网络搭建对比
本章节将会从训练和推理需要的基本模块出发,介绍MindSpore脚本编写的相关内容,包含数据集、网络模型及loss函数、优化器、训练流程、推理流程等内容。其中会包含一些在网络迁移中常用的功能技巧,比如网络编写的规范,训练、推理流程模板,动态shape的规避策略等。
网络训练原理
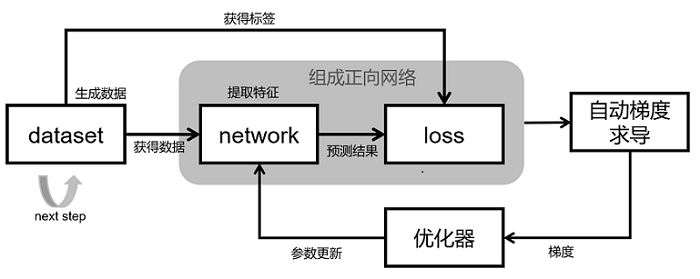
网络训练的基本原理如上图所示:
整个网络的训练过程包含5个模块:
dataset;用于获取数据,包含网络的输入,标签等。MindSpore提供了基本的常见的数据集处理接口,同时也支持利用python的迭代器构建数据集。
network;网络模型实现,一般使用Cell包装。在init里声明需要的模块和算子,在construct里构图实现。
loss;损失函数。用于衡量预测值与真实值差异的程度。深度学习中,模型训练就是通过不停地迭代来缩小损失函数值的过程,定义一个好的损失函数可以帮助损失函数值更快收敛,达到更好的精度,MindSpore提供了很多常见的loss函数,当然可以自己定义实现自己的loss函数。
自动梯度求导;一般将network和loss一起包装成正向网络一起给到自动梯度求导模块进行梯度计算。MindSpore提供了自动的梯度求导接口,该功能对用户屏蔽了大量的求导细节和过程,大大降低了框架的使用门槛。需要自定义梯度时,MindSpore也提供了接口去自由实现梯度计算。
优化器;优化器在模型训练过程中,用于计算和更新网络参数。MindSpore提供了许多通用的优化器供用户选择,同时也支持用户根据需要自定义优化器。
网络推理原理
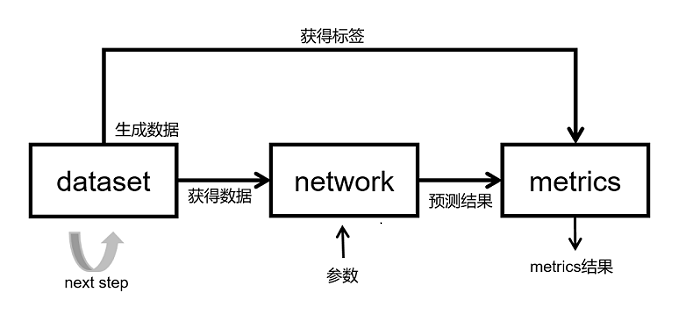
网络推理的基本原理如上图所示:
整个网络的推理过程包含3个模块:
dataset;用于获取数据,包含网络的输入,标签等。由于推理过程需要推理全部的推理数据集,batchsize最好设置成1,如果batchsize不是1的话,注意,加batch时加drop_remainder=False,另外推理过程是一个固定的过程,加载同样的参数每一次的推理结果相同,推理过程不要有随机的数据增强。
network;网络模型实现,一般使用Cell包装。推理时的网络结构一般和训练是一样的。需要注意推理时给Cell加set_train(False)的标签,训练时加set_train(True)的标签,这个和PyTorch model.eval() (模型评估模式),model.train() (模型训练模式) 一样。
metrics;当训练任务结束,常常需要评价指标(Metrics)评估函数来评估模型的好坏。常用的评价指标有混淆矩阵、准确率 Accuracy、精确率 Precision、召回率 Recall等。mindspore.nn模块提供了常见的 评估函数 ,用户也可以根据需要自行定义评估指标。自定义Metrics函数需要继承train.Metric父类,并重新实现父类中的clear方法、update方法和eval方法。
网络搭建
了解了网络训练和推理的过程后,下面介绍在MindSpore上实现网络训练和推理的过程。
说明
做网络迁移时,我们推荐在完成网络脚本的编写后,优先做模型的推理验证。这样做有以下几点好处:
比起训练,推理过程是固定的,能够与参考实现进行对比;
比起训练,推理需要的时间极少,能够快速验证网络结构和推理流程的正确性;
训练完的结果需要使用推理过程来验证模型的结果,需要优先保证推理的正确才能证明训练的有效。
在实践网络搭建之前,请先了解MindSpore和PyTorch在数据对象、网络搭建接口、指定后端设备代码上的差别:
Tensor/Parameter
在PyTorch中,可以存储数据的对象总共有四种,分别是 Tensor、 Variable 、 Parameter 、 Buffer 。这四种对象的默认行为均不相同,当我们不需要求梯度时,通常使用 Tensor`和 `Buffer 两类数据对象,当我们需要求梯度时,通常使用 Variable 和 Parameter 两类对象。PyTorch 在设计这四种数据对象时,功能上存在冗余( Variable 后续会被废弃也说明了这一点)。
MindSpore优化了数据对象的设计逻辑,仅保留了两种数据对象: Tensor 和 Parameter,其中 Tensor 对象仅参与运算,并不需要对其进行梯度求导和参数更新,而 Parameter 数据对象和PyTorch的 Parameter 意义相同,会根据其属性 requires_grad 来决定是否对其进行梯度求导和参数更新。在网络迁移时,只要是在PyTorch中未进行参数更新的数据对象,均可在MindSpore中声明为 Tensor。
nn.Module/nn.Cell
使用PyTorch构建网络结构时,我们会用到 nn.Module 类,通常将网络中的元素定义在 __init__ 函数中并对其初始化,将网络的图结构表达定义在 forward 函数中,通过调用这些类的对象完成整个模型的构建和训练。 nn.Module 不仅为我们提供了构建图接口,它还为我们提供了一些常用的 Module API,来帮助我们执行更复杂逻辑。
MindSpore中的 nn.Cell 类发挥着和PyTorch中 nn.Module 相同的作用,都是用来构建图结构的模块,MindSpore也同样提供了丰富的 Cell API 供开发者使用,虽然名字不能一一对应,但 nn.Module 中常用的功能都可以在 nn.Cell 中找到映射。 nn.Cell 默认情况下是推理模式。对于继承 nn.Cell 的类,如果训练和推理具有不同结构,子类会默认执行推理分支。PyTorch的 nn.Module 默认情况下是训练模式。
以几个常用方法为例:
常用方法
nn.Module
nn.Cell
获取子元素
named_children
cells_and_names
添加子元素
add_module
insert_child_to_cell
获取元素的参数
parameters
get_parameters
device设置
PyTorch在构建模型时,通常会利用 torch.device 指定模型和数据绑定的设备,是在CPU还是GPU上,如果支持多GPU,还可以指定具体的GPU序号。绑定相应的设备后,需要将模型和数据部署到对应设备。
而在MindSpore中,我们通过 context 中的 device_target 参数指定模型绑定的设备, device_id 指定设备的序号。与PyTorch不同的是,一旦设备设置成功,输入数据和模型会默认拷贝到指定的设备中执行,不需要也无法再改变数据和模型所运行的设备类型。 此外,网络运行后返回的 Tensor 默认均拷贝到CPU设备,可以直接对该 Tensor 进行访问和修改,包括转成 numpy 格式,无需像PyTorch一样需要先执行 tensor.cpu 再转换成numpy格式。
示例代码如下:
PyTorch
MindSpore
import os import torch from torch import nn # 如果 GPU 可用,则绑定到 GPU 0,否则绑定到 CPU device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # 单 GPU 或者 CPU # 将模型部署到指定的硬件 model.to(device) # 将数据部署到指定的硬件 data.to(device) # 在多个 GPU 上分发训练 if torch.cuda.device_count() > 1: model = nn.DataParallel(model, device_ids=[0,1,2]) model.to(device) # 设置可用设备 os.environ['CUDA_VISIBLE_DEVICE']='1' model.cuda()
import mindspore as ms ms.set_context(device_target='Ascend', device_id=0) # 定义网络 Model = .. # 定义数据集 dataset = .. # 训练,根据 device_target 自动部署到 Ascend Model.train(1, dataset)
MindSpore网络编写注意事项
在MindSpore网络实现过程中,有一些容易出现问题的地方,遇到问题请优先排查是否有以下情况:
数据处理中使用MindSpore的算子。数据处理过程一般会有多线程/多进程,此场景下数据处理使用MindSpore的算子存在限制,数据处理过程中使用的操作建议使用三方的实现代替,如numpy,opencv,pandas,PIL等。
切片操作,当遇到对一个Tensor进行切片时需要注意,切片的下标是否是变量,当是变量时会有限制,请参考网络主体和loss搭建对动态shape规避。
自定义混合精度和Model里的
amp_level冲突,使用自定义的混合精度就不要设置Model里的amp_level。在Ascend环境下Conv,Sort,TopK只能是float16的,注意加loss scale避免溢出。
在Ascend环境下Conv,Pooling等带有stride属性的算子对stride的长度有规定,需要规避。
在分布式环境下必须加seed,用以保证多卡的初始化的参数一致。
网络中使用Cell的list或者Parameter的list的情况,请在
init里对list进行转换,转换成CellList,SequentialCell,ParameterTuple。
# 在init里定义图构造时需要用的层,不要这样写
self.layer = [nn.Conv2d(1, 3), nn.BatchNorm(3), nn.ReLU()]
# 需要包装成CellList或者SequentialCell
self.layer = nn.CellList([nn.Conv2d(1, 3), nn.BatchNorm(3), nn.ReLU()])
# 或者
self.layer = nn.SequentialCell([nn.Conv2d(1, 3), nn.BatchNorm(3), nn.ReLU()])