MindSpore 2.6 Is Officially Released to Support E2E Out-of-the-Box DeepSeek and Day-0 Migration of Mainstream SOTA Models, Combining User-Friendliness with Exceptional Efficiency
MindSpore 2.6 Is Officially Released to Support E2E Out-of-the-Box DeepSeek and Day-0 Migration of Mainstream SOTA Models, Combining User-Friendliness with Exceptional Efficiency
After months of development and contributions from the MindSpore open-source community, the MindSpore 2.6 framework is now available.
This version brings three major feature upgrades:
1. Supports out-of-the-box training and inference of the DeepSeek MoE model, with enhanced pre-training and post-training features: Dropless MoE training is fully supported, and reinforcement learning training based on the GRPO algorithm is implemented.
2. Compatible with mainstream ecosystems and supports plug-in access to the vLLM ecosystem, openEuler collaborative optimization, and 20-minute out-of-the-box deployment of DeepSeek.
3. Combines user-friendliness with exceptional efficiency: MindSpeed acceleration library, day-0 migration of mainstream SOTA models, one-line code configuration for automatic parallelism, interface function decoupling, and debugging and optimization tool upgrade.
Now, let's delve into the key features of MindSpore 2.6.
-- DeepSeek Full-Stack Capabilities --
1 Dropless MoE Training and DeepSeek V3 Large Cluster Deployment Accelerated by Hierarchical Communication and Forward and Backward Communication Overlapping
Based on the dynamic shape capability of static graphs and automatic redistribution capability of sharding, Morph custom parallelism is added in MindSpore 2.6, allowing users to control the insertion of communication operators in frontend scripts, greatly improving the usability and flexibility of static graph parallelism. In addition, MindSpore MoE uses Morph to encapsulate expert parallelism of highly dynamic and unaligned shapes based on the capacity mode, and embeds the entire network based on automatic redistribution, implementing Dropless MoE training in static graphs. In addition, the E2E performance is improved through optimization methods such as heterogeneous cache, fused operators, and backward communication overlapping.
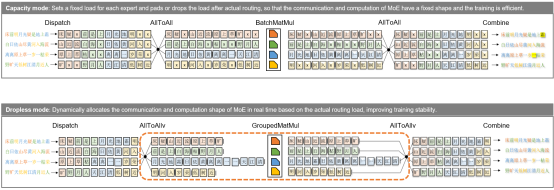
- Heterogeneous cache: The AllToAllv communication shape of MoE training depends on the real-time routing status of data. The routing status needs to be transferred from a device to a host (D2H) before the communication operator is delivered. As a result, the D2H copy and operator delivery flow are interrupted. Currently, the heterogeneous capability of MindSpore can be used to cache the routing status on the host after the first D2H. The number of interrupts in the delivery flow is reduced from 4 or 6 (including recomputation) to 1. According to the test, the performance of DeepSeek V3 is improved by 5%.
- Fused operators: In the implementation of Dropless MoE, the permute and unpermute fused operators are used to sort and reversely sort data, the GMMAssignAdd fused operator is used to combine the computation and gradient accumulation of MoE dW, and the MMAssignAdd fused operator is used to combine the dW computation and gradient accumulation of the MLA part. Swiglu fuses the computation of the activation function into one operator and allows the computation of two pre-matrices to be fused into one. The RoPE fused operator integrates the entire rotation position encoding algorithm to accelerate related computation. The test result shows that there is a 10% performance gain on DeepSeek V3.
- Backward communication overlapping: By overlapping the backward Combine AllToAllv operation backpropagation of shared experts, and overlapping the Dispatch AllToAllv operation with MoE dW computation, MindSpore achieves backward computation-communication overlapping. The test result shows that DeepSeek V3 has a 6% performance gain.
When DeepSeek V3 671B is deployed on a large-scale cluster, the AllToAll communication occupies about 30% overhead due to high sparsity and large-scale expert parallelism. MindSpore MoE optimizes communication performance through hierarchical communication and forward and backward communication overlapping.
Reference link: https://gitee.com/mindspore/mindformers/tree/dev/research/deepseek3
2 Graph Compilation and Combination Quantization Improving the Inference System Throughput and Halving the GPU Memory Usage
MindSpore 2.6 optimizes the inference network based on the network structure and MLA structure of DeepSeek V3/R1.
- Graph generation: MindSpore automatically compiles the Python class or function of a model into a complete computational graph through Just-In-Time (JIT) compilation. JIT compilation provides multiple modes (AST, bytecode, and trace) to meet the requirements of different scenarios, covering most Python syntax.
- Operator fusion: Based on the computational graph, operators are fused through automatic pattern matching. Multiple small operators are fused into a single large-granularity operator in the entire graph. Large operators reduce the overhead of host delivery and greatly shorten the compute latency of the device.
- Dynamic shape support: A three-level pipeline is built for shape inference, tiling data computation, and delivery and execution. This pipeline overlaps host computation and device computation, effectively improving the dynamic shape execution efficiency of the computational graph.
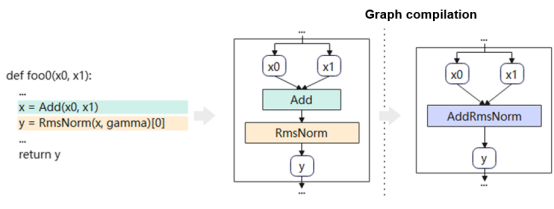
In addition, to reduce the deployment cost of the DeepSeek-R1 model, MindSpore 2.6 provides the Golden Stick model compression tool. You can construct and verify multiple combined quantization solutions without intruding and modifying the model network script.
Reference links:
MindSpore DeepSeek-V3/R1 inference model script: https://gitee.com/mindspore/mindformers/tree/dev/research/deepseek3
MindSpore DeepSeek-R1 inference model repository: https://modelers.cn/models/MindSpore-Lab/DeepSeek-R1-W8A8
3 Integrated Deployment of the Entire GRPO Training and Inference Process Implementing Reinforcement Learning Training Based on the GRPO Algorithm
With the popularity of DeepSeek R1, the group relative policy optimization (GRPO) algorithm has attracted wide attention in the industry. GRPO is an algorithm for reinforcement learning training proposed for logical inference tasks such as mathematics. The DeepSeek R1 model obtained through large-scale post-training of the GRPO algorithm has significantly improved logical inference capabilities, emerging with deep thinking capabilities such as long chains of thought and reflection. Its performance in mathematics and programming tasks has surpassed or rivaled that of OpenAI o1 series models.
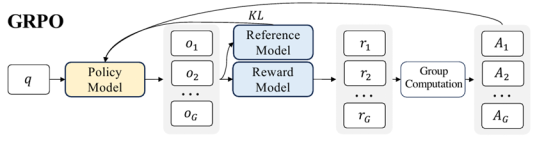
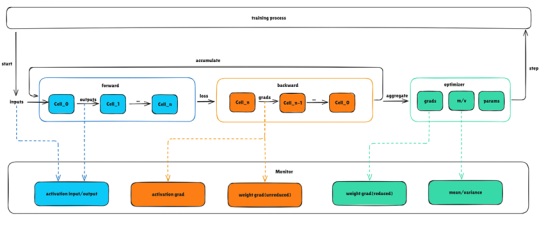
GRPO training process
Compared with the single-model training code developed before, the GRPO reinforcement learning training process involves the policy model and reference model. The policy model is used to generate data, the reference model and reward function are used to calculate the loss, and then the policy model is trained. As shown in the preceding figure, this process requires frequent switching between the inference and training states of the model, and involves a weight of the reference model and two weights of policy model inference and policy model training. This poses higher requirements on training performance and memory management. For reinforcement learning developers, it is a great challenge to quickly complete algorithm development and model training. MindSpore 2.6 provides the following optimization technologies for the GRPO reinforcement learning training process:
- Decouples the training process from model definition, and allows users to customize the model structure, reward function, and training hyperparameters.
- Co-deploys training and inference to implement online automatic rearrangement of training and inference weights, avoiding weight file flushing and saving time for offline conversion and weight file storing.
- Uses the heterogeneous memory swap technology to load models to the video RAM as required, avoiding the coexistence of training and inference weights and supporting training tasks of larger models.
Based on the preceding technologies, MindSpore streamlines the entire process of GRPO reinforcement learning training and provides multiple training interfaces for reinforcement learning developers to quickly implement algorithms.
Reference link: https://gitee.com/mindspore/mindrlhf/tree/master/examples/grpo
4 SAPP Pipeline Load Balancing Tool Supporting DeepSeek Heterogeneous Models and Improving Optimization Performance by 25%
In the DeepSeek architecture, the number of experts in different MoE layers is different, and the MTP layer is introduced. This makes the memory and computation modeling of different layers of the DeepSeek model significantly different. If manual optimization is performed, engineers need to summarize the memory change rules of different layers at different stages through multiple experiments. Compared with the Llama series models, the complexity and workload are multiplied.
For heterogeneous models such as DeepSeek, the SAPP pipeline load balancing tool in MindSpore 2.6 is effectively compatible with the execution sequence constraints. The following table shows the DeepSeek-V3 671B optimization instance. The training performance (tokens/s) of a large-scale cluster is improved by 25%.
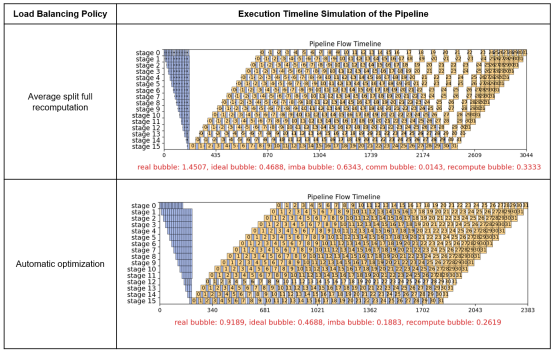
Reference link: https://gitee.com/mindspore/toolkits/tree/master/autoparallel/pipeline_balance
-- Ecosystem Compatibility and Extension --
5 Plug-in Access to the vLLM Ecosystem, openEuler Collaborative Optimization, and 20-Minute Out-of-the-Box Deployment of DeepSeek
MindSpore 2.6 develops the vllm-mindspore independent plug-in to integrate the LLM inference capability into the vLLM ecosystem. For the vLLM service and scheduling components, the PyTorch interfaces are mapped to the MindSpore capability to fully support core features such as vLLM Continual Batching and PagedAttention. The model, network layer, and custom operator components of the vLLM backend are replaced with the MindSpore-incubated, frontend-based parallel LLM inference module, inheriting the high-performance inference capability of Ascend and MindSpore.
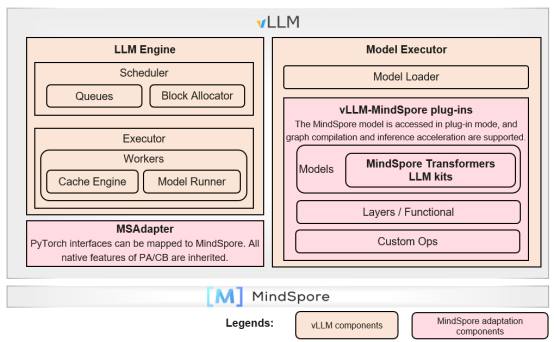
In addition, MindSpore works with the OpenAtom openEuler (openEuler for short) open-source community to implement hierarchical collaborative optimization of OS+AI basic software for DeepSeek LLM inference based on Kunpeng and Ascend. The DeepSeek open-source solution image of vLLM+MindSpore+openEuler is released to support one-click inference service deployment and 20-minute out-of-the-box model, the throughput of a single request can reach 18.5 tokens/s, and the throughput of 192 requests can reach 1350 tokens/s.
Reference link: https://gitee.com/mindspore/vllm-mindspore
-- Higher F****ramework Usability --
6 Optimizing Parallel Configuration Items to Enable Automatic Parallel Configuration of a Line of Code
The MindSpore distributed parallel interface is configured using set_auto_parallel_context(). There are more than 25 configuration items, covering various parallel settings. This brings a certain threshold to the use and understanding. For example, the context is a global scope. When a process has multiple networks and the parallel policies of each network are inconsistent, you need to reconfigure the parallel policies at a proper position and be familiar with parallel policy conflict scenarios.
In MindSpore 2.6, the AutoParallel class is added to support parallel configuration for a single network. You can configure automatic parallelism for a built network using only one line of code:
parallel_net = AutoParallel(single_net, parallel_mode="semi_auto")
You can set parallel_mode to sharding_propagation or recursive_programming and use the corresponding interfaces to develop parallel scenarios. For example, you can enable optimizer parallelism by using the parallel_net.hsdp() interface and enable pipeline parallelism and scheduling policies by using the parallel_net.pipeline() interface.
Reference link: https://www.mindspore.cn/docs/en/master/api_python/mindspore.parallel.html
7 Aligning Differentiated Interface Functions with the Mainstream Ecosystem, Supporting the MindSpeed Acceleration Library
To reduce the threshold and workload of LLM migration and adaptation, MindSpore 2.6 builds the MSAdapter adaptation layer to bridge the MindSpeed acceleration library. This allows the code of the mainstream ecosystem to be quickly migrated to MindSpore without changing the original usage habits of users. MindSpeed supports mainstream LLMs, helping users efficiently use Ascend computing power.
You can obtain the out-of-the-box DeepSeek-V3 script code and dataset of MindSpore by referring to the MindSpeed-LLM documentation.
Reference link: https://gitee.com/ascend/MindSpeed-Core-MS/blob/feature-0.2/docs/deepseekv3.md
8 Optimizing Global Parameters of the Global set_context Interface, Providing Single-responsibility APIs to Enable Functions Such As Compilation and Runtime, and Improving Code Readability
In MindSpore 2.6, more than 50 configuration items of the mindspore.set_context() interface are decoupled, and single-responsibility APIs are designed and launched to implement compilation, runtime, and device management functions.
8.1 Adding the runtime and device_context Modules to Improve the Usability of Memory and Hardware Resource Management
The mindspore.runtime module is added to encapsulate the execution, memory, stream, and event interfaces, facilitating hardware resource scheduling at the Python layer. For example, the memory-related parameters max_device_memory, variable_memory_max_size, mempool_block_size, and memory_optimize_level in set_context are used to set memory-related functions. Now, these parameters are optimized and combined into the runtime.set_memory() interface. The fine-grained memory settings are changed to function input parameters to improve the readability of the interface, making it easier to understand and use.
Reference link: https://www.mindspore.cn/docs/en/master/api_python/mindspore.runtime.html
8.2 New mindspore.jit Enabling Dynamic Graph and Compilation Capabilities, Improving Development Usability
Parameters related to the compilation capability in mindspore.set_context() are summarized in mindspore.jit(). In addition, the parameters of the jit function are redesigned. Parameters are provided to developers based on the key features of the compilation process, such as capture_mode (code capture mode), jit_level (compilation optimization level), dynamic (whether to perform dynamic shape), and backend (compilation running backend), improving understandability.
MindSpore uses the dynamic graph mode by default to ensure ease of development and debugging. Performance acceleration can be implemented by decorating local functions with JIT compilation.
Reference link: https://www.mindspore.cn/docs/en/master/api_python/mindspore/mindspore.jit.html
9 Using msprobe to Monitor the Training Status of Dynamic Graphs in Real Time, Improving the Accuracy Optimization Efficiency
To solve the problem that abnormal updates in the LLM training service may cause drastic status changes and difficult fault locating during model training, the msprobe tool is added to monitor the training status in the MindSpore dynamic graph scenario. Activation values, weight gradients, optimizer status, and intermediate values of communication operators can be collected and recorded with low performance loss during model training. The training status is displayed in real time, and accuracy problems can be quickly analyzed. You can monitor the corresponding objects as required. For example, during abnormal training with more losses but normal gradient norm, monitor the forward process of the model. During training with abnormal gradient norm, monitor the gradients of weights and activations.
You can configure the system to monitor the input and output of activations during network-wide training and save the data to disks. The data can be used as the input for manual analysis of model training accuracy, improving the accuracy optimization efficiency.
Reference link: https://gitee.com/ascend/mstt/blob/master/debug/accuracy_tools/msprobe/docs/19.monitor.md