用「头孢+Jina」建立的炫酷「昇腾游乐场」快来体验!
用「头孢+Jina」建立的炫酷「昇腾游乐场」快来体验!
硬件极客们:
「昇腾开发者」公众号正式启动啦!关注「昇腾开发者」感受最炫酷的Playground ,来体验用MindSpore+Jina建立的昇腾开源游乐场!
以下文章来源于昇腾开发者 ,作者Ascend
对AI感兴趣,却无从入手?偶然间看到有趣的图片想搜索更多类似的图却不知该如何操作?想知道快速识别录入大量手写数据信息的方法?希望简化AI集群资源管理以及任务调度的相关工作?
「昇腾开源游乐场」帮您一步一步实现以上想法,为了向广大开发者提供基于昇腾软件栈的交互式AI体验demo,我们开发了「昇腾开源游乐场」(http://ascend.gitee.io/playground/)
[
](https://mp.weixin.qq.com/s/6KszgRRwxNeHOQj3cHYmPQ#)
昇腾开源游乐场
在「昇腾开源游乐场」中,您可以通过我们所提供的小型程序,体验到一些基于昇腾环境非常有趣的AI应用,如昇腾找同款、昇腾助力HPC等。
在「昇腾开源游乐场」界面中,您可以拖拽一张内置的蘑菇图片或者手动上传一张全新的蘑菇图片,由搜索程序进行识别并返回最接近的蘑菇图片;还可实现手写一个中文数字,由系统识别返回结果的功能。
应用演示
为了能让大家对「昇腾开源游乐场」有比较直观的感受,首先带大家一起体验下它提供的两款AI小程序:昇腾找同款和昇腾助力HPC。
昇腾找同款:手写中文数字查询

(点击这里,去原文观看视频)
手写汉字识别有着极为广泛的应用场景,在大规模的数据记录(人口普查等)中,往往需要输入大量的用户信息,以前需要人工手动输入会耗费大量的人力和物力,如今有了AI技术的帮助,这类汉字识别可以通过机器自动进行识别与录入。
下面以简单的中文数字识别为例,向大家展示用小程序识别手写汉字数字(如:一,二等),让机器帮您查询并返回和您手写的中文数字最相似的结果。识别步骤如下:
1. 访问「昇腾开源游乐场」主页面:
http://ascend.gitee.io/playground/
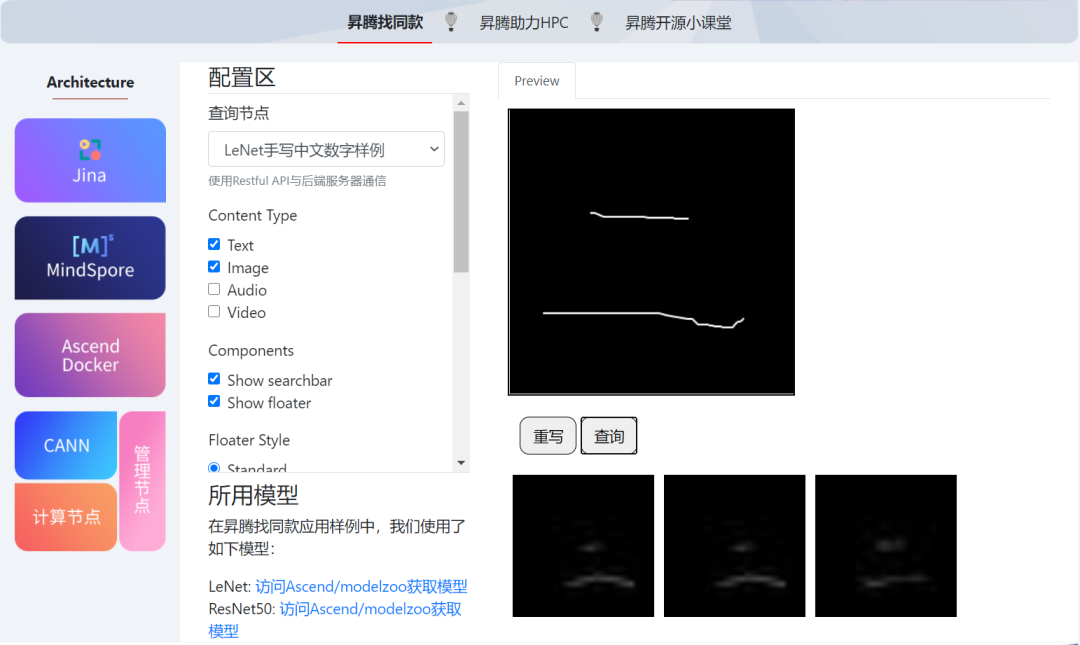
2. 在”配置区” -> “查询节点”下拉框选择“LeNet手写中文数字样例”;
3. 在“Preview”界面黑色面板内手写单个中文汉字,暂时仅支持“零至十,百,千,万,亿”等15个中文数字,示例面板为手写中文数字“二”;
4. 点击“查询”按钮会返回与手写“二”最为相似的三张结果图。
昇腾找同款:毒蘑菇搜索

(点击这里,去原文观看视频)
大千世界蘑菇种类数不胜数,是否可以通过AI技术来鉴别蘑菇毒性呢?通过「昇腾开源游乐场」只需将任一张蘑菇图片拖拽到交互区,昇腾找同款应用就会从检索库保存的数千张蘑菇图片中搜索出50张同类或最相似的蘑菇图片,听上去是不是很酷炫?!
想要亲自上手体验一下的话,只需打开http://ascend.gitee.io/playground页面,配置区选择ResNet50毒蘑菇样例,然后您可以从查询样例中选择一张蘑菇图片拖拽到右侧的搜索区即可,应用展示效果如下:
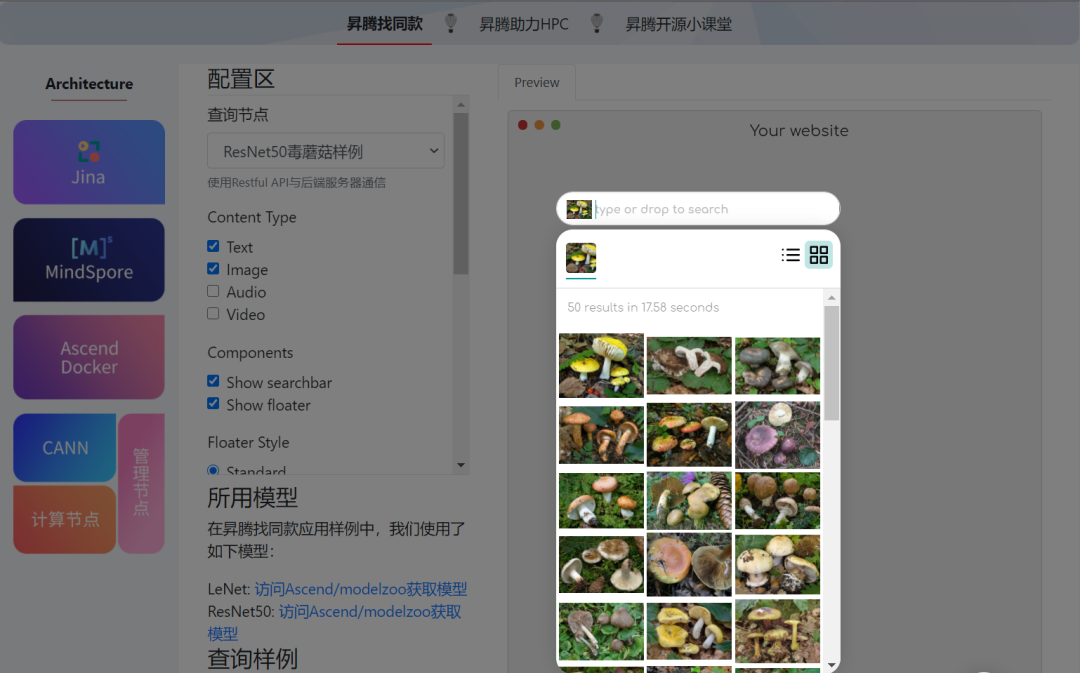
△昇腾找同款毒蘑菇搜索效果展示
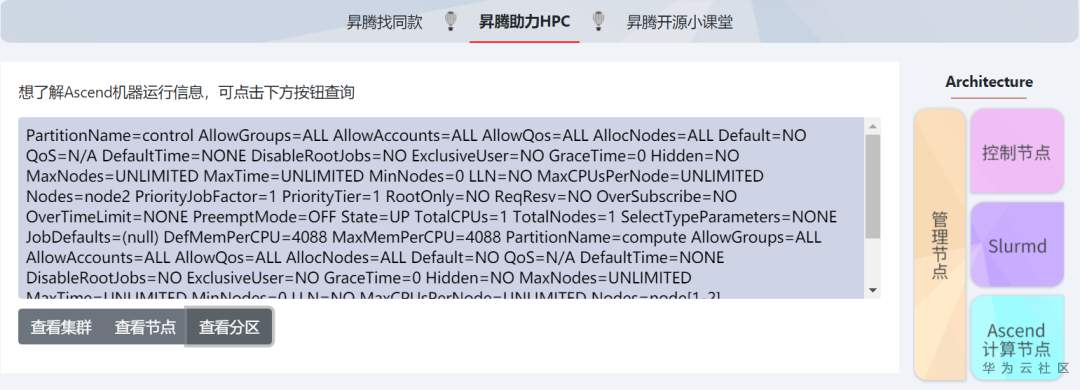
昇腾助力HPC:集群资源管理
当您准备或已经在HPC(High Performance Computing)等大规模计算场景使用了昇腾AI集群,希望简化集群资源管理以及任务调度的相关工作,那么可以使用由北大团队合作贡献到昇腾开源社区的slurm plugin项目(https://gitee.com/ascend/slurm-atlas-plugin)
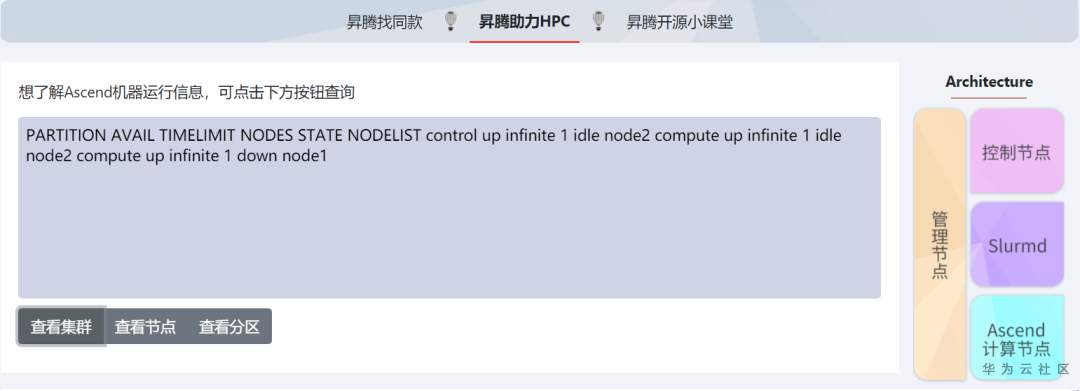
1. 查询集群状态:
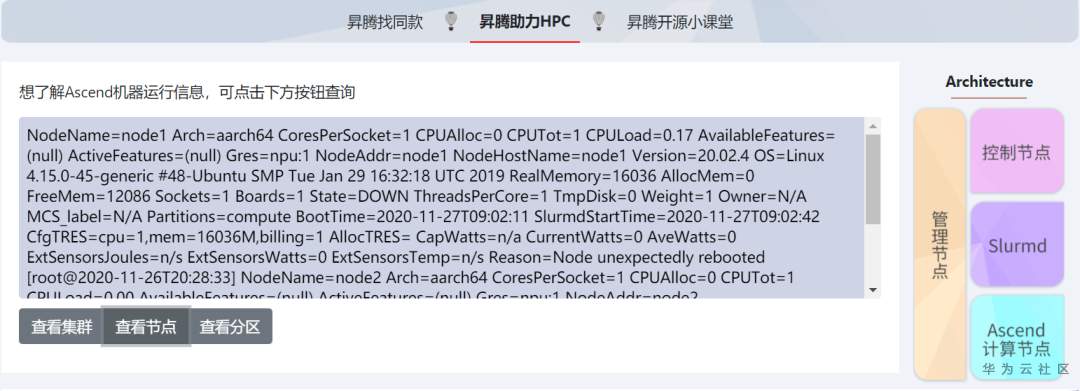
2. 查询节点资源:
3.查询分区资源:
方案设计与开源实现
刚刚和大家一起体验了「昇腾开源游乐场」 有趣的应用,相信您一定还想知道更加详细的知识,接下来我们一起来看下整体方案的实现原理,值得一提的是整个游乐场都是用开源软件搭建的!
前端交互界面
1. 先了解下如何实现炫酷的UI界面?
我们的前端服务采用了HTML + CSS + JavaScript等技术,基于jinabox.js项目(https://github.com/jina-ai/jinabox.js/ )实现了可视化的操作页面,用户只需在页面上轻松的动动手,比如手写一个中文汉字或拖拽一张蘑菇图片,发送查询就可以返回结果了。
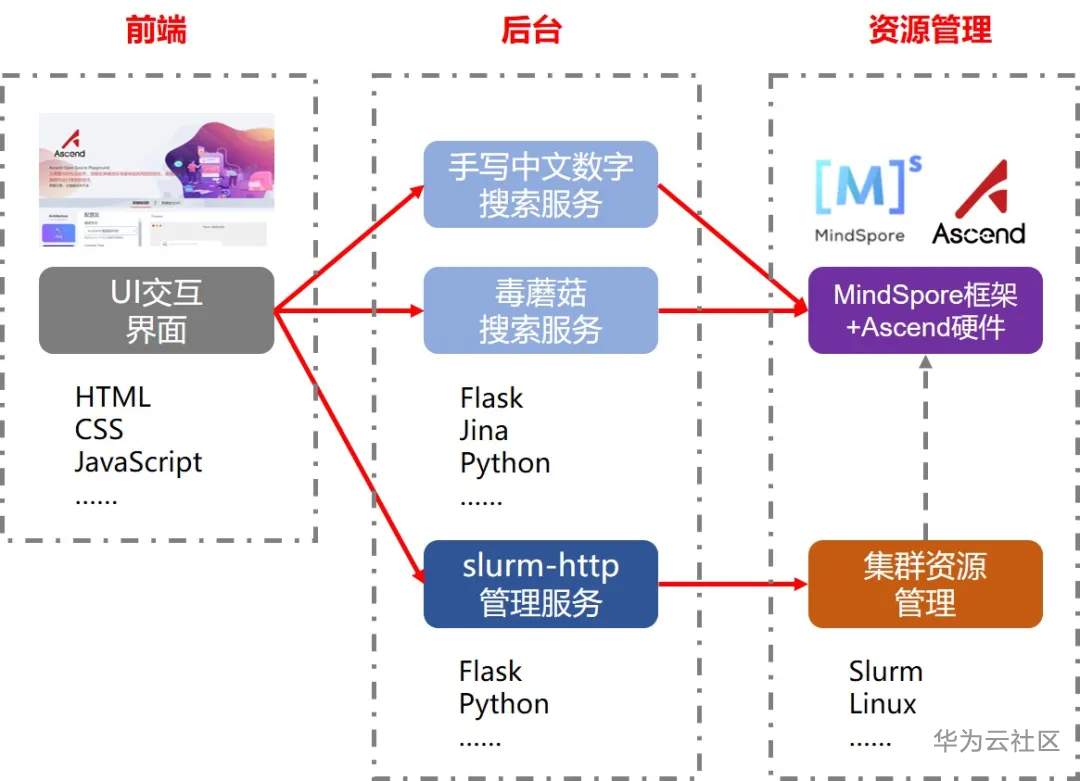
2. 前端交互界面和后台服务之间如何通信?
如上图所示,前端页面会根据用户的操作发送相应的http请求,并通过RESTful API与后端的三个服务器站点建立通信。其RESTful API格式如下:
· http://{host_ip}:{port}/api-server/search,POST操作
· http://{host_ip}:{port}/cluster,GET操作
· http://{host_ip}:{port}/nodes,GET操作
· http://{host_ip}:{port}/partitions,GET操作
后台搜索服务
我们的后台搜索服务主要采用了Jina服务(https://github.com/jina-ai/jina)+ MindSpore框架(https://www.mindspore.cn/) + Ascend后端的对接方案,同时通过Jina内置的Gateway服务实现外部功能。在Jina中,我们可以使用Flow来描述流水线的任务。
以手写中文数字应用为例,查询过程中涉及Index和 Query 两个Flow,它们的使用yaml文件定义如下:
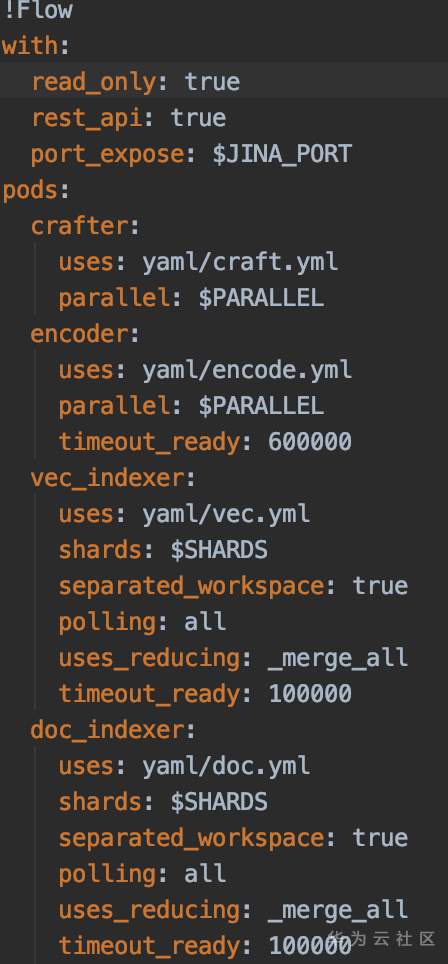
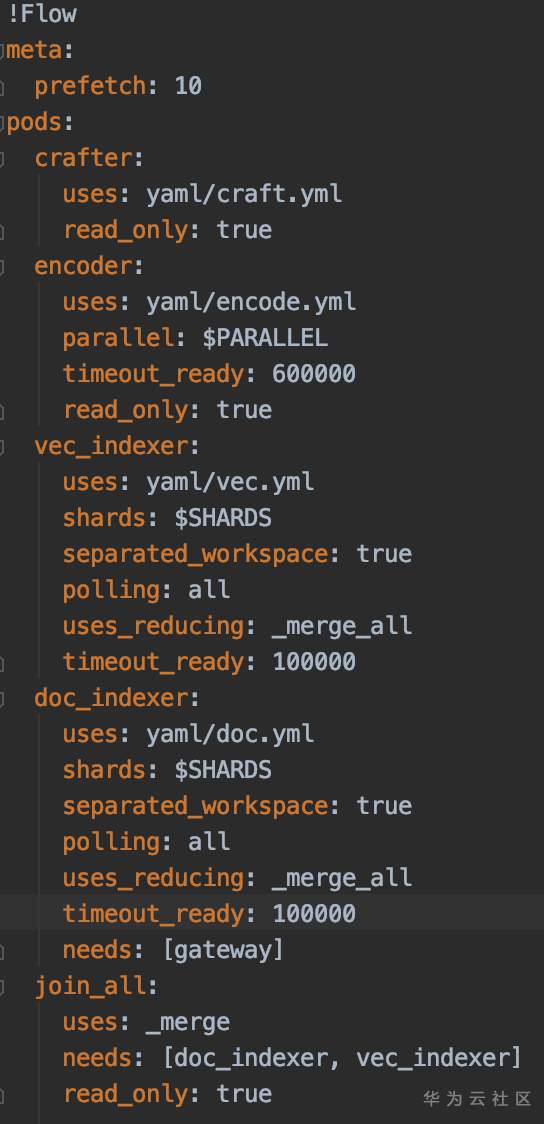
左:Index Flow yaml文件定义 右:Query Flow yaml文件定义
两个Flow过程都由craft,encode,vec,doc 4个yaml文件构成,大致可以概括为读取数据,将数据转换为模型可处理的矩阵矢量格式,加载模型,对矢量数据进行处理,最后建立索引结果。
即:将手写的中文数字“二”图片数据,经处理后输入28*28大小的图片,然后经encode转换为[-1, 1, 28, 28 ]的矢量数据,形如NCHW格式,为MindSpore LeNet可处理的矩阵数据格式,加载已经预先训练中文汉字数据集生成的MindSpore LeNet checkpoint文件,处理矩阵数据,最后可生成结果索引文件,查询数据集中与用户输入图片最为相似的结果返回。
集群资源管理
在介绍昇腾集群资源管理方案之前,先来补充下相关知识点:
1. 首先,什么是Slurm?
Slurm(Simple Linux Utility for Resource Management)是一套用于Linux集群的开源集群管理和作业调度系统,(敲黑板)注意重点是Linux工具、集群管理和作业调度。
Slurm中包含几个重要的实体概念:
· 集群(cluster):
由单个或多个节点构成的一种计算节点集合
· 节点(node):
用于表示物理机或虚拟机,通常以主机名命名
· 分区(partition):
跨越多个节点的逻辑区域
· 作业(job):
执行某一段特定程序的任务
· 队列(queue):
当提交的作业资源超出可用配额时,将作业放入队列
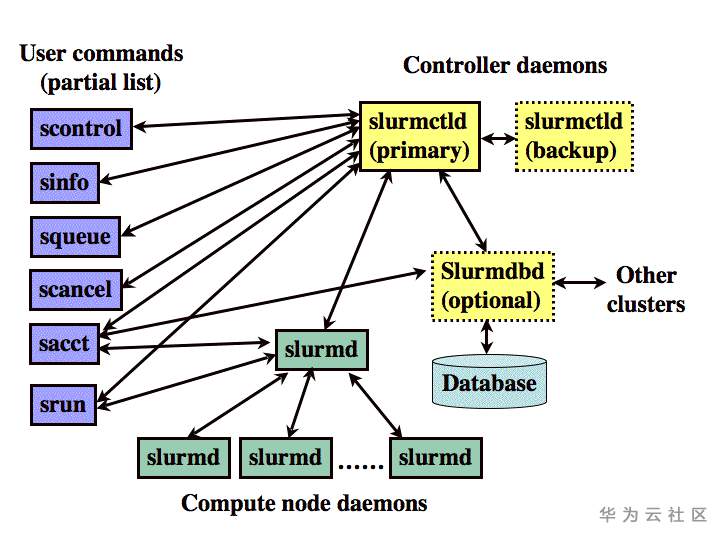
Slurm集群逻辑架构
如上图所示,Slurm包含了如下组件:
· slurmctld:
监控集群资源和作业状态
· slurmd:
作为计算节点的守护进程,用于管理compute节点和与control节点的通信
· slurmdbd:
用于在数据库两种记录多个slurm管理集群的作业统计信息(可选)
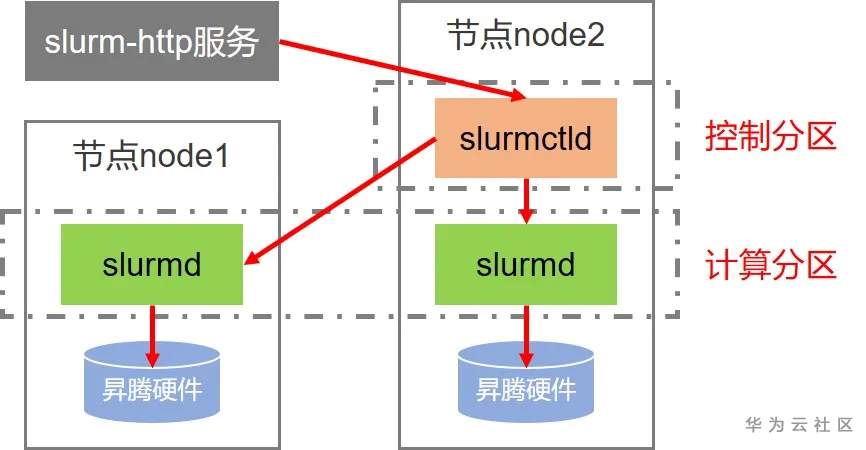
2. 接下来,我们一起看下昇腾资源管理系统是什么样子?
想要更全面了解昇腾并收获更多新奇体验,可以通过扫描下图二维码加入昇腾开源社区,在这里您可以通过Issue建立直达Commiter的交流渠道,快速闭环问题和需求,还能参加社区活动,回复Issue,获取激励,更多收获可参考下图↓
