and 5 as positive. Samples of score 3 is ignored.
The Amazon Reviews Polarity and Amazon Reviews Full datasets have the same directory structures. You can unzip the dataset files into the following structure and read by MindSpore's API:
. └── amazon_review_dir ├── train.csv ├── test.csv └── readme.txtCitation:
@article{zhang2015character, title={Character-level convolutional networks for text classification}, author={Zhang, Xiang and Zhao, Junbo and LeCun, Yann}, journal={Advances in neural information processing systems}, volume={28}, pages={649--657}, year={2015} }
- class mindspore.dataset.CLUEDataset(dataset_files, task='AFQMC', usage='train', num_samples=None, num_parallel_workers=None, shuffle=Shuffle.GLOBAL, num_shards=None, shard_id=None, cache=None)[source]
CLUE(Chinese Language Understanding Evaluation) dataset. Supported CLUE classification tasks:
'AFQMC','TNEWS','IFLYTEK','CMNLI','WSC'and'CSL'.- Parameters:
dataset_files (Union[str, list[str]]) – String or list of files to be read or glob strings to search for a pattern of files. The list will be sorted in a lexicographical order.
task (str, optional) – The type of task, one of
'AFQMC','TNEWS','IFLYTEK','CMNLI','WSC'and'CSL'. Default:'AFQMC'.usage (str, optional) – Specify the
'train','test'or'eval'part of dataset. Default:'train'.num_samples (int, optional) – The number of samples to be included in the dataset. Default:
None, will include all samples.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (Union[bool, Shuffle], optional) –
Data shuffling mode in each epoch. The bool type or enumeration type can be transferred for specifying. Default:
Shuffle.GLOBAL. If shuffle isFalse, no shuffling will be performed. If shuffle isTrue, it is equivalent to setting shuffle toShuffle.GLOBAL. There are three levels of shuffling, desired shuffle enum defined bymindspore.dataset.Shuffle.Shuffle.GLOBAL: Shuffle both the files and samples, same as setting shuffle toTrue.Shuffle.FILES: Shuffle files only.
num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the maximum sample number of per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
The generated dataset with different task settings has different output columns:
task
usage
Output column
AFQMC
train
[sentence1, dtype=string]
[sentence2, dtype=string]
[label, dtype=string]
test
[id, dtype=uint32]
[sentence1, dtype=string]
[sentence2, dtype=string]
eval
[sentence1, dtype=string]
[sentence2, dtype=string]
[label, dtype=string]
TNEWS
train
[label, dtype=string]
[label_des, dtype=string]
[sentence, dtype=string]
[keywords, dtype=string]
test
[label, dtype=uint32]
[keywords, dtype=string]
[sentence, dtype=string]
eval
[label, dtype=string]
[label_des, dtype=string]
[sentence, dtype=string]
[keywords, dtype=string]
IFLYTEK
train
[label, dtype=string]
[label_des, dtype=string]
[sentence, dtype=string]
test
[id, dtype=uint32]
[sentence, dtype=string]
eval
[label, dtype=string]
[label_des, dtype=string]
[sentence, dtype=string]
CMNLI
train
[sentence1, dtype=string]
[sentence2, dtype=string]
[label, dtype=string]
test
[id, dtype=uint32]
[sentence1, dtype=string]
[sentence2, dtype=string]
eval
[sentence1, dtype=string]
[sentence2, dtype=string]
[label, dtype=string]
WSC
train
[span1_index, dtype=uint32]
[span2_index, dtype=uint32]
[span1_text, dtype=string]
[span2_text, dtype=string]
[idx, dtype=uint32]
[text, dtype=string]
[label, dtype=string]
test
[span1_index, dtype=uint32]
[span2_index, dtype=uint32]
[span1_text, dtype=string]
[span2_text, dtype=string]
[idx, dtype=uint32]
[text, dtype=string]
eval
[span1_index, dtype=uint32]
[span2_index, dtype=uint32]
[span1_text, dtype=string]
[span2_text, dtype=string]
[idx, dtype=uint32]
[text, dtype=string]
[label, dtype=string]
CSL
train
[id, dtype=uint32]
[abst, dtype=string]
[keyword, dtype=string]
[label, dtype=string]
test
[id, dtype=uint32]
[abst, dtype=string]
[keyword, dtype=string]
eval
[id, dtype=uint32]
[abst, dtype=string]
[keyword, dtype=string]
[label, dtype=string]
- Raises:
ValueError – If dataset_files are not valid or do not exist.
ValueError – task is not in
'AFQMC','TNEWS','IFLYTEK','CMNLI','WSC'or'CSL'.ValueError – usage is not in
'train','test'or'eval'.ValueError – If num_parallel_workers exceeds the max thread numbers.
ValueError – If shard_id is not in range of [0, num_shards ).
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
- Tutorial Examples:
Examples
>>> import mindspore.dataset as ds >>> clue_dataset_dir = ["/path/to/clue_dataset_file"] # contains 1 or multiple clue files >>> dataset = ds.CLUEDataset(dataset_files=clue_dataset_dir, task='AFQMC', usage='train')
About CLUE dataset:
CLUE, a Chinese Language Understanding Evaluation benchmark. It contains multiple tasks, including single-sentence classification, sentence pair classification, and machine reading comprehension.
You can unzip the dataset files into the following structure and read by MindSpore's API, such as afqmc dataset:
. └── afqmc_public ├── train.json ├── test.json └── dev.jsonCitation:
@article{CLUEbenchmark, title = {CLUE: A Chinese Language Understanding Evaluation Benchmark}, author = {Liang Xu, Xuanwei Zhang, Lu Li, Hai Hu, Chenjie Cao, Weitang Liu, Junyi Li, Yudong Li, Kai Sun, Yechen Xu, Yiming Cui, Cong Yu, Qianqian Dong, Yin Tian, Dian Yu, Bo Shi, Jun Zeng, Rongzhao Wang, Weijian Xie, Yanting Li, Yina Patterson, Zuoyu Tian, Yiwen Zhang, He Zhou, Shaoweihua Liu, Qipeng Zhao, Cong Yue, Xinrui Zhang, Zhengliang Yang, Zhenzhong Lan}, journal = {arXiv preprint arXiv:2004.05986}, year = {2020}, howpublished = {https://github.com/CLUEbenchmark/CLUE} }
- class mindspore.dataset.CMUArcticDataset(dataset_dir, name=None, num_samples=None, num_parallel_workers=None, shuffle=None, sampler=None, num_shards=None, shard_id=None, cache=None)[source]
CMU Arctic dataset.
The generated dataset has four columns:
[waveform, sample_rate, transcript, utterance_id]. The tensor of columnwaveformis of the float32 type. The tensor of columnsample_rateis of a scalar of uint32 type. The tensor of columntranscriptis of a scalar of string type. The tensor of columnutterance_idis of a scalar of string type.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
name (str, optional) – Part of this dataset, can be
'aew','ahw','aup','awb','axb','bdl','clb','eey','fem','gka','jmk','ksp','ljm','lnh','rms','rxr','slp'or'slt'. Default:None, means'aew'.num_samples (int, optional) – The number of audio files to be included in the dataset. Default:
None, will read all audio files.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (bool, optional) – Whether or not to perform shuffle on the dataset. Default:
None, expected order behavior shown in the table below.sampler (Sampler, optional) – Object used to choose samples from the dataset. Default:
None, expected order behavior shown in the table below.num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None, no dividing. When this argument is specified, num_samples reflects the max sample number of per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None, will use0. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir does not contain data files.
ValueError – If num_parallel_workers exceeds the max thread numbers.
RuntimeError – If sampler and shuffle are specified at the same time.
RuntimeError – If sampler and num_shards/shard_id are specified at the same time.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If shard_id is not in range of [0, num_shards ).
- Tutorial Examples:
Note
Not support
mindspore.dataset.PKSamplerfor sampler parameter yet.The parameters num_samples , shuffle , num_shards , shard_id can be used to control the sampler used in the dataset, and their effects when combined with parameter sampler are as follows.
Examples
>>> import mindspore.dataset as ds >>> cmu_arctic_dataset_directory = "/path/to/cmu_arctic_dataset_directory" >>> >>> # 1) Read 500 samples (audio files) in cmu_arctic_dataset_directory >>> dataset = ds.CMUArcticDataset(cmu_arctic_dataset_directory, name="ahw", num_samples=500) >>> >>> # 2) Read all samples (audio files) in cmu_arctic_dataset_directory >>> dataset = ds.CMUArcticDataset(cmu_arctic_dataset_directory)
About CMUArctic dataset:
The CMU Arctic databases are designed for speech synthesis research. These single speaker speech databases have been carefully recorded under studio conditions and consist of approximately 1200 phonetically balanced English utterances. In addition to wave files, the databases provide complete support for the Festival Speech Synthesis System, including pre-built voices that may be used as is. The entire package is distributed as free software, without restriction on commercial or non-commercial use.
You can construct the following directory structure from CMUArctic dataset and read by MindSpore's API.
. └── cmu_arctic_dataset_directory ├── cmu_us_aew_arctic │ ├── wav │ │ ├──arctic_a0001.wav │ │ ├──arctic_a0002.wav │ │ ├──... │ ├── etc │ │ └── txt.done.data ├── cmu_us_ahw_arctic │ ├── wav │ │ ├──arctic_a0001.wav │ │ ├──arctic_a0002.wav │ │ ├──... │ └── etc │ └── txt.done.data └──...Citation:
@article{LTI2003CMUArctic, title = {CMU ARCTIC databases for speech synthesis}, author = {John Kominek and Alan W Black}, journal = {Language Technologies Institute [Online]}, year = {2003} howpublished = {http://www.festvox.org/cmu_arctic/} }
- class mindspore.dataset.CSVDataset(dataset_files, field_delim=',', column_defaults=None, column_names=None, num_samples=None, num_parallel_workers=None, shuffle=Shuffle.GLOBAL, num_shards=None, shard_id=None, cache=None)[source]
A source dataset that reads and parses comma-separated values (CSV) files as dataset.
The columns of generated dataset depend on the source CSV files.
- Parameters:
dataset_files (Union[str, list[str]]) – String or list of files to be read or glob strings to search for a pattern of files. The list will be sorted in a lexicographical order.
field_delim (str, optional) – A string that indicates the char delimiter to separate fields. Default:
','.column_defaults (list, optional) – List of default data types for the CSV columns. Default:
None. Each item in the list is either a valid type (float, int, or string). If this is not provided, treats all columns as string type.column_names (list[str], optional) – List of column names of the dataset. Default:
None. If this is not provided, infers the column_names from the first row of CSV file.num_samples (int, optional) – The number of samples to be included in the dataset. Default:
None, will include all samples.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (Union[bool, Shuffle], optional) –
Perform reshuffling of the data every epoch. Default:
Shuffle.GLOBAL. Bool type and Shuffle enum are both supported to pass in. If shuffle isFalse, no shuffling will be performed. If shuffle isTrue, performs global shuffle. There are three levels of shuffling, desired shuffle enum defined bymindspore.dataset.Shuffle.Shuffle.GLOBAL: Shuffle both the files and samples, same as setting shuffle to True.Shuffle.FILES: Shuffle files only.
num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the maximum sample number of per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_files are not valid or do not exist.
ValueError – If field_delim is invalid.
ValueError – If num_parallel_workers exceeds the max thread numbers.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If shard_id is not in range of [0, num_shards ).
Examples
>>> import mindspore.dataset as ds >>> csv_dataset_dir = ["/path/to/csv_dataset_file"] # contains 1 or multiple csv files >>> dataset = ds.CSVDataset(dataset_files=csv_dataset_dir, column_names=['col1', 'col2', 'col3', 'col4'])
- class mindspore.dataset.Caltech101Dataset(dataset_dir, target_type=None, num_samples=None, num_parallel_workers=1, shuffle=None, decode=False, sampler=None, num_shards=None, shard_id=None)[source]
Caltech 101 dataset.
The columns of the generated dataset depend on the value of target_type .
When target_type is
'category', the columns are[image, category].When target_type is
'annotation', the columns are[image, annotation].When target_type is
'all', the columns are[image, category, annotation].
The tensor of column
imageis of the uint8 type. The tensor of columncategoryis of the uint32 type. The tensor of columnannotationis a 2-dimensional ndarray that stores the contour of the image and consists of a series of points.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset. This root directory contains two subdirectories, one is called 101_ObjectCategories, which stores images, and the other is called Annotations, which stores annotations.
target_type (str, optional) – Target of the image. If target_type is
'category', return the category representing the target class. If target_type is'annotation', return annotation. If target_type is'all', return category and annotation. Default:None, means'category'.num_samples (int, optional) – The number of images to be included in the dataset. Default:
None, all images.num_parallel_workers (int, optional) – Number of worker subprocesses to read the data. Default:
1.shuffle (bool, optional) – Whether to perform shuffle on the dataset. Default:
None, expected order behavior shown in the table below.decode (bool, optional) – Whether to decode the images after reading. Default:
False.sampler (Sampler, optional) – Object used to choose samples from the dataset. Default:
None, expected order behavior shown in the table below.num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the maximum sample number of per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.
- Raises:
RuntimeError – If dataset_dir does not contain data files.
RuntimeError – If sampler and shuffle are specified at the same time.
RuntimeError – If sampler and num_shards/shard_id are specified at the same time.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If shard_id is not in range of [0, num_shards ).
ValueError – If target_type is not
'category','annotation'or'all'.ValueError – If num_parallel_workers exceeds the max thread numbers.
- Tutorial Examples:
Note
The parameters num_samples , shuffle , num_shards , shard_id can be used to control the sampler used in the dataset, and their effects when combined with parameter sampler are as follows.
Examples
>>> import mindspore.dataset as ds >>> caltech101_dataset_directory = "/path/to/caltech101_dataset_directory" >>> >>> # 1) Read all samples (image files) in caltech101_dataset_directory with 8 threads >>> dataset = ds.Caltech101Dataset(dataset_dir=caltech101_dataset_directory, num_parallel_workers=8) >>> >>> # 2) Read all samples (image files) with the target_type "annotation" >>> dataset = ds.Caltech101Dataset(dataset_dir=caltech101_dataset_directory, target_type="annotation")
About Caltech101Dataset:
Pictures of objects belonging to 101 categories, about 40 to 800 images per category. Most categories have about 50 images. The size of each image is roughly 300 x 200 pixels. The official provides the contour data of each object in each picture, which is the annotation.
Here is the original Caltech101 dataset structure, and you can unzip the dataset files into the following directory structure, which are read by MindSpore API.
. └── caltech101_dataset_directory ├── 101_ObjectCategories │ ├── Faces │ │ ├── image_0001.jpg │ │ ├── image_0002.jpg │ │ ... │ ├── Faces_easy │ │ ├── image_0001.jpg │ │ ├── image_0002.jpg │ │ ... │ ├── ... └── Annotations ├── Airplanes_Side_2 │ ├── annotation_0001.mat │ ├── annotation_0002.mat │ ... ├── Faces_2 │ ├── annotation_0001.mat │ ├── annotation_0002.mat │ ... ├── ...Citation:
@article{FeiFei2004LearningGV, author = {Li Fei-Fei and Rob Fergus and Pietro Perona}, title = {Learning Generative Visual Models from Few Training Examples: An Incremental Bayesian Approach Tested on 101 Object Categories}, journal = {Computer Vision and Pattern Recognition Workshop}, year = {2004}, url = {https://data.caltech.edu/records/mzrjq-6wc02}, }
- class mindspore.dataset.Caltech256Dataset(dataset_dir, num_samples=None, num_parallel_workers=None, shuffle=None, decode=False, sampler=None, num_shards=None, shard_id=None, cache=None)[source]
Caltech 256 dataset.
The generated dataset has two columns:
[image, label]. The tensor of columnimageis of the uint8 type. The tensor of columnlabelis of the uint32 type.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
num_samples (int, optional) – The number of images to be included in the dataset. Default:
None, all images.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers (8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (bool, optional) – Whether to perform shuffle on the dataset. Default:
None, expected order behavior shown in the table below.decode (bool, optional) – Whether to decode the images after reading. Default:
False.sampler (Sampler, optional) – Object used to choose samples from the dataset. Default:
None, expected order behavior shown in the table below.num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the maximum sample number of per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir does not contain data files.
RuntimeError – If sampler and shuffle are specified at the same time.
RuntimeError – If sampler and num_shards/shard_id are specified at the same time.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If shard_id is not in range of [0, num_shards ).
ValueError – If num_parallel_workers exceeds the max thread numbers.
- Tutorial Examples:
Note
The parameters num_samples , shuffle , num_shards , shard_id can be used to control the sampler used in the dataset, and their effects when combined with parameter sampler are as follows.
Examples
>>> import mindspore.dataset as ds >>> caltech256_dataset_dir = "/path/to/caltech256_dataset_directory" >>> >>> # 1) Read all samples (image files) in caltech256_dataset_dir with 8 threads >>> dataset = ds.Caltech256Dataset(dataset_dir=caltech256_dataset_dir, num_parallel_workers=8)
About Caltech256Dataset:
Caltech-256 is an object recognition dataset containing 30,607 real-world images of different sizes, spanning 257 classes (256 object classes and an additional clutter class). Each class is represented by at least 80 images. The dataset is a superset of the Caltech-101 dataset.
. └── caltech256_dataset_directory ├── 001.ak47 │ ├── 001_0001.jpg │ ├── 001_0002.jpg │ ... ├── 002.american-flag │ ├── 002_0001.jpg │ ├── 002_0002.jpg │ ... ├── 003.backpack │ ├── 003_0001.jpg │ ├── 003_0002.jpg │ ... ├── ...Citation:
@article{griffin2007caltech, title = {Caltech-256 object category dataset}, added-at = {2021-01-21T02:54:42.000+0100}, author = {Griffin, Gregory and Holub, Alex and Perona, Pietro}, biburl = {https://www.bibsonomy.org/bibtex/21f746f23ff0307826cca3e3be45f8de7/s364315}, interhash = {bfe1e648c1778c04baa60f23d1223375}, intrahash = {1f746f23ff0307826cca3e3be45f8de7}, publisher = {California Institute of Technology}, timestamp = {2021-01-21T02:54:42.000+0100}, year = {2007} }
- class mindspore.dataset.CelebADataset(dataset_dir, num_parallel_workers=None, shuffle=None, usage='all', sampler=None, decode=False, extensions=None, num_samples=None, num_shards=None, shard_id=None, cache=None, decrypt=None)[source]
CelebA(CelebFaces Attributes) dataset.
Only support to read list_attr_celeba.txt currently, which is the attribute annotations of the dataset. The generated dataset has two columns:
[image, attr]. The tensor of columnimageis of the uint8 type. The tensor of columnattris of the uint32 type and one hot encoded.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers (8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (bool, optional) – Whether to perform shuffle on the dataset. Default:
None.usage (str, optional) – Specify the
'train','valid','test'part or'all'parts of dataset. Default:'all', will read all samples.sampler (Sampler, optional) – Object used to choose samples from the dataset. Default:
None.decode (bool, optional) – Whether to decode the images after reading. Default:
False.extensions (list[str], optional) – List of file extensions to be included in the dataset. Default:
None.num_samples (int, optional) – The number of images to be included in the dataset. Default:
None, will include all images.num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the maximum sample number of per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.decrypt (callable, optional) – Image decryption function, which receives the path of the encrypted image file and returns the decrypted bytes data. Default:
None, no decryption.
- Raises:
RuntimeError – If dataset_dir does not contain data files.
RuntimeError – If sampler and shuffle are specified at the same time.
RuntimeError – If sampler and num_shards/shard_id are specified at the same time.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If shard_id is not in range of [0, num_shards ).
ValueError – If num_parallel_workers exceeds the max thread numbers.
ValueError – If usage is not
'train','valid','test'or'all'.
- Tutorial Examples:
Note
The parameters num_samples , shuffle , num_shards , shard_id can be used to control the sampler used in the dataset, and their effects when combined with parameter sampler are as follows.
Examples
>>> import mindspore.dataset as ds >>> celeba_dataset_dir = "/path/to/celeba_dataset_directory" >>> >>> # Read 5 samples from CelebA dataset >>> dataset = ds.CelebADataset(dataset_dir=celeba_dataset_dir, usage='train', num_samples=5) >>> >>> # Note: In celeba dataset, each data dictionary has keys "image" and "attr"
About CelebA dataset:
CelebFaces Attributes Dataset (CelebA) is a large-scale dataset with more than 200K celebrity images, each with 40 attribute annotations.
The images in this dataset cover large pose variations and background clutter. CelebA has large diversities, large quantities, and rich annotations, including
10,177 number of identities,
202,599 number of images,
5 landmark locations, 40 binary attributes annotations per image.
The dataset can be employed as the training and test sets for the following computer vision tasks: attribute recognition, detection, landmark (or facial part) and localization.
Original CelebA dataset structure:
. └── CelebA ├── README.md ├── Img │ ├── img_celeba.7z │ ├── img_align_celeba_png.7z │ └── img_align_celeba.zip ├── Eval │ └── list_eval_partition.txt └── Anno ├── list_landmarks_celeba.txt ├── list_landmarks_align_celeba.txt ├── list_bbox_celeba.txt ├── list_attr_celeba.txt └── identity_CelebA.txtYou can unzip the dataset files into the following structure and read by MindSpore's API.
. └── celeba_dataset_directory ├── list_attr_celeba.txt ├── 000001.jpg ├── 000002.jpg ├── 000003.jpg ├── ...Citation:
@article{DBLP:journals/corr/LiuLWT14, author = {Ziwei Liu and Ping Luo and Xiaogang Wang and Xiaoou Tang}, title = {Deep Learning Attributes in the Wild}, journal = {CoRR}, volume = {abs/1411.7766}, year = {2014}, url = {http://arxiv.org/abs/1411.7766}, archivePrefix = {arXiv}, eprint = {1411.7766}, timestamp = {Tue, 10 Dec 2019 15:37:26 +0100}, biburl = {https://dblp.org/rec/journals/corr/LiuLWT14.bib}, bibsource = {dblp computer science bibliography, https://dblp.org}, howpublished = {http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html} }
- class mindspore.dataset.Cifar100Dataset(dataset_dir, usage=None, num_samples=None, num_parallel_workers=None, shuffle=None, sampler=None, num_shards=None, shard_id=None, cache=None)[source]
CIFAR-100 dataset.
The generated dataset has three columns
[image, coarse_label, fine_label]. The tensor of columnimageis of the uint8 type. The tensor of columncoarse_labelandfine_labelare each a scalar of uint32 type.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
usage (str, optional) – Usage of this dataset, can be
'train','test'or'all'.'train'will read from 50,000 train samples,'test'will read from 10,000 test samples,'all'will read from all 60,000 samples. Default:None, all samples.num_samples (int, optional) – The number of images to be included in the dataset. Default:
None, all images.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers (8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (bool, optional) – Whether to perform shuffle on the dataset. Default:
None, expected order behavior shown in the table below.sampler (Sampler, optional) – Object used to choose samples from the dataset. Default:
None, expected order behavior shown in the table below.num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the maximum number of samples per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir does not contain data files.
RuntimeError – If sampler and shuffle are specified at the same time.
RuntimeError – If sampler and num_shards/shard_id are specified at the same time.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If shard_id is not in range of [0, num_shards ).
ValueError – If num_parallel_workers exceeds the max thread numbers.
ValueError – If usage is not
'train','test'or'all'.
- Tutorial Examples:
Note
The parameters num_samples , shuffle , num_shards , shard_id can be used to control the sampler used in the dataset, and their effects when combined with parameter sampler are as follows.
Examples
>>> import mindspore.dataset as ds >>> cifar100_dataset_dir = "/path/to/cifar100_dataset_directory" >>> >>> # 1) Get all samples from CIFAR100 dataset in sequence >>> dataset = ds.Cifar100Dataset(dataset_dir=cifar100_dataset_dir, shuffle=False) >>> >>> # 2) Randomly select 350 samples from CIFAR100 dataset >>> dataset = ds.Cifar100Dataset(dataset_dir=cifar100_dataset_dir, num_samples=350, shuffle=True) >>> >>> # In CIFAR100 dataset, each dictionary has 3 keys: "image", "fine_label" and "coarse_label"
About CIFAR-100 dataset:
This dataset is just like the CIFAR-10, except it has 100 classes containing 600 images each. There are 500 training images and 100 testing images per class. The 100 classes in the CIFAR-100 are grouped into 20 superclasses. Each image comes with a "fine" label (the class to which it belongs) and a "coarse" label (the superclass to which it belongs).
Here is the original CIFAR-100 dataset structure. You can unzip the dataset files into the following directory structure and read by MindSpore's API.
. └── cifar-100-binary ├── train.bin ├── test.bin ├── fine_label_names.txt └── coarse_label_names.txtCitation:
@techreport{Krizhevsky09, author = {Alex Krizhevsky}, title = {Learning multiple layers of features from tiny images}, institution = {}, year = {2009}, howpublished = {http://www.cs.toronto.edu/~kriz/cifar.html} }
- class mindspore.dataset.Cifar10Dataset(dataset_dir, usage=None, num_samples=None, num_parallel_workers=None, shuffle=None, sampler=None, num_shards=None, shard_id=None, cache=None)[source]
CIFAR-10 dataset.
This api only supports parsing CIFAR-10 file in binary version now. The generated dataset has two columns
[image, label]. The tensor of columnimageis of the uint8 type. The tensor of columnlabelis a scalar of the uint32 type.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
usage (str, optional) – Usage of this dataset, can be
'train','test'or'all'.'train'will read from 50,000 train samples,'test'will read from 10,000 test samples,'all'will read from all 60,000 samples. Default:None, all samples.num_samples (int, optional) – The number of images to be included in the dataset. Default:
None, all images.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (bool, optional) – Whether to perform shuffle on the dataset. Default:
None, expected order behavior shown in the table below.sampler (Sampler, optional) – Object used to choose samples from the dataset. Default:
None, expected order behavior shown in the table below.num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the maximum sample number of per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir does not contain data files.
RuntimeError – If sampler and shuffle are specified at the same time.
RuntimeError – If sampler and num_shards/shard_id are specified at the same time.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If shard_id is not in range of [0, num_shards ).
ValueError – If num_parallel_workers exceeds the max thread numbers.
ValueError – If usage is not
'train','test'or'all'.
- Tutorial Examples:
Note
The parameters num_samples , shuffle , num_shards , shard_id can be used to control the sampler used in the dataset, and their effects when combined with parameter sampler are as follows.
Examples
>>> import mindspore.dataset as ds >>> cifar10_dataset_dir = "/path/to/cifar10_dataset_directory" >>> >>> # 1) Get all samples from CIFAR10 dataset in sequence >>> dataset = ds.Cifar10Dataset(dataset_dir=cifar10_dataset_dir, shuffle=False) >>> >>> # 2) Randomly select 350 samples from CIFAR10 dataset >>> dataset = ds.Cifar10Dataset(dataset_dir=cifar10_dataset_dir, num_samples=350, shuffle=True) >>> >>> # 3) Get samples from CIFAR10 dataset for shard 0 in a 2-way distributed training >>> dataset = ds.Cifar10Dataset(dataset_dir=cifar10_dataset_dir, num_shards=2, shard_id=0) >>> >>> # In CIFAR10 dataset, each dictionary has keys "image" and "label"
About CIFAR-10 dataset:
The CIFAR-10 dataset consists of 60000 32x32 color images in 10 classes, with 6000 images per class. There are 50000 training images and 10000 test images. The 10 different classes represent airplanes, cars, birds, cats, deer, dogs, frogs, horses, ships, and trucks.
Here is the original CIFAR-10 dataset structure. You can unzip the dataset files into the following directory structure and read by MindSpore's API.
. └── cifar-10-batches-bin ├── data_batch_1.bin ├── data_batch_2.bin ├── data_batch_3.bin ├── data_batch_4.bin ├── data_batch_5.bin ├── test_batch.bin ├── readme.html └── batches.meta.txtCitation:
@techreport{Krizhevsky09, author = {Alex Krizhevsky}, title = {Learning multiple layers of features from tiny images}, institution = {}, year = {2009}, howpublished = {http://www.cs.toronto.edu/~kriz/cifar.html} }
- class mindspore.dataset.CityscapesDataset(dataset_dir, usage='train', quality_mode='fine', task='instance', num_samples=None, num_parallel_workers=None, shuffle=None, decode=None, sampler=None, num_shards=None, shard_id=None, cache=None)[source]
Cityscapes dataset.
The generated dataset has two columns
[image, task]. The tensor of columnimageis of the uint8 type. The tensor of columntaskis of the uint8 type if task is not'polygon', otherwise it is a string tensor with serialized json.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
usage (str, optional) – Acceptable usages include
'train','test','val'or'all'if quality_mode is'fine'otherwise'train','train_extra','val'or'all'. Default:'train', the training samples will be read.quality_mode (str, optional) – Acceptable quality_modes include
'fine'or'coarse'. Default:'fine'.task (str, optional) – Acceptable tasks include
'instance','semantic','polygon'or'color'. Default:'instance'.num_samples (int, optional) – The number of images to be included in the dataset. Default:
None, all images.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (bool, optional) – Whether to perform shuffle on the dataset. Default:
None, expected order behavior shown in the table below.decode (bool, optional) – Decode the images after reading. Default:
None, which meansFalse, the images are not decoded after reading.sampler (Sampler, optional) – Object used to choose samples from the dataset. Default:
None, expected order behavior shown in the table below.num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the max sample number of per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir is invalid or does not contain data files.
RuntimeError – If sampler and shuffle are specified at the same time.
RuntimeError – If sampler and num_shards/shard_id are specified at the same time.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If num_parallel_workers exceeds the max thread numbers.
ValueError – If dataset_dir does not exist.
ValueError – If task is not
'instance','semantic','polygon'or'color'.ValueError – If quality_mode is not
'fine'or'coarse'.ValueError – If usage is invalid.
ValueError – If shard_id is not in range of [0, num_shards ).
- Tutorial Examples:
Note
The parameters num_samples , shuffle , num_shards , shard_id can be used to control the sampler used in the dataset, and their effects when combined with parameter sampler are as follows.
Examples
>>> import mindspore.dataset as ds >>> cityscapes_dataset_dir = "/path/to/cityscapes_dataset_directory" >>> >>> # 1) Get all samples from Cityscapes dataset in sequence >>> dataset = ds.CityscapesDataset(dataset_dir=cityscapes_dataset_dir, task="instance", quality_mode="fine", ... usage="train", shuffle=False, num_parallel_workers=1) >>> >>> # 2) Randomly select 350 samples from Cityscapes dataset >>> dataset = ds.CityscapesDataset(dataset_dir=cityscapes_dataset_dir, num_samples=350, shuffle=True, ... num_parallel_workers=1) >>> >>> # 3) Get samples from Cityscapes dataset for shard 0 in a 2-way distributed training >>> dataset = ds.CityscapesDataset(dataset_dir=cityscapes_dataset_dir, num_shards=2, shard_id=0, ... num_parallel_workers=1) >>> >>> # In Cityscapes dataset, each dictionary has keys "image" and "task"
About Cityscapes dataset:
The Cityscapes dataset consists of 5000 color images with high quality dense pixel annotations and 19998 color images with coarser polygonal annotations in 50 cities. There are 30 classes in this dataset and the polygonal annotations include dense semantic segmentation and instance segmentation for vehicle and people.
You can unzip the dataset files into the following directory structure and read by MindSpore's API.
Taking the quality_mode of fine as an example.
. └── Cityscapes ├── leftImg8bit | ├── train | | ├── aachen | | | ├── aachen_000000_000019_leftImg8bit.png | | | ├── aachen_000001_000019_leftImg8bit.png | | | ├── ... | | ├── bochum | | | ├── ... | | ├── ... | ├── test | | ├── ... | ├── val | | ├── ... └── gtFine ├── train | ├── aachen | | ├── aachen_000000_000019_gtFine_color.png | | ├── aachen_000000_000019_gtFine_instanceIds.png | | ├── aachen_000000_000019_gtFine_labelIds.png | | ├── aachen_000000_000019_gtFine_polygons.json | | ├── aachen_000001_000019_gtFine_color.png | | ├── aachen_000001_000019_gtFine_instanceIds.png | | ├── aachen_000001_000019_gtFine_labelIds.png | | ├── aachen_000001_000019_gtFine_polygons.json | | ├── ... | ├── bochum | | ├── ... | ├── ... ├── test | ├── ... └── val ├── ...Citation:
@inproceedings{Cordts2016Cityscapes, title = {The Cityscapes Dataset for Semantic Urban Scene Understanding}, author = {Cordts, Marius and Omran, Mohamed and Ramos, Sebastian and Rehfeld, Timo and Enzweiler, Markus and Benenson, Rodrigo and Franke, Uwe and Roth, Stefan and Schiele, Bernt}, booktitle = {Proc. of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2016} }
- class mindspore.dataset.CoNLL2000Dataset(dataset_dir, usage=None, num_samples=None, shuffle=Shuffle.GLOBAL, num_shards=None, shard_id=None, num_parallel_workers=None, cache=None)[source]
CoNLL-2000 (Conference on Computational Natural Language Learning) chunking dataset.
The generated dataset has three columns:
[word, pos_tag, chunk_tag]. The tensors of columnword, columnpos_tag, and columnchunk_tagare of the string type.- Parameters:
dataset_dir (str) – Path to the root directory that contains the CoNLL2000 chunking dataset.
usage (str, optional) – Usage of dataset, can be
'train','test', or'all'. For dataset,'train'will read from 8,936 train samples,'test'will read from 2,012 test samples,'all'will read from all 10,948 samples. Default:None, read all samples.num_samples (int, optional) – Number of samples (rows) to be read. Default:
None, read the full dataset.shuffle (Union[bool, Shuffle], optional) –
Perform reshuffling of the data every epoch. Default:
Shuffle.GLOBAL. If shuffle isFalse, no shuffling will be performed. If shuffle isTrue, performs global shuffle. There are three levels of shuffling, desired shuffle enum defined bymindspore.dataset.Shuffle.Shuffle.GLOBAL: Shuffle both the files and samples, same as setting shuffle toTrue.Shuffle.FILES: Shuffle files only.
num_shards (int, optional) –
Number of shards that the dataset will be divided into. When this argument is specified, num_samples reflects the max sample number of per shard. Default:
None. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . This argument can only be specified when num_shards is also specified. Default:
None.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir does not contain data files.
ValueError – If num_parallel_workers exceeds the max thread numbers.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
- Tutorial Examples:
Examples
>>> import mindspore.dataset as ds >>> conll2000_dataset_dir = "/path/to/conll2000_dataset_dir" >>> dataset = ds.CoNLL2000Dataset(dataset_dir=conll2000_dataset_dir, usage='all')
About CoNLL2000 Dataset:
The CoNLL2000 chunking dataset consists of the text from sections 15-20 of the Wall Street Journal corpus. Texts are chunked using IOB notation, and the chunk type has NP, VP, PP, ADJP and ADVP. The dataset consists of three columns separated by spaces. The first column contains the current word, the second is part-of-speech tag as derived by the Brill tagger and the third is chunk tag as derived from the WSJ corpus. Text chunking consists of dividing a text in syntactically correlated parts of words.
You can unzip the dataset files into the following structure and read by MindSpore's API:
. └── conll2000_dataset_dir ├── train.txt ├── test.txt └── readme.txtCitation:
@inproceedings{tksbuchholz2000conll, author = {Tjong Kim Sang, Erik F. and Sabine Buchholz}, title = {Introduction to the CoNLL-2000 Shared Task: Chunking}, editor = {Claire Cardie and Walter Daelemans and Claire Nedellec and Tjong Kim Sang, Erik}, booktitle = {Proceedings of CoNLL-2000 and LLL-2000}, publisher = {Lisbon, Portugal}, pages = {127--132}, year = {2000} }
- class mindspore.dataset.CocoDataset(dataset_dir, annotation_file, task='Detection', num_samples=None, num_parallel_workers=None, shuffle=None, decode=False, sampler=None, num_shards=None, shard_id=None, cache=None, extra_metadata=False, decrypt=None)[source]
COCO(Common Objects in Context) dataset.
CocoDataset supports five kinds of tasks, which are Object Detection, Keypoint Detection, Stuff Segmentation, Panoptic Segmentation and Captioning of 2017 Train/Val/Test dataset.
- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
annotation_file (str) – Path to the annotation JSON file.
task (str, optional) – Set the task type for reading COCO data. Supported task types:
'Detection','Stuff','Panoptic','Keypoint'and'Captioning'. Default:'Detection'.num_samples (int, optional) – The number of images to be included in the dataset. Default:
None, all images.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (bool, optional) – Whether to perform shuffle on the dataset. Default:
None, expected order behavior shown in the table below.decode (bool, optional) – Decode the images after reading. Default:
False.sampler (Sampler, optional) – Object used to choose samples from the dataset. Default:
None, expected order behavior shown in the table below.num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the maximum number of samples per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.extra_metadata (bool, optional) – Flag to add extra meta-data to row. If True, an additional column will be output at the end
[_meta-filename, dtype=string]. Default:False.decrypt (callable, optional) – Image decryption function, which accepts the path of the encrypted image file and returns the decrypted bytes data. Default:
None, no decryption.
The generated dataset with different task setting has different output columns:
task
Output column
Detection
[image, dtype=uint8]
[bbox, dtype=float32]
[category_id, dtype=uint32]
[iscrowd, dtype=uint32]
Stuff
[image, dtype=uint8]
[segmentation, dtype=float32]
[iscrowd, dtype=uint32]
Keypoint
[image, dtype=uint8]
[keypoints, dtype=float32]
[num_keypoints, dtype=uint32]
Panoptic
[image, dtype=uint8]
[bbox, dtype=float32]
[category_id, dtype=uint32]
[iscrowd, dtype=uint32]
[area, dtype=uint32]
Captioning
[image, dtype=uint8]
[captions, dtype=string]
- Raises:
RuntimeError – If dataset_dir does not contain data files.
RuntimeError – If sampler and shuffle are specified at the same time.
RuntimeError – If sampler and num_shards/shard_id are specified at the same time.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
RuntimeError – If parsing the JSON file failed.
ValueError – If num_parallel_workers exceeds the max thread numbers.
ValueError – If task is not
'Detection','Stuff','Panoptic','Keypoint'or'Captioning'.ValueError – If annotation_file does not exist.
ValueError – If dataset_dir does not exist.
ValueError – If shard_id is not in range of [0, num_shards ).
- Tutorial Examples:
Note
When the parameter extra_metadata is set to
True, use the rename operation to remove the prefix _meta- from the additional data column _meta-filename. Otherwise, this additional data column will not appear in the rows returned by the iteration.Not support
mindspore.dataset.PKSamplerfor sampler parameter yet.The parameters num_samples , shuffle , num_shards , shard_id can be used to control the sampler used in the dataset, and their effects when combined with parameter sampler are as follows.
Examples
>>> import mindspore.dataset as ds >>> coco_dataset_dir = "/path/to/coco_dataset_directory/images" >>> coco_annotation_file = "/path/to/coco_dataset_directory/annotation_file" >>> >>> # 1) Read COCO data for Detection task >>> dataset = ds.CocoDataset(dataset_dir=coco_dataset_dir, ... annotation_file=coco_annotation_file, ... task='Detection') >>> >>> # 2) Read COCO data for Stuff task >>> dataset = ds.CocoDataset(dataset_dir=coco_dataset_dir, ... annotation_file=coco_annotation_file, ... task='Stuff') >>> >>> # 3) Read COCO data for Panoptic task >>> dataset = ds.CocoDataset(dataset_dir=coco_dataset_dir, ... annotation_file=coco_annotation_file, ... task='Panoptic') >>> >>> # 4) Read COCO data for Keypoint task >>> dataset = ds.CocoDataset(dataset_dir=coco_dataset_dir, ... annotation_file=coco_annotation_file, ... task='Keypoint') >>> >>> # 5) Read COCO data for Captioning task >>> dataset = ds.CocoDataset(dataset_dir=coco_dataset_dir, ... annotation_file=coco_annotation_file, ... task='Captioning') >>> >>> # In COCO dataset, each dictionary has keys "image" and "annotation"
About COCO dataset:
COCO(Microsoft Common Objects in Context) is a large-scale object detection, segmentation, and captioning dataset with several features: Object segmentation, Recognition in context, Superpixel stuff segmentation, 330K images (>200K labeled), 1.5 million object instances, 80 object categories, 91 stuff categories, 5 captions per image, 250,000 people with keypoints. In contrast to the popular ImageNet dataset, COCO has fewer categories but more instances per category.
You can unzip the original COCO-2017 dataset files into this directory structure and read by MindSpore's API.
. └── coco_dataset_directory ├── train2017 │ ├── 000000000009.jpg │ ├── 000000000025.jpg │ ├── ... ├── test2017 │ ├── 000000000001.jpg │ ├── 000000058136.jpg │ ├── ... ├── val2017 │ ├── 000000000139.jpg │ ├── 000000057027.jpg │ ├── ... └── annotations ├── captions_train2017.json ├── captions_val2017.json ├── instances_train2017.json ├── instances_val2017.json ├── person_keypoints_train2017.json └── person_keypoints_val2017.jsonCitation:
@article{DBLP:journals/corr/LinMBHPRDZ14, author = {Tsung{-}Yi Lin and Michael Maire and Serge J. Belongie and Lubomir D. Bourdev and Ross B. Girshick and James Hays and Pietro Perona and Deva Ramanan and Piotr Doll{'{a}}r and C. Lawrence Zitnick}, title = {Microsoft {COCO:} Common Objects in Context}, journal = {CoRR}, volume = {abs/1405.0312}, year = {2014}, url = {http://arxiv.org/abs/1405.0312}, archivePrefix = {arXiv}, eprint = {1405.0312}, timestamp = {Mon, 13 Aug 2018 16:48:13 +0200}, biburl = {https://dblp.org/rec/journals/corr/LinMBHPRDZ14.bib}, bibsource = {dblp computer science bibliography, https://dblp.org} }
- get_class_indexing()[source]
Get the mapping dictionary from category names to category indexes.
This dictionary can be used to look up which category name corresponds to a particular category index.
- Returns:
Dict[str, List[int]], the mappings from category names to category index list. The first element of the list is always the category ID. Only in Panoptic tasks, the second element of the list indicates whether the category is a thing or a stuff.
Examples
>>> import mindspore.dataset as ds >>> coco_dataset_dir = "/path/to/coco_dataset_directory/images" >>> coco_annotation_file = "/path/to/coco_dataset_directory/annotation_file" >>> >>> # Read COCO data for Detection task >>> dataset = ds.CocoDataset(dataset_dir=coco_dataset_dir, ... annotation_file=coco_annotation_file, ... task='Detection') >>> >>> class_indexing = dataset.get_class_indexing()
- class mindspore.dataset.DBpediaDataset(dataset_dir, usage=None, num_samples=None, num_parallel_workers=None, shuffle=Shuffle.GLOBAL, num_shards=None, shard_id=None, cache=None)[source]
DBpedia dataset.
The generated dataset has three columns
[class, title, content], and the data type of three columns is string.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
usage (str, optional) – Usage of this dataset, can be
'train','test'or'all'.'train'will read from 560,000 train samples,'test'will read from 70,000 test samples,'all'will read from all 630,000 samples. Default:None, all samples.num_samples (int, optional) – The number of samples to be included in the dataset. Default:
None, will include all text.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (Union[bool, Shuffle], optional) –
Perform reshuffling of the data every epoch. Bool type and Shuffle enum are both supported to pass in. Default:
Shuffle.GLOBAL. If shuffle isFalse, no shuffling will be performed. If shuffle isTrue, it is equivalent to setting shuffle toShuffle.GLOBAL. Set the mode of data shuffling by passing in enumeration variables:Shuffle.GLOBAL: Shuffle both the files and samples.Shuffle.FILES: Shuffle files only.
num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the maximum sample number of per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir does not contain data files.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If num_parallel_workers exceeds the max thread numbers.
ValueError – If shard_id is not in range of [0, num_shards ).
- Tutorial Examples:
Examples
>>> import mindspore.dataset as ds >>> dbpedia_dataset_dir = "/path/to/dbpedia_dataset_directory" >>> >>> # 1) Read 3 samples from DBpedia dataset >>> dataset = ds.DBpediaDataset(dataset_dir=dbpedia_dataset_dir, num_samples=3) >>> >>> # 2) Read train samples from DBpedia dataset >>> dataset = ds.DBpediaDataset(dataset_dir=dbpedia_dataset_dir, usage="train")
About DBpedia dataset:
The DBpedia dataset consists of 630,000 text samples in 14 classes, there are 560,000 samples in the train.csv and 70,000 samples in the test.csv. The 14 different classes represent Company, EducationalInstitution, Artist, Athlete, OfficeHolder, MeanOfTransportation, Building, NaturalPlace, Village, Animal, Plant, Album, Film, WrittenWork.
Here is the original DBpedia dataset structure. You can unzip the dataset files into this directory structure and read by MindSpore's API.
. └── dbpedia_dataset_dir ├── train.csv ├── test.csv ├── classes.txt └── readme.txtCitation:
@article{DBpedia, title = {DBPedia Ontology Classification Dataset}, author = {Jens Lehmann, Robert Isele, Max Jakob, Anja Jentzsch, Dimitris Kontokostas, Pablo N. Mendes, Sebastian Hellmann, Mohamed Morsey, Patrick van Kleef, Sören Auer, Christian Bizer}, year = {2015}, howpublished = {http://dbpedia.org} }
- class mindspore.dataset.DIV2KDataset(dataset_dir, usage='train', downgrade='bicubic', scale=2, num_samples=None, num_parallel_workers=None, shuffle=None, decode=None, sampler=None, num_shards=None, shard_id=None, cache=None)[source]
DIV2K(DIVerse 2K resolution image) dataset.
The generated dataset has two columns
[hr_image, lr_image]. The tensor of columnhr_imageand the tensor of columnlr_imageare of the uint8 type.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
usage (str, optional) – Acceptable usages include
'train','valid'or'all'. Default:'train'.downgrade (str, optional) – Acceptable downgrades include
'bicubic','unknown','mild','difficult'or'wild'. Default:'bicubic'.scale (int, optional) – Acceptable scales include
2,3,4or8. Default:2. When downgrade is'bicubic', scale can be2,3,4,8. When downgrade is'unknown', scale can only be2,3,4. When downgrade is'mild','difficult'or'wild', scale can only be4.num_samples (int, optional) – The number of images to be included in the dataset. Default:
None, all images.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (bool, optional) – Whether to perform shuffle on the dataset. Default:
None, expected order behavior shown in the table below.decode (bool, optional) – Decode the images after reading. Default:
None, set toFalse.sampler (Sampler, optional) – Object used to choose samples from the dataset. Default:
None, expected order behavior shown in the table below.num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the maximum number of samples per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir is invalid or does not contain data files.
RuntimeError – If sampler and shuffle are specified at the same time.
RuntimeError – If sampler and num_shards/shard_id are specified at the same time.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If dataset_dir does not exist.
ValueError – If usage is invalid.
ValueError – If downgrade is invalid.
ValueError – If scale is invalid, or does not match the value of the downgrade parameter.
ValueError – If scale equals
8and downgrade does not equal'bicubic'.ValueError – If downgrade is
'mild','difficult'or'wild', and scale does not equal4.ValueError – If num_parallel_workers exceeds the max thread numbers.
ValueError – If shard_id is not in range of [0, num_shards ).
- Tutorial Examples:
Note
The parameters num_samples , shuffle , num_shards , shard_id can be used to control the sampler used in the dataset, and their effects when combined with parameter sampler are as follows.
Examples
>>> import mindspore.dataset as ds >>> div2k_dataset_dir = "/path/to/div2k_dataset_directory" >>> >>> # 1) Get all samples from DIV2K dataset in sequence >>> dataset = ds.DIV2KDataset(dataset_dir=div2k_dataset_dir, usage="train", scale=2, downgrade="bicubic", ... shuffle=False) >>> >>> # 2) Randomly select 350 samples from DIV2K dataset >>> dataset = ds.DIV2KDataset(dataset_dir=div2k_dataset_dir, usage="train", scale=2, downgrade="bicubic", ... num_samples=350, shuffle=True) >>> >>> # 3) Get samples from DIV2K dataset for shard 0 in a 2-way distributed training >>> dataset = ds.DIV2KDataset(dataset_dir=div2k_dataset_dir, usage="train", scale=2, downgrade="bicubic", ... num_shards=2, shard_id=0) >>> >>> # In DIV2K dataset, each dictionary has keys "hr_image" and "lr_image"
About DIV2K dataset:
The DIV2K dataset consists of 1000 2K resolution images, among which 800 images are for training, 100 images are for validation and 100 images are for testing. NTIRE 2017 and NTIRE 2018 include only training dataset and validation dataset.
You can unzip the dataset files into the following directory structure and read by MindSpore's API.
Take the training set as an example.
. └── DIV2K ├── DIV2K_train_HR | ├── 0001.png | ├── 0002.png | ├── ... ├── DIV2K_train_LR_bicubic | ├── X2 | | ├── 0001x2.png | | ├── 0002x2.png | | ├── ... | ├── X3 | | ├── 0001x3.png | | ├── 0002x3.png | | ├── ... | └── X4 | ├── 0001x4.png | ├── 0002x4.png | ├── ... ├── DIV2K_train_LR_unknown | ├── X2 | | ├── 0001x2.png | | ├── 0002x2.png | | ├── ... | ├── X3 | | ├── 0001x3.png | | ├── 0002x3.png | | ├── ... | └── X4 | ├── 0001x4.png | ├── 0002x4.png | ├── ... ├── DIV2K_train_LR_mild | ├── 0001x4m.png | ├── 0002x4m.png | ├── ... ├── DIV2K_train_LR_difficult | ├── 0001x4d.png | ├── 0002x4d.png | ├── ... ├── DIV2K_train_LR_wild | ├── 0001x4w.png | ├── 0002x4w.png | ├── ... └── DIV2K_train_LR_x8 ├── 0001x8.png ├── 0002x8.png ├── ...Citation:
@InProceedings{Agustsson_2017_CVPR_Workshops, author = {Agustsson, Eirikur and Timofte, Radu}, title = {NTIRE 2017 Challenge on Single Image Super-Resolution: Dataset and Study}, booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops}, url = "http://www.vision.ee.ethz.ch/~timofter/publications/Agustsson-CVPRW-2017.pdf", month = {July}, year = {2017} }
- class mindspore.dataset.DSCallback(step_size=1)[source]
Abstract base class used to build dataset callback classes.
Users can obtain the dataset pipeline context through ds_run_context , including cur_epoch_num , cur_step_num_in_epoch and cur_step_num .
- Parameters:
step_size (int, optional) – The number of steps between adjacent ds_step_begin/ds_step_end calls. Default:
1, will be called at each step.
Examples
>>> import mindspore.dataset as ds >>> from mindspore.dataset import DSCallback >>> >>> class PrintInfo(DSCallback): ... def ds_begin(self, ds_run_context): ... print("callback: start dataset pipeline", flush=True) ... ... def ds_epoch_begin(self, ds_run_context): ... print("callback: epoch begin, we are in epoch", ds_run_context.cur_epoch_num, flush=True) ... ... def ds_epoch_end(self, ds_run_context): ... print("callback: epoch end, we are in epoch", ds_run_context.cur_epoch_num, flush=True) ... ... def ds_step_begin(self, ds_run_context): ... print("callback: step begin, step", ds_run_context.cur_step_num_in_epoch, flush=True) ... ... def ds_step_end(self, ds_run_context): ... print("callback: step end, step", ds_run_context.cur_step_num_in_epoch, flush=True) >>> >>> dataset = ds.GeneratorDataset([1, 2], "col1", shuffle=False, num_parallel_workers=1) >>> dataset = dataset.map(operations=lambda x: x, callbacks=PrintInfo()) >>> >>> # Start dataset pipeline >>> iterator = dataset.create_tuple_iterator(num_epochs=2) >>> for i in range(2): ... for d in iterator: ... pass callback: start dataset pipeline callback: epoch begin, we are in epoch 1 callback: step begin, step 1 callback: step begin, step 2 callback: step end, step 1 callback: step end, step 2 callback: epoch end, we are in epoch 1 callback: epoch begin, we are in epoch 2 callback: step begin, step 1 callback: step begin, step 2 callback: step end, step 1 callback: step end, step 2 callback: epoch end, we are in epoch 2
- create_runtime_obj()[source]
Internal method, creates a runtime (C++) object from the callback methods defined by the user.
- Returns:
_c_dataengine.PyDSCallback.
- ds_begin(ds_run_context)[source]
Called before the data pipeline is started.
- Parameters:
ds_run_context (RunContext) – Include some information of the data pipeline.
- ds_epoch_begin(ds_run_context)[source]
Called before a new epoch is started.
- Parameters:
ds_run_context (RunContext) – Include some information of the data pipeline.
- ds_epoch_end(ds_run_context)[source]
Called after an epoch is finished.
- Parameters:
ds_run_context (RunContext) – Include some information of the data pipeline.
- ds_step_begin(ds_run_context)[source]
Called before a step starts.
- Parameters:
ds_run_context (RunContext) – Include some information of the data pipeline.
- ds_step_end(ds_run_context)[source]
Called after a step finishes.
- Parameters:
ds_run_context (RunContext) – Include some information of the data pipeline.
- class mindspore.dataset.DatasetCache(session_id, size=0, spilling=False, hostname=None, port=None, num_connections=None, prefetch_size=None)[source]
A client to interface with tensor caching service.
For details, please check Tutorial .
- Parameters:
session_id (int) – A user assigned session id for the current pipeline.
size (int, optional) – Size of the memory set aside for the row caching. Default:
0, which means unlimited, note that it might bring in the risk of running out of memory on the machine.spilling (bool, optional) – Whether or not spilling to disk if out of memory. Default:
False.hostname (str, optional) – Host name. Default:
None, use default hostname '127.0.0.1'.port (int, optional) – Port to connect to server. Default:
None, use default port 50052.num_connections (int, optional) – Number of tcp/ip connections. Default:
None, use default value 12.prefetch_size (int, optional) – The size of the cache queue between operations. Default:
None, use default value 20.
Examples
>>> import subprocess >>> import mindspore.dataset as ds >>> >>> # Create a cache instance with command line `dataset-cache --start` >>> # Create a session with `dataset-cache -g` >>> # After creating cache with a valid session, get session id with command `dataset-cache --list_sessions` >>> command = "dataset-cache --list_sessions | tail -1 | awk -F ' ' '{{print $1;}}'" >>> session_id = subprocess.getoutput(command).split('\n')[-1] >>> some_cache = ds.DatasetCache(session_id=int(session_id), size=0) >>> >>> dataset_dir = "/path/to/image_folder_dataset_directory" >>> dataset = ds.ImageFolderDataset(dataset_dir, cache=some_cache)
- get_stat()[source]
Get the statistics from a cache. After the data pipeline, three types of statistics can be obtained, including average number of cache hits (avg_cache_sz), number of caches in memory (num_mem_cached) and number of caches in disk (num_disk_cached).
Examples
>>> import os >>> import subprocess >>> import mindspore.dataset as ds >>> >>> # In example above, we created cache with a valid session id >>> command = "dataset-cache --list_sessions | tail -1 | awk -F ' ' '{{print $1;}}'" >>> id = subprocess.getoutput(command).split('\n')[-1] >>> some_cache = ds.DatasetCache(session_id=int(id), size=0) >>> >>> # run the dataset pipeline to trigger cache >>> dataset = ds.ImageFolderDataset("/path/to/image_folder_dataset_directory", cache=some_cache) >>> data = list(dataset) >>> >>> # get status of cache >>> stat = some_cache.get_stat() >>> # Average cache size >>> cache_sz = stat.avg_cache_sz >>> # Number of rows cached in memory >>> num_mem_cached = stat.num_mem_cached >>> # Number of rows spilled to disk >>> num_disk_cached = stat.num_disk_cached
- class mindspore.dataset.DistributedSampler(num_shards, shard_id, shuffle=True, num_samples=None, offset=-1)[source]
A sampler that accesses a shard of the dataset, it helps divide dataset into multi-subset for distributed training.
Note
The shuffling modes supported for different datasets are as follows:
List of support for shuffling mode Shuffling Mode
MindDataset
TFRecordDataset
Others
Shuffle.ADAPTIVESupported
Not Supported
Not Supported
Shuffle.GLOBALSupported
Supported
Supported
Shuffle.PARTIALSupported
Not Supported
Not Supported
Shuffle.FILESSupported
Supported
Not Supported
Shuffle.INFILESupported
Not Supported
Not Supported
- Parameters:
num_shards (int) – Number of shards to divide the dataset into.
shard_id (int) – Shard ID of the current shard, which should be within the range of [0, num_shards - 1].
shuffle (Union[bool, Shuffle], optional) –
Specify the shuffle mode. Default:
True, performsmindspore.dataset.Shuffle.GLOBAL. If shuffle isFalse, no shuffling will be performed. There are several levels of shuffling, desired shuffle enum is defined bymindspore.dataset.Shuffle.Shuffle.ADAPTIVE: When the number of dataset samples is less than or equal to 100 million,Shuffle.GLOBALis used. When the number of dataset samples is greater than 100 million,Shuffle.PARTIALis used. The shuffle is performed once every 1 million samples.Shuffle.GLOBAL: Global shuffle of all rows of data in dataset. The memory usage is large.Shuffle.PARTIAL: Partial shuffle of data in dataset for every 1 million samples. The memory usage is less thanShuffle.GLOBAL.Shuffle.FILES: Shuffle the file sequence but keep the order of data within each file.Shuffle.INFILE: Keep the file sequence the same but shuffle the data within each file.
num_samples (int, optional) – The number of samples to draw. Default:
None, which means sample all elements.offset (int, optional) – The starting shard ID where the elements in the dataset are sent to, which should be no more than num_shards . This parameter is only valid when a ConcatDataset takes a
mindspore.dataset.DistributedSampleras its sampler. It will affect the number of samples per shard. Default:-1, which means each shard has the same number of samples.
- Raises:
TypeError – If num_shards is not of type int.
TypeError – If shard_id is not of type int.
TypeError – If shuffle is not of type bool or Shuffle.
TypeError – If num_samples is not of type int.
TypeError – If offset is not of type int.
ValueError – If num_samples is a negative value.
RuntimeError – If num_shards is not a positive value.
RuntimeError – If shard_id is smaller than 0 or equal to num_shards or larger than num_shards .
RuntimeError – If offset is greater than num_shards .
Examples
>>> import mindspore.dataset as ds >>> # creates a distributed sampler with 10 shards in total. This shard is shard 5. >>> sampler = ds.DistributedSampler(10, 5) >>> dataset = ds.ImageFolderDataset(image_folder_dataset_dir, ... num_parallel_workers=8, ... sampler=sampler)
- class mindspore.dataset.EMnistDataset(dataset_dir, name, usage=None, num_samples=None, num_parallel_workers=None, shuffle=None, sampler=None, num_shards=None, shard_id=None, cache=None)[source]
EMNIST(Extended MNIST) dataset.
The generated dataset has two columns
[image, label]. The tensor of columnimageis of the uint8 type. The tensor of columnlabelis a scalar of the uint32 type.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
name (str) – Name of splits for this dataset, can be
'byclass','bymerge','balanced','letters','digits'or'mnist'.usage (str, optional) – Usage of this dataset, can be
'train','test'or'all'.'train'will read from 60,000 train samples,'test'will read from 10,000 test samples,'all'will read from all 70,000 samples. Default:None, will read all samples.num_samples (int, optional) – The number of images to be included in the dataset. Default:
None, will read all images.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (bool, optional) – Whether or not to perform shuffle on the dataset. Default:
None, expected order behavior shown in the table below.sampler (Sampler, optional) – Object used to choose samples from the dataset. Default:
None, expected order behavior shown in the table below.num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the maximum number of samples per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If sampler and shuffle are specified at the same time.
RuntimeError – If sampler and num_shards/shard_id are specified at the same time.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If shard_id is not in range of [0, num_shards ).
- Tutorial Examples:
Note
The parameters num_samples , shuffle , num_shards , shard_id can be used to control the sampler used in the dataset, and their effects when combined with parameter sampler are as follows.
Examples
>>> import mindspore.dataset as ds >>> emnist_dataset_dir = "/path/to/emnist_dataset_directory" >>> >>> # Read 3 samples from EMNIST dataset >>> dataset = ds.EMnistDataset(dataset_dir=emnist_dataset_dir, name="mnist", num_samples=3) >>> >>> # Note: In EMNIST dataset, each dictionary has keys "image" and "label"
About EMNIST dataset:
The EMNIST dataset is a set of handwritten character digits derived from the NIST Special Database 19 and converted to a 28x28 pixel image format and dataset structure that directly matches the MNIST dataset. Further information on the dataset contents and conversion process can be found in the paper available at https://arxiv.org/abs/1702.05373v1.
The numbers of characters and classes of each split of EMNIST are as follows:
By Class: 814,255 characters and 62 unbalanced classes. By Merge: 814,255 characters and 47 unbalanced classes. Balanced: 131,600 characters and 47 balanced classes. Letters: 145,600 characters and 26 balanced classes. Digits: 280,000 characters and 10 balanced classes. MNIST: 70,000 characters and 10 balanced classes.
Here is the original EMNIST dataset structure. You can unzip the dataset files into this directory structure and read by MindSpore's API.
. └── mnist_dataset_dir ├── emnist-mnist-train-images-idx3-ubyte ├── emnist-mnist-train-labels-idx1-ubyte ├── emnist-mnist-test-images-idx3-ubyte ├── emnist-mnist-test-labels-idx1-ubyte ├── ...Citation:
@inproceedings{cohen2017emnist, title = {EMNIST: Extending MNIST to handwritten letters}, author = {Cohen, Gregory and Afshar, Saeed and Tapson, Jonathan and Van Schaik, Andre}, booktitle = {2017 international joint conference on neural networks (IJCNN)}, pages = {2921--2926}, year = {2017}, organization = {IEEE} }
- class mindspore.dataset.EnWik9Dataset(dataset_dir, num_samples=None, num_parallel_workers=None, shuffle=True, num_shards=None, shard_id=None, cache=None)[source]
EnWik9 dataset.
The generated dataset has one column
[text]with type string.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
num_samples (int, optional) – The number of samples to be included in the dataset. Default:
None, will include all samples.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (Union[bool, Shuffle], optional) –
Perform reshuffling of the data every epoch. Bool type and Shuffle enum are both supported to pass in. Default:
True. If shuffle isFalse, no shuffling will be performed. If shuffle isTrue, it is equivalent to setting shuffle toShuffle.GLOBAL. Set the mode of data shuffling by passing in enumeration variables:Shuffle.GLOBAL: Shuffle both the files and samples.Shuffle.FILES: Shuffle files only.
num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the maximum number of samples per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir does not contain data files.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If num_parallel_workers exceeds the max thread numbers.
- Tutorial Examples:
Examples
>>> import mindspore.dataset as ds >>> en_wik9_dataset_dir = "/path/to/en_wik9_dataset" >>> dataset2 = ds.EnWik9Dataset(dataset_dir=en_wik9_dataset_dir, num_samples=2, ... shuffle=True)
About EnWik9 dataset:
The data of EnWik9 is UTF-8 encoded XML consisting primarily of English text. It contains 243,426 article titles, of which 85,560 are redirect pages to fix broken links, and the rest are regular articles.
The data is UTF-8 clean. All characters are in the range U'0000 to U'10FFFF with valid encodings of 1 to 4 bytes. The byte values 0xC0, 0xC1, and 0xF5-0xFF never occur. Also, in the Wikipedia dumps, there are no control characters in the range 0x00-0x1F except for 0x09 (tab) and 0x0A (linefeed). Linebreaks occur only on paragraph boundaries, so they always have a semantic purpose.
You can unzip the dataset files into the following directory structure and read by MindSpore's API.
. └── EnWik9 ├── enwik9Citation:
@NetworkResource{Hutter_prize, author = {English Wikipedia}, url = "https://mattmahoney.net/dc/textdata.html", month = {March}, year = {2006} }
- class mindspore.dataset.FakeImageDataset(num_images=1000, image_size=(224, 224, 3), num_classes=10, base_seed=0, num_samples=None, num_parallel_workers=None, shuffle=None, sampler=None, num_shards=None, shard_id=None, cache=None)[source]
A source dataset for generating fake images.
The generated dataset has two columns
[image, label]. The tensor of columnimageis of the uint8 type. The columnlabelis a scalar of the uint32 type.- Parameters:
num_images (int, optional) – Number of images to generate in the dataset. Default:
1000.image_size (tuple, optional) – Size of the fake image. Default:
(224, 224, 3).num_classes (int, optional) – Number of classes in the dataset. Default:
10.base_seed (int, optional) – Offsets the index-based random seed used to generate each image. Default:
0.num_samples (int, optional) – The number of images to be included in the dataset. Default:
None, will read all images.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (bool, optional) – Whether or not to perform shuffle on the dataset. Default:
None, expected order behavior shown in the table below.sampler (Sampler, optional) – Object used to choose samples from the dataset. Default:
None, expected order behavior shown in the table below.num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the max sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If sampler and shuffle are specified at the same time.
RuntimeError – If sampler and num_shards/shard_id are specified at the same time.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If num_parallel_workers exceeds the max thread numbers.
ValueError – If shard_id is not in range of [0, num_shards ).
- Tutorial Examples:
Note
The parameters num_samples , shuffle , num_shards , shard_id can be used to control the sampler used in the dataset, and their effects when combined with parameter sampler are as follows.
Examples
>>> import mindspore.dataset as ds >>> # Read 3 samples from FakeImage dataset >>> dataset = ds.FakeImageDataset(num_images=1000, image_size=(224,224,3), ... num_classes=10, base_seed=0, num_samples=3)
- class mindspore.dataset.FashionMnistDataset(dataset_dir, usage=None, num_samples=None, num_parallel_workers=None, shuffle=None, sampler=None, num_shards=None, shard_id=None, cache=None)[source]
Fashion-MNIST dataset.
The generated dataset has two columns
[image, label]. The tensor of columnimageis of the uint8 type. The columnlabelis a scalar of the uint32 type.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
usage (str, optional) – Usage of this dataset, can be
'train','test'or'all'.'train'will read from 60,000 train samples,'test'will read from 10,000 test samples,'all'will read from all 70,000 samples. Default:None, will read all samples.num_samples (int, optional) – The number of images to be included in the dataset. Default:
None, will read all images.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (bool, optional) – Whether or not to perform shuffle on the dataset. Default:
None, expected order behavior shown in the table below.sampler (Sampler, optional) – Object used to choose samples from the dataset. Default:
None, expected order behavior shown in the table below.num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the maximum sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir does not contain data files.
RuntimeError – If sampler and shuffle are specified at the same time.
RuntimeError – If sampler and num_shards/shard_id are specified at the same time.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If num_parallel_workers exceeds the max thread numbers.
ValueError – If shard_id is not in range of [0, num_shards ).
- Tutorial Examples:
Note
The parameters num_samples , shuffle , num_shards , shard_id can be used to control the sampler used in the dataset, and their effects when combined with parameter sampler are as follows.
Examples
>>> import mindspore.dataset as ds >>> fashion_mnist_dataset_dir = "/path/to/fashion_mnist_dataset_directory" >>> >>> # Read 3 samples from FASHIONMNIST dataset >>> dataset = ds.FashionMnistDataset(dataset_dir=fashion_mnist_dataset_dir, num_samples=3) >>> >>> # Note: In FASHIONMNIST dataset, each dictionary has keys "image" and "label"
About Fashion-MNIST dataset:
Fashion-MNIST is a dataset of Zalando's article images—consisting of a training set of 60,000 examples and a test set of 10,000 examples. Each example is a 28x28 grayscale image, associated with a label from 10 classes. We intend Fashion-MNIST to serve as a direct drop-in replacement for the original MNIST dataset for benchmarking machine learning algorithms. It shares the same image size and structure of training and testing splits.
You can unzip the dataset files into this directory structure and read by MindSpore's API.
. └── fashionmnist_dataset_dir ├── t10k-images-idx3-ubyte ├── t10k-labels-idx1-ubyte ├── train-images-idx3-ubyte └── train-labels-idx1-ubyteCitation:
@online{xiao2017/online, author = {Han Xiao and Kashif Rasul and Roland Vollgraf}, title = {Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms}, date = {2017-08-28}, year = {2017}, eprintclass = {cs.LG}, eprinttype = {arXiv}, eprint = {cs.LG/1708.07747}, }
- class mindspore.dataset.FlickrDataset(dataset_dir, annotation_file, num_samples=None, num_parallel_workers=None, shuffle=None, decode=None, sampler=None, num_shards=None, shard_id=None, cache=None)[source]
Flickr8k and Flickr30k datasets.
The generated dataset has two columns
[image, annotation]. The tensor of columnimageis of the uint8 type. The tensor of columnannotationis a tensor which contains 5 annotations strings, such as ["a", "b", "c", "d", "e"].- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
annotation_file (str) – Path to the root directory that contains the annotation.
num_samples (int, optional) – The number of images to be included in the dataset. Default:
None, all images.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (bool, optional) – Whether to perform shuffle on the dataset. Default:
None, expected order behavior shown in the table below.decode (bool, optional) – Decode the images after reading. Default:
None.sampler (Sampler, optional) – Object used to choose samples from the dataset. Default:
None, expected order behavior shown in the table below.num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the maximum sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir is not valid or does not contain data files.
ValueError – If num_parallel_workers exceeds the max thread numbers.
RuntimeError – If sampler and shuffle are specified at the same time.
RuntimeError – If sampler and num_shards/shard_id are specified at the same time.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If dataset_dir does not exist.
ValueError – If annotation_file does not exist.
ValueError – If shard_id is not in range of [0, num_shards ).
- Tutorial Examples:
Note
The parameters num_samples , shuffle , num_shards , shard_id can be used to control the sampler used in the dataset, and their effects when combined with parameter sampler are as follows.
Examples
>>> import mindspore.dataset as ds >>> flickr_dataset_dir = "/path/to/flickr_dataset_directory" >>> annotation_file = "/path/to/flickr_annotation_file" >>> >>> # 1) Get all samples from FLICKR dataset in sequence >>> dataset = ds.FlickrDataset(dataset_dir=flickr_dataset_dir, ... annotation_file=annotation_file, ... shuffle=False) >>> >>> # 2) Randomly select 350 samples from FLICKR dataset >>> dataset = ds.FlickrDataset(dataset_dir=flickr_dataset_dir, ... annotation_file=annotation_file, ... num_samples=350, ... shuffle=True) >>> >>> # 3) Get samples from FLICKR dataset for shard 0 in a 2-way distributed training >>> dataset = ds.FlickrDataset(dataset_dir=flickr_dataset_dir, ... annotation_file=annotation_file, ... num_shards=2, ... shard_id=0) >>> >>> # In FLICKR dataset, each dictionary has keys "image" and "annotation"
About Flickr8k dataset:
The Flickr8k dataset consists of 8092 color images. There are 40460 annotations in the Flickr8k.token.txt, each image has 5 annotations.
You can unzip the dataset files into the following directory structure and read by MindSpore's API.
. └── Flickr8k ├── Flickr8k_Dataset │ ├── 1000268201_693b08cb0e.jpg │ ├── 1001773457_577c3a7d70.jpg │ ├── ... └── Flickr8k.token.txtCitation:
@article{DBLP:journals/jair/HodoshYH13, author = {Micah Hodosh and Peter Young and Julia Hockenmaier}, title = {Framing Image Description as a Ranking Task: Data, Models and Evaluation Metrics}, journal = {J. Artif. Intell. Res.}, volume = {47}, pages = {853--899}, year = {2013}, url = {https://doi.org/10.1613/jair.3994}, doi = {10.1613/jair.3994}, timestamp = {Mon, 21 Jan 2019 15:01:17 +0100}, biburl = {https://dblp.org/rec/journals/jair/HodoshYH13.bib}, bibsource = {dblp computer science bibliography, https://dblp.org} }
About Flickr30k dataset:
The Flickr30k dataset consists of 31783 color images. There are 158915 annotations in the results_20130124.token, each image has 5 annotations.
You can unzip the dataset files into the following directory structure and read by MindSpore's API.
. └── Flickr30k ├── flickr30k-images │ ├── 1000092795.jpg │ ├── 10002456.jpg │ ├── ... └── results_20130124.tokenCitation:
@article{DBLP:journals/tacl/YoungLHH14, author = {Peter Young and Alice Lai and Micah Hodosh and Julia Hockenmaier}, title = {From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions}, journal = {Trans. Assoc. Comput. Linguistics}, volume = {2}, pages = {67--78}, year = {2014}, url = {https://tacl2013.cs.columbia.edu/ojs/index.php/tacl/article/view/229}, timestamp = {Wed, 17 Feb 2021 21:55:25 +0100}, biburl = {https://dblp.org/rec/journals/tacl/YoungLHH14.bib}, bibsource = {dblp computer science bibliography, https://dblp.org} }
- class mindspore.dataset.Flowers102Dataset(dataset_dir, task='Classification', usage='all', num_samples=None, num_parallel_workers=1, shuffle=None, decode=False, sampler=None, num_shards=None, shard_id=None)[source]
Oxford 102 Flower dataset.
According to the given task configuration, the generated dataset has different output columns: - task = 'Classification', output columns: [image, dtype=uint8] , [label, dtype=uint32] . - task = 'Segmentation', output columns: [image, dtype=uint8] , [segmentation, dtype=uint8] , [label, dtype=uint32] .
- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
task (str, optional) – Specify the
'Classification'or'Segmentation'task. Default:'Classification'.usage (str, optional) – Specify the
'train','valid','test'part or'all'parts of dataset. Default: 'all', will read all samples.num_samples (int, optional) – The number of samples to be included in the dataset. Default:
None, all images.num_parallel_workers (int, optional) – Number of worker subprocesses used to fetch the dataset in parallel. Default:
1.shuffle (bool, optional) – Whether or not to perform shuffle on the dataset. Default:
None, expected order behavior shown in the table below.decode (bool, optional) – Whether or not to decode the images and segmentations after reading. Default:
False.sampler (Union[Sampler, Iterable], optional) – Object used to choose samples from the dataset. Default:
None, expected order behavior shown in the table below.num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the maximum sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument must be specified only when num_shards is also specified.
- Raises:
RuntimeError – If dataset_dir does not contain data files.
RuntimeError – If sampler and shuffle are specified at the same time.
RuntimeError – If sampler and num_shards/shard_id are specified at the same time.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If num_parallel_workers exceeds the max thread numbers.
ValueError – If shard_id is not in range of [0, num_shards ).
- Tutorial Examples:
Note
The parameters num_samples , shuffle , num_shards , shard_id can be used to control the sampler used in the dataset, and their effects when combined with parameter sampler are as follows.
Examples
>>> import mindspore.dataset as ds >>> flowers102_dataset_dir = "/path/to/flowers102_dataset_directory" >>> dataset = ds.Flowers102Dataset(dataset_dir=flowers102_dataset_dir, ... task="Classification", ... usage="all", ... decode=True)
About Flowers102 dataset:
Flowers102 dataset consists of 102 flower categories. The flowers commonly occur in the United Kingdom. Each class consists of between 40 and 258 images.
Here is the original Flowers102 dataset structure. You can unzip the dataset files into this directory structure and read by MindSpore's API.
. └── flowers102_dataset_dir ├── imagelabels.mat ├── setid.mat ├── jpg ├── image_00001.jpg ├── image_00002.jpg ├── ... ├── segmim ├── segmim_00001.jpg ├── segmim_00002.jpg ├── ...Citation:
@InProceedings{Nilsback08, author = "Maria-Elena Nilsback and Andrew Zisserman", title = "Automated Flower Classification over a Large Number of Classes", booktitle = "Indian Conference on Computer Vision, Graphics and Image Processing", month = "Dec", year = "2008", }
- class mindspore.dataset.Food101Dataset(dataset_dir, usage=None, num_samples=None, num_parallel_workers=None, shuffle=None, decode=False, sampler=None, num_shards=None, shard_id=None, cache=None)[source]
Food101 dataset.
The generated dataset has two columns
[image, label]. The tensor of columnimageis of the uint8 type. The tensor of columnlabelis of the string type.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
usage (str, optional) – Usage of this dataset, can be
'train','test', or'all'.'train'will read from 75,750 samples,'test'will read from 25,250 samples, and'all'will read all'train'and'test'samples. Default:None, will be set to'all'.num_samples (int, optional) – The number of images to be included in the dataset. Default:
None, will read all images.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (bool, optional) – Whether or not to perform shuffle on the dataset. Default:
None, expected order behavior shown in the table below.decode (bool, optional) – Decode the images after reading. Default:
False.sampler (Sampler, optional) – Object used to choose samples from the dataset. Default:
None, expected order behavior shown in the table below.num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the maximum sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir does not contain data files.
RuntimeError – If sampler and shuffle are specified at the same time.
RuntimeError – If sampler and num_shards/shard_id are specified at the same time.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If shard_id is not in range of [0, num_shards ).
ValueError – If num_parallel_workers exceeds the max thread numbers.
ValueError – If the value of usage is not
'train','test', or'all'.ValueError – If dataset_dir does not exist.
- Tutorial Examples:
Note
The parameters num_samples , shuffle , num_shards , shard_id can be used to control the sampler used in the dataset, and their effects when combined with parameter sampler are as follows.
Examples
>>> import mindspore.dataset as ds >>> food101_dataset_dir = "/path/to/food101_dataset_directory" >>> >>> # Read 3 samples from Food101 dataset >>> dataset = ds.Food101Dataset(dataset_dir=food101_dataset_dir, num_samples=3)
About Food101 dataset:
The Food101 is a dataset of 101 food categories, with 101,000 images. There are 250 test images and 750 training images in each class. All images were rescaled to have a maximum side length of 512 pixels.
The following is the original Food101 dataset structure. You can unzip the dataset files into this directory structure and read by MindSpore's API.
. └── food101_dir ├── images │ ├── apple_pie │ │ ├── 1005649.jpg │ │ ├── 1014775.jpg │ │ ├──... │ ├── baby_back_rips │ │ ├── 1005293.jpg │ │ ├── 1007102.jpg │ │ ├──... │ └──... └── meta ├── train.txt ├── test.txt ├── classes.txt ├── train.json ├── test.json └── train.txtCitation:
@inproceedings{bossard14, title = {Food-101 -- Mining Discriminative Components with Random Forests}, author = {Bossard, Lukas and Guillaumin, Matthieu and Van Gool, Luc}, booktitle = {European Conference on Computer Vision}, year = {2014} }
- class mindspore.dataset.GTZANDataset(dataset_dir, usage=None, num_samples=None, num_parallel_workers=None, shuffle=None, sampler=None, num_shards=None, shard_id=None, cache=None)[source]
GTZAN dataset.
The generated dataset has three columns:
[waveform, sample_rate, label]. The tensor of columnwaveformis of the float32 type. The tensor of columnsample_rateis of a scalar of uint32 type. The tensor of columnlabelis of a scalar of string type.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
usage (str, optional) – Usage of this dataset, can be 'train', 'valid', 'test' or 'all'. Default:
None, will read all samples.num_samples (int, optional) – The number of audio to be included in the dataset. Default:
None, will read all audio.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (bool, optional) – Whether or not to perform shuffle on the dataset. Default:
None, expected order behavior shown in the table below.sampler (Sampler, optional) – Object used to choose samples from the dataset. Default:
None, expected order behavior shown in the table below.num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the max sample number of per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir does not contain data files.
ValueError – If num_parallel_workers exceeds the max thread numbers.
RuntimeError – If sampler and shuffle are specified at the same time.
RuntimeError – If sampler and num_shards/shard_id are specified at the same time.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If shard_id is not in range of [0, num_shards ).
- Tutorial Examples:
Note
Does not support
mindspore.dataset.PKSamplerfor sampler parameter yet.The parameters num_samples , shuffle , num_shards , shard_id can be used to control the sampler used in the dataset, and their effects when combined with parameter sampler are as follows.
Examples
>>> import mindspore.dataset as ds >>> gtzan_dataset_directory = "/path/to/gtzan_dataset_directory" >>> >>> # 1) Read 500 samples (audio files) in gtzan_dataset_directory >>> dataset = ds.GTZANDataset(gtzan_dataset_directory, usage="all", num_samples=500) >>> >>> # 2) Read all samples (audio files) in gtzan_dataset_directory >>> dataset = ds.GTZANDataset(gtzan_dataset_directory)
About GTZAN dataset:
The GTZAN dataset appears in at least 100 published works and is the most commonly used public dataset for evaluation in machine listening research for music genre recognition. It consists of 1000 audio tracks, each of which is 30 seconds long. It contains 10 genres (blues, classical, country, disco, hiphop, jazz, metal, pop, reggae and rock), each of which is represented by 100 tracks. The tracks are all 22050Hz Mono 16-bit audio files in .wav format.
You can construct the following directory structure from GTZAN dataset and read by MindSpore's API.
. └── gtzan_dataset_directory ├── blues │ ├──blues.00000.wav │ ├──blues.00001.wav │ ├──blues.00002.wav │ ├──... ├── disco │ ├──disco.00000.wav │ ├──disco.00001.wav │ ├──disco.00002.wav │ └──... └──...Citation:
@misc{tzanetakis_essl_cook_2001, author = "Tzanetakis, George and Essl, Georg and Cook, Perry", title = "Automatic Musical Genre Classification Of Audio Signals", url = "http://ismir2001.ismir.net/pdf/tzanetakis.pdf", publisher = "The International Society for Music Information Retrieval", year = "2001" }
- class mindspore.dataset.GeneratorDataset(source, column_names=None, column_types=None, schema=None, num_samples=None, num_parallel_workers=1, shuffle=None, sampler=None, num_shards=None, shard_id=None, python_multiprocessing=True, max_rowsize=None, batch_sampler=None, collate_fn=None)[source]
A source dataset that generates data from Python by invoking Python data source each epoch.
The column names and column types of generated dataset depend on Python data defined by users.
- Parameters:
source (Union[Random Accessible, Iterable]) –
A custom dataset from which to load the data. MindSpore supports the following types of datasets:
Random-accessible (map-style) datasets: A dataset object that implements the __getitem__() and __len__() methods, represents a mapping from indexes/keys to data samples. For example, such a dataset source, when accessed with source[idx], can read the idx-th sample from disk, see Random-accessible dataset example for details.
Iterable-style dataset: An iterable dataset object that implements __iter__() and __next__() methods, represents an iterable over data samples. This type of dataset is suitable for situations where random reads are costly or even impossible, and where batch sizes depend on the data being acquired. For example, such a dataset source, when accessed iter(source), can return a stream of data reading from a database or remote server, see Iterable-style dataset example for details.
column_names (Union[str, list[str]], optional) – List of column names of the dataset. Default:
None. Users are required to provide either column_names or schema.column_types (list[mindspore.dtype], optional) – List of column data types of the dataset. Default:
None. If provided, sanity check will be performed on generator output (deprecated in future version).schema (Union[str, Schema], optional) – Data format policy, which specifies the data types and shapes of the data column to be read. Both JSON file path and objects constructed by
mindspore.dataset.Schemaare acceptable (deprecated in future version). Default:None.num_samples (int, optional) – The number of samples to be included in the dataset. Default:
None, all images.num_parallel_workers (int, optional) – Number of worker threads/subprocesses used to fetch the dataset in parallel. Default:
1.shuffle (bool, optional) – Whether or not to perform shuffle on the dataset. Random accessible input is required. Default:
None, expected order behavior shown in the table below.sampler (Union[Sampler, Iterable], optional) – Object used to choose samples from the dataset. Random accessible input is required. Default:
None, expected order behavior shown in the table below.num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. Random accessible input is required. When this argument is specified, num_samples reflects the maximum sample number of per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument must be specified only when num_shards is also specified. Random accessible input is required.python_multiprocessing (bool, optional) – Parallelize Python operations with multiple worker process. This option could be beneficial if the Python operation is computational heavy. Default:
True.max_rowsize (int, optional) – Maximum size of data (in MB) that is used for shared memory allocation to copy data between processes, the total occupied shared memory will increase as
num_parallel_workersandmindspore.dataset.config.set_prefetch_size()increase. If set to-1, shared memory will be dynamically allocated with the actual size of data. This is only used ifpython_multiprocessingis set toTrue. Default:None, allocate shared memory dynamically (deprecated in future version).batch_sampler (Iterable, optional) – Similar to sampler , but returns a batch of indices at a time, the corresponding data will be combined into a batch. Mutually exclusive with num_samples , shuffle , num_shards , shard_id and sampler . Default:
None, do not use batch sampler.collate_fn (Callable[List[numpy.ndarray]], optional) – Define how to merge a list of data into a batch. Only valid if batch_sampler is used. Default:
None, do not use collation function.
Warning
GeneratorDataset uses dill module implicitly in multiprocessing spawn mode to serialize/deserialize source, which is known to be insecure. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling. Never load data that could have come from untrusted sources, or has been tampered with.
Note
The parameter column_types , schema and max_rowsize will be deprecated in a future version.
If you configure python_multiprocessing=True (Default:
True) and num_parallel_workers>1 (default:1) indicates that the multiprocessing mode is started for data load acceleration. At this time, as the dataset iterates, the memory consumption of the subprocess will gradually increase, mainly because the subprocess of the user-defined dataset obtains the member variables from the main process in the Copy On Write way. Example: If you define a dataset with __init__ function which contains a large number of member variable data (for example, a very large file name list is loaded during the dataset construction) and uses the multiprocessing mode, which may cause the problem of OOM (the estimated total memory usage is: (num_parallel_workers+1) * size of the parent process ). The simplest solution is to replace Python objects (such as list/dict/int/float/string) with non referenced data types (such as Pandas, Numpy or PyArrow objects) for member variables, or load less metadata in member variables, or configure python_multiprocessing=False to use multi-threading mode.You can use the following classes/functions to reduce the size of member variables:
mindspore.dataset.utils.LineReader: Use this class to initialize your text file object in the __init__ function. Then read the file content based on the line number of the object with the __getitem__ function.Input source accepts user-defined Python functions (PyFuncs), and sets the multiprocessing start method to spawn mode by ds.config.set_multiprocessing_start_method("spawn") with python_multiprocessing=True and num_parallel_workers>1 supports adding network computing operators from mindspore.nn and mindspore.ops or others into this source, otherwise adding to the source is not supported.
When the user defined dataset by source calls the DVPP operator during dataset loading and processing, the supported scenarios are as follows:
Multithreading
Multiprocessing
spawn
fork
Independent
process mode
Data Processing: support
Data Processing + Network training: not support
Data Processing: support
Data Processing + Network training: support
Data Processing: support
Data Processing + Network training: not support
Non-independent
process mode
Data Processing: support
Data Processing + Network training: support
Data Processing: support
Data Processing + Network training: support
Data Processing: support
Data Processing + Network training: not support
The parameters num_samples , shuffle , num_shards , shard_id can be used to control the sampler used in the dataset, and their effects when combined with parameter sampler are as follows.
- Raises:
RuntimeError – If source raises an exception during execution.
RuntimeError – If len of column_names does not match output len of source.
ValueError – If num_parallel_workers exceeds the max thread numbers.
ValueError – If sampler and shuffle are specified at the same time.
ValueError – If sampler and sharding are specified at the same time.
ValueError – If num_shards is specified but shard_id is None.
ValueError – If shard_id is specified but num_shards is None.
ValueError – If shard_id is not in range of [0, num_shards ).
ValueError – If batch_sampler is specified together with num_samples , shuffle , num_shards , shard_id and sampler.
ValueError – If collate_fn is specified while batch_sampler is None.
TypeError – If batch_sampler is not iterable.
TypeError – If collate_fn is not callable.
Examples
>>> import mindspore.dataset as ds >>> import numpy as np >>> >>> # 1) Multidimensional generator function as callable input. >>> def generator_multidimensional(): ... for i in range(64): ... yield (np.array([[i, i + 1], [i + 2, i + 3]]),) >>> >>> dataset = ds.GeneratorDataset(source=generator_multidimensional, column_names=["multi_dimensional_data"]) >>> >>> # 2) Multi-column generator function as callable input. >>> def generator_multi_column(): ... for i in range(64): ... yield np.array([i]), np.array([[i, i + 1], [i + 2, i + 3]]) >>> >>> dataset = ds.GeneratorDataset(source=generator_multi_column, column_names=["col1", "col2"]) >>> >>> # 3) Iterable dataset as iterable input. >>> class MyIterable: ... def __init__(self): ... self._index = 0 ... self._data = np.random.sample((5, 2)) ... self._label = np.random.sample((5, 1)) ... ... def __next__(self): ... if self._index >= len(self._data): ... raise StopIteration ... else: ... item = (self._data[self._index], self._label[self._index]) ... self._index += 1 ... return item ... ... def __iter__(self): ... self._index = 0 ... return self ... ... def __len__(self): ... return len(self._data) >>> >>> dataset = ds.GeneratorDataset(source=MyIterable(), column_names=["data", "label"]) >>> >>> # 4) Random accessible dataset as random accessible input. >>> class MyAccessible: ... def __init__(self): ... self._data = np.random.sample((5, 2)) ... self._label = np.random.sample((5, 1)) ... ... def __getitem__(self, index): ... return self._data[index], self._label[index] ... ... def __len__(self): ... return len(self._data) >>> >>> dataset = ds.GeneratorDataset(source=MyAccessible(), column_names=["data", "label"]) >>> >>> # list, dict, tuple of Python is also random accessible >>> dataset = ds.GeneratorDataset(source=[(np.array(0),), (np.array(1),), (np.array(2),)], column_names=["col"])
- Tutorial Examples:
- add_sampler(new_sampler)[source]
Add a child sampler for the current dataset.
Note
If the sampler is added and it has a shuffle option, its value must be
Shuffle.GLOBAL. Additionally, the original sampler's shuffle value cannot beShuffle.PARTIAL.
- Parameters:
new_sampler (Sampler) – The child sampler to be added.
Examples
>>> import mindspore.dataset as ds >>> dataset = ds.GeneratorDataset([i for i in range(10)], "column1") >>> >>> new_sampler = ds.DistributedSampler(10, 2) >>> dataset.add_sampler(new_sampler)
- class mindspore.dataset.IMDBDataset(dataset_dir, usage=None, num_samples=None, num_parallel_workers=None, shuffle=None, sampler=None, num_shards=None, shard_id=None, cache=None)[source]
IMDb(Internet Movie Database) dataset.
The generated dataset has two columns:
[text, label]. The tensor of columntextis of the string type. The columnlabelis of a scalar of uint32 type.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
usage (str, optional) – Usage of this dataset, can be
'train','test'or'all'. Default:None, will read all samples.num_samples (int, optional) – The number of samples to be included in the dataset. Default:
None, will include all samples.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (bool, optional) – Whether or not to perform shuffle on the dataset. Default:
None, expected order behavior shown in the table below.sampler (Sampler, optional) – Object used to choose samples from the dataset. Default:
None, expected order behavior shown in the table below.num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the maximum sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir does not contain data files.
RuntimeError – If sampler and shuffle are specified at the same time.
RuntimeError – If sampler and num_shards/shard_id are specified at the same time.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If num_parallel_workers exceeds the max thread numbers.
ValueError – If shard_id is not in range of [0, num_shards ).
- Tutorial Examples:
Note
The parameters num_samples , shuffle , num_shards , shard_id can be used to control the sampler used in the dataset, and their effects when combined with parameter sampler are as follows.
Examples
>>> import mindspore.dataset as ds >>> imdb_dataset_dir = "/path/to/imdb_dataset_directory" >>> >>> # 1) Read all samples (text files) in imdb_dataset_dir with 8 threads >>> dataset = ds.IMDBDataset(dataset_dir=imdb_dataset_dir, num_parallel_workers=8) >>> >>> # 2) Read train samples (text files). >>> dataset = ds.IMDBDataset(dataset_dir=imdb_dataset_dir, usage="train")
About IMDBDataset:
The IMDB dataset contains 50,000 highly polarized reviews from the Internet Movie Database (IMDB). The dataset was divided into 25,000 comments for training and 25,000 comments for testing, with both the training set and test set containing 50% positive and 50% negative comments. Train labels and test labels are all lists of 0 and 1, where 0 stands for negative and 1 for positive.
You can unzip the dataset files into this directory structure and read by MindSpore's API.
. └── imdb_dataset_directory ├── train │ ├── pos │ │ ├── 0_9.txt │ │ ├── 1_7.txt │ │ ├── ... │ ├── neg │ │ ├── 0_3.txt │ │ ├── 1_1.txt │ │ ├── ... ├── test │ ├── pos │ │ ├── 0_10.txt │ │ ├── 1_10.txt │ │ ├── ... │ ├── neg │ │ ├── 0_2.txt │ │ ├── 1_3.txt │ │ ├── ...Citation:
@InProceedings{maas-EtAl:2011:ACL-HLT2011, author = {Maas, Andrew L. and Daly, Raymond E. and Pham, Peter T. and Huang, Dan and Ng, Andrew Y. and Potts, Christopher}, title = {Learning Word Vectors for Sentiment Analysis}, booktitle = {Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies}, month = {June}, year = {2011}, address = {Portland, Oregon, USA}, publisher = {Association for Computational Linguistics}, pages = {142--150}, url = {http://www.aclweb.org/anthology/P11-1015} }
- class mindspore.dataset.IWSLT2016Dataset(dataset_dir, usage=None, language_pair=None, valid_set=None, test_set=None, num_samples=None, shuffle=Shuffle.GLOBAL, num_shards=None, shard_id=None, num_parallel_workers=None, cache=None)[source]
IWSLT2016(International Workshop on Spoken Language Translation) dataset.
The generated dataset has two columns:
[text, translation]. The tensor of columntextis of the string type. The columntranslationis of the string type.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
usage (str, optional) – Acceptable usages include 'train', 'valid', 'test' and 'all'. Default:
None, all samples.language_pair (sequence, optional) – Sequence containing source and target language, supported values are
('en', 'fr'),('en', 'de'),('en', 'cs'),('en', 'ar'),('fr', 'en'),('de', 'en'),('cs', 'en'),('ar', 'en'). Default:None, set to('de', 'en').valid_set (str, optional) – A string to identify validation set, when usage is valid or all, the validation set of valid_set type will be read, supported values are
'dev2010','tst2010','tst2011','tst2012','tst2013'and'tst2014'. Default:None, set to'tst2013'.test_set (str, optional) – A string to identify test set, when usage is test or all, the test set of test_set type will be read, supported values are
'dev2010','tst2010','tst2011','tst2012','tst2013'and'tst2014'. Default:None, set to'tst2014'.num_samples (int, optional) – Number of samples (rows) to read. Default:
None, reads the full dataset.shuffle (Union[bool, Shuffle], optional) –
Perform reshuffling of the data every epoch. Bool type and Shuffle enum are both supported to pass in. Default:
Shuffle.GLOBAL. If shuffle isFalse, no shuffling will be performed. If shuffle isTrue, it is equivalent to setting shuffle toShuffle.GLOBAL. Set the mode of data shuffling by passing in enumeration variables:Shuffle.GLOBAL: Shuffle both the files and samples.Shuffle.FILES: Shuffle files only.
num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the maximum sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir does not contain data files.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If num_parallel_workers exceeds the max thread numbers.
- Tutorial Examples:
Examples
>>> import mindspore.dataset as ds >>> iwslt2016_dataset_dir = "/path/to/iwslt2016_dataset_dir" >>> dataset = ds.IWSLT2016Dataset(dataset_dir=iwslt2016_dataset_dir, usage='all', ... language_pair=('de', 'en'), valid_set='tst2013', test_set='tst2014')
About IWSLT2016 dataset:
IWSLT is an international oral translation conference, a major annual scientific conference dedicated to all aspects of oral translation. The MT task of the IWSLT evaluation activity constitutes a dataset, which can be publicly obtained through the WIT3 website wit3 . The IWSLT2016 dataset includes translations from English to Arabic, Czech, French, and German, and translations from Arabic, Czech, French, and German to English.
You can unzip the original IWSLT2016 dataset files into this directory structure and read by MindSpore's API. After decompression, you also need to decompress the dataset to be read in the specified folder. For example, if you want to read the dataset of de-en, you need to unzip the tgz file in the de/en directory, the dataset is in the unzipped folder.
. └── iwslt2016_dataset_directory ├── subeval_files └── texts ├── ar │ └── en │ └── ar-en ├── cs │ └── en │ └── cs-en ├── de │ └── en │ └── de-en │ ├── IWSLT16.TED.dev2010.de-en.de.xml │ ├── train.tags.de-en.de │ ├── ... ├── en │ ├── ar │ │ └── en-ar │ ├── cs │ │ └── en-cs │ ├── de │ │ └── en-de │ └── fr │ └── en-fr └── fr └── en └── fr-enCitation:
@inproceedings{cettoloEtAl:EAMT2012, Address = {Trento, Italy}, Author = {Mauro Cettolo and Christian Girardi and Marcello Federico}, Booktitle = {Proceedings of the 16$^{th}$ Conference of the European Association for Machine Translation (EAMT)}, Date = {28-30}, Month = {May}, Pages = {261--268}, Title = {WIT$^3$: Web Inventory of Transcribed and Translated Talks}, Year = {2012}}
- class mindspore.dataset.IWSLT2017Dataset(dataset_dir, usage=None, language_pair=None, num_samples=None, shuffle=Shuffle.GLOBAL, num_shards=None, shard_id=None, num_parallel_workers=None, cache=None)[source]
IWSLT2017(International Workshop on Spoken Language Translation) dataset.
The generated dataset has two columns:
[text, translation]. The tensors of columntextandtranslationare of the string type.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
usage (str, optional) – Acceptable usages include 'train', 'valid', 'test' and 'all'. Default:
None, all samples.language_pair (sequence, optional) – List containing src and tgt language, supported values are
('en', 'nl'),('en', 'de'),('en', 'it'),('en', 'ro'),('nl', 'en'),('nl', 'de'),('nl', 'it'),('nl', 'ro'),('de', 'en'),('de', 'nl'),('de', 'it'),('de', 'ro'),('it', 'en'),('it', 'nl'),('it', 'de'),('it', 'ro'),('ro', 'en'),('ro', 'nl'),('ro', 'de'),('ro', 'it'). Default:None, set to('de', 'en').num_samples (int, optional) – Number of samples (rows) to read. Default:
None, reads the full dataset.shuffle (Union[bool, Shuffle], optional) –
Perform reshuffling of the data every epoch. Bool type and Shuffle enum are both supported to pass in. Default:
Shuffle.GLOBAL. If shuffle isFalse, no shuffling will be performed. If shuffle isTrue, it is equivalent to setting shuffle toShuffle.GLOBAL. Set the mode of data shuffling by passing in enumeration variables:Shuffle.GLOBAL: Shuffle both the files and samples.Shuffle.FILES: Shuffle files only.
num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the max sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir does not contain data files.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If num_parallel_workers exceeds the max thread numbers.
- Tutorial Examples:
Examples
>>> import mindspore.dataset as ds >>> iwslt2017_dataset_dir = "/path/to/iwslt2017_dataset_dir" >>> dataset = ds.IWSLT2017Dataset(dataset_dir=iwslt2017_dataset_dir, usage='all', language_pair=('de', 'en'))
About IWSLT2017 dataset:
IWSLT is an international oral translation conference, a major annual scientific conference dedicated to all aspects of oral translation. The MT task of the IWSLT evaluation activity constitutes a dataset, which can be publicly obtained through the WIT3 website wit3 . The IWSLT2017 dataset involves German, English, Italian, Dutch, and Romanian. The dataset includes translations in any two different languages.
You can unzip the original IWSLT2017 dataset files into this directory structure and read by MindSpore's API. You need to decompress the dataset package in texts/DeEnItNlRo/DeEnItNlRo directory to get the DeEnItNlRo-DeEnItNlRo subdirectory.
. └── iwslt2017_dataset_directory └── DeEnItNlRo └── DeEnItNlRo └── DeEnItNlRo-DeEnItNlRo ├── IWSLT17.TED.dev2010.de-en.de.xml ├── train.tags.de-en.de ├── ...Citation:
@inproceedings{cettoloEtAl:EAMT2012, Address = {Trento, Italy}, Author = {Mauro Cettolo and Christian Girardi and Marcello Federico}, Booktitle = {Proceedings of the 16$^{th}$ Conference of the European Association for Machine Translation (EAMT)}, Date = {28-30}, Month = {May}, Pages = {261--268}, Title = {WIT$^3$: Web Inventory of Transcribed and Translated Talks}, Year = {2012}}
- class mindspore.dataset.ImageFolderDataset(dataset_dir, num_samples=None, num_parallel_workers=None, shuffle=None, sampler=None, extensions=None, class_indexing=None, decode=False, num_shards=None, shard_id=None, cache=None, decrypt=None)[source]
A source dataset that reads images from a tree of directories. All images within one folder have the same label.
The generated dataset has two columns:
[image, label]. The tensor of columnimageis of the uint8 type. The tensor of columnlabelis of a scalar of uint32 type.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
num_samples (int, optional) – The number of images to be included in the dataset. Default:
None, all images.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (bool, optional) – Whether or not to perform shuffle on the dataset. Default:
None, expected order behavior shown in the table below.sampler (Sampler, optional) – Object used to choose samples from the dataset. Default:
None, expected order behavior shown in the table below.extensions (list[str], optional) – List of file extensions to be included in the dataset. Default:
None.class_indexing (dict, optional) – A str-to-int mapping from folder name to index. Default:
None, the folder names will be sorted alphabetically and each class will be given a unique index starting from 0.decode (bool, optional) – Decode the images after reading. Default:
False.num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the maximum sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.decrypt (callable, optional) – Image decryption function, which accepts the path of the encrypted image file and returns the decrypted bytes data. Default:
None, no decryption.
- Raises:
RuntimeError – If dataset_dir does not contain data files.
RuntimeError – If sampler and shuffle are specified at the same time.
RuntimeError – If sampler and num_shards/shard_id are specified at the same time.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
RuntimeError – If class_indexing is not a dictionary.
ValueError – If num_parallel_workers exceeds the max thread numbers.
ValueError – If shard_id is not in range of [0, num_shards ).
- Tutorial Examples:
Note
The shape of the image column is [undecoded_image_size] if decode flag is
False, or [H,W,C] otherwise.The parameters num_samples , shuffle , num_shards , shard_id can be used to control the sampler used in the dataset, and their effects when combined with parameter sampler are as follows.
Examples
>>> import mindspore.dataset as ds >>> image_folder_dataset_dir = "/path/to/image_folder_dataset_directory" >>> >>> # 1) Read all samples (image files) in image_folder_dataset_dir with 8 threads >>> dataset = ds.ImageFolderDataset(dataset_dir=image_folder_dataset_dir, ... num_parallel_workers=8) >>> >>> # 2) Read all samples (image files) from folder cat and folder dog with label 0 and 1 >>> dataset = ds.ImageFolderDataset(dataset_dir=image_folder_dataset_dir, ... class_indexing={"cat":0, "dog":1}) >>> >>> # 3) Read all samples (image files) in image_folder_dataset_dir with extensions .JPEG >>> # and .png (case sensitive) >>> dataset = ds.ImageFolderDataset(dataset_dir=image_folder_dataset_dir, ... extensions=[".JPEG", ".png"])
About ImageFolderDataset:
You can construct the following directory structure from your dataset files and read by MindSpore's API.
. └── image_folder_dataset_directory ├── class1 │ ├── 000000000001.jpg │ ├── 000000000002.jpg │ ├── ... ├── class2 │ ├── 000000000001.jpg │ ├── 000000000002.jpg │ ├── ... ├── class3 │ ├── 000000000001.jpg │ ├── 000000000002.jpg │ ├── ... ├── classN ├── ...- get_class_indexing()[source]
Get the class index.
- Returns:
dict, a str-to-int mapping from label name to index.
Examples
>>> import mindspore.dataset as ds >>> image_folder_dataset_dir = "/path/to/image_folder_dataset_directory" >>> >>> dataset = ds.ImageFolderDataset(dataset_dir=image_folder_dataset_dir) >>> class_indexing = dataset.get_class_indexing()
- class mindspore.dataset.KITTIDataset(dataset_dir, usage=None, num_samples=None, num_parallel_workers=None, shuffle=None, decode=False, sampler=None, num_shards=None, shard_id=None, cache=None)[source]
KITTI dataset.
When usage is
"train", the generated dataset has multiple columns:[image, label, truncated, occluded, alpha, bbox, dimensions, location, rotation_y]; When usage is "test", the generated dataset has only one column:[image]. The tensor of columnimageis of the uint8 type. The tensor of columnlabelis of the uint32 type. The tensor of columntruncatedis of the float32 type. The tensor of columnoccludedis of the uint32 type. The tensor of columnalphais of the float32 type. The tensor of columnbboxis of the float32 type. The tensor of columndimensionsis of the float32 type. The tensor of columnlocationis of the float32 type. The tensor of columnrotation_yis of the float32 type.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
usage (str, optional) – Usage of this dataset, can be
"train"or"test"."train"will read 7481 train samples,"test"will read from 7518 test samples without label. Default:None, will use"train".num_samples (int, optional) – The number of images to be included in the dataset. Default:
None, will include all images.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (bool, optional) – Whether to perform shuffle on the dataset. Default:
None, expected order behavior shown in the table below.decode (bool, optional) – Decode the images after reading. Default:
False.sampler (Sampler, optional) – Object used to choose samples from the dataset. Default:
None, expected order behavior shown in the table below.num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the max sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards. Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If sampler and shuffle are specified at the same time.
RuntimeError – If sampler and num_shards/shard_id are specified at the same time.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If dataset_dir does not exist.
ValueError – If shard_id is not in range of [0, num_shards ).
- Tutorial Examples:
Note
The parameters num_samples , shuffle , num_shards , shard_id can be used to control the sampler used in the dataset, and their effects when combined with parameter sampler are as follows.
Examples
>>> import mindspore.dataset as ds >>> kitti_dataset_dir = "/path/to/kitti_dataset_directory" >>> >>> # 1) Read all KITTI train dataset samples in kitti_dataset_dir in sequence >>> dataset = ds.KITTIDataset(dataset_dir=kitti_dataset_dir, usage="train") >>> >>> # 2) Read then decode all KITTI test dataset samples in kitti_dataset_dir in sequence >>> dataset = ds.KITTIDataset(dataset_dir=kitti_dataset_dir, usage="test", ... decode=True, shuffle=False)
About KITTI dataset:
KITTI (Karlsruhe Institute of Technology and Toyota Technological Institute) is one of the most popular datasets for use in mobile robotics and autonomous driving. It consists of hours of traffic scenarios recorded with a variety of sensor modalities, including high-resolution RGB, grayscale stereo cameras, and a 3D laser scanner. Despite its popularity, the dataset itself does not contain ground truth for semantic segmentation. However, various researchers have manually annotated parts of the dataset to fit their necessities. Álvarez et al. generated ground truth for 323 images from the road detection challenge with three classes: road, vehicles and sky. Zhang et al. annotated 252 (140 for training and 112 for testing) acquisitions – RGB and Velodyne scans – from the tracking challenge for ten object categories: building, sky, road, vegetation, sidewalk, car, pedestrian, cyclist, sign/pole, and fence.
You can unzip the original KITTI dataset files into this directory structure and read by MindSpore's API.
. └── kitti_dataset_directory ├── data_object_image_2 │ ├──training │ │ ├──image_2 │ │ │ ├── 000000000001.jpg │ │ │ ├── 000000000002.jpg │ │ │ ├── ... │ ├──testing │ │ ├── image_2 │ │ │ ├── 000000000001.jpg │ │ │ ├── 000000000002.jpg │ │ │ ├── ... ├── data_object_label_2 │ ├──training │ │ ├──label_2 │ │ │ ├── 000000000001.jpg │ │ │ ├── 000000000002.jpg │ │ │ ├── ...Citation:
@INPROCEEDINGS{Geiger2012CVPR, author={Andreas Geiger and Philip Lenz and Raquel Urtasun}, title={Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite}, booktitle={Conference on Computer Vision and Pattern Recognition (CVPR)}, year={2012} }
- class mindspore.dataset.KMnistDataset(dataset_dir, usage=None, num_samples=None, num_parallel_workers=None, shuffle=None, sampler=None, num_shards=None, shard_id=None, cache=None)[source]
KMNIST(Kuzushiji-MNIST) dataset.
The generated dataset has two columns
[image, label]. The tensor of columnimageis of the uint8 type. The columnlabelis a scalar of the uint32 type.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
usage (str, optional) – Usage of this dataset, can be
'train','test'or'all'.'train'will read from 60,000 train samples,'test'will read from 10,000 test samples,'all'will read from all 70,000 samples. Default:None, will read all samples.num_samples (int, optional) – The number of images to be included in the dataset. Default:
None, will read all images.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (bool, optional) – Whether or not to perform shuffle on the dataset. Default:
None, expected order behavior shown in the table below.sampler (Sampler, optional) – Object used to choose samples from the dataset. Default:
None, expected order behavior shown in the table below.num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the maximum sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir does not contain data files.
RuntimeError – If sampler and shuffle are specified at the same time.
RuntimeError – If sampler and sharding are specified at the same time.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If num_parallel_workers exceeds the max thread numbers.
ValueError – If shard_id is not in range of [0, num_shards ).
- Tutorial Examples:
Note
The parameters num_samples , shuffle , num_shards , shard_id can be used to control the sampler used in the dataset, and their effects when combined with parameter sampler are as follows.
Examples
>>> import mindspore.dataset as ds >>> kmnist_dataset_dir = "/path/to/kmnist_dataset_directory" >>> >>> # Read 3 samples from KMNIST dataset >>> dataset = ds.KMnistDataset(dataset_dir=kmnist_dataset_dir, num_samples=3)
About KMNIST dataset:
KMNIST is a dataset, adapted from Kuzushiji Dataset, as a drop-in replacement for MNIST dataset, which is the most famous dataset in the machine learning community.
Here is the original KMNIST dataset structure. You can unzip the dataset files into this directory structure and read by MindSpore's API.
. └── kmnist_dataset_dir ├── t10k-images-idx3-ubyte ├── t10k-labels-idx1-ubyte ├── train-images-idx3-ubyte └── train-labels-idx1-ubyteCitation:
@online{clanuwat2018deep, author = {Tarin Clanuwat and Mikel Bober-Irizar and Asanobu Kitamoto and Alex Lamb and Kazuaki Yamamoto and David Ha}, title = {Deep Learning for Classical Japanese Literature}, date = {2018-12-03}, year = {2018}, eprintclass = {cs.CV}, eprinttype = {arXiv}, eprint = {cs.CV/1812.01718}, }
- class mindspore.dataset.LFWDataset(dataset_dir, task=None, usage=None, image_set=None, num_samples=None, num_parallel_workers=None, shuffle=None, decode=False, sampler=None, num_shards=None, shard_id=None, cache=None)[source]
LFW(Labeled Faces in the Wild) dataset.
When task is 'people', the generated dataset has two columns:
[image, label]; When task is 'pairs', the generated dataset has three columns:[image1, image2, label]. The tensor of columnimage,image1, andimage2are of the uint8 type. The tensor of columnlabelis a scalar of the uint32 type.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
task (str, optional) – Set the task type of reading LFW data, support
'people'and'pairs'. Default:None, means'people'.usage (str, optional) – The image split to use, support
'10fold','train','test'and'all'. Default:None, will read samples including'train'and'test'.image_set (str, optional) – Type of image funneling to use, support
'original','funneled'or'deepfunneled'. Default:None, will use'funneled'.num_samples (int, optional) – The number of images to be included in the dataset. Default:
None, all images.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (bool, optional) – Whether or not to perform shuffle on the dataset. Default:
None, expected order behavior shown in the table below.decode (bool, optional) – Decode the images after reading. Default:
False.sampler (Sampler, optional) – Object used to choose samples from the dataset. Default:
None, expected order behavior shown in the table below.num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the max sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards. Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir does not contain data files.
RuntimeError – If sampler and shuffle are specified at the same time.
RuntimeError – If sampler and sharding are specified at the same time.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If shard_id is invalid (< 0 or >= num_shards ).
- Tutorial Examples:
Note
The parameters num_samples , shuffle , num_shards , shard_id can be used to control the sampler used in the dataset, and their effects when combined with parameter sampler are as follows.
Examples
>>> import mindspore.dataset as ds >>> # 1) Read LFW People dataset >>> lfw_people_dataset_dir = "/path/to/lfw_people_dataset_directory" >>> dataset = ds.LFWDataset(dataset_dir=lfw_people_dataset_dir, task="people", usage="10fold", ... image_set="original") >>> >>> # 2) Read LFW Pairs dataset >>> lfw_pairs_dataset_dir = "/path/to/lfw_pairs_dataset_directory" >>> dataset = ds.LFWDataset(dataset_dir=lfw_pairs_dataset_dir, task="pairs", usage="test", image_set="funneled")
About LFW dataset:
LFW (Labeled Faces in the Wild) dataset is one of the most commonly used and widely open datasets in the field of face recognition. It was released by Gary B. Huang and his team at Massachusetts Institute of Technology in 2007. The dataset includes nearly 50,000 images of 13,233 individuals, which are sourced from various internet platforms and contain diverse environmental factors such as different poses, lighting conditions, and angles. Most of the images in the dataset are frontal and cover a wide range of ages, genders, and ethnicities.
You can unzip the original LFW dataset files into this directory structure and read by MindSpore's API.
. └── lfw_dataset_directory ├── lfw │ ├──Aaron_Eckhart │ │ ├──Aaron_Eckhart_0001.jpg │ │ ├──... │ ├──Abbas_Kiarostami │ │ ├── Abbas_Kiarostami_0001.jpg │ │ ├──... │ ├──... ├── lfw-deepfunneled │ ├──Aaron_Eckhart │ │ ├──Aaron_Eckhart_0001.jpg │ │ ├──... │ ├──Abbas_Kiarostami │ │ ├── Abbas_Kiarostami_0001.jpg │ │ ├──... │ ├──... ├── lfw_funneled │ ├──Aaron_Eckhart │ │ ├──Aaron_Eckhart_0001.jpg │ │ ├──... │ ├──Abbas_Kiarostami │ │ ├── Abbas_Kiarostami_0001.jpg │ │ ├──... │ ├──... ├── lfw-names.txt ├── pairs.txt ├── pairsDevTest.txt ├── pairsDevTrain.txt ├── people.txt ├── peopleDevTest.txt ├── peopleDevTrain.txtCitation:
@TechReport{LFWTech, title={LFW: A Database for Studying Recognition in Unconstrained Environments}, author={Gary B. Huang and Manu Ramesh and Tamara Berg and Erik Learned-Miller}, institution ={University of Massachusetts, Amherst}, year={2007}, number={07-49}, month={October}, howpublished = {http://vis-www.cs.umass.edu/lfw} }
- class mindspore.dataset.LJSpeechDataset(dataset_dir, num_samples=None, num_parallel_workers=None, shuffle=None, sampler=None, num_shards=None, shard_id=None, cache=None)[source]
LJSpeech dataset.
The generated dataset has four columns
[waveform, sample_rate, transcription, normalized_transcript]. The columnwaveformis a tensor of the float32 type. The columnsample_rateis a scalar of the int32 type. The columntranscriptionis a scalar of the string type. The columnnormalized_transcriptis a scalar of the string type.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
num_samples (int, optional) – The number of audio to be included in the dataset. Default:
None, will read all audio.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (bool, optional) – Whether to perform shuffle on the dataset. Default:
None, expected order behavior shown in the table below.sampler (Sampler, optional) – Object used to choose samples from the dataset. Default:
None, expected order behavior shown in the table below.num_shards (int, optional) –
Number of shards that the dataset will be divided into during distributed training. Default:
None. When this argument is specified, num_samples reflects the maximum sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir does not contain data files.
RuntimeError – If sampler and shuffle are specified at the same time.
RuntimeError – If sampler and num_shards/shard_id are specified at the same time.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If num_parallel_workers exceeds the max thread numbers.
ValueError – If shard_id is not in range of [0, num_shards ).
- Tutorial Examples:
Note
The parameters num_samples , shuffle , num_shards , shard_id can be used to control the sampler used in the dataset, and their effects when combined with parameter sampler are as follows.
Examples
>>> import mindspore.dataset as ds >>> lj_speech_dataset_dir = "/path/to/lj_speech_dataset_directory" >>> >>> # 1) Get all samples from LJSPEECH dataset in sequence >>> dataset = ds.LJSpeechDataset(dataset_dir=lj_speech_dataset_dir, shuffle=False) >>> >>> # 2) Randomly select 350 samples from LJSPEECH dataset >>> dataset = ds.LJSpeechDataset(dataset_dir=lj_speech_dataset_dir, num_samples=350, shuffle=True) >>> >>> # 3) Get samples from LJSPEECH dataset for shard 0 in a 2-way distributed training >>> dataset = ds.LJSpeechDataset(dataset_dir=lj_speech_dataset_dir, num_shards=2, shard_id=0) >>> >>> # In LJSPEECH dataset, each dictionary has keys "waveform", "sample_rate", "transcription" >>> # and "normalized_transcript"
About LJSPEECH dataset:
This is a public domain speech dataset consisting of 13,100 short audio clips of a single speaker reading passages from 7 non-fiction books. A transcription is provided for each clip. Clips vary in length from 1 to 10 seconds and have a total length of approximately 24 hours.
The texts were published between 1884 and 1964, and are in the public domain. The audio was recorded in 2016-17 by the LibriVox project and is also in the public domain.
Here is the original LJSPEECH dataset structure. You can unzip the dataset files into the following directory structure and read by MindSpore's API.
. └── LJSpeech-1.1 ├── README ├── metadata.csv └── wavs ├── LJ001-0001.wav ├── LJ001-0002.wav ├── LJ001-0003.wav ├── LJ001-0004.wav ├── LJ001-0005.wav ├── LJ001-0006.wav ├── LJ001-0007.wav ├── LJ001-0008.wav ... ├── LJ050-0277.wav └── LJ050-0278.wavCitation:
@misc{lj_speech17, author = {Keith Ito and Linda Johnson}, title = {The LJ Speech Dataset}, howpublished = {url{https://keithito.com/LJ-Speech-Dataset}}, year = 2017 }
- class mindspore.dataset.LSUNDataset(dataset_dir, usage=None, classes=None, num_samples=None, num_parallel_workers=None, shuffle=None, decode=False, sampler=None, num_shards=None, shard_id=None, cache=None)[source]
LSUN(Large-Scale Scene Understanding) dataset.
The generated dataset has two columns:
[image, label]. The tensor of columnimageis of the uint8 type. The tensor of columnlabelis a scalar of uint32 type.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
usage (str, optional) – Usage of this dataset, can be
"train","test","valid"or"all". Default:None, will be set to"all".classes (Union[str, list[str]], optional) – Choose the specific classes to load. Default:
None, means loading all classes in root directory.num_samples (int, optional) – The number of images to be included in the dataset. Default:
None, all images.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (bool, optional) – Whether or not to perform shuffle on the dataset. Default:
None, expected order behavior shown in the table below.decode (bool, optional) – Decode the images after reading. Default:
False.sampler (Sampler, optional) – Object used to choose samples from the dataset. Default:
None, expected order behavior shown in the table below.num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the max sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards. Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir does not contain data files.
RuntimeError – If sampler and shuffle are specified at the same time.
RuntimeError – If sampler and sharding are specified at the same time.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If shard_id is invalid (< 0 or >= num_shards ).
ValueError – If usage or classes is invalid (not in specific types).
- Tutorial Examples:
Note
The parameters num_samples , shuffle , num_shards , shard_id can be used to control the sampler used in the dataset, and their effects when combined with parameter sampler are as follows.
Examples
>>> import mindspore.dataset as ds >>> lsun_dataset_dir = "/path/to/lsun_dataset_directory" >>> >>> # 1) Read all samples (image files) in lsun_dataset_dir with 8 threads >>> dataset = ds.LSUNDataset(dataset_dir=lsun_dataset_dir, ... num_parallel_workers=8) >>> >>> # 2) Read all train samples (image files) from folder "bedroom" and "classroom" >>> dataset = ds.LSUNDataset(dataset_dir=lsun_dataset_dir, usage="train", ... classes=["bedroom", "classroom"])
About LSUN dataset:
The LSUN (Large-Scale Scene Understanding) is a large-scale dataset used for indoors scene understanding. It was originally launched by Stanford University in 2015 with the aim of providing a challenging and diverse dataset for research in computer vision and machine learning. The main application of this dataset for research is indoor scene analysis.
This dataset contains ten different categories of scenes, including bedrooms, living rooms, restaurants, lounges, studies, kitchens, bathrooms, corridors, children's room, and outdoors. Each category contains tens of thousands of images from different perspectives, and these images are high-quality, high-resolution real-world images.
You can unzip the dataset files into this directory structure and read by MindSpore's API.
. └── lsun_dataset_directory ├── test │ ├── ... ├── bedroom_train │ ├── 1_1.jpg │ ├── 1_2.jpg ├── bedroom_val │ ├── ... ├── classroom_train │ ├── ... ├── classroom_val │ ├── ...Citation:
article{yu15lsun, title={LSUN: Construction of a Large-scale Image Dataset using Deep Learning with Humans in the Loop}, author={Yu, Fisher and Zhang, Yinda and Song, Shuran and Seff, Ari and Xiao, Jianxiong}, journal={arXiv preprint arXiv:1506.03365}, year={2015} }
- class mindspore.dataset.LibriTTSDataset(dataset_dir, usage=None, num_samples=None, num_parallel_workers=None, shuffle=None, sampler=None, num_shards=None, shard_id=None, cache=None)[source]
LibriTTS dataset.
The generated dataset has seven columns
[waveform, sample_rate, original_text, normalized_text, speaker_id, chapter_id, utterance_id]. The tensor of columnwaveformis of the float32 type. The tensor of columnsample_rateis of a scalar of uint32 type. The tensor of columnoriginal_textis of a scalar of string type. The tensor of columnnormalized_textis of a scalar of string type. The tensor of columnspeaker_idis of a scalar of uint32 type. The tensor of columnchapter_idis of a scalar of uint32 type. The tensor of columnutterance_idis of a scalar of string type.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
usage (str, optional) – Part of this dataset, can be
'dev-clean','dev-other','test-clean','test-other','train-clean-100','train-clean-360','train-other-500', or'all'. Default:None, means'all'.num_samples (int, optional) – The number of audio to be included in the dataset. Default:
None, will read all audio.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (bool, optional) – Whether or not to perform shuffle on the dataset. Default:
None, expected order behavior shown in the table below.sampler (Sampler, optional) – Object used to choose samples from the dataset. Default:
None, expected order behavior shown in the table below.num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the maximum sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir does not contain data files.
ValueError – If num_parallel_workers exceeds the max thread numbers.
RuntimeError – If sampler and shuffle are specified at the same time.
RuntimeError – If sampler and num_shards/shard_id are specified at the same time.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If shard_id is not in range of [0, num_shards ).
- Tutorial Examples:
Note
Does not support
mindspore.dataset.PKSamplerfor sampler parameter yet.The parameters num_samples , shuffle , num_shards , shard_id can be used to control the sampler used in the dataset, and their effects when combined with parameter sampler are as follows.
Examples
>>> import mindspore.dataset as ds >>> libri_tts_dataset_dir = "/path/to/libri_tts_dataset_directory" >>> >>> # 1) Read 500 samples (audio files) in libri_tts_dataset_directory >>> dataset = ds.LibriTTSDataset(libri_tts_dataset_dir, usage="train-clean-100", num_samples=500) >>> >>> # 2) Read all samples (audio files) in libri_tts_dataset_directory >>> dataset = ds.LibriTTSDataset(libri_tts_dataset_dir)
About LibriTTS dataset:
LibriTTS is a multi-speaker English corpus of approximately 585 hours of read English speech at 24kHz sampling rate, prepared by Heiga Zen with the assistance of Google Speech and Google Brain team members. The LibriTTS corpus is designed for TTS research. It is derived from the original materials (mp3 audio files from LibriVox and text files from Project Gutenberg) of the LibriSpeech corpus.
You can construct the following directory structure from LibriTTS dataset and read by MindSpore's API.
. └── libri_tts_dataset_directory ├── dev-clean │ ├── 116 │ │ ├── 288045 | | | ├── 116_288045.trans.tsv │ │ │ ├── 116_288045_000003_000000.wav │ │ │ └──... │ │ ├── 288046 | | | ├── 116_288046.trans.tsv | | | ├── 116_288046_000003_000000.wav │ | | └── ... | | └── ... │ ├── 1255 │ │ ├── 138279 | | | ├── 1255_138279.trans.tsv │ │ │ ├── 1255_138279_000001_000000.wav │ │ │ └── ... │ │ ├── 74899 | | | ├── 1255_74899.trans.tsv | | | ├── 1255_74899_000001_000000.wav │ | | └── ... | | └── ... | └── ... └── ...Citation:
@article{lecun2010mnist, title = {LIBRITTS handwritten digit database}, author = {zpw, NBU}, journal = {ATT Labs [Online]}, volume = {2}, year = {2010}, howpublished = {http://www.openslr.org/resources/60/}, description = {The LibriSpeech ASR corpus (http://www.openslr.org/12/) [1] has been used in various research projects. However, as it was originally designed for ASR research, there are some undesired properties when using for TTS research} }
- class mindspore.dataset.ManifestDataset(dataset_file, usage='train', num_samples=None, num_parallel_workers=None, shuffle=None, sampler=None, class_indexing=None, decode=False, num_shards=None, shard_id=None, cache=None)[source]
A source dataset for reading images from a Manifest file.
The generated dataset has two columns:
[image, label]. The tensor of columnimageis of the uint8 type. The tensor of columnlabelis a scalar of uint64 type.- Parameters:
dataset_file (str) – File to be read.
usage (str, optional) – Acceptable usages include
'train','eval'and'inference'. Default:'train'.num_samples (int, optional) – The number of images to be included in the dataset. Default:
None, will include all images.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (bool, optional) – Whether to perform shuffle on the dataset. Default:
None, expected order behavior shown in the table below.sampler (Sampler, optional) – Object used to choose samples from the dataset. Default:
None, expected order behavior shown in the table below.class_indexing (dict, optional) – A str-to-int mapping from label name to index. Default:
None, the folder names will be sorted alphabetically and each class will be given a unique index starting from 0.decode (bool, optional) – Decode the images after reading. Default:
False.num_shards (int, optional) –
Number of shards that the dataset will be divided into during distributed training. Default:
None. When this argument is specified, num_samples reflects the max number of samples per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_file are not valid or do not exist.
RuntimeError – If sampler and shuffle are specified at the same time.
RuntimeError – If sampler and num_shards/shard_id are specified at the same time.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
RuntimeError – If class_indexing is not a dictionary.
ValueError – If num_parallel_workers exceeds the max thread numbers.
ValueError – If shard_id is not in range of [0, num_shards ).
- Tutorial Examples:
Note
If decode is
False, the "image" column will get the 1D raw bytes of the image. Otherwise, a decoded image with shape \([H,W,C]\) will be returned.The parameters num_samples , shuffle , num_shards , shard_id can be used to control the sampler used in the dataset, and their effects when combined with parameter sampler are as follows.
Examples
>>> import mindspore.dataset as ds >>> manifest_dataset_dir = "/path/to/manifest_dataset_file" >>> >>> # 1) Read all samples specified in manifest_dataset_dir dataset with 8 threads for training >>> dataset = ds.ManifestDataset(dataset_file=manifest_dataset_dir, usage="train", num_parallel_workers=8) >>> >>> # 2) Read samples (specified in manifest_file.manifest) for shard 0 in a 2-way distributed training setup >>> dataset = ds.ManifestDataset(dataset_file=manifest_dataset_dir, num_shards=2, shard_id=0)
About Manifest dataset:
Manifest file contains a list of files included in a dataset, including basic file info such as File name and File ID, along with extended file metadata. Manifest is a data format file supported by Huawei Modelarts. For details, see Specifications for Importing the Manifest File .
. └── manifest_dataset_directory ├── train │ ├── 1.JPEG │ ├── 2.JPEG │ ├── ... ├── eval │ ├── 1.JPEG │ ├── 2.JPEG │ ├── ...- get_class_indexing()[source]
Get the class index.
- Returns:
dict, a str-to-int mapping from label name to index.
Examples
>>> import mindspore.dataset as ds >>> manifest_dataset_dir = "/path/to/manifest_dataset_file" >>> >>> dataset = ds.ManifestDataset(dataset_file=manifest_dataset_dir) >>> class_indexing = dataset.get_class_indexing()
- class mindspore.dataset.MindDataset(dataset_files, columns_list=None, num_parallel_workers=None, shuffle=None, num_shards=None, shard_id=None, sampler=None, padded_sample=None, num_padded=None, num_samples=None, cache=None)[source]
A source dataset that reads and parses MindRecord dataset.
The columns of generated dataset depend on the source MindRecord files.
- Parameters:
dataset_files (Union[str, list[str]]) – If dataset_file is a str, it represents for a file name of one component of a mindrecord source, other files with identical source in the same path will be found and loaded automatically. If dataset_file is a list, it represents for a list of dataset files to be read directly.
columns_list (list[str], optional) – List of columns to be read. Default:
None, read all columns.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (Union[bool, Shuffle], optional) –
Perform reshuffling of the data every epoch, bool type and
Shuffleenum are both supported to pass in. Default:None, performsmindspore.dataset.Shuffle.ADAPTIVE. If shuffle is set toFalse, no shuffling will be performed. If shuffle is set toTrue, shuffle is set tomindspore.dataset.Shuffle.ADAPTIVE. There are several levels of shuffling, desired shuffle enum defined bymindspore.dataset.Shuffle.Shuffle.ADAPTIVE: When the number of dataset samples is less than or equal to 100 million,Shuffle.GLOBALis used. When the number of dataset samples is greater than 100 million,Shuffle.PARTIALis used. The shuffle is performed once every 1 million samples.Shuffle.GLOBAL: Global shuffle of all rows of data in dataset. The memory usage is large.Shuffle.PARTIAL: Partial shuffle of data in dataset for every 1 million samples. The memory usage is less thanShuffle.GLOBAL.Shuffle.FILES: Shuffle the file sequence but keep the order of data within each file.Shuffle.INFILE: Keep the file sequence the same but shuffle the data within each file.
num_shards (int, optional) –
Number of shards that the dataset will be divided into during distributed training. Default:
None. When this argument is specified, num_samples reflects the maximum sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.sampler (Sampler, optional) – Object used to choose samples from the dataset. Default:
None, sampler is exclusive with shuffle. Support list:mindspore.dataset.SubsetRandomSampler,mindspore.dataset.PKSampler,mindspore.dataset.RandomSampler,mindspore.dataset.SequentialSampler,mindspore.dataset.DistributedSampler.padded_sample (dict, optional) – Samples will be appended to dataset, where keys are the same as columns_list. Default:
None.num_padded (int, optional) – Number of padding samples. Dataset size plus num_padded should be divisible by num_shards. Default:
None.num_samples (int, optional) – The number of samples to be included in the dataset. Default:
None, all samples.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
ValueError – If dataset_files are not valid or do not exist.
ValueError – If num_parallel_workers exceeds the max thread numbers.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If shard_id is not in range of [0, num_shards ).
TypeError – If shuffle is not of type None, bool or Shuffle.
Note
When sharding MindRecord (by configuring num_shards and shard_id), there are two strategies to implement the data sharding logic. This API uses the strategy 1 by default, which can be switched to strategy 2 by setting the environment variable MS_DEV_MINDRECORD_SHARD_BY_BLOCK=True . This environment variable only applies to the DistributedSampler sampler.
Data sharding strategy 1 rank 0
rank 1
rank 2
rank 3
0
1
2
3
4
5
6
7
8
9
10
11
Data sharding strategy 2 rank 0
rank 1
rank 2
rank 3
0
3
6
9
1
4
7
10
2
5
8
11
Note
The parameters num_samples , shuffle , num_shards , shard_id can be used to control the sampler used in the dataset, and their effects when combined with parameter sampler are as follows.
Examples
>>> import mindspore.dataset as ds >>> mindrecord_files = ["/path/to/mind_dataset_file"] # contains 1 or multiple MindRecord files >>> dataset = ds.MindDataset(dataset_files=mindrecord_files)
- class mindspore.dataset.MnistDataset(dataset_dir, usage=None, num_samples=None, num_parallel_workers=None, shuffle=None, sampler=None, num_shards=None, shard_id=None, cache=None)[source]
MNIST dataset.
The generated dataset has two columns
[image, label]. The tensor of columnimageis of the uint8 type. The tensor of columnlabelis a scalar of the uint32 type.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
usage (str, optional) – Usage of this dataset, can be
'train','test'or'all'.'train'will read from 60,000 train samples,'test'will read from 10,000 test samples,'all'will read from all 70,000 samples. Default:None, will read all samples.num_samples (int, optional) – The number of images to be included in the dataset. Default:
None, will read all images.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (bool, optional) – Whether or not to perform shuffle on the dataset. Default:
None, expected order behavior shown in the table below.sampler (Sampler, optional) – Object used to choose samples from the dataset. Default:
None, expected order behavior shown in the table below.num_shards (int, optional) –
Number of shards that the dataset will be divided into during distributed training. Default:
None. When this argument is specified, num_samples reflects the maximum sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir does not contain data files.
RuntimeError – If sampler and shuffle are specified at the same time.
RuntimeError – If both the sampler and num_shards parameters are specified, or both the sampler and shard_id parameters are specified.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If num_parallel_workers exceeds the max thread numbers.
ValueError – If usage is not
'train','test'or'all'.ValueError – If shard_id is not in range of [0, num_shards ).
- Tutorial Examples:
Note
The parameters num_samples , shuffle , num_shards , shard_id can be used to control the sampler used in the dataset, and their effects when combined with parameter sampler are as follows.
Examples
>>> import mindspore.dataset as ds >>> mnist_dataset_dir = "/path/to/mnist_dataset_directory" >>> >>> # Read 3 samples from MNIST dataset >>> dataset = ds.MnistDataset(dataset_dir=mnist_dataset_dir, num_samples=3) >>> >>> # Note: In mnist_dataset dataset, each dictionary has keys "image" and "label"
About MNIST dataset:
The MNIST database of handwritten digits has a training set of 60,000 examples, and a test set of 10,000 examples. It is a subset of a larger set available from NIST. The digits have been size-normalized and centered in a fixed-size image.
Here is the original MNIST dataset structure. You can unzip the dataset files into this directory structure and read by MindSpore's API.
. └── mnist_dataset_dir ├── t10k-images-idx3-ubyte ├── t10k-labels-idx1-ubyte ├── train-images-idx3-ubyte └── train-labels-idx1-ubyteCitation:
@article{lecun2010mnist, title = {MNIST handwritten digit database}, author = {LeCun, Yann and Cortes, Corinna and Burges, CJ}, journal = {ATT Labs [Online]}, volume = {2}, year = {2010}, howpublished = {http://yann.lecun.com/exdb/mnist} }
- class mindspore.dataset.Multi30kDataset(dataset_dir, usage=None, language_pair=None, num_samples=None, num_parallel_workers=None, shuffle=None, num_shards=None, shard_id=None, cache=None)[source]
Multi30k dataset.
The generated dataset has two columns
[text, translation]. The tensor of columntextis of the string type. The tensor of columntranslationis of the string type.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
usage (str, optional) – Acceptable usages include
'train','test','valid'or'all'. Default:None, will read all samples.language_pair (Sequence[str, str], optional) – Acceptable language_pair include
['en', 'de'],['de', 'en']. Default:None, means['en', 'de'].num_samples (int, optional) – The number of samples to be included in the dataset. Default:
None, will read all samples.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (Union[bool, Shuffle], optional) –
Perform reshuffling of the data every epoch. Bool type and Shuffle enum are both supported to pass in. Default:
Shuffle.GLOBAL. If shuffle isFalse, no shuffling will be performed. If shuffle isTrue, it is equivalent to setting shuffle toShuffle.GLOBAL. Set the mode of data shuffling by passing in enumeration variables:Shuffle.GLOBAL: Shuffle both the files and samples.Shuffle.FILES: Shuffle files only.
num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the max sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir does not contain data files.
RuntimeError – If num_samples is less than 0.
RuntimeError – If num_parallel_workers exceeds the max thread numbers.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If shard_id is not in range of [0, num_shards ).
ValueError – If usage is not
'train','test','valid'or'all'.TypeError – If language_pair is not of type Sequence[str, str].
- Tutorial Examples:
Examples
>>> import mindspore.dataset as ds >>> multi30k_dataset_dir = "/path/to/multi30k_dataset_directory" >>> data = ds.Multi30kDataset(dataset_dir=multi30k_dataset_dir, usage='all', language_pair=['de', 'en'])
About Multi30k dataset:
Multi30K is a multilingual dataset that features approximately 31,000 standardized images described in multiple languages. The images are sourced from Flickr and each image comes with sentence descriptions in both English and German, as well as descriptions in other languages. Multi30k is used primarily for training and testing in tasks such as image captioning, machine translation, and visual question answering.
You can unzip the dataset files into the following directory structure and read by MindSpore's API.
└── multi30k_dataset_directory ├── training │ ├── train.de │ └── train.en ├── validation │ ├── val.de │ └── val.en └── mmt16_task1_test ├── val.de └── val.enCitation:
@article{elliott-EtAl:2016:VL16, author = {{Elliott}, D. and {Frank}, S. and {Sima'an}, K. and {Specia}, L.}, title = {Multi30K: Multilingual English-German Image Descriptions}, booktitle = {Proceedings of the 5th Workshop on Vision and Language}, year = {2016}, pages = {70--74}, year = 2016 }
- class mindspore.dataset.NumpySlicesDataset(data, column_names=None, num_samples=None, num_parallel_workers=1, shuffle=None, sampler=None, num_shards=None, shard_id=None)[source]
Creates a dataset with given data slices, mainly for loading Python data into dataset.
The column names and column types of generated dataset depend on Python data defined by users.
- Parameters:
data (Union[list, tuple, dict]) – Input of given data. Supported data types include: list, tuple, dict and other NumPy formats. Input data will be sliced along the first dimension and generate additional rows, if input is list, there will be one column in each row, otherwise there tends to be multi columns. Large data is not recommended to be loaded in this way as data is loading into memory.
column_names (list[str], optional) – List of column names of the dataset. Default:
None. If column_names is not provided, the output column names will be named as the keys of dict when the input data is a dict, otherwise they will be named like column_0, column_1 …num_samples (int, optional) – The number of samples to be included in the dataset. Default:
None, all samples.num_parallel_workers (int, optional) – Number of worker subprocesses used to fetch the dataset in parallel. Default:
1.shuffle (bool, optional) – Whether or not to perform shuffle on the dataset. Only specify the data parameter if it has a random-access property (__getitem__). Default:
None, expected order behavior shown in the table below.sampler (Union[Sampler, Iterable], optional) – Object used to choose samples from the dataset. Only specify the data parameter if it has a random-access property (__getitem__). Default:
None, expected order behavior shown in the table below.num_shards (int, optional) –
Number of shards that the dataset will be divided into during distributed training. Default:
None. When this argument is specified, num_samples reflects the max sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument must be specified only when num_shards is also specified.
Note
The parameters num_samples , shuffle , num_shards , shard_id can be used to control the sampler used in the dataset, and their effects when combined with parameter sampler are as follows.
- Raises:
RuntimeError – If len of column_names does not match output len of data.
ValueError – If num_parallel_workers exceeds the max thread numbers.
ValueError – If sampler and shuffle are specified at the same time.
ValueError – If both the sampler and num_shards parameters are specified, or both the sampler and shard_id parameters are specified.
ValueError – If num_shards is specified but shard_id is None.
ValueError – If shard_id is specified but num_shards is None.
ValueError – If shard_id is not in range of [0, num_shards ).
- Tutorial Examples:
Examples
>>> import mindspore.dataset as ds >>> # 1) Input data can be a list >>> data = [1, 2, 3] >>> dataset = ds.NumpySlicesDataset(data=data, column_names=["column_1"]) >>> >>> # 2) Input data can be a dictionary, and column_names will be its keys >>> data = {"a": [1, 2], "b": [3, 4]} >>> dataset = ds.NumpySlicesDataset(data=data) >>> >>> # 3) Input data can be a tuple of lists (or NumPy arrays), each tuple element refers to data in each column >>> data = ([1, 2], [3, 4], [5, 6]) >>> dataset = ds.NumpySlicesDataset(data=data, column_names=["column_1", "column_2", "column_3"]) >>> >>> # 4) Load data from CSV file >>> import pandas as pd >>> df = pd.read_csv(filepath_or_buffer=csv_dataset_dir[0]) >>> dataset = ds.NumpySlicesDataset(data=dict(df), shuffle=False)
- class mindspore.dataset.OBSMindDataset(dataset_files, server, ak, sk, sync_obs_path, columns_list=None, shuffle=Shuffle.GLOBAL, num_shards=None, shard_id=None, shard_equal_rows=True)[source]
A source dataset that reads and parses MindRecord dataset which stored in cloud storage such as OBS, Minio or AWS S3.
The columns of generated dataset depend on the source MindRecord files.
Note
This interface accesses the /cache directory for node synchronization and requires the user to ensure access to the /cache directory.
- Parameters:
dataset_files (list[str]) – List of files in cloud storage to be read and file path is in the format of s3://bucketName/objectKey.
server (str) – Endpoint for accessing cloud storage. If it's OBS Service of Huawei Cloud, the endpoint is like
<obs.cn-north-4.myhuaweicloud.com>(Region cn-north-4). If it's Minio which starts locally, the endpoint is like<https://127.0.0.1:9000>.ak (str) – The access key ID used to access the OBS data.
sk (str) – The secret access key used to access the OBS data.
sync_obs_path (str) – Remote dir path used for synchronization, users need to create it on cloud storage in advance. Path is in the format of s3://bucketName/objectKey.
columns_list (list[str], optional) – List of columns to be read. Default:
None, read all columns.shuffle (Union[bool, Shuffle], optional) –
Perform reshuffling of the data every epoch. Default:
Shuffle.GLOBAL. Bool type and Shuffle enum are both supported to pass in. If shuffle isFalse, no shuffling will be performed. If shuffle isTrue, performs global shuffle. There are three levels of shuffling, desired shuffle enum defined bymindspore.dataset.Shuffle.Shuffle.GLOBAL: Global shuffle of all rows of data in dataset, same as setting shuffle to True.Shuffle.FILES: Shuffle the file sequence but keep the order of data within each file.Shuffle.INFILE: Keep the file sequence the same but shuffle the data within each file.
num_shards (int, optional) –
Number of shards that the dataset will be divided into during distributed training. Default:
None. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards. Default:
None. This argument can only be specified when num_shards is also specified.shard_equal_rows (bool, optional) – Get equal rows for all shards. Default:
True. If shard_equal_rows is false, number of rows of each shard may be not equal, and may lead to a failure in distributed training. When the number of samples per MindRecord file are not equal, it is suggested to set toTrue. This argument should only be specified when num_shards is also specified.
- Raises:
RuntimeError – If sync_obs_path does not exist.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If columns_list is invalid.
ValueError – If shard_id is not in range of [0, num_shards ).
Note
It's necessary to create a synchronization directory on cloud storage in advance which be defined by parameter: sync_obs_path .
If training is offline(no cloud), it's recommended to set the environment variable BATCH_JOB_ID .
In distributed training, if there are multiple nodes(servers), all 8 devices must be used in each node(server). If there is only one node(server), there is no such restriction.
Examples
>>> import mindspore.dataset as ds >>> # OBS >>> bucket = "iris" # your obs bucket name >>> # the bucket directory structure is similar to the following: >>> # - imagenet21k >>> # | - mr_imagenet21k_01 >>> # | - mr_imagenet21k_02 >>> # - sync_node >>> dataset_obs_dir = ["s3://" + bucket + "/imagenet21k/mr_imagenet21k_01", ... "s3://" + bucket + "/imagenet21k/mr_imagenet21k_02"] >>> sync_obs_dir = "s3://" + bucket + "/sync_node" >>> num_shards = 8 >>> shard_id = 0 >>> dataset = ds.OBSMindDataset(dataset_obs_dir, "obs.cn-north-4.myhuaweicloud.com", ... "AK of OBS", "SK of OBS", ... sync_obs_dir, shuffle=True, num_shards=num_shards, shard_id=shard_id)
- class mindspore.dataset.OmniglotDataset(dataset_dir, background=None, num_samples=None, num_parallel_workers=None, shuffle=None, decode=False, sampler=None, num_shards=None, shard_id=None, cache=None)[source]
Omniglot dataset.
The generated dataset has two columns
[image, label]. The tensor of columnimageis of the uint8 type. The tensor of columnlabelis a scalar of the uint32 type.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
background (bool, optional) – Whether to create dataset from the "background" set. Otherwise create from the "evaluation" set. Default:
None, set toTrue.num_samples (int, optional) – The number of images to be included in the dataset. Default:
None, all images.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (bool, optional) – Whether or not to perform shuffle on the dataset. Default:
None, expected order behavior shown in the table below.decode (bool, optional) – Decode the images after reading. Default:
False.sampler (Sampler, optional) – Object used to choose samples from the dataset. Default:
None, expected order behavior shown in the table below.num_shards (int, optional) –
Number of shards that the dataset will be divided into during distributed training. Default:
None. When this argument is specified, num_samples reflects the max sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards. Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir does not contain data files.
RuntimeError – If sampler and shuffle are specified at the same time.
RuntimeError – If sampler and sharding are specified at the same time.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If shard_id is not in range of [0, num_shards ).
- Tutorial Examples:
Note
The parameters num_samples , shuffle , num_shards , shard_id can be used to control the sampler used in the dataset, and their effects when combined with parameter sampler are as follows.
Examples
>>> import mindspore.dataset as ds >>> omniglot_dataset_dir = "/path/to/omniglot_dataset_directory" >>> dataset = ds.OmniglotDataset(dataset_dir=omniglot_dataset_dir, ... num_parallel_workers=8)
About Omniglot dataset:
The Omniglot dataset is designed for developing more human-like learning algorithms. It contains 1623 different handwritten characters from 50 different alphabets. Each of the 1623 characters was drawn online via Amazon's Mechanical Turk by 20 different people. Each image is paired with stroke data, a sequences of [x, y, t] coordinates with time in milliseconds.
You can unzip the original Omniglot dataset files into this directory structure and read by MindSpore's API.
. └── omniglot_dataset_directory ├── images_background/ │ ├── character_class1/ │ ├──── 01.jpg │ ├──── 02.jpg │ ├── character_class2/ │ ├──── 01.jpg │ ├──── 02.jpg │ ├── ... ├── images_evaluation/ │ ├── character_class1/ │ ├──── 01.jpg │ ├──── 02.jpg │ ├── character_class2/ │ ├──── 01.jpg │ ├──── 02.jpg │ ├── ...Citation:
@article{lake2015human, title={Human-level concept learning through probabilistic program induction}, author={Lake, Brenden M and Salakhutdinov, Ruslan and Tenenbaum, Joshua B}, journal={Science}, volume={350}, number={6266}, pages={1332--1338}, year={2015}, publisher={American Association for the Advancement of Science} }
- class mindspore.dataset.PKSampler(num_val, num_class=None, shuffle=False, class_column='label', num_samples=None)[source]
Samples K elements for each P class in the dataset.
- Parameters:
num_val (int) – Number of elements to sample for each class.
num_class (int, optional) – Number of classes to sample. Default:
None, sample all classes. This parameter is not currently supported.shuffle (bool, optional) – Whether to shuffle the class IDs. Default:
False.class_column (str, optional) – Name of column with class labels for MindDataset. Default:
'label'.num_samples (int, optional) – The number of samples to draw. Default:
None, which means sample all elements.
- Raises:
TypeError – If shuffle is not of type bool.
TypeError – If class_column is not of type str.
TypeError – If num_samples is not of type int.
NotImplementedError – If num_class is not
None.RuntimeError – If num_val is not a positive value.
ValueError – If num_samples is a negative value.
Examples
>>> import mindspore.dataset as ds >>> # creates a PKSampler that will get 3 samples from every class. >>> sampler = ds.PKSampler(3) >>> dataset = ds.ImageFolderDataset(image_folder_dataset_dir, ... num_parallel_workers=8, ... sampler=sampler)
- class mindspore.dataset.PaddedDataset(padded_samples)[source]
Creates a dataset with filler data provided by user.
Mainly used to add samples to the original dataset for distributed training, so that samples can be evenly distributed across shards.
- Parameters:
- Raises:
TypeError – If padded_samples is not an instance of list.
TypeError – If the element of padded_samples is not an instance of dict.
ValueError – If the padded_samples is empty.
- Tutorial Examples:
Examples
>>> import mindspore.dataset as ds >>> import numpy as np >>> data = [{'image': np.zeros(1, np.uint8)}, {'image': np.zeros(2, np.uint8)}] >>> dataset = ds.PaddedDataset(padded_samples=data)
- class mindspore.dataset.PennTreebankDataset(dataset_dir, usage=None, num_samples=None, num_parallel_workers=None, shuffle=Shuffle.GLOBAL, num_shards=None, shard_id=None, cache=None)[source]
PennTreebank dataset.
The generated dataset has one column
[text]. The tensor of columntextis of the string type.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
usage (str, optional) – Acceptable usages include
'train','test','valid'and'all'.'train'will read from 42,068 train samples of string type,'test'will read from 3,370 test samples of string type,'valid'will read from 3,761 test samples of string type,'all'will read from all 49,199 samples of string type. Default:None, all samples.num_samples (int, optional) – Number of samples (rows) to read. Default:
None, reads the full dataset.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (Union[bool, Shuffle], optional) –
Perform reshuffling of the data every epoch. Bool type and Shuffle enum are both supported to pass in. Default:
Shuffle.GLOBAL. If shuffle isFalse, no shuffling will be performed. If shuffle isTrue, it is equivalent to setting shuffle toShuffle.GLOBAL. Set the mode of data shuffling by passing in enumeration variables:Shuffle.GLOBAL: Shuffle both the files and samples.Shuffle.FILES: Shuffle files only.
num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the max sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir does not contain data files.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If num_parallel_workers exceeds the max thread numbers.
- Tutorial Examples:
Examples
>>> import mindspore.dataset as ds >>> penn_treebank_dataset_dir = "/path/to/penn_treebank_dataset_directory" >>> dataset = ds.PennTreebankDataset(dataset_dir=penn_treebank_dataset_dir, usage='all')
About PennTreebank dataset:
Penn Treebank (PTB) dataset, is widely used in machine learning for NLP (Natural Language Processing) research. Word-level PTB does not contain capital letters, numbers, and punctuation, and the vocabulary is capped at 10k unique words, which is relatively small in comparison to most modern datasets which can result in a larger number of out of vocabulary tokens.
Here is the original PennTreebank dataset structure. You can unzip the dataset files into this directory structure and read by MindSpore's API.
. └── PennTreebank_dataset_dir ├── ptb.test.txt ├── ptb.train.txt └── ptb.valid.txtCitation:
@techreport{Santorini1990, added-at = {2014-03-26T23:25:56.000+0100}, author = {Santorini, Beatrice}, biburl = {https://www.bibsonomy.org/bibtex/234cdf6ddadd89376090e7dada2fc18ec/butonic}, file = {:Santorini - Penn Treebank tag definitions.pdf:PDF}, institution = {Department of Computer and Information Science, University of Pennsylvania}, interhash = {818e72efd9e4b5fae3e51e88848100a0}, intrahash = {34cdf6ddadd89376090e7dada2fc18ec}, keywords = {dis pos tagging treebank}, number = {MS-CIS-90-47}, timestamp = {2014-03-26T23:25:56.000+0100}, title = {Part-of-speech tagging guidelines for the {P}enn {T}reebank {P}roject}, url = {ftp://ftp.cis.upenn.edu/pub/treebank/doc/tagguide.ps.gz}, year = 1990 }
- class mindspore.dataset.PhotoTourDataset(dataset_dir, name, usage=None, num_samples=None, num_parallel_workers=None, shuffle=None, sampler=None, num_shards=None, shard_id=None, cache=None)[source]
PhotoTour dataset.
According to the given usage configuration, the generated dataset has different output columns:
When usage is
'train', output columns: [image, dtype=uint8] .When usage is not
'train', output columns: [image1, dtype=uint8] , [image2, dtype=uint8] , [matches, dtype=uint32] .
- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
name (str) – Name of the dataset to load, should be one of
'notredame','yosemite','liberty','notredame_harris','yosemite_harris'or'liberty_harris'.usage (str, optional) – Usage of the dataset, can be
'train'or'test'. Default:None, will be set to 'train'. When usage is 'train', number of samples for each name is {'notredame': 468159, 'yosemite': 633587, 'liberty': 450092, 'liberty_harris': 379587, 'yosemite_harris': 450912, 'notredame_harris': 325295}. When usage is 'test', will read 100,000 samples for testing.num_samples (int, optional) – The number of images to be included in the dataset. Default:
None, will read all images.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (bool, optional) – Whether or not to perform shuffle on the dataset. Default:
None, expected order behavior shown in the table below.sampler (Sampler, optional) – Object used to choose samples from the dataset. Default:
None, expected order behavior shown in the table below.num_shards (int, optional) –
Number of shards that the dataset will be divided into during distributed training. Default:
None. When this argument is specified, num_samples reflects the max sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir does not contain data files.
RuntimeError – If sampler and shuffle are specified at the same time.
RuntimeError – If sampler and num_shards/shard_id are specified at the same time.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If dataset_dir does not exist.
ValueError – If usage is not
'train'or'test'.ValueError – If name is not
'notredame','yosemite','liberty','notredame_harris','yosemite_harris'or'liberty_harris'.ValueError – If num_parallel_workers exceeds the max thread numbers.
ValueError – If shard_id is not in range of [0, num_shards ).
- Tutorial Examples:
Note
The parameters num_samples , shuffle , num_shards , shard_id can be used to control the sampler used in the dataset, and their effects when combined with parameter sampler are as follows.
Examples
>>> import mindspore.dataset as ds >>> # Read 3 samples from PhotoTour dataset. >>> dataset = ds.PhotoTourDataset(dataset_dir="/path/to/photo_tour_dataset_directory", ... name='liberty', usage='train', num_samples=3)
About PhotoTour dataset:
The data is taken from Photo Tourism reconstructions from Trevi Fountain (Rome), Notre Dame (Paris) and Half Dome (Yosemite). Each dataset consists of a series of corresponding patches, which are obtained by projecting 3D points from Photo Tourism reconstructions back into the original images.
The dataset consists of 1024 x 1024 bitmap (.bmp) images, each containing a 16 x 16 array of image patches. Each patch is sampled as 64 x 64 grayscale, with a canonical scale and orientation. For details of how the scale and orientation is established, please see the paper. An associated metadata file info.txt contains the match information. Each row of info.txt corresponds to a separate patch, with the patches ordered from left to right and top to bottom in each bitmap image. The first number on each row of info.txt is the 3D point ID from which that patch was sampled – patches with the same 3D point ID are projected from the same 3D point (into different images). The second number in info.txt corresponds to the image from which the patch was sampled, and is not used at present.
You can unzip the original PhotoTour dataset files into this directory structure and read by MindSpore's API.
. └── photo_tour_dataset_directory ├── liberty/ │ ├── info.txt // two columns: 3D_point_ID, unused │ ├── m50_100000_100000_0.txt // seven columns: patch_ID1, 3D_point_ID1, unused1, │ │ // patch_ID2, 3D_point_ID2, unused2, unused3 │ ├── patches0000.bmp // 1024*1024 pixels, with 16 * 16 patches. │ ├── patches0001.bmp │ ├── ... ├── yosemite/ │ ├── ... ├── notredame/ │ ├── ... ├── liberty_harris/ │ ├── ... ├── yosemite_harris/ │ ├── ... ├── notredame_harris/ │ ├── ...Citation:
@INPROCEEDINGS{4269996, author={Winder, Simon A. J. and Brown, Matthew}, booktitle={2007 IEEE Conference on Computer Vision and Pattern Recognition}, title={Learning Local Image Descriptors}, year={2007}, volume={}, number={}, pages={1-8}, doi={10.1109/CVPR.2007.382971} }
- class mindspore.dataset.Places365Dataset(dataset_dir, usage=None, small=True, decode=False, num_samples=None, num_parallel_workers=None, shuffle=None, sampler=None, num_shards=None, shard_id=None, cache=None)[source]
Places365 dataset.
The generated dataset has two columns
[image, label]. The tensor of columnimageis of the uint8 type. The tensor of columnlabelis of the uint32 type.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
usage (str, optional) – Usage of this dataset, can be
'train-standard','train-challenge'or'val'. Default:None, will be set to'train-standard'.small (bool, optional) – Use 256 * 256 images (True) or high resolution images (False). Default:
True.decode (bool, optional) – Decode the images after reading. Default:
False.num_samples (int, optional) – The number of images to be included in the dataset. Default:
None, will read all images.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (bool, optional) – Whether or not to perform shuffle on the dataset. Default:
None, expected order behavior shown in the table below.sampler (Sampler, optional) – Object used to choose samples from the dataset. Default:
None, expected order behavior shown in the table below.num_shards (int, optional) –
Number of shards that the dataset will be divided into during distributed training. Default:
None. When this argument is specified, num_samples reflects the max sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir does not contain data files.
RuntimeError – If sampler and shuffle are specified at the same time.
RuntimeError – If sampler and num_shards/shard_id are specified at the same time.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If num_parallel_workers exceeds the max thread numbers.
ValueError – If shard_id is not in range of [0, num_shards ).
ValueError – If usage is not
"train-standard","train-challenge"or"val".
- Tutorial Examples:
Note
The parameters num_samples , shuffle , num_shards , shard_id can be used to control the sampler used in the dataset, and their effects when combined with parameter sampler are as follows.
Examples
>>> import mindspore.dataset as ds >>> place365_dataset_dir = "/path/to/place365_dataset_directory" >>> >>> # Read 3 samples from Places365 dataset >>> dataset = ds.Places365Dataset(dataset_dir=place365_dataset_dir, usage='train-standard', ... small=True, decode=True, num_samples=3)
About Places365 dataset:
Convolutional neural networks (CNNs) trained on the Places2 Database can be used for scene recognition as well as generic deep scene features for visual recognition.
The author releases the data of Places365-Standard and the data of Places365-Challenge to the public. Places365-Standard is the core set of Places2 Database, which has been used to train the Places365-CNNs. The author will add other kinds of annotation on the Places365-Standard in the future. Places365-Challenge is the competition set of Places2 Database, which has 6.2 million extra images compared to the Places365-Standard. The Places365-Challenge will be used for the Places Challenge 2016.
You can unzip the original Places365 dataset files into this directory structure and read by MindSpore's API.
. └── categories_places365 ├── places365_train-standard.txt ├── places365_train-challenge.txt ├── val_large/ │ ├── Places365_val_00000001.jpg │ ├── Places365_val_00000002.jpg │ ├── Places365_val_00000003.jpg │ ├── ... ├── val_256/ │ ├── ... ├── data_large_standard/ │ ├── ... ├── data_256_standard/ │ ├── ... ├── data_large_challenge/ │ ├── ... ├── data_256_challenge/ │ ├── ...Citation:
@article{zhou2017places, title={Places: A 10 million Image Database for Scene Recognition}, author={Zhou, Bolei and Lapedriza, Agata and Khosla, Aditya and Oliva, Aude and Torralba, Antonio}, journal={IEEE Transactions on Pattern Analysis and Machine Intelligence}, year={2017}, publisher={IEEE} }
- class mindspore.dataset.QMnistDataset(dataset_dir, usage=None, compat=True, num_samples=None, num_parallel_workers=None, shuffle=None, sampler=None, num_shards=None, shard_id=None, cache=None)[source]
QMNIST dataset.
The generated dataset has two columns
[image, label]. The tensor of columnimageis of the uint8 type. The tensor of columnlabelis of the uint32 type.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
usage (str, optional) – Usage of this dataset, can be
'train','test','test10k','test50k','nist'or'all'. Default:None, will read all samples.compat (bool, optional) – Specifies the labeling information for each sample. Whether the label for each example is class number (compat=
True) or the full QMNIST information (compat=False). Default:True.num_samples (int, optional) – The number of images to be included in the dataset. Default:
None, will read all images.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (bool, optional) – Whether or not to perform shuffle on the dataset. Default:
None, expected order behavior shown in the table below.sampler (Sampler, optional) – Object used to choose samples from the dataset. Default:
None, expected order behavior shown in the table below.num_shards (int, optional) –
Number of shards that the dataset will be divided into during distributed training. Default:
None. When this argument is specified, num_samples reflects the maximum sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir does not contain data files.
RuntimeError – If sampler and shuffle are specified at the same time.
RuntimeError – If sampler and num_shards/shard_id are specified at the same time.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If shard_id is not in range of [0, num_shards ).
ValueError – If num_parallel_workers exceeds the max thread numbers.
- Tutorial Examples:
Note
The parameters num_samples , shuffle , num_shards , shard_id can be used to control the sampler used in the dataset, and their effects when combined with parameter sampler are as follows.
Examples
>>> import mindspore.dataset as ds >>> qmnist_dataset_dir = "/path/to/qmnist_dataset_directory" >>> >>> # Read 3 samples from QMNIST train dataset >>> dataset = ds.QMnistDataset(dataset_dir=qmnist_dataset_dir, num_samples=3) >>> >>> # Note: In QMNIST dataset, each dictionary has keys "image" and "label"
About QMNIST dataset:
The QMNIST dataset was generated from the original data found in the NIST Special Database 19 with the goal to match the MNIST preprocessing as closely as possible. Through an iterative process, researchers tried to generate an additional 50k images of MNIST-like data. They started with a reconstruction process given in the paper and used the Hungarian algorithm to find the best matches between the original MNIST samples and their reconstructed samples.
Here is the original QMNIST dataset structure. You can unzip the dataset files into this directory structure and read by MindSpore's API.
. └── qmnist_dataset_dir ├── qmnist-train-images-idx3-ubyte ├── qmnist-train-labels-idx2-int ├── qmnist-test-images-idx3-ubyte ├── qmnist-test-labels-idx2-int ├── xnist-images-idx3-ubyte └── xnist-labels-idx2-intCitation:
@incollection{qmnist-2019, title = "Cold Case: The Lost MNIST Digits", author = "Chhavi Yadav and L'{e}on Bottou", booktitle = {Advances in Neural Information Processing Systems 32}, year = {2019}, publisher = {Curran Associates, Inc.}, }
- class mindspore.dataset.RandomDataset(total_rows=None, schema=None, columns_list=None, num_samples=None, num_parallel_workers=None, cache=None, shuffle=None, num_shards=None, shard_id=None)[source]
A source dataset that generates random data.
- Parameters:
total_rows (int, optional) – Number of samples for the dataset to generate. Default:
None, number of samples is random.schema (Union[str, Schema], optional) – Data format policy, which specifies the data types and shapes of the data column to be read. Both JSON file path and objects constructed by
mindspore.dataset.Schemaare acceptable. Default:None.columns_list (list[str], optional) – List of column names of the dataset. Default:
None, the columns will be named like this "c0", "c1", "c2" etc.num_samples (int, optional) – The number of samples to be included in the dataset. Default:
None, all samples.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.shuffle (bool, optional) – Whether or not to perform shuffle on the dataset. Default:
None, expected order behavior shown in the table below.num_shards (int, optional) –
Number of shards that the dataset will be divided into during distributed training. Default:
None. When this argument is specified, num_samples reflects the maximum sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.
- Raises:
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If num_parallel_workers exceeds the max thread numbers.
ValueError – If shard_id is not in range of [0, num_shards ).
TypeError – If total_rows is not of type int.
TypeError – If num_shards is not of type int.
TypeError – If num_parallel_workers is not of type int.
TypeError – If shuffle is not of type bool.
TypeError – If columns_list is not of type list.
- Tutorial Examples:
Examples
>>> from mindspore import dtype as mstype >>> import mindspore.dataset as ds >>> >>> schema = ds.Schema() >>> schema.add_column('image', de_type=mstype.uint8, shape=[2]) >>> schema.add_column('label', de_type=mstype.uint8, shape=[1]) >>> # apply dataset operations >>> ds1 = ds.RandomDataset(schema=schema, total_rows=50, num_parallel_workers=4)
- class mindspore.dataset.RandomSampler(replacement=False, num_samples=None, shuffle=Shuffle.GLOBAL)[source]
Samples the elements randomly.
Note
The shuffling modes supported for different datasets are as follows:
List of support for shuffling mode Shuffling Mode
MindDataset
TFRecordDataset
Others
Shuffle.ADAPTIVESupported
Not Supported
Not Supported
Shuffle.GLOBALSupported
Supported
Supported
Shuffle.PARTIALSupported
Not Supported
Not Supported
Shuffle.FILESSupported
Supported
Not Supported
Shuffle.INFILESupported
Not Supported
Not Supported
- Parameters:
replacement (bool, optional) – If True, put the sample ID back for the next draw. Default:
False.num_samples (int, optional) – Number of elements to sample. Default:
None, which means sample all elements.shuffle (Shuffle, optional) –
Specify the shuffle mode. Default:
Shuffle.GLOBAL, Global shuffle of all rows of data in dataset. There are several levels of shuffling, desired shuffle enum defined bymindspore.dataset.Shuffle.Shuffle.ADAPTIVE: When the number of dataset samples is less than or equal to 100 million,Shuffle.GLOBALis used. When the number of dataset samples is greater than 100 million,Shuffle.PARTIALis used. The shuffle is performed once every 1 million samples.Shuffle.GLOBAL: Global shuffle of all rows of data in dataset. The memory usage is large.Shuffle.PARTIAL: Partial shuffle of data in dataset for every 1 million samples. The memory usage is less thanShuffle.GLOBAL.Shuffle.FILES: Shuffle the file sequence but keep the order of data within each file.Shuffle.INFILE: Keep the file sequence the same but shuffle the data within each file.
- Raises:
TypeError – If replacement is not of type bool.
TypeError – If num_samples is not of type int.
ValueError – If num_samples is a negative value.
TypeError – If shuffle is not of type Shuffle.
Examples
>>> import mindspore.dataset as ds >>> # creates a RandomSampler >>> sampler = ds.RandomSampler() >>> dataset = ds.ImageFolderDataset(image_folder_dataset_dir, ... num_parallel_workers=8, ... sampler=sampler)
- class mindspore.dataset.RenderedSST2Dataset(dataset_dir, usage=None, num_samples=None, num_parallel_workers=None, shuffle=None, decode=False, sampler=None, num_shards=None, shard_id=None, cache=None)[source]
RenderedSST2(Rendered Stanford Sentiment Treebank v2) dataset.
The generated dataset has two columns:
[image, label]. The tensor of columnimageis of the uint8 type. The tensor of columnlabelis of the uint32 type.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
usage (str, optional) – Usage of this dataset, can be
'train','val','test'or'all'. Default:None, will read all samples.num_samples (int, optional) – The number of images to be included in the dataset. Default:
None, will include all images.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (bool, optional) – Whether or not to perform shuffle on the dataset. Default:
None, expected order behavior shown in the table below.decode (bool, optional) – Whether or not to decode the images after reading. Default:
False.sampler (Sampler, optional) – Object used to choose samples from the dataset. Default:
None, expected order behavior shown in the table below.num_shards (int, optional) –
Number of shards that the dataset will be divided into during distributed training. Default:
None. When this argument is specified, num_samples reflects the maximum sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . This argument can only be specified when num_shards is also specified. Default:
None.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir does not contain data files.
RuntimeError – If sampler and shuffle are specified at the same time.
RuntimeError – If sampler and num_shards/shard_id are specified at the same time.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If usage is not
'train','test','val'or'all'.ValueError – If num_parallel_workers exceeds the max thread numbers.
ValueError – If shard_id is not in range of [0, num_shards ).
- Tutorial Examples:
Note
The parameters num_samples , shuffle , num_shards , shard_id can be used to control the sampler used in the dataset, and their effects when combined with parameter sampler are as follows.
Examples
>>> import mindspore.dataset as ds >>> rendered_sst2_dataset_dir = "/path/to/rendered_sst2_dataset_directory" >>> >>> # 1) Read all samples (image files) in rendered_sst2_dataset_dir with 8 threads >>> dataset = ds.RenderedSST2Dataset(dataset_dir=rendered_sst2_dataset_dir, ... usage="all", num_parallel_workers=8)
About RenderedSST2Dataset:
Rendered SST2 is an image classification dataset which was generated by rendering sentences in the Standford Sentiment Treebank v2 dataset. There are three splits in this dataset and each split contains two classes (positive and negative): a train split containing 6920 images (3610 positive and 3310 negative), a validation split containing 872 images (444 positive and 428 negative), and a test split containing 1821 images (909 positive and 912 negative).
Here is the original RenderedSST2 dataset structure. You can unzip the dataset files into the following directory structure and read by MindSpore's API.
. └── rendered_sst2_dataset_directory ├── train │ ├── negative │ │ ├── 0001.jpg │ │ ├── 0002.jpg │ │ ... │ └── positive │ ├── 0001.jpg │ ├── 0002.jpg │ ... ├── test │ ├── negative │ │ ├── 0001.jpg │ │ ├── 0002.jpg │ │ ... │ └── positive │ ├── 0001.jpg │ ├── 0002.jpg │ ... └── valid ├── negative │ ├── 0001.jpg │ ├── 0002.jpg │ ... └── positive ├── 0001.jpg ├── 0002.jpg ...Citation:
@inproceedings{socher-etal-2013-recursive, title = {Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank}, author = {Socher, Richard and Perelygin, Alex and Wu, Jean and Chuang, Jason and Manning, Christopher D. and Ng, Andrew and Potts, Christopher}, booktitle = {Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing}, month = oct, year = {2013}, address = {Seattle, Washington, USA}, publisher = {Association for Computational Linguistics}, url = {https://www.aclweb.org/anthology/D13-1170}, pages = {1631--1642}, }
- class mindspore.dataset.SBDataset(dataset_dir, task='Boundaries', usage='all', num_samples=None, num_parallel_workers=1, shuffle=None, decode=None, sampler=None, num_shards=None, shard_id=None)[source]
SB(Semantic Boundaries) Dataset.
By configuring the task parameter, the generated dataset has different output columns.
task is
'Boundaries', there are two output columns: the 'image' column has the data type uint8 and the 'label' column contains one image of the data type uint8.task is
'Segmentation', there are two output columns: the 'image' column has the data type uint8 and the 'label' column contains 20 images of the data type uint8.
- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
task (str, optional) – Acceptable tasks include
'Boundaries'or'Segmentation'. Default:'Boundaries'.usage (str, optional) – Acceptable usages include
'train','val','train_noval'and'all'. Default:'all'.num_samples (int, optional) – The number of images to be included in the dataset. Default:
None, all images.num_parallel_workers (int, optional) – Number of worker subprocesses to read the data. Default:
1.shuffle (bool, optional) – Whether to perform shuffle on the dataset. Default:
None, expected order behavior shown in the table below.decode (bool, optional) – Decode the images after reading. Default:
None, meansFalse.sampler (Sampler, optional) – Object used to choose samples from the dataset. Default:
None, expected order behavior shown in the table below.num_shards (int, optional) –
Number of shards that the dataset will be divided into during parallel training. Default:
None. When this argument is specified, num_samples reflects the max sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.
- Raises:
RuntimeError – If dataset_dir is not valid or does not contain data files.
RuntimeError – If sampler and shuffle are specified at the same time.
RuntimeError – If sampler and num_shards/shard_id are specified at the same time.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If dataset_dir does not exist.
ValueError – If num_parallel_workers exceeds the max thread numbers.
ValueError – If task is not
'Boundaries'or'Segmentation'.ValueError – If usage is not
'train','val','train_noval'or'all'.ValueError – If shard_id is not in range of [0, num_shards ).
- Tutorial Examples:
Note
The parameters num_samples , shuffle , num_shards , shard_id can be used to control the sampler used in the dataset, and their effects when combined with parameter sampler are as follows.
Examples
>>> import mindspore.dataset as ds >>> sb_dataset_dir = "/path/to/sb_dataset_directory" >>> >>> # 1) Get all samples from Semantic Boundaries Dataset in sequence >>> dataset = ds.SBDataset(dataset_dir=sb_dataset_dir, shuffle=False) >>> >>> # 2) Randomly select 350 samples from Semantic Boundaries Dataset >>> dataset = ds.SBDataset(dataset_dir=sb_dataset_dir, num_samples=350, shuffle=True) >>> >>> # 3) Get samples from Semantic Boundaries Dataset for shard 0 in a 2-way distributed training >>> dataset = ds.SBDataset(dataset_dir=sb_dataset_dir, num_shards=2, shard_id=0) >>> >>> # In Semantic Boundaries Dataset, each dictionary has keys "image" and "task"
About Semantic Boundaries Dataset:
The Semantic Boundaries Dataset consists of 11355 color images. There are 8498 image names in the train.txt, 2857 image names in the val.txt and 5623 image names in the train_noval.txt. The category cls contains the Segmentation and Boundaries results of category-level. The category inst contains the Segmentation and Boundaries results of instance-level.
You can unzip the dataset files into the following structure and read by MindSpore's API:
. └── benchmark_RELEASE ├── dataset ├── img │ ├── 2008_000002.jpg │ ├── 2008_000003.jpg │ ├── ... ├── cls │ ├── 2008_000002.mat │ ├── 2008_000003.mat │ ├── ... ├── inst │ ├── 2008_000002.mat │ ├── 2008_000003.mat │ ├── ... ├── train.txt └── val.txt@InProceedings{BharathICCV2011, author = "Bharath Hariharan and Pablo Arbelaez and Lubomir Bourdev and Subhransu Maji and Jitendra Malik", title = "Semantic Contours from Inverse Detectors", booktitle = "International Conference on Computer Vision (ICCV)", year = "2011", }
- class mindspore.dataset.SBUDataset(dataset_dir, num_samples=None, num_parallel_workers=None, shuffle=None, decode=False, sampler=None, num_shards=None, shard_id=None, cache=None)[source]
SBU(SBU Captioned Photo) dataset.
The generated dataset has two columns
[image, caption]. The tensor of columnimageis of the uint8 type. The tensor of columncaptionis of the string type.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
num_samples (int, optional) – The number of images to be included in the dataset. Default:
None, will read all images.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (bool, optional) – Whether or not to perform shuffle on the dataset. Default:
None, expected order behavior shown in the table below.decode (bool, optional) – Decode the images after reading. Default:
False.sampler (Sampler, optional) – Object used to choose samples from the dataset. Default:
None, expected order behavior shown in the table below.num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the max sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir does not contain data files.
RuntimeError – If sampler and shuffle are specified at the same time.
RuntimeError – If sampler and num_shards/shard_id are specified at the same time.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If num_parallel_workers exceeds the max thread numbers.
ValueError – If shard_id is not in range of [0, num_shards ).
- Tutorial Examples:
Note
The parameters num_samples , shuffle , num_shards , shard_id can be used to control the sampler used in the dataset, and their effects when combined with parameter sampler are as follows.
Examples
>>> import mindspore.dataset as ds >>> sbu_dataset_dir = "/path/to/sbu_dataset_directory" >>> # Read 3 samples from SBU dataset >>> dataset = ds.SBUDataset(dataset_dir=sbu_dataset_dir, num_samples=3)
About SBU dataset:
SBU dataset is a large captioned photo collection. It contains one million images with associated visually relevant captions.
You should manually download the images using official download.m by replacing 'urls{i}(24, end)' with 'urls{i}(24:1:end)' and keep the directory as below.
. └─ dataset_dir ├── SBU_captioned_photo_dataset_captions.txt ├── SBU_captioned_photo_dataset_urls.txt └── sbu_images ├── m_3326_3596303505_3ce4c20529.jpg ├── ...... └── m_2522_4182181099_c3c23ab1cc.jpgCitation:
@inproceedings{Ordonez:2011:im2text, Author = {Vicente Ordonez and Girish Kulkarni and Tamara L. Berg}, Title = {Im2Text: Describing Images Using 1 Million Captioned Photographs}, Booktitle = {Neural Information Processing Systems ({NIPS})}, Year = {2011}, }
- class mindspore.dataset.SQuADDataset(dataset_dir, usage=None, num_samples=None, num_parallel_workers=None, shuffle=Shuffle.GLOBAL, num_shards=None, shard_id=None, cache=None)[source]
SQuAD 1.1 and SQuAD 2.0 datasets.
The generated dataset with different versions and usages has the same output columns:
[context, question, text, answer_start]. The tensor of columncontextis of the string type. The tensor of columnquestionis of the string type. The tensor of columntextcontains the answer in the context of the string type. The tensor of columnanswer_startis the start index of answer in context, which is of the uint32 type.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
usage (str, optional) – Specify the
'train','dev'or'all'part of dataset. Default:None, all samples.num_samples (int, optional) – The number of samples to be included in the dataset. Default:
None, will include all samples.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (Union[bool, Shuffle], optional) –
Perform reshuffling of the data every epoch. Bool type and Shuffle enum are both supported to pass in. Default:
Shuffle.GLOBAL. IfFalseis provided, no shuffling will be performed. IfTrueis provided, it is the same as setting toShuffle.GLOBAL. If Shuffle is provided, the effect is as follows:Shuffle.GLOBAL: Shuffle both the files and samples.Shuffle.FILES: Shuffle files only.
num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the maximum sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir does not contain data files.
ValueError – If num_parallel_workers exceeds the max thread numbers.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If shard_id is not in range of [0, num_shards ).
- Tutorial Examples:
Examples
>>> import mindspore.dataset as ds >>> squad_dataset_dir = "/path/to/squad_dataset_file" >>> dataset = ds.SQuADDataset(dataset_dir=squad_dataset_dir, usage='all')
About SQuAD dataset:
SQuAD (Stanford Question Answering Dataset) is a reading comprehension dataset, consisting of questions posed by crowdworkers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the corresponding reading passage, or the question might be unanswerable.
SQuAD 1.1, the previous version of the SQuAD dataset, contains 100,000+ question-answer pairs on 500+ articles. SQuAD 2.0 combines the 100,000 questions in SQuAD 1.1 with over 50,000 unanswerable questions written adversarially by crowdworkers to look similar to answerable ones. To do well on SQuAD 2.0, systems must not only answer questions when possible, but also determine when no answer is supported by the paragraph and abstain from answering.
You can get the dataset files into the following structure and read by MindSpore's API,
For SQuAD 1.1:
. └── SQuAD1 ├── train-v1.1.json └── dev-v1.1.jsonFor SQuAD 2.0:
. └── SQuAD2 ├── train-v2.0.json └── dev-v2.0.jsonCitation:
@misc{rajpurkar2016squad, title = {SQuAD: 100,000+ Questions for Machine Comprehension of Text}, author = {Pranav Rajpurkar and Jian Zhang and Konstantin Lopyrev and Percy Liang}, year = {2016}, eprint = {1606.05250}, archivePrefix = {arXiv}, primaryClass = {cs.CL} } @misc{rajpurkar2018know, title = {Know What You Don't Know: Unanswerable Questions for SQuAD}, author = {Pranav Rajpurkar and Robin Jia and Percy Liang}, year = {2018}, eprint = {1806.03822}, archivePrefix = {arXiv}, primaryClass = {cs.CL} }
- class mindspore.dataset.SST2Dataset(dataset_dir, usage=None, num_samples=None, num_parallel_workers=None, shuffle=Shuffle.GLOBAL, num_shards=None, shard_id=None, cache=None)[source]
SST2(Stanford Sentiment Treebank v2) dataset.
The generated dataset's train.tsv and dev.tsv have two columns
[sentence, label]. The generated dataset's test.tsv has one column[sentence]. The tensors of columnsentenceandlabelare of the string type.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
usage (str, optional) – Usage of this dataset, can be
"train","test"or"dev"."train"will read from 67,349 train samples,"test"will read from 1,821 test samples,"dev"will read from all 872 samples. Default:None, will read train samples.num_samples (int, optional) – The number of samples to be included in the dataset. Default:
None, will include all text.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (Union[bool, Shuffle], optional) –
Perform reshuffling of the data every epoch. Bool type and Shuffle enum are both supported to pass in. Default:
Shuffle.GLOBAL. If shuffle isFalse, no shuffling will be performed; If shuffle isTrue, the behavior is the same as setting shuffle to beShuffle.GLOBAL. Set the mode of data shuffling by passing in enumeration variables:Shuffle.GLOBAL: Shuffle both the files and samples.Shuffle.FILES: Shuffle files only.
num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the maximum sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards. This argument can only be specified when num_shards is also specified. Default:
None.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir does not contain data files.
ValueError – If num_parallel_workers exceeds the max thread numbers.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If shard_id is not in range of [0, num_shards ).
- Tutorial Examples:
Examples
>>> import mindspore.dataset as ds >>> sst2_dataset_dir = "/path/to/sst2_dataset_directory" >>> >>> # 1) Read 3 samples from SST2 dataset >>> dataset = ds.SST2Dataset(dataset_dir=sst2_dataset_dir, num_samples=3) >>> >>> # 2) Read train samples from SST2 dataset >>> dataset = ds.SST2Dataset(dataset_dir=sst2_dataset_dir, usage="train")
About SST2 dataset: The Stanford Sentiment Treebank is a corpus with fully labeled parse trees that allows for a complete analysis of the compositional effects of sentiment in language. The corpus is based on the dataset introduced by Pang and Lee (2005) and consists of 11,855 single sentences extracted from movie reviews. It was parsed with the Stanford parser and includes a total of 215,154 unique phrases from those parse trees, each annotated by 3 human judges.
Here is the original SST2 dataset structure. You can unzip the dataset files into this directory structure and read by MindSpore's API.
. └── sst2_dataset_dir ├── train.tsv ├── test.tsv ├── dev.tsv └── originalCitation:
@inproceedings{socher-etal-2013-recursive, title = {Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank}, author = {Socher, Richard and Perelygin, Alex and Wu, Jean and Chuang, Jason and Manning, Christopher D. and Ng, Andrew and Potts, Christopher}, booktitle = {Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing}, month = oct, year = {2013}, address = {Seattle, Washington, USA}, publisher = {Association for Computational Linguistics}, url = {https://www.aclweb.org/anthology/D13-1170}, pages = {1631--1642}, }
- class mindspore.dataset.STL10Dataset(dataset_dir, usage=None, num_samples=None, num_parallel_workers=None, shuffle=None, sampler=None, num_shards=None, shard_id=None, cache=None)[source]
STL-10 dataset.
The generated dataset has two columns:
[image, label]. The tensor of columnimageis of the uint8 type. The tensor of columnlabelis of a scalar of uint32 type.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
usage (str, optional) – Usage of this dataset, can be
'train','test','unlabeled','train+unlabeled'or'all'.'train'will read from 5,000 train samples,'test'will read from 8,000 test samples,'unlabeled'will read from all 100,000 samples, and'train+unlabeled'will read from 105,000 samples,'all'will read all the samples. Default:None, all samples.num_samples (int, optional) – The number of images to be included in the dataset. It can be less than the total number of datasets. Default:
None, all images.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (bool, optional) – Whether to perform shuffle on the dataset. Default:
None, expected order behavior shown in the table below.sampler (Sampler, optional) – Object used to choose samples from the dataset. Default:
None, expected order behavior shown in the table below.num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the max sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir is not valid or does not exist or does not contain data files.
RuntimeError – If sampler and shuffle are specified at the same time.
RuntimeError – If sampler and num_shards/shard_id are specified at the same time.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If usage is invalid.
ValueError – If num_parallel_workers exceeds the max thread numbers.
ValueError – If shard_id is not in range of [0, num_shards ).
- Tutorial Examples:
Note
The parameters num_samples , shuffle , num_shards , shard_id can be used to control the sampler used in the dataset, and their effects when combined with parameter sampler are as follows.
Examples
>>> import mindspore.dataset as ds >>> stl10_dataset_dir = "/path/to/stl10_dataset_directory" >>> >>> # 1) Get all samples from STL10 dataset in sequence >>> dataset = ds.STL10Dataset(dataset_dir=stl10_dataset_dir, shuffle=False) >>> >>> # 2) Randomly select 350 samples from STL10 dataset >>> dataset = ds.STL10Dataset(dataset_dir=stl10_dataset_dir, num_samples=350, shuffle=True) >>> >>> # 3) Get samples from STL10 dataset for shard 0 in a 2-way distributed training >>> dataset = ds.STL10Dataset(dataset_dir=stl10_dataset_dir, num_shards=2, shard_id=0)
About STL10 dataset:
STL10 dataset consists of 10 classes: airplane, bird, car, cat, deer, dog, horse, monkey, ship, truck. Images are 96x96 pixels, color. 500 training images, 800 test images per class and 100000 unlabeled images. Labels are 0-indexed, and unlabeled images have -1 as their labels.
Here is the original STL10 dataset structure. You can unzip the dataset files into this directory structure and read by MindSpore's API.
. └── stl10_dataset_dir ├── train_X.bin ├── train_y.bin ├── test_X.bin ├── test_y.bin └── unlabeled_X.binCitation of STL10 dataset:
@techreport{Coates10, author = {Adam Coates}, title = {Learning multiple layers of features from tiny images}, year = {2010}, howpublished = {https://cs.stanford.edu/~acoates/stl10/}, description = {The STL-10 dataset consists of 96x96 RGB images in 10 classes, with 500 training images and 800 testing images per class. There are 5000 training images and 8000 test images. It also has 100000 unlabeled images for unsupervised learning. These examples are extracted from a similar but broader distribution of images. } }
- class mindspore.dataset.SUN397Dataset(dataset_dir, num_samples=None, num_parallel_workers=None, shuffle=None, decode=False, sampler=None, num_shards=None, shard_id=None, cache=None)[source]
SUN397(Scene UNderstanding) dataset.
The generated dataset has two columns:
[image, label]. The tensor of columnimageis of the uint8 type. The tensor of columnlabelis of the uint32 type.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
num_samples (int, optional) – The number of images to be included in the dataset. It can be less than the total number of datasets. Default:
None, all images.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (bool, optional) – Whether or not to perform shuffle on the dataset. Default:
None, expected order behavior shown in the table below.decode (bool, optional) – Whether or not to decode the images after reading. Default:
False, meaning not decoding.sampler (Sampler, optional) – Object used to choose samples from the dataset. Default:
None, expected order behavior shown in the table below.num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the maximum sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . This argument can only be specified when num_shards is also specified. Default:
None.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir does not contain data files.
RuntimeError – If sampler and shuffle are specified at the same time.
RuntimeError – If sampler and num_shards/shard_id are specified at the same time.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If num_parallel_workers exceeds the max thread numbers.
ValueError – If shard_id is not in range of [0, num_shards ).
- Tutorial Examples:
Note
The parameters num_samples , shuffle , num_shards , shard_id can be used to control the sampler used in the dataset, and their effects when combined with parameter sampler are as follows.
Examples
>>> import mindspore.dataset as ds >>> sun397_dataset_dir = "/path/to/sun397_dataset_directory" >>> >>> # 1) Read all samples (image files) in sun397_dataset_dir with 8 threads >>> dataset = ds.SUN397Dataset(dataset_dir=sun397_dataset_dir, num_parallel_workers=8)
About SUN397Dataset:
The SUN397 or Scene UNderstanding (SUN) is a dataset for scene recognition consisting of 397 categories with 108,754 images. The number of images varies across categories, but there are at least 100 images per category. Images are in jpg, png, or gif format.
Here is the original SUN397 dataset structure. You can unzip the dataset files into this directory structure and read by MindSpore's API.
. └── sun397_dataset_directory ├── ClassName.txt ├── README.txt ├── a │ ├── abbey │ │ ├── sun_aaaulhwrhqgejnyt.jpg │ │ ├── sun_aacphuqehdodwawg.jpg │ │ ├── ... │ ├── apartment_building │ │ └── outdoor │ │ ├── sun_aamyhslnsnomjzue.jpg │ │ ├── sun_abbjzfrsalhqivis.jpg │ │ ├── ... │ ├── ... ├── b │ ├── badlands │ │ ├── sun_aabtemlmesogqbbp.jpg │ │ ├── sun_afbsfeexggdhzshd.jpg │ │ ├── ... │ ├── balcony │ │ ├── exterior │ │ │ ├── sun_aaxzaiuznwquburq.jpg │ │ │ ├── sun_baajuldidvlcyzhv.jpg │ │ │ ├── ... │ │ └── interior │ │ ├── sun_babkzjntjfarengi.jpg │ │ ├── sun_bagjvjynskmonnbv.jpg │ │ ├── ... │ └── ... ├── ...Citation:
@inproceedings{xiao2010sun, title = {Sun database: Large-scale scene recognition from abbey to zoo}, author = {Xiao, Jianxiong and Hays, James and Ehinger, Krista A and Oliva, Aude and Torralba, Antonio}, booktitle = {2010 IEEE computer society conference on computer vision and pattern recognition}, pages = {3485--3492}, year = {2010}, organization = {IEEE} }
- class mindspore.dataset.SVHNDataset(dataset_dir, usage=None, num_samples=None, num_parallel_workers=1, shuffle=None, sampler=None, num_shards=None, shard_id=None)[source]
SVHN(Street View House Numbers) dataset.
The generated dataset has two columns:
[image, label]. The tensor of columnimageis of the uint8 type. The tensor of columnlabelis of a scalar of uint32 type.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
usage (str, optional) – Specify the
'train','test','extra'or'all'parts of dataset. Default:None, will read all samples.num_samples (int, optional) – The number of samples to be included in the dataset. Default:
None, all images.num_parallel_workers (int, optional) – Number of worker subprocesses used to fetch the dataset in parallel. Default:
1.shuffle (bool, optional) – Whether or not to perform shuffle on the dataset. Default:
None, expected order behavior shown in the table below.sampler (Sampler, optional) – Object used to choose samples from the dataset. Default:
None, expected order behavior shown in the table below.num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the max sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument must be specified only when num_shards is also specified.
- Raises:
RuntimeError – If dataset_dir is not valid or does not exist or does not contain data files.
RuntimeError – If sampler and shuffle are specified at the same time.
RuntimeError – If sampler and num_shards/shard_id are specified at the same time.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If usage is invalid.
ValueError – If num_parallel_workers exceeds the max thread numbers.
ValueError – If shard_id is not in range of [0, num_shards ).
- Tutorial Examples:
Note
The parameters num_samples , shuffle , num_shards , shard_id can be used to control the sampler used in the dataset, and their effects when combined with parameter sampler are as follows.
Examples
>>> import mindspore.dataset as ds >>> svhn_dataset_dir = "/path/to/svhn_dataset_directory" >>> dataset = ds.SVHNDataset(dataset_dir=svhn_dataset_dir, usage="train")
About SVHN dataset:
SVHN dataset consists of 10 digit classes and is obtained from house numbers in Google Street View images.
Here is the original SVHN dataset structure. You can unzip the dataset files into this directory structure and read by MindSpore's API.
. └── svhn_dataset_dir ├── train_32x32.mat ├── test_32x32.mat └── extra_32x32.matCitation:
@article{ title={Reading Digits in Natural Images with Unsupervised Feature Learning}, author={Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bissacco, Bo Wu, Andrew Y. Ng}, conference={NIPS Workshop on Deep Learning and Unsupervised Feature Learning 2011.}, year={2011}, publisher={NIPS}, url={http://ufldl.stanford.edu/housenumbers} }
- class mindspore.dataset.Schema(schema_file=None)[source]
Class to represent a schema of a dataset.
- Parameters:
schema_file (str, optional) – Path of the schema file. Default:
None.- Raises:
RuntimeError – If schema file failed to load.
Examples
>>> import mindspore.dataset as ds >>> from mindspore import dtype as mstype >>> >>> # Create schema; specify column name, mindspore.dtype and shape of the column >>> schema = ds.Schema() >>> schema.add_column(name='col1', de_type=mstype.int64, shape=[2])
- add_column(name, de_type, shape=None)[source]
Add new column to the schema.
- Parameters:
- Raises:
ValueError – If column type is unknown.
Examples
>>> import mindspore.dataset as ds >>> from mindspore import dtype as mstype >>> >>> schema = ds.Schema() >>> schema.add_column('col_1d', de_type=mstype.int64, shape=[2])
- from_json(json_obj)[source]
Get schema file from JSON object.
- Parameters:
json_obj (dict) – Object of JSON parsed.
- Raises:
RuntimeError – If there is an unknown item in the object.
RuntimeError – If dataset type is missing in the object.
RuntimeError – If columns are missing in the object.
Examples
>>> import json >>> from mindspore.dataset import Schema >>> >>> with open("/path/to/schema_file", "r") as file: ... json_obj = json.load(file) ... schema = Schema() ... schema.from_json(json_obj)
- parse_columns(columns)[source]
Parse the columns and add them to the schema.
- Parameters:
columns (Union[dict, list[dict], tuple[dict]]) –
Dataset attribute information, decoded from schema file.
list[dict], name and type must be in keys, shape optional.
dict, columns.keys() as name, columns.values() is dict, and type inside, shape optional.
- Raises:
RuntimeError – If failed to parse columns.
RuntimeError – If column's name field is missing.
RuntimeError – If column's type field is missing.
Examples
>>> from mindspore.dataset import Schema >>> schema = Schema() >>> columns1 = [{'name': 'image', 'type': 'int8', 'shape': [3, 3]}, ... {'name': 'label', 'type': 'int8', 'shape': [1]}] >>> schema.parse_columns(columns1) >>> columns2 = {'image': {'shape': [3, 3], 'type': 'int8'}, 'label': {'shape': [1], 'type': 'int8'}} >>> schema.parse_columns(columns2)
- to_json()[source]
Get a JSON string of the schema.
- Returns:
str, JSON string of the schema.
Examples
>>> from mindspore.dataset import Schema >>> from mindspore import dtype as mstype >>> >>> schema = Schema() >>> schema.add_column('col_1d', de_type=mstype.int64, shape=[2]) >>> json = schema.to_json()
- class mindspore.dataset.SemeionDataset(dataset_dir, num_samples=None, num_parallel_workers=None, shuffle=None, sampler=None, num_shards=None, shard_id=None, cache=None)[source]
Semeion dataset.
The generated dataset has two columns
[image, label]. The tensor of columnimageis of the uint8 type. The tensor of columnlabelis a scalar of the uint32 type.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
num_samples (int, optional) – The number of samples to be included in the dataset. Default:
None, will read all images.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (bool, optional) – Whether to perform shuffle on the dataset. Default:
None, expected order behavior shown in the table below.sampler (Sampler, optional) – Object used to choose samples from the dataset. Default:
None, expected order behavior shown in the table below.num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the maximum sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir does not contain data files.
RuntimeError – If sampler and shuffle are specified at the same time.
RuntimeError – If sampler and num_shards/shard_id are specified at the same time.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If num_parallel_workers exceeds the max thread numbers.
ValueError – If shard_id is not in range of [0, num_shards ).
- Tutorial Examples:
Note
The parameters num_samples , shuffle , num_shards , shard_id can be used to control the sampler used in the dataset, and their effects when combined with parameter sampler are as follows.
Examples
>>> import mindspore.dataset as ds >>> semeion_dataset_dir = "/path/to/semeion_dataset_directory" >>> >>> # 1) Get all samples from SEMEION dataset in sequence >>> dataset = ds.SemeionDataset(dataset_dir=semeion_dataset_dir, shuffle=False) >>> >>> # 2) Randomly select 10 samples from SEMEION dataset >>> dataset = ds.SemeionDataset(dataset_dir=semeion_dataset_dir, num_samples=10, shuffle=True) >>> >>> # 3) Get samples from SEMEION dataset for shard 0 in a 2-way distributed training >>> dataset = ds.SemeionDataset(dataset_dir=semeion_dataset_dir, num_shards=2, shard_id=0) >>> >>> # In SEMEION dataset, each dictionary has keys: image, label.
About SEMEION dataset:
The dataset was created by Tactile Srl, Brescia, Italy (http://www.tattile.it) and donated in 1994 to Semeion Research Center of Sciences of Communication, Rome, Italy (http://www.semeion.it), for machine learning research.
This dataset consists of 1593 records (rows) and 256 attributes (columns). Each record represents a handwritten digit, originally scanned with a resolution of 256 grey scale. Each pixel of each original scanned image was first stretched, and after scaled between 0 and 1 (setting to 0 every pixel whose value was under the value 127 of the grey scale (127 included) and setting to 1 each pixel whose original value in the grey scale was over 127). Finally, each binary image was scaled again into a 16x16 square box (the final 256 binary attributes).
. └── semeion_dataset_dir └──semeion.data └──semeion.namesCitation:
@article{ title={The Theory of Independent Judges, in Substance Use & Misuse 33(2)1998, pp 439-461}, author={M Buscema, MetaNet}, }
- class mindspore.dataset.SequentialSampler(start_index=None, num_samples=None)[source]
Samples the dataset elements sequentially that is equivalent to not using a sampler.
- Parameters:
- Raises:
TypeError – If start_index is not of type int.
TypeError – If num_samples is not of type int.
RuntimeError – If start_index is a negative value.
ValueError – If num_samples is a negative value.
Examples
>>> import mindspore.dataset as ds >>> # creates a SequentialSampler >>> sampler = ds.SequentialSampler() >>> dataset = ds.ImageFolderDataset(image_folder_dataset_dir, ... num_parallel_workers=8, ... sampler=sampler)
- class mindspore.dataset.SogouNewsDataset(dataset_dir, usage=None, num_samples=None, shuffle=Shuffle.GLOBAL, num_shards=None, shard_id=None, num_parallel_workers=None, cache=None)[source]
Sogou News dataset.
The generated dataset has three columns:
[index, title, content], and the data type of three columns is string.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
usage (str, optional) – Usage of this dataset, can be
'train','test'or'all'.'train'will read from 450,000 train samples,'test'will read from 60,000 test samples,'all'will read from all 510,000 samples. Default:None, all samples.num_samples (int, optional) – Number of samples (rows) to read. Default:
None, read all samples.shuffle (Union[bool, Shuffle], optional) –
Perform reshuffling of the data every epoch. Bool type and Shuffle enum are both supported to pass in. Default:
Shuffle.GLOBAL. If shuffle isFalse, no shuffling will be performed. If shuffle isTrue, it is equivalent to setting shuffle toShuffle.GLOBAL. Set the mode of data shuffling by passing in enumeration variables:Shuffle.GLOBAL: Shuffle both the files and samples, same as setting shuffle to True.Shuffle.FILES: Shuffle files only.
num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the max sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir does not contain data files.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If num_parallel_workers exceeds the max thread numbers.
- Tutorial Examples:
Examples
>>> import mindspore.dataset as ds >>> sogou_news_dataset_dir = "/path/to/sogou_news_dataset_dir" >>> dataset = ds.SogouNewsDataset(dataset_dir=sogou_news_dataset_dir, usage='all')
About Sogou News Dataset:
Sogou News dataset includes 3 columns, corresponding to class index (1 to 5), title and content. The title and content are escaped using double quotes ("), and any internal double quote is escaped by 2 double quotes (""). New lines are escaped by a backslash followed with an "n" character, that is "\n".
You can unzip the dataset files into the following structure and read by MindSpore's API:
. └── sogou_news_dir ├── classes.txt ├── readme.txt ├── test.csv └── train.csvCitation:
@misc{zhang2015characterlevel, title={Character-level Convolutional Networks for Text Classification}, author={Xiang Zhang and Junbo Zhao and Yann LeCun}, year={2015}, eprint={1509.01626}, archivePrefix={arXiv}, primaryClass={cs.LG} }
- class mindspore.dataset.SpeechCommandsDataset(dataset_dir, usage=None, num_samples=None, num_parallel_workers=None, shuffle=None, sampler=None, num_shards=None, shard_id=None, cache=None)[source]
Speech Commands dataset.
The generated dataset has five columns
[waveform, sample_rate, label, speaker_id, utterance_number]. The tensor of columnwaveformis a vector of the float32 type. The tensor of columnsample_rateis a scalar of the int32 type. The tensor of columnlabelis a scalar of the string type. The tensor of columnspeaker_idis a scalar of the string type. The tensor of columnutterance_numberis a scalar of the int32 type.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
usage (str, optional) – Usage of this dataset, can be
'train','test','valid'or'all'.'train'will read from 84,843 samples,'test'will read from 11,005 samples,'valid'will read from 9,981 valid samples and'all'will read from all 105,829 samples. Default:None, will read all samples.num_samples (int, optional) – The number of samples to be included in the dataset. Default:
None, will read all samples.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (bool, optional) – Whether or not to perform shuffle on the dataset. Default:
None, expected order behavior shown in the table below.sampler (Sampler, optional) – Object used to choose samples from the dataset. Default:
None, expected order behavior shown in the table below.num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the maximum sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir does not contain data files.
RuntimeError – If sampler and shuffle are specified at the same time.
RuntimeError – If sampler and num_shards/shard_id are specified at the same time.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If num_parallel_workers exceeds the max thread numbers.
ValueError – If shard_id is not in range of [0, num_shards ).
- Tutorial Examples:
Note
The parameters num_samples , shuffle , num_shards , shard_id can be used to control the sampler used in the dataset, and their effects when combined with parameter sampler are as follows.
Examples
>>> import mindspore.dataset as ds >>> speech_commands_dataset_dir = "/path/to/speech_commands_dataset_directory" >>> >>> # Read 3 samples from SpeechCommands dataset >>> dataset = ds.SpeechCommandsDataset(dataset_dir=speech_commands_dataset_dir, num_samples=3)
About SpeechCommands dataset:
The SpeechCommands is a database for limited_vocabulary speech recognition, containing 105,829 audio samples of '.wav' format.
Here is the original SpeechCommands dataset structure. You can unzip the dataset files into this directory structure and read by MindSpore's API.
. └── speech_commands_dataset_dir ├── cat ├── b433eff_nohash_0.wav ├── 5a33edf_nohash_1.wav └──.... ├── dog ├── b433w2w_nohash_0.wav └──.... ├── four └── ....Citation:
@article{2018Speech, title={Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition}, author={Warden, P.}, year={2018} }
- class mindspore.dataset.SubsetRandomSampler(indices, num_samples=None)[source]
Samples the elements randomly from a sequence of indices.
- Parameters:
indices (Iterable) – A sequence of indices (Any iterable Python object but string).
num_samples (int, optional) – Number of elements to sample. Used to partially extract samples obtained through sampling. Default:
None, which means sample all elements.
- Raises:
TypeError – If elements of indices are not of type number.
TypeError – If num_samples is not of type int.
ValueError – If num_samples is a negative value.
Examples
>>> import mindspore.dataset as ds >>> indices = [0, 1, 2, 3, 7, 88, 119] >>> >>> # create a SubsetRandomSampler, will sample from the provided indices >>> sampler = ds.SubsetRandomSampler(indices) >>> data = ds.ImageFolderDataset(image_folder_dataset_dir, num_parallel_workers=8, sampler=sampler)
- class mindspore.dataset.SubsetSampler(indices, num_samples=None)[source]
Samples the elements from a sequence of indices.
- Parameters:
indices (Iterable) – A sequence of indices (Any iterable Python object but string).
num_samples (int, optional) – Number of elements to sample. Used to partially extract samples obtained through sampling. Default:
None, which means sample all elements.
- Raises:
TypeError – If elements of indices are not of type number.
TypeError – If num_samples is not of type int.
ValueError – If num_samples is a negative value.
Examples
>>> import mindspore.dataset as ds >>> indices = [0, 1, 2, 3, 4, 5] >>> >>> # creates a SubsetSampler, will sample from the provided indices >>> sampler = ds.SubsetSampler(indices) >>> dataset = ds.ImageFolderDataset(image_folder_dataset_dir, ... num_parallel_workers=8, ... sampler=sampler)
- class mindspore.dataset.TFRecordDataset(dataset_files, schema=None, columns_list=None, num_samples=None, num_parallel_workers=None, shuffle=Shuffle.GLOBAL, num_shards=None, shard_id=None, shard_equal_rows=False, cache=None, compression_type=None)[source]
A source dataset that reads and parses datasets stored on disk in TFData format.
The columns of generated dataset depend on the source TFRecord files.
Note
'TFRecordDataset' is not supported on Windows platform yet.
- Parameters:
dataset_files (Union[str, list[str]]) – String or list of files to be read or glob strings to search for a pattern of files. The list will be sorted in lexicographical order.
schema (Union[str, Schema], optional) – Data format policy, which specifies the data types and shapes of the data column to be read. Both JSON file path and objects constructed by
mindspore.dataset.Schemaare acceptable. Default:None.columns_list (list[str], optional) – List of columns to be read. Default:
None, read all columns.num_samples (int, optional) –
The number of samples (rows) to be included in the dataset. Default:
None. When num_shards and shard_id are specified, it will be interpreted as number of rows per shard. Processing priority for num_samples is as the following:If specify num_samples with value > 0, read num_samples samples.
If no num_samples and specify numRows(parsed from schema) with value > 0, read numRows samples.
If no num_samples and no schema, read the full dataset.
num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (Union[bool, Shuffle], optional) –
Perform reshuffling of the data every epoch. Default:
Shuffle.GLOBAL. Bool type and Shuffle enum are both supported to pass in. If shuffle isFalse, no shuffling will be performed. If shuffle isTrue, perform global shuffle. There are three levels of shuffling, desired shuffle enum defined bymindspore.dataset.Shuffle.Shuffle.GLOBAL: Shuffle both the files and samples, same as setting shuffle toTrue.Shuffle.FILES: Shuffle files only.
num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the maximum sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.shard_equal_rows (bool, optional) – Get equal rows for all shards. Default:
False. If shard_equal_rows is False, the number of rows of each shard may not be equal, and may lead to a failure in distributed training. When the number of samples per TFRecord file are not equal, it is suggested to set it toTrue. This argument should only be specified when num_shards is also specified. When compression_type is notNone, and num_samples or numRows (parsed from schema ) is provided, shard_equal_rows will be implied asTrue.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.compression_type (str, optional) – The type of compression used for all files, must be either
'','GZIP', or'ZLIB'. Default:None, as in empty string. It is highly recommended to provide num_samples or numRows (parsed from schema) when compression_type is"GZIP"or"ZLIB"to avoid performance degradation caused by multiple decompressions of the same file to obtain the file size.
- Raises:
ValueError – If dataset_files are not valid or do not exist.
ValueError – If num_parallel_workers exceeds the max thread numbers.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If shard_id is not in range of [0, num_shards ).
ValueError – If compression_type is not
'','GZIP'or'ZLIB'.ValueError – If compression_type is provided, but the number of dataset files < num_shards .
ValueError – If num_samples < 0.
Examples
>>> import mindspore.dataset as ds >>> from mindspore import dtype as mstype >>> >>> tfrecord_dataset_dir = ["/path/to/tfrecord_dataset_file"] # contains 1 or multiple TFRecord files >>> tfrecord_schema_file = "/path/to/tfrecord_schema_file" >>> >>> # 1) Get all rows from tfrecord_dataset_dir with no explicit schema. >>> # The meta-data in the first row will be used as a schema. >>> dataset = ds.TFRecordDataset(dataset_files=tfrecord_dataset_dir) >>> >>> # 2) Get all rows from tfrecord_dataset_dir with user-defined schema. >>> schema = ds.Schema() >>> schema.add_column(name='col_1d', de_type=mstype.int64, shape=[2]) >>> dataset = ds.TFRecordDataset(dataset_files=tfrecord_dataset_dir, schema=schema) >>> >>> # 3) Get all rows from tfrecord_dataset_dir with the schema file. >>> dataset = ds.TFRecordDataset(dataset_files=tfrecord_dataset_dir, schema=tfrecord_schema_file)
- class mindspore.dataset.TedliumDataset(dataset_dir, release, usage=None, extensions=None, num_samples=None, num_parallel_workers=None, shuffle=None, sampler=None, num_shards=None, shard_id=None, cache=None)[source]
Tedlium dataset. The columns of generated dataset depend on the source SPH files and the corresponding STM files.
The generated dataset has six columns
[waveform, sample_rate, transcript, talk_id, speaker_id, identifier].The data type of column waveform is float32, the data type of column sample_rate is int32, and the data type of columns transcript , talk_id , speaker_id and identifier is string.
- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
release (str) – Release of the dataset, can be
'release1','release2','release3'.usage (str, optional) – Usage of this dataset. For release1 or release2, can be
'train','test','dev'or'all'.'train'will read from train samples,'test'will read from test samples,'dev'will read from dev samples,'all'will read from all samples. For release3, can only be'all', it will read from data samples. Default:None, will read all samples.extensions (str, optional) – Extensions of the SPH files, only
'.sph'is valid. Default:None, set to".sph".num_samples (int, optional) – The number of audio samples to be included in the dataset. Default:
None, will read all samples.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (bool, optional) – Whether to perform shuffle on the dataset. Default:
None, expected order behavior shown in the table below.sampler (Sampler, optional) – Object used to choose samples from the dataset. Default:
None, expected order behavior shown in the table below.num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the maximum sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir does not contain stm files.
RuntimeError – If sampler and shuffle are specified at the same time.
RuntimeError – If sampler and num_shards/shard_id are specified at the same time.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If num_parallel_workers exceeds the max thread numbers.
ValueError – If shard_id is not in range of [0, num_shards ).
- Tutorial Examples:
Note
The parameters num_samples , shuffle , num_shards , shard_id can be used to control the sampler used in the dataset, and their effects when combined with parameter sampler are as follows.
Examples
>>> import mindspore.dataset as ds >>> # 1) Get all train samples from TEDLIUM_release1 dataset in sequence. >>> dataset = ds.TedliumDataset(dataset_dir="/path/to/tedlium1_dataset_directory", ... release="release1", shuffle=False) >>> >>> # 2) Randomly select 10 samples from TEDLIUM_release2 dataset. >>> dataset = ds.TedliumDataset(dataset_dir="/path/to/tedlium2_dataset_directory", ... release="release2", num_samples=10, shuffle=True) >>> >>> # 3) Get samples from TEDLIUM_release-3 dataset for shard 0 in a 2-way distributed training. >>> dataset = ds.TedliumDataset(dataset_dir="/path/to/tedlium3_dataset_directory", ... release="release3", num_shards=2, shard_id=0) >>> >>> # In TEDLIUM dataset, each dictionary has keys : waveform, sample_rate, transcript, talk_id, >>> # speaker_id and identifier.
About TEDLIUM_release1 dataset:
The TED-LIUM corpus is English-language TED talks, with transcriptions, sampled at 16kHz. It contains about 118 hours of speech.
About TEDLIUM_release2 dataset:
This is the TED-LIUM corpus release 2, licensed under Creative Commons BY-NC-ND 3.0. All talks and text are property of TED Conferences LLC. The TED-LIUM corpus was made from audio talks and their transcriptions available on the TED website. These data were prepared and filtered in order to train acoustic models to participate to the International Workshop on Spoken Language Translation 2011 (the LIUM English/French SLT system reached the first rank in the SLT task).
About TEDLIUM_release-3 dataset:
This is the TED-LIUM corpus release 3, licensed under Creative Commons BY-NC-ND 3.0. All talks and text are property of TED Conferences LLC. This new TED-LIUM release was made through a collaboration between the Ubiqus company and the LIUM (University of Le Mans, France).
You can unzip the dataset files into the following directory structure and read by MindSpore's API.
The structure of TEDLIUM release2 is the same as TEDLIUM release1, only the data is different.
. └──TEDLIUM_release1 └── dev ├── sph ├── AlGore_2009.sph ├── BarrySchwartz_2005G.sph ├── stm ├── AlGore_2009.stm ├── BarrySchwartz_2005G.stm └── test ├── sph ├── AimeeMullins_2009P.sph ├── BillGates_2010.sph ├── stm ├── AimeeMullins_2009P.stm ├── BillGates_2010.stm └── train ├── sph ├── AaronHuey_2010X.sph ├── AdamGrosser_2007.sph ├── stm ├── AaronHuey_2010X.stm ├── AdamGrosser_2007.stm └── readme └── TEDLIUM.150k.dicThe directory structure of TEDLIUM release3 is slightly different.
. └──TEDLIUM_release-3 └── data ├── ctl ├── sph ├── 911Mothers_2010W.sph ├── AalaElKhani.sph ├── stm ├── 911Mothers_2010W.stm ├── AalaElKhani.stm └── doc └── legacy └── LM └── speaker-adaptation └── readme └── TEDLIUM.150k.dicCitation:
@article{ title={TED-LIUM: an automatic speech recognition dedicated corpus}, author={A. Rousseau, P. Deléglise, Y. Estève}, journal={Proceedings of the Eighth International Conference on Language Resources and Evaluation (LREC'12)}, year={May 2012}, biburl={https://www.openslr.org/7/} } @article{ title={Enhancing the TED-LIUM Corpus with Selected Data for Language Modeling and More TED Talks}, author={A. Rousseau, P. Deléglise, and Y. Estève}, journal={Proceedings of the Eighth International Conference on Language Resources and Evaluation (LREC'12)}, year={May 2014}, biburl={https://www.openslr.org/19/} } @article{ title={TED-LIUM 3: twice as much data and corpus repartition for experiments on speaker adaptation}, author={François Hernandez, Vincent Nguyen, Sahar Ghannay, Natalia Tomashenko, and Yannick Estève}, journal={the 20th International Conference on Speech and Computer (SPECOM 2018)}, year={September 2018}, biburl={https://www.openslr.org/51/} }
- class mindspore.dataset.TextFileDataset(dataset_files, num_samples=None, num_parallel_workers=None, shuffle=Shuffle.GLOBAL, num_shards=None, shard_id=None, cache=None)[source]
A source dataset that reads and parses datasets stored on disk in text format. The generated dataset has one column
[text]with type string.- Parameters:
dataset_files (Union[str, list[str]]) – String or list of files to be read or glob strings to search for a pattern of files. The list will be sorted in a lexicographical order.
num_samples (int, optional) – The number of samples to be included in the dataset. Default:
None, will include all samples.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (Union[bool, Shuffle], optional) –
Perform reshuffling of the data every epoch. Bool type and Shuffle enum are both supported to pass in. Default:
Shuffle.GLOBAL. If shuffle isFalse, no shuffling will be performed. If shuffle isTrue, performs global shuffle. There are two levels of shuffling, desired shuffle enum defined bymindspore.dataset.Shuffle.Shuffle.GLOBAL: Shuffle both the files and samples, same as setting shuffle to True.Shuffle.FILES: Shuffle files only.
num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the maximum sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
ValueError – If dataset_files are not valid or do not exist.
ValueError – If num_parallel_workers exceeds the max thread numbers.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If shard_id is not in range of [0, num_shards ).
- Tutorial Examples:
Examples
>>> import mindspore.dataset as ds >>> text_file_list = ["/path/to/text_file_dataset_file"] # contains 1 or multiple text files >>> dataset = ds.TextFileDataset(dataset_files=text_file_list)
- class mindspore.dataset.UDPOSDataset(dataset_dir, usage=None, num_samples=None, shuffle=Shuffle.GLOBAL, num_shards=None, shard_id=None, num_parallel_workers=None, cache=None)[source]
UDPOS(Universal Dependencies dataset for Part of Speech) dataset.
The generated dataset has three columns:
[word, universal, stanford], and the data type of three columns is string.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
usage (str, optional) – Usage of this dataset, can be
'train','test','valid'or'all'.'train'will read from 12,543 train samples,'test'will read from 2,077 test samples,'valid'will read from 2,002 test samples,'all'will read from all 16,622 samples. Default:None, all samples.num_samples (int, optional) – Number of samples (rows) to read. Default:
None, reads the full dataset.shuffle (Union[bool, Shuffle], optional) –
Perform reshuffling of the data every epoch. Bool type and Shuffle enum are both supported to pass in. Default:
Shuffle.GLOBAL. If shuffle isFalse, no shuffling will be performed. If shuffle isTrue, it is equivalent to setting shuffle toShuffle.GLOBAL. Set the mode of data shuffling by passing in enumeration variables:Shuffle.GLOBAL: Shuffle both the files and samples.Shuffle.FILES: Shuffle files only.
num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the max sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir does not contain data files.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If num_parallel_workers exceeds the max thread numbers.
- Tutorial Examples:
Examples
>>> import mindspore.dataset as ds >>> udpos_dataset_dir = "/path/to/udpos_dataset_dir" >>> dataset = ds.UDPOSDataset(dataset_dir=udpos_dataset_dir, usage='all')
About UDPOS dataset:
Text corpus dataset that clarifies syntactic or semantic sentence structure. The corpus comprises 254,830 words and 16,622 sentences, taken from various web media including weblogs, newsgroups, emails and reviews.
Citation:
@inproceedings{silveira14gold, year = {2014}, author = {Natalia Silveira and Timothy Dozat and Marie-Catherine de Marneffe and Samuel Bowman and Miriam Connor and John Bauer and Christopher D. Manning}, title = {A Gold Standard Dependency Corpus for {E}nglish}, booktitle = {Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC-2014)} }
- class mindspore.dataset.USPSDataset(dataset_dir, usage=None, num_samples=None, num_parallel_workers=None, shuffle=Shuffle.GLOBAL, num_shards=None, shard_id=None, cache=None)[source]
USPS(U.S. Postal Service) dataset.
The generated dataset has two columns:
[image, label]. The tensor of columnimageis of the uint8 type. The tensor of columnlabelis of the uint32 type.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
usage (str, optional) – Usage of this dataset, can be
'train','test'or'all'.'train'will read from 7,291 train samples,'test'will read from 2,007 test samples,'all'will read from all 9,298 samples. Default:None, will read all samples.num_samples (int, optional) – The number of images to be included in the dataset. Default:
None, will read all images.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (Union[bool, Shuffle], optional) –
Perform reshuffling of the data every epoch. Bool type and Shuffle enum are both supported to pass in. Default:
Shuffle.GLOBAL. If shuffle isFalse, no shuffling will be performed. If shuffle isTrue, it is equivalent to setting shuffle toShuffle.GLOBAL. Set the mode of data shuffling by passing in enumeration variables:Shuffle.GLOBAL: Shuffle both the files and samples.Shuffle.FILES: Shuffle files only.
num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the max sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir is not valid or does not exist or does not contain data files.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If usage is invalid.
ValueError – If num_parallel_workers exceeds the max thread numbers.
ValueError – If shard_id is not in range of [0, num_shards ).
- Tutorial Examples:
Examples
>>> import mindspore.dataset as ds >>> usps_dataset_dir = "/path/to/usps_dataset_directory" >>> >>> # Read 3 samples from USPS dataset >>> dataset = ds.USPSDataset(dataset_dir=usps_dataset_dir, num_samples=3)
About USPS dataset:
USPS is a digit dataset automatically scanned from envelopes by the U.S. Postal Service containing a total of 9,298 16×16 pixel grayscale samples. The images are centered, normalized and show a broad range of font styles.
Here is the original USPS dataset structure. You can download and unzip the dataset files into this directory structure and read by MindSpore's API.
. └── usps_dataset_dir ├── usps ├── usps.tCitation:
@article{hull1994database, title={A database for handwritten text recognition research}, author={Hull, Jonathan J.}, journal={IEEE Transactions on pattern analysis and machine intelligence}, volume={16}, number={5}, pages={550--554}, year={1994}, publisher={IEEE} }
- class mindspore.dataset.VOCDataset(dataset_dir, task='Segmentation', usage='train', class_indexing=None, num_samples=None, num_parallel_workers=None, shuffle=None, decode=False, sampler=None, num_shards=None, shard_id=None, cache=None, extra_metadata=False, decrypt=None)[source]
VOC(Visual Object Classes) dataset.
The generated dataset with different task setting has different output columns:
task =
Detection, output columns:[image, dtype=uint8],[bbox, dtype=float32],[label, dtype=uint32],[difficult, dtype=uint32],[truncate, dtype=uint32].task =
Segmentation, output columns:[image, dtype=uint8],[target,dtype=uint8].
- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
task (str, optional) – Set the task type of reading voc data, now only support
'Segmentation'or'Detection'. Default:'Segmentation'.usage (str, optional) – Set the task type of ImageSets. Default:
'train'. If task is'Segmentation', image and annotation list will be loaded in ./ImageSets/Segmentation/usage + ".txt"; If task is 'Detection', image and annotation list will be loaded in ./ImageSets/Main/usage + ".txt"; if task and usage are not set, image and annotation list will be loaded in ./ImageSets/Segmentation/train.txt as default.class_indexing (dict, optional) – A str-to-int mapping from label name to index, only valid in 'Detection' task. Default:
None, the folder names will be sorted alphabetically and each class will be given a unique index starting from 0.num_samples (int, optional) – The number of images to be included in the dataset. Default:
None, all images.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (bool, optional) – Whether to perform shuffle on the dataset. Default:
None, expected order behavior shown in the table below.decode (bool, optional) – Decode the images after reading. Default:
False.sampler (Sampler, optional) – Object used to choose samples from the dataset. Default:
None, expected order behavior shown in the table below.num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the maximum sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.extra_metadata (bool, optional) – Flag to add extra meta-data to row. If True, an additional column named
[_meta-filename, dtype=string]will be output at the end. Default:False.decrypt (callable, optional) – Image decryption function, which accepts the path of the encrypted image file and returns the decrypted bytes data. Default:
None, no decryption.
- Raises:
RuntimeError – If dataset_dir does not contain data files.
RuntimeError – If xml of Annotations is an invalid format.
RuntimeError – If xml of Annotations lacks attribute of object .
RuntimeError – If xml of Annotations lacks attribute of bndbox .
RuntimeError – If sampler and shuffle are specified at the same time.
RuntimeError – If sampler and num_shards/shard_id are specified at the same time.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If num_parallel_workers exceeds the max thread numbers.
ValueError – If task is not equal
'Segmentation'or'Detection'.ValueError – If task is
'Segmentation'but class_indexing is notNone.ValueError – If txt related to mode does not exist.
ValueError – If shard_id is not in range of [0, num_shards ).
- Tutorial Examples:
Note
Column '[_meta-filename, dtype=string]' won't be output unless an explicit rename dataset op is added to remove the prefix('_meta-').
The parameters num_samples , shuffle , num_shards , shard_id can be used to control the sampler used in the dataset, and their effects when combined with parameter sampler are as follows.
Examples
>>> import mindspore.dataset as ds >>> voc_dataset_dir = "/path/to/voc_dataset_directory" >>> >>> # 1) Read VOC data for segmentation training >>> dataset = ds.VOCDataset(dataset_dir=voc_dataset_dir, task="Segmentation", usage="train") >>> >>> # 2) Read VOC data for detection training >>> dataset = ds.VOCDataset(dataset_dir=voc_dataset_dir, task="Detection", usage="train") >>> >>> # 3) Read all VOC dataset samples in voc_dataset_dir with 8 threads in random order >>> dataset = ds.VOCDataset(dataset_dir=voc_dataset_dir, task="Detection", usage="train", ... num_parallel_workers=8) >>> >>> # 4) Read then decode all VOC dataset samples in voc_dataset_dir in sequence >>> dataset = ds.VOCDataset(dataset_dir=voc_dataset_dir, task="Detection", usage="train", ... decode=True, shuffle=False) >>> >>> # In VOC dataset, if task='Segmentation', each dictionary has keys "image" and "target" >>> # In VOC dataset, if task='Detection', each dictionary has keys "image" and "annotation"
About VOC dataset:
The PASCAL Visual Object Classes (VOC) challenge is a benchmark in visual object category recognition and detection, providing the vision and machine learning communities with a standard dataset of images and annotation, and standard evaluation procedures.
You can unzip the original VOC-2012 dataset files into this directory structure and read by MindSpore's API.
. └── voc2012_dataset_dir ├── Annotations │ ├── 2007_000027.xml │ ├── 2007_000032.xml │ ├── ... ├── ImageSets │ ├── Action │ ├── Layout │ ├── Main │ └── Segmentation ├── JPEGImages │ ├── 2007_000027.jpg │ ├── 2007_000032.jpg │ ├── ... ├── SegmentationClass │ ├── 2007_000032.png │ ├── 2007_000033.png │ ├── ... └── SegmentationObject ├── 2007_000032.png ├── 2007_000033.png ├── ...Citation:
@article{Everingham10, author = {Everingham, M. and Van~Gool, L. and Williams, C. K. I. and Winn, J. and Zisserman, A.}, title = {The Pascal Visual Object Classes (VOC) Challenge}, journal = {International Journal of Computer Vision}, volume = {88}, year = {2012}, number = {2}, month = {jun}, pages = {303--338}, biburl = {http://host.robots.ox.ac.uk/pascal/VOC/pubs/everingham10.html#bibtex}, howpublished = {http://host.robots.ox.ac.uk/pascal/VOC/voc2012/index.html} }
- get_class_indexing()[source]
Get the class index.
- Returns:
dict, a str-to-int mapping from label name to index.
Examples
>>> import mindspore.dataset as ds >>> voc_dataset_dir = "/path/to/voc_dataset_directory" >>> >>> dataset = ds.VOCDataset(dataset_dir=voc_dataset_dir, task="Detection") >>> class_indexing = dataset.get_class_indexing()
- class mindspore.dataset.WIDERFaceDataset(dataset_dir, usage=None, num_samples=None, num_parallel_workers=None, shuffle=None, decode=False, sampler=None, num_shards=None, shard_id=None, cache=None)[source]
WIDERFace dataset.
When usage is "train", "valid" or "all", the generated dataset has eight columns ["image", "bbox", "blur", "expression", "illumination", "occlusion", "pose", "invalid"]. The data type of the image column is uint8, and all other columns are uint32. When usage is "test", it only has one column ["image"], with uint8 data type.
- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
usage (str, optional) – Usage of this dataset, can be
'train','test','valid'or'all'.'train'will read from 12,880 samples,'test'will read from 16,097 samples,'valid'will read from 3,226 test samples and'all'will read all'train'and'valid'samples. Default:None, will be set to'all'.num_samples (int, optional) – The number of images to be included in the dataset. Default:
None, will read all images.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (bool, optional) – Whether or not to perform shuffle on the dataset. Default:
None, expected order behavior shown in the table below.decode (bool, optional) – Decode the images after reading. Default:
False, not decoding.sampler (Sampler, optional) – Object used to choose samples from the dataset. Default:
None, expected order behavior shown in the table below.num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the maximum sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir does not contain data files.
RuntimeError – If sampler and shuffle are specified at the same time.
RuntimeError – If sampler and num_shards/shard_id are specified at the same time.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If shard_id is not in range of [0, num_shards ).
ValueError – If usage is not
'train','test','valid','all'.ValueError – If num_parallel_workers exceeds the max thread numbers.
ValueError – If dataset_dir does not exist.
- Tutorial Examples:
Note
The parameters num_samples , shuffle , num_shards , shard_id can be used to control the sampler used in the dataset, and their effects when combined with parameter sampler are as follows.
Examples
>>> import mindspore.dataset as ds >>> wider_face_dir = "/path/to/wider_face_dataset" >>> >>> # Read 3 samples from WIDERFace dataset >>> dataset = ds.WIDERFaceDataset(dataset_dir=wider_face_dir, num_samples=3)
About WIDERFace dataset:
The WIDERFace database has a training set of 12,880 samples, a testing set of 16,097 examples and a validating set of 3,226 examples. It is a subset of a larger set available from WIDER. The digits have been size-normalized and centered in a fixed-size image.
The following is the original WIDERFace dataset structure. You can unzip the dataset files into this directory structure and read by MindSpore's API.
. └── wider_face_dir ├── WIDER_test │ └── images │ ├── 0--Parade │ │ ├── 0_Parade_marchingband_1_9.jpg │ │ ├── ... │ ├──1--Handshaking │ ├──... ├── WIDER_train │ └── images │ ├── 0--Parade │ │ ├── 0_Parade_marchingband_1_11.jpg │ │ ├── ... │ ├──1--Handshaking │ ├──... ├── WIDER_val │ └── images │ ├── 0--Parade │ │ ├── 0_Parade_marchingband_1_102.jpg │ │ ├── ... │ ├──1--Handshaking │ ├──... └── wider_face_split ├── wider_face_test_filelist.txt ├── wider_face_train_bbx_gt.txt └── wider_face_val_bbx_gt.txtCitation:
@inproceedings{2016WIDER, title={WIDERFACE: A Detection Benchmark}, author={Yang, S. and Luo, P. and Loy, C. C. and Tang, X.}, booktitle={IEEE}, pages={5525-5533}, year={2016}, }
- class mindspore.dataset.WaitedDSCallback(step_size=1)[source]
Abstract base class used to build dataset callback classes that are synchronized with the training callback class mindspore.train.Callback .
It can be used to execute a custom callback method before a step or an epoch, such as updating the parameters of operations according to the loss of the previous training epoch in auto augmentation.
Users can obtain the network training context through train_run_context , such as network , train_network , epoch_num , batch_num , loss_fn , optimizer , parallel_mode , device_number , list_callback , cur_epoch_num , cur_step_num , dataset_sink_mode , net_outputs , etc., see mindspore.train.Callback .
Users can obtain the dataset pipeline context through ds_run_context , including cur_epoch_num , cur_step_num_in_epoch and cur_step_num .
Note
Note that the call is triggered only at the beginning of the second step or epoch.
- Parameters:
step_size (int, optional) – The number of rows in each step, usually set equal to the batch size. Default:
1.
Examples
>>> import mindspore as ms >>> import mindspore.dataset as ds >>> import mindspore.nn as nn >>> from mindspore.dataset import WaitedDSCallback >>> >>> ms.set_context(mode=ms.GRAPH_MODE) >>> ms.set_device(device_target="CPU") >>> >>> # custom callback class for data synchronization in data pipeline >>> class MyWaitedCallback(WaitedDSCallback): ... def __init__(self, events, step_size=1): ... super().__init__(step_size) ... self.events = events ... ... # callback method to be executed by data pipeline before the epoch starts ... def sync_epoch_begin(self, train_run_context, ds_run_context): ... event = f"ds_epoch_begin_{ds_run_context.cur_epoch_num}_{ds_run_context.cur_step_num}" ... self.events.append(event) ... ... # callback method to be executed by data pipeline before the step starts ... def sync_step_begin(self, train_run_context, ds_run_context): ... event = f"ds_step_begin_{ds_run_context.cur_epoch_num}_{ds_run_context.cur_step_num}" ... self.events.append(event) >>> >>> # custom callback class for data synchronization in network training >>> class MyMSCallback(ms.Callback): ... def __init__(self, events): ... self.events = events ... ... # callback method to be executed by network training after the epoch ends ... def epoch_end(self, run_context): ... cb_params = run_context.original_args() ... event = f"ms_epoch_end_{cb_params.cur_epoch_num}_{cb_params.cur_step_num}" ... self.events.append(event) ... ... # callback method to be executed by network training after the step ends ... def step_end(self, run_context): ... cb_params = run_context.original_args() ... event = f"ms_step_end_{cb_params.cur_epoch_num}_{cb_params.cur_step_num}" ... self.events.append(event) >>> >>> # custom network >>> class Net(nn.Cell): ... def construct(self, x, y): ... return x >>> >>> # define a parameter that needs to be synchronized between data pipeline and network training >>> events = [] >>> >>> # define callback classes of data pipeline and network training >>> my_cb1 = MyWaitedCallback(events, 1) >>> my_cb2 = MyMSCallback(events) >>> arr = [1, 2, 3, 4] >>> >>> # construct data pipeline >>> data = ds.NumpySlicesDataset((arr, arr), column_names=["c1", "c2"], shuffle=False) >>> # map the data callback object into the pipeline >>> data = data.map(operations=(lambda x: x), callbacks=my_cb1) >>> >>> net = Net() >>> model = ms.train.Model(net) >>> >>> # add the data and network callback objects to the model training callback list >>> model.train(2, data, dataset_sink_mode=False, callbacks=[my_cb2, my_cb1])
- create_runtime_obj()[source]
Internal method, creates a runtime (C++) object from the callback methods defined by the user.
- Returns:
_c_dataengine.PyDSCallback.
- ds_epoch_begin(ds_run_context)[source]
Internal method, do not call/override. Define mindspore.dataset.DSCallback.ds_epoch_begin to wait for mindspore.train.callback.Callback.epoch_end.
- Parameters:
ds_run_context – Include some information of the data pipeline.
- ds_step_begin(ds_run_context)[source]
Internal method, do not call/override. Define mindspore.dataset.DSCallback.ds_step_begin to wait for mindspore.train.callback.Callback.step_end.
- Parameters:
ds_run_context – Include some information of the data pipeline.
- end(run_context)[source]
Internal method, release wait when the network training ends.
- Parameters:
run_context – Include some information of the model.
- epoch_end(run_context)[source]
Internal method, do not call/override. Defines epoch_end of Callback to release the wait in ds_epoch_begin.
- Parameters:
run_context – Include some information of the model.
- step_end(run_context)[source]
Internal method, do not call/override. Defines step_end of Callback to release the wait in ds_step_begin.
- Parameters:
run_context – Include some information of the model.
- sync_epoch_begin(train_run_context, ds_run_context)[source]
Called before a new dataset epoch is started and after the previous training epoch is ended.
- Parameters:
train_run_context – Include some information of the model with feedback from the previous epoch.
ds_run_context – Include some information of the data pipeline.
- sync_step_begin(train_run_context, ds_run_context)[source]
Called before a new dataset step is started and after the previous training step is ended.
- Parameters:
train_run_context – Include some information of the model with feedback from the previous step.
ds_run_context – Include some information of the data pipeline.
- class mindspore.dataset.WeightedRandomSampler(weights, num_samples=None, replacement=True)[source]
Samples the elements from [0, len(weights) - 1] randomly with the given weights (probabilities).
- Parameters:
- Raises:
TypeError – If elements of weights are not of type number.
TypeError – If num_samples is not of type int.
TypeError – If replacement is not of type bool.
RuntimeError – If weights is empty or all zero.
ValueError – If num_samples is a negative value.
Examples
>>> import mindspore.dataset as ds >>> weights = [0.9, 0.01, 0.4, 0.8, 0.1, 0.1, 0.3] >>> >>> # creates a WeightedRandomSampler that will sample 4 elements without replacement >>> sampler = ds.WeightedRandomSampler(weights, 4) >>> dataset = ds.ImageFolderDataset(image_folder_dataset_dir, ... num_parallel_workers=8, ... sampler=sampler)
- class mindspore.dataset.WikiTextDataset(dataset_dir, usage=None, num_samples=None, num_parallel_workers=None, shuffle=Shuffle.GLOBAL, num_shards=None, shard_id=None, cache=None)[source]
WikiText2 and WikiText103 datasets.
The generated dataset has one column
[text], and the tensor of column text is of the string type.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
usage (str, optional) – Acceptable usages include
'train','test','valid'and'all'. Default:None, all samples.num_samples (int, optional) – Number of samples (rows) to read. Default:
None, reads the full dataset.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (Union[bool, Shuffle], optional) –
Perform reshuffling of the data every epoch. Bool type and Shuffle enum are both supported to pass in. Default:
Shuffle.GLOBAL. If shuffle isFalse, no shuffling will be performed. If shuffle isTrue, it is equivalent to setting shuffle toShuffle.GLOBAL. Set the mode of data shuffling by passing in enumeration variables:Shuffle.GLOBAL: Shuffle both the files and samples.Shuffle.FILES: Shuffle files only.
num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the max sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir does not contain data files or invalid.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If shard_id is not in range of [0, num_shards ).
ValueError – If num_samples is invalid (< 0).
ValueError – If num_parallel_workers exceeds the max thread numbers.
- Tutorial Examples:
About WikiTextDataset dataset:
The WikiText Long Term Dependency Language Modeling Dataset is an English lexicon containing 100 million words. These terms are drawn from Wikipedia's premium and benchmark articles, including versions of Wikitext2 and Wikitext103. For WikiText2, it has 36718 lines in wiki.train.tokens, 4358 lines in wiki.test.tokens and 3760 lines in wiki.valid.tokens. For WikiText103, it has 1801350 lines in wiki.train.tokens, 4358 lines in wiki.test.tokens and 3760 lines in wiki.valid.tokens.
Here is the original WikiText dataset structure. You can unzip the dataset files into this directory structure and read by MindSpore's API.
. └── WikiText2/WikiText103 ├── wiki.train.tokens ├── wiki.test.tokens ├── wiki.valid.tokensCitation:
@article{merity2016pointer, title={Pointer sentinel mixture models}, author={Merity, Stephen and Xiong, Caiming and Bradbury, James and Socher, Richard}, journal={arXiv preprint arXiv:1609.07843}, year={2016} }
Examples
>>> import mindspore.dataset as ds >>> wiki_text_dataset_dir = "/path/to/wiki_text_dataset_directory" >>> dataset = ds.WikiTextDataset(dataset_dir=wiki_text_dataset_dir, usage='all')
- class mindspore.dataset.YahooAnswersDataset(dataset_dir, usage=None, num_samples=None, num_parallel_workers=None, shuffle=Shuffle.GLOBAL, num_shards=None, shard_id=None, cache=None)[source]
YahooAnswers dataset.
The generated dataset has four columns
[class, title, content, answer], whose data type is string.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
usage (str, optional) – Usage of this dataset, can be
'train','test'or'all'.'train'will read from 1,400,000 train samples,'test'will read from 60,000 test samples,'all'will read from all 1,460,000 samples. Default:None, all samples.num_samples (int, optional) – The number of samples to be included in the dataset. Default:
None, will include all text.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (Union[bool, Shuffle], optional) –
Perform reshuffling of the data every epoch. Bool type and Shuffle enum are both supported to pass in. Default:
Shuffle.GLOBAL. If shuffle isFalse, no shuffling will be performed. If shuffle isTrue, it is equivalent to setting shuffle toShuffle.GLOBAL. Set the mode of data shuffling by passing in enumeration variables:Shuffle.GLOBAL: Shuffle both the files and samples.Shuffle.FILES: Shuffle files only.
num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the maximum sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir does not contain data files.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If shard_id is not in range of [0, num_shards ).
ValueError – If num_parallel_workers exceeds the max thread numbers.
- Tutorial Examples:
Examples
>>> import mindspore.dataset as ds >>> yahoo_answers_dataset_dir = "/path/to/yahoo_answers_dataset_directory" >>> >>> # 1) Read 3 samples from YahooAnswers dataset >>> dataset = ds.YahooAnswersDataset(dataset_dir=yahoo_answers_dataset_dir, num_samples=3) >>> >>> # 2) Read train samples from YahooAnswers dataset >>> dataset = ds.YahooAnswersDataset(dataset_dir=yahoo_answers_dataset_dir, usage="train")
About YahooAnswers dataset:
The YahooAnswers dataset consists of 630,000 text samples in 10 classes. There are 560,000 samples in the train.csv and 70,000 samples in the test.csv. The 10 different classes represent Society & Culture, Science & Mathematics, Health, Education & Reference, Computers & Internet, Sports, Business & Finance, Entertainment & Music, Family & Relationships, Politics & Government.
Here is the original YahooAnswers dataset structure. You can unzip the dataset files into this directory structure and read by MindSpore's API.
. └── yahoo_answers_dataset_dir ├── train.csv ├── test.csv ├── classes.txt └── readme.txtCitation:
@article{YahooAnswers, title = {Yahoo! Answers Topic Classification Dataset}, author = {Xiang Zhang}, year = {2015}, howpublished = {} }
- class mindspore.dataset.YelpReviewDataset(dataset_dir, usage=None, num_samples=None, shuffle=Shuffle.GLOBAL, num_shards=None, shard_id=None, num_parallel_workers=None, cache=None)[source]
Yelp Review Polarity and Yelp Review Full datasets.
The generated dataset has two columns:
[label, text], and the data type of two columns is string.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
usage (str, optional) –
Usage of this dataset, can be
'train','test'or'all'. Default:None, all samples.For Polarity,
'train'will read from 560,000 train samples,'test'will read from 38,000 test samples,'all'will read from all 598,000 samples.For Full,
'train'will read from 650,000 train samples,'test'will read from 50,000 test samples,'all'will read from all 700,000 samples.
num_samples (int, optional) – Number of samples (rows) to read. Default:
None, reads all samples.shuffle (Union[bool, Shuffle], optional) –
Perform reshuffling of the data every epoch. Bool type and Shuffle enum are both supported to pass in. Default:
Shuffle.GLOBAL. If shuffle isFalse, no shuffling will be performed. If shuffle isTrue, it is equivalent to setting shuffle toShuffle.GLOBAL. Set the mode of data shuffling by passing in enumeration variables:Shuffle.GLOBAL: Shuffle both the files and samples.Shuffle.FILES: Shuffle files only.
num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the max sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir does not contain data files.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If num_parallel_workers exceeds the max thread numbers.
- Tutorial Examples:
Examples
>>> import mindspore.dataset as ds >>> yelp_review_dataset_dir = "/path/to/yelp_review_dataset_dir" >>> dataset = ds.YelpReviewDataset(dataset_dir=yelp_review_dataset_dir, usage='all')
About YelpReview Dataset:
The Yelp Review Full dataset consists of reviews from Yelp. It is extracted from the Yelp Dataset Challenge 2015 data, and it is mainly used for text classification.
The Yelp Review Polarity dataset is constructed from the above dataset, by considering stars 1 and 2 negative, and 3 and 4 positive.
The directory structures of these two datasets are the same. You can unzip the dataset files into the following structure and read by MindSpore's API:
. └── yelp_review_dir ├── train.csv ├── test.csv └── readme.txtCitation:
For Yelp Review Polarity:
@article{zhangCharacterlevelConvolutionalNetworks2015, archivePrefix = {arXiv}, eprinttype = {arxiv}, eprint = {1509.01626}, primaryClass = {cs}, title = {Character-Level {{Convolutional Networks}} for {{Text Classification}}}, abstract = {This article offers an empirical exploration on the use of character-level convolutional networks (ConvNets) for text classification. We constructed several large-scale datasets to show that character-level convolutional networks could achieve state-of-the-art or competitive results. Comparisons are offered against traditional models such as bag of words, n-grams and their TFIDF variants, and deep learning models such as word-based ConvNets and recurrent neural networks.}, journal = {arXiv:1509.01626 [cs]}, author = {Zhang, Xiang and Zhao, Junbo and LeCun, Yann}, month = sep, year = {2015}, }
Citation:
For Yelp Review Full:
@article{zhangCharacterlevelConvolutionalNetworks2015, archivePrefix = {arXiv}, eprinttype = {arxiv}, eprint = {1509.01626}, primaryClass = {cs}, title = {Character-Level {{Convolutional Networks}} for {{Text Classification}}}, abstract = {This article offers an empirical exploration on the use of character-level convolutional networks (ConvNets) for text classification. We constructed several large-scale datasets to show that character-level convolutional networks could achieve state-of-the-art or competitive results. Comparisons are offered against traditional models such as bag of words, n-grams and their TFIDF variants, and deep learning models such as word-based ConvNets and recurrent neural networks.}, journal = {arXiv:1509.01626 [cs]}, author = {Zhang, Xiang and Zhao, Junbo and LeCun, Yann}, month = sep, year = {2015}, }
- class mindspore.dataset.YesNoDataset(dataset_dir, num_samples=None, num_parallel_workers=None, shuffle=None, sampler=None, num_shards=None, shard_id=None, cache=None)[source]
YesNo dataset.
The generated dataset has three columns
[waveform, sample_rate, labels]. The tensor of columnwaveformis a vector of the float32 type. The tensor of columnsample_rateis a scalar of the int32 type. The tensor of columnlabelsis a scalar of the int32 type.- Parameters:
dataset_dir (str) – Path to the root directory that contains the dataset.
num_samples (int, optional) – The number of audio to be included in the dataset. Default:
None, will read all audio.num_parallel_workers (int, optional) – Number of worker threads to read the data. Default:
None, will use global default workers(8), it can be set bymindspore.dataset.config.set_num_parallel_workers().shuffle (bool, optional) – Whether or not to perform shuffle on the dataset. Default:
None, expected order behavior shown in the table below.sampler (Sampler, optional) – Object used to choose samples from the dataset. Default:
None, expected order behavior shown in the table below.num_shards (int, optional) –
Number of shards that the dataset will be divided into. Default:
None. When this argument is specified, num_samples reflects the maximum sample number per shard. Used in data parallel training .shard_id (int, optional) – The shard ID within num_shards . Default:
None. This argument can only be specified when num_shards is also specified.cache (DatasetCache, optional) –
Use tensor caching service to speed up dataset processing. More details: Single-Node Data Cache . Default:
None, which means no cache is used.
- Raises:
RuntimeError – If dataset_dir does not contain data files.
ValueError – If num_parallel_workers exceeds the max thread numbers.
RuntimeError – If sampler and shuffle are specified at the same time.
RuntimeError – If sampler and num_shards/shard_id are specified at the same time.
RuntimeError – If num_shards is specified but shard_id is None.
RuntimeError – If shard_id is specified but num_shards is None.
ValueError – If shard_id is not in range of [0, num_shards ).
- Tutorial Examples:
Note
The parameters num_samples , shuffle , num_shards , shard_id can be used to control the sampler used in the dataset, and their effects when combined with parameter sampler are as follows.
Examples
>>> import mindspore.dataset as ds >>> yes_no_dataset_dir = "/path/to/yes_no_dataset_directory" >>> >>> # Read 3 samples from YesNo dataset >>> dataset = ds.YesNoDataset(dataset_dir=yes_no_dataset_dir, num_samples=3) >>> >>> # Note: In YesNo dataset, each dictionary has keys "waveform", "sample_rate", "labels"
About YesNo dataset:
Yesno is an audio dataset consisting of 60 recordings of one individual saying yes or no in Hebrew; each recording is eight words long.
Here is the original YesNo dataset structure. You can unzip the dataset files into this directory structure and read by MindSpore's API.
. └── yes_no_dataset_dir ├── 1_1_0_0_1_1_0_0.wav ├── 1_0_0_0_1_1_0_0.wav ├── 1_1_0_0_1_1_0_0.wav └──....Citation:
@NetworkResource{Kaldi_audio_project, author = {anonymous}, url = "http://www.openslr.org/1/" }
- mindspore.dataset.compare(pipeline1, pipeline2)[source]
Compare if two dataset pipelines are the same.
- Parameters:
- Returns:
bool, whether pipeline1 is equal to pipeline2.
Examples
>>> import mindspore.dataset as ds >>> >>> pipeline1 = ds.MnistDataset("/path/to/mnist_dataset_directory", num_samples=100) >>> pipeline2 = ds.Cifar10Dataset("/path/to/cifar10_dataset_directory", num_samples=100) >>> res = ds.compare(pipeline1, pipeline2)
- mindspore.dataset.deserialize(input_dict=None, json_filepath=None)[source]
Deserialize the data processing pipeline. The API accepts a Python dictionary or a JSON file generated by
mindspore.dataset.serialize().- Parameters:
input_dict (dict) – A Python dictionary containing a serialized dataset graph. Default:
None.json_filepath (str) – A path to the JSON file containing the dataset graph. User can obtain this file by calling API
mindspore.dataset.serialize(). Default:None.
- Returns:
de.Dataset or None if an error occurs.
- Raises:
OSError – Cannot open the JSON file.
Examples
>>> import mindspore.dataset as ds >>> import mindspore.dataset.transforms as transforms >>> >>> mnist_dataset_dir = "/path/to/mnist_dataset_directory" >>> dataset = ds.MnistDataset(mnist_dataset_dir, num_samples=100) >>> one_hot_encode = transforms.OneHot(10) # num_classes is input argument >>> dataset = dataset.map(operations=one_hot_encode, input_columns="label") >>> dataset = dataset.batch(batch_size=10, drop_remainder=True) >>> >>> # Case 1: to/from JSON file >>> serialized_data = ds.serialize(dataset, json_filepath="/path/to/mnist_dataset_pipeline.json") >>> deserialized_dataset = ds.deserialize(json_filepath="/path/to/mnist_dataset_pipeline.json") >>> >>> # Case 2: to/from Python dictionary >>> serialized_data = ds.serialize(dataset) >>> deserialized_dataset = ds.deserialize(input_dict=serialized_data)
- mindspore.dataset.serialize(dataset, json_filepath='')[source]
Serialize dataset pipeline into a JSON file.
Note
Complete serialization of Python objects is not currently supported. Scenarios that are not supported include data pipelines that use GeneratorDataset or map / batch operations that contain custom Python functions. For Python objects, serialization operations do not yield the full object content, which means that deserialization of the JSON file obtained by serialization may result in errors. For example, when serializing the data pipeline of Python user-defined functions, a related warning message appears and the obtained JSON file cannot be deserialized into a usable data pipeline.
- Parameters:
- Returns:
Dict, the dictionary containing the serialized dataset graph.
- Raises:
OSError – Cannot open a file.
Examples
>>> import mindspore.dataset as ds >>> import mindspore.dataset.transforms as transforms >>> >>> mnist_dataset_dir = "/path/to/mnist_dataset_directory" >>> dataset = ds.MnistDataset(mnist_dataset_dir, num_samples=100) >>> one_hot_encode = transforms.OneHot(10) # num_classes is input argument >>> dataset = dataset.map(operations=one_hot_encode, input_columns="label") >>> dataset = dataset.batch(batch_size=10, drop_remainder=True) >>> # serialize it to JSON file >>> serialized_data = ds.serialize(dataset, json_filepath="/path/to/mnist_dataset_pipeline.json")
- mindspore.dataset.show(dataset, indentation=2)[source]
Write the dataset pipeline graph to the logger.info file.
- Parameters:
Examples
>>> import mindspore.dataset as ds >>> import mindspore.dataset.transforms as transforms >>> >>> mnist_dataset_dir = "/path/to/mnist_dataset_directory" >>> dataset = ds.MnistDataset(mnist_dataset_dir, num_samples=100) >>> one_hot_encode = transforms.OneHot(10) >>> dataset = dataset.map(operations=one_hot_encode, input_columns="label") >>> dataset = dataset.batch(batch_size=10, drop_remainder=True) >>> ds.show(dataset)
- mindspore.dataset.sync_wait_for_dataset(rank_id, rank_size, current_epoch, obs_runtime)[source]
Wait until the dataset files required by all devices are downloaded.
Note
This function will be automatically executed during the iteration of
mindspore.dataset.OBSMindDataset, and no manual call is required.
- mindspore.dataset.zip(datasets)[source]
Zip the datasets in the input tuple of datasets.
- Parameters:
datasets (tuple[Dataset]) – A tuple of datasets to be zipped together. The number of datasets must be more than 1.
- Returns:
Dataset, a new dataset with the above operation applied.
- Raises:
ValueError – If the number of datasets is 1.
TypeError – If datasets is not a tuple.
Examples
>>> # Create a dataset which is the combination of dataset_1 and dataset_2 >>> import mindspore.dataset as ds >>> >>> dataset_1 = ds.GeneratorDataset([1], "column1") >>> dataset_2 = ds.GeneratorDataset([2], "column2") >>> dataset = ds.zip((dataset_1, dataset_2))
User Defined
A source dataset that generates data from Python by invoking Python data source each epoch. |
Standard Format
A source dataset that reads and parses MindRecord dataset. |
|
A source dataset that reads and parses MindRecord dataset which stored in cloud storage such as OBS, Minio or AWS S3. |
|
A source dataset that reads and parses datasets stored on disk in TFData format. |
Open Source
Vision
Caltech 101 dataset. |
|
Caltech 256 dataset. |
|
CelebA(CelebFaces Attributes) dataset. |
|
CIFAR-10 dataset. |
|
CIFAR-100 dataset. |
|
Cityscapes dataset. |
|
COCO(Common Objects in Context) dataset. |
|
DIV2K(DIVerse 2K resolution image) dataset. |
|
EMNIST(Extended MNIST) dataset. |
|
A source dataset for generating fake images. |
|
Fashion-MNIST dataset. |
|
Flickr8k and Flickr30k datasets. |
|
Oxford 102 Flower dataset. |
|
Food101 dataset. |
|
A source dataset that reads images from a tree of directories. |
|
KITTI dataset. |
|
KMNIST(Kuzushiji-MNIST) dataset. |
|
LFW(Labeled Faces in the Wild) dataset. |
|
LSUN(Large-Scale Scene Understanding) dataset. |
|
A source dataset for reading images from a Manifest file. |
|
MNIST dataset. |
|
Omniglot dataset. |
|
PhotoTour dataset. |
|
Places365 dataset. |
|
QMNIST dataset. |
|
RenderedSST2(Rendered Stanford Sentiment Treebank v2) dataset. |
|
SB(Semantic Boundaries) Dataset. |
|
SBU(SBU Captioned Photo) dataset. |
|
Semeion dataset. |
|
STL-10 dataset. |
|
SUN397(Scene UNderstanding) dataset. |
|
SVHN(Street View House Numbers) dataset. |
|
USPS(U.S. |
|
VOC(Visual Object Classes) dataset. |
|
WIDERFace dataset. |
Text
AG News dataset. |
|
Amazon Review Polarity and Amazon Review Full datasets. |
|
CLUE(Chinese Language Understanding Evaluation) dataset. |
|
A source dataset that reads and parses comma-separated values (CSV) files as dataset. |
|
CoNLL-2000 (Conference on Computational Natural Language Learning) chunking dataset. |
|
DBpedia dataset. |
|
EnWik9 dataset. |
|
IMDb(Internet Movie Database) dataset. |
|
IWSLT2016(International Workshop on Spoken Language Translation) dataset. |
|
IWSLT2017(International Workshop on Spoken Language Translation) dataset. |
|
Multi30k dataset. |
|
PennTreebank dataset. |
|
Sogou News dataset. |
|
SQuAD 1.1 and SQuAD 2.0 datasets. |
|
SST2(Stanford Sentiment Treebank v2) dataset. |
|
A source dataset that reads and parses datasets stored on disk in text format. |
|
UDPOS(Universal Dependencies dataset for Part of Speech) dataset. |
|
WikiText2 and WikiText103 datasets. |
|
YahooAnswers dataset. |
|
Yelp Review Polarity and Yelp Review Full datasets. |
Audio
CMU Arctic dataset. |
|
GTZAN dataset. |
|
LibriTTS dataset. |
|
LJSpeech dataset. |
|
Speech Commands dataset. |
|
Tedlium dataset. |
|
YesNo dataset. |
Others
Creates a dataset with given data slices, mainly for loading Python data into dataset. |
|
Creates a dataset with filler data provided by user. |
|
A source dataset that generates random data. |
Sampler
A sampler that accesses a shard of the dataset, it helps divide dataset into multi-subset for distributed training. |
|
Samples K elements for each P class in the dataset. |
|
Samples the elements randomly. |
|
Samples the dataset elements sequentially that is equivalent to not using a sampler. |
|
Samples the elements randomly from a sequence of indices. |
|
Samples the elements from a sequence of indices. |
|
Samples the elements from [0, len(weights) - 1] randomly with the given weights (probabilities). |
Config
The config module can set or obtain the global configuration parameters of the data processing pipeline.
Set the upper limit on the number of batches of data that the Host can send to the Device. |
|
Load the project configuration from the file. |
|
Set the seed for the random number generator in data pipeline. |
|
Get random number seed. |
|
Set the buffer queue size between dataset operations in the pipeline. |
|
Get the prefetch size as the number of rows. |
|
Set a new global configuration default value for the number of parallel workers. |
|
Get the global configuration of the number of parallel workers. |
|
Set the default state of numa enabled. |
|
Get the state of numa to indicate enabled/disabled. |
|
Set the default interval (in milliseconds) for monitor sampling. |
|
Get the global configuration of the sampling interval of the performance monitor. |
|
Set the default timeout (in seconds) for |
|
Get the default timeout (in seconds) for |
|
Set num_parallel_workers for each op automatically (This feature is turned off by default). |
|
Get the setting of automatic number of workers (turned on or off). |
|
Set whether to use shared memory for interprocess communication when data processing multiprocessing is turned on. |
|
Get the default state of shared mem enabled variable. |
|
Set whether to enable AutoTune for data pipeline parameters. |
|
Get whether AutoTune is currently enabled. |
|
Set the configuration adjustment interval (in steps) for AutoTune. |
|
Get the current configuration adjustment interval (in steps) for AutoTune. |
|
Set the automatic offload flag of the dataset. |
|
Get the state of the automatic offload flag (True or False), it is disabled by default. |
|
Set the default state of watchdog Python thread as enabled. |
|
Get the state of watchdog Python thread to indicate enabled or disabled state. |
|
Set whether dataset pipeline should recover in fast mode during failover (In fast mode, random augmentations may not get the same results as before the failure occurred). |
|
Get whether the fast recovery mode is enabled for the current dataset pipeline. |
|
|
In a multi-process/multi-threaded environment, the default interval (in seconds) at which an alert log is printed when the main process/main thread times out while retrieving data. |
|
Get the global configuration of multiprocessing/multithreading timeout when main process/thread gets data from subprocesses/child threads. |
Set the method in which erroneous samples should be processed in a dataset pipeline. |
|
Get the current strategy for processing erroneous samples in a dataset pipeline. |
|
An enumeration for error_samples_mode . |
|
Set the debug_mode flag of the dataset pipeline. |
|
Get whether debug mode is currently enabled for the data pipeline. |
|
Set a global configuration to indicate how to start a subprocess for data preprocessing. |
|
Get the global configuration of multiprocessing start method. |
|
Set the backend used to decode videos. |
|
Returns the currently active backend used to decode videos. |
Tools
This class helps to get dataset information dynamically when the input of batch_size or per_batch_map in batch operation is a callable object. |
|
A client to interface with tensor caching service. |
|
Abstract base class used to build dataset callback classes. |
|
Class to represent a schema of a dataset. |
|
Specify the shuffle mode. |
|
Abstract base class used to build dataset callback classes that are synchronized with the training callback class mindspore.train.Callback . |
|
Compare if two dataset pipelines are the same. |
|
The base class for Dataset Pipeline Python Debugger hook. |
|
Deserialize the data processing pipeline. |
|
Serialize dataset pipeline into a JSON file. |
|
Write the dataset pipeline graph to the logger.info file. |
|
Draw an image with given bboxes and class labels (with scores). |
|
Line-based file reader. |