MindSpore 2.4 is officially released, featuring native support for supernodes and enhanced distributed parallel capabilities to accelerate foundation model training
MindSpore 2.4 is officially released, featuring native support for supernodes and enhanced distributed parallel capabilities to accelerate foundation model training
经过昇思MindSpore开源社区开发者们几个月的开发与贡献,现正式发布昇思MindSpore2.4版本。
其中在大模型训练方面,面向新一代硬件架构超节点,推出原生长序列并行算法Ring Attention和高维张量并行优化,大幅提升模型训练效率。长序列并行算法Ring Attention旨在解决长序列训练时内存开销过大、出现内存瓶颈这一问题,同时提高计算与通信掩盖,实现训练性能提升。高维张量并行允许灵活控制对张量的切分次数和切分轴,支持1D、2D、3D切分,基于超节点架构带来的TP域与CP域扩展,在合适的切分策略下,实现通信占比降低、计算效率提升。
在调试调优阶段,提供流水并行自动负载均衡工具,自动优化集群算力和内存利用率,降低空等时间,实现Pipeline并行分钟级策略寻优,从而大幅降低调试调优成本、相比专家调优策略训练性能提升20%。支持算子级策略传播算法(Sharding Propagation),简化模型并行策略配置过程,开发者仅需配置少量算子策略,便可以自动地将策略传播给网络中其他算子, LLAMA类网络和Mixtral类网络策略传播算法可以降低配置80%以上的算子级并行策略。提升调试调优效率。
在大模型推理方面,提供8bit混合量化能力,支持并行解码方式、SLoRA服务化部署,并结合MindIE服务化支持PD分离部署,不断提升推理效率。
下面就为大家详细解读昇思2.4版本的关键特性。
——大模型训练与调试调优效率提升——
1 支持长序列并行算法Ring Attention,打破Attention计算内存限制,实现超长序列训练
近几年大模型对长序列的需求快速增长,众多大模型应用对于超长序列输入都提出了强烈的需求,例如长文档任务、个性化记忆、AI Agent、多模态理解与生成等。但与此同时,超长的序列长度也给大模型训练带来巨大的技术挑战。由于 Transformer 模型的 Attention 模块的计算量及内存占用与序列长度的平方成正比,随着序列长度的快速增长,Attention 的计算开销和内存开销增长迅速,导致超出显存容量而无法进行训练,因此需要高效的长序列并行技术,而长序列并行算法Ring Attention目前成为业界长序列并行的代表性技术,用于解决长序列训练时内存开销问题,同时实现了计算与通信掩盖。
昇思MindSpore2.4版本支持Ring Attention算法,如下图所示,利用 Attention 的分块计算性质,当序列并行度为 N 时,将 Q,K,V 分别切分为 N 个子块,每张卡分别调用 FlashAttention 算子来计算本地{Qi, Ki, Vi}子块的 Attention 结果。由于每张卡只需要计算切分后 QKV 子块的 Attention,其内存占用大幅降低。RingAttention 在做 FA 计算的同时采用环形通信向相邻卡收集和发送子块,实现计算与通信的最大化掩盖,保障了长序列并行的整体性能。
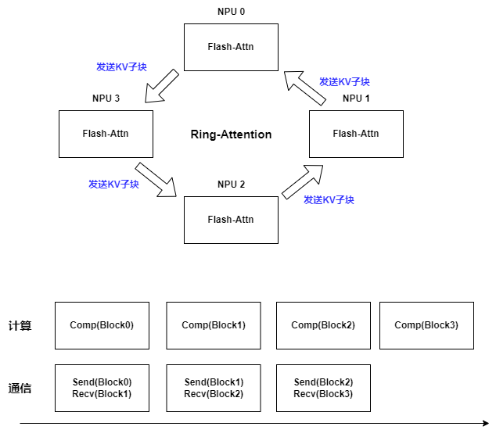
依托超节点架构,通过分析llama3模型训练64K序列长度数据集实验结果,相较于采用重计算来解决内存不足的问题,采用MindSpore 2.4版本的Ring Attention算法能够得到13%的性能提升。
参考链接:https://gitee.com/mindspore/mindformers/blob/dev/mindformers/modules/flash_attention.py
2 支持高维张量并行,降低通信量,实现训练性能加速
大模型训练中,模型并行能够有效减少内存负荷,但其引入的通信是一个显著的性能瓶颈。因此需要优化整网模型切分策略以期引入最小的通信量。张量并行训练将一个张量沿特定维度分成 N 块,每个设备只持有整个张量的 1/N,进行MatMul/BatchMatMul等算子计算,并引入额外通信保证最终结果正确。
昇思MindSpore2.4版本新增支持高维张量并行,允许灵活控制对张量的切分次数和切分轴,支持1D、2D、3D切分。2D/3D切分相对与1D切分,在合适的切分策略下,通信量随着TP设备数增长更慢,在TP设备数较大时有着更低的通信量。
- 1D张量并行中进行MatMul/BatchMatMul计算时,每张卡上存着激活的全部数据,仅在权重的一个维度上进行切分,并通过一次AllReduce通信得到最终计算结果。
- 2D张量并行将激活与权重均按x、y两个通信组切分,权重在两个维度上均会被切分,通信主要在激活上进行。
- 3D张量并行则是进一步将总卡数拆分为x、y、z三个通信组,进行了更细粒度的切分,并将一部分通信分散到了权重上。
- 2D/3D并行下,用户可根据模型的激活、权重张量shape不同,选择不同的张量切分方式,降低总通信量,引入最小通信量,提高端到端训练速度。
实测在超节点环境、TP不小于16卡配置下的大模型训练中可提高5%训练速度。
参考链接:https://www.mindspore.cn/docs/zh-CN/master/model_train/parallel/high_dimension_tensor_parallel.html
3 提供SAPP自动负载均衡工具,大模型流水线并行性能超越专家调优20+%
大模型训练性能调优需要同时考虑多维混合并行策略配置与内存限制,工程师需要在集群上尝试不同的组合方案才有可能找到性能达标的并行策略,这一过程常常耗费数周时间,且消耗大量算力成本。
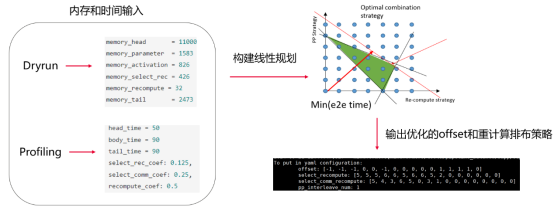
为解决上述问题,昇思MindSpore2.4版本提供了SAPP(Symbolic Automatic Parallel Planner)自动负载均衡工具。如上图所示,输入模型的内存和时间信息,以及部分流水线并行性能相关的超参(如重计算对性能的影响),工具将自行构建线性规划问题,通过全局求解的方式,为大模型自动生成流水线并行中的stage-layer配比,调整各layer重计算策略,自动优化集群算力和内存利用率,降低空等时间,实现Pipeline并行分钟级策略寻优,大幅度降低性能调优成本,显著提升端到端训练性能。
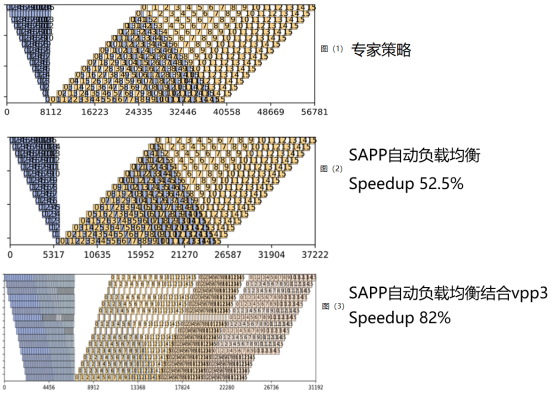
以LLAMA2-175B模型为例,流水并行数设置为16,如上图所示,图(1)展示专家策略的流水排布较为工整,但是含有较多空白的计算空隙(bubble);图(2)展示相同模型使用SAPP的结果,计算空隙大幅度减少,端到端性能相比于专家策略提升52.5%;图(3)是开启流水交织并行(Pipeline Interleave)时候的SAPP结果,设置vpp=3,从图中可以看出计算被切得更细,且负载均衡调整更加精细化,端到端性能相比于专家策略提升82%。
实验显示,通过SAPP自动负载均衡工具优化,端到端训练性能对比均分策略提升20+%,在复杂网络(如多模态)下最高可提升200%,同时在开启流水交织并行的复杂场景下,人为分析较为困难,而SAPP自动负载均衡工具可以快速提供高效并行策略,突破人工调优极限。
4 优化自动算子级策略传播算法,降低80%并行策略配置,支持典型大模型
在深度学习领域,随着数据集和参数量的规模日益增大,训练时间和硬件资源的需求也随之增长。分布式并行训练是解决这一问题的关键,但其配置和优化往往需要专业知识和大量时间。为此,昇思MindSpore推出了自动并行策略传播算法(Sharding Propagation),旨在简化模型并行策略配置的过程。用户仅需配置少量算子策略,便可以自动地将策略传播给网络中其他算子,从而找到重排代价最小的整网并行配置。
如下图所示,给定神经网络的计算图后,我们首先对没有配置切分策略的算子进行枚举,以确定其可行的策略,并对每条边的重排布策略及其相应的代价进行计算。然后,算法会从已经确定策略的算子开始,将策略沿着计算图的边传播到下一个算子。在传播过程中,算法总是选择能最小化通信和计算代价的目的算子的策略,直到所有算子的切分策略都被确定并形成一个最优的策略组合。
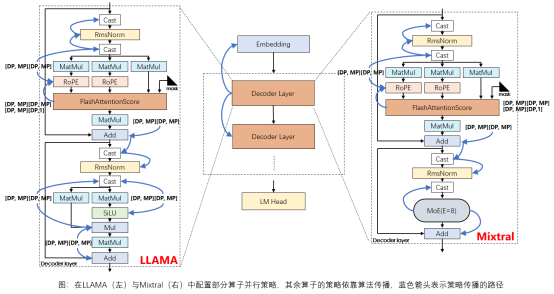
在确保与专家配置所有算子并行策略相比性能无损耗的情况下,LLAMA类网络和Mixtral类网络策略传播算法可以降低配置80%以上的算子级并行策略,这意味着用户可以节省大量的时间和精力,专注于模型优化和调优。
昇思MindSpore2.4版本在已有支持CV和推荐类网络的基础上,新增支持了Transformer类大模型,包括千亿稠密模型(e.g., LLAMA)、万亿稀疏模型(e.g., Mixtral)以及多模态网络。在囊括常见3D并行(DP, TP, PP)的基础上,兼容大模型性能特性如长序列并行、通信计算掩盖(多副本并行)、优化器并行、流水交织并行以及支持配置自定义Layout,并支持昇思MindSpore静态图模式,动静统一模式,兼容函数式写法。
未来,昇思MindSpore将进一步支持对Cell的入口进行策略配置,进一步减少用户需手动配置的数量,进一步简化并行配置过程。
——大模型推理效率提升——
5 金箍棒提供8bit混合量化能力,降低大模型推理时延30%
大模型推理过程中对于显存和算力有巨大的需求,昇思MindSpore金箍棒新增训练后量化PTQ算法提供8bit混合量化能力,通过将网络中线性层从浮点域量化到整型域,能够缓解memory bound,并显著降低显存和算力开销,从而提升推理性价比。PTQ算法是一种training-free的量化算法,可以通过配置项支持8bit权重量化、SmoothQuant、KVCache 8bit量化以及他们之间的组合算法,如同时使能SmoothQuant和KVCache 8bit量化。
我们对llama2 70B网络,使用200条squad1.1语料进行校准,耗时约8分钟完成SmoothQuant和KVCache 8bit量化。并使用BoolQ数据集进行评测,F1和EM均有轻微下降(1%以内)。量化后checkpoint文件大小缩减为原来的64%,推理的平均端到端时延降低30%以上。
参考链接:https://gitee.com/mindspore/golden-stick/tree/master/mindspore_gs/ptq/ptq
6 支持并行解码,利用算力优势实现推理性能加速
大模型推理使用自回归解码的方式,通常需要逐个token地进行串行解码,并且生成每个token都需要将所有参数从存储单元传输到计算单元。因此在自回归解码过程中,受限于访存带宽,计算资源过剩。为了提高Decode阶段的算力利用率,降低端到端时延,昇思MindSpore2.4版本支持并行解码,是大模型推理的一种新型解码方式。
与自回归解码不同,并行解码每步可以同时解码多个token,然后并行验证它们,从而加速推理性能。前瞻解码(Lookahead Decoding)是一种基于Jacobi迭代的并行解码算法,无需微调,且不依赖小模型或离线数据集。前瞻解码通过Prompt及输出结果生成N-Grams,根据N-Grams生成草稿token,执行并行解码进行校验,减少推理步数以获得加速效果。
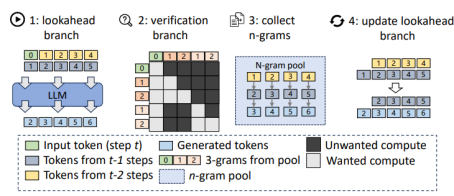
我们对Llama2-7B网络进行了前瞻解码功能测试,在batch size为18场景下,推理性能提升1.20.47倍。
7 支持MindIE服务化全量增量分离架构,提升推理吞吐量50%
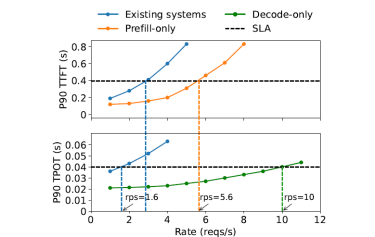
由于大模型推理在Prefill和Decoding阶段在资源需求和执行时间上有差异,Prefill是计算密集型任务,而Decodeing是存储密集型任务,PD混部会面临资源竞争、缓存压力、延迟增加和负载不均衡等问题。如下图所示,Prefill-only吞吐量有5.6tps,Decode-only有10tps,而混部只有1.6tps。
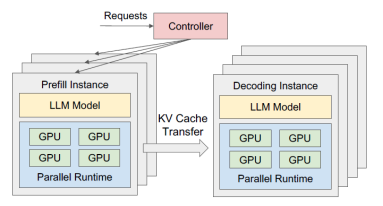
为了解决上述问题,昇思MindSpore2.4版本通过结合MindIE服务化支持PD分离部署。如下图所示,通过将Prefill和Decoding阶段分别部署到不同节点,并结合分布式调度等机制,有效缓解了资源竞争、简化了缓存管理、降低了响应延迟并实现了更均衡的负载分配,推理吞吐量可提升50%以上。
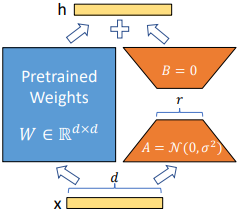
8 支持SLoRA服务化部署,实现大模型多微调权重调度推理
LoRA通过对大模型的权重矩阵进行隐式的低秩转换,可以解决大模型微调时存在的参数数量庞大、计算成本高等问题。昇思MindSpore2.4版本支持SloRA,可以在服务化部署时自动修改网络模型,实现LoRA网络结构适配和多LoRA权重加载并共享大部分模型参数。在推理时SLoRA提供了LoRA模型控制接口,实现LoRA任务的自由组合和快速切换。