Released MindSpore 2.3.0 to Continuously Improve Dynamic/Static Graphs and Foundation Models
Released MindSpore 2.3.0 to Continuously Improve Dynamic/Static Graphs and Foundation Models
After several months of development and contribution by community developers, MindSpore 2.3.0 is officially released. Dynamic graphs support the direct call of operators to improve API performance, and static graphs support O(n) levels of compilation to improve debugging and optimization capabilities. In terms of foundation model training, the overlap of communication and computation is greatly optimized, and the FlopsUtilizationCollector API is added to collect statistics on the computing power utilization. In terms of foundation model inference, an inference optimization solution for LLM is launched to improve inference performance, and MindSpore Transformers can improve inference performance and usability. In terms of scientific computing suites, the partial differential equation (PDE) model PDEformer and spectral neural operator (SNO) are added to MindSpore Flow. The following describes the key features of MindSpore 2.3.0 in detail:
-- Basic Framework Evolution --
1 Direct Call of Operators in Dynamic Graphs Improving API Performance
In the MindSpore framework, most APIs combine small operators, which brings extra Python and operator launch overhead. In earlier MindSpore versions, when a single operator in a dynamic graph is executed, a single-operator subgraph is used for execution. A series of operations need to be performed, such as single-operator subgraph composition, compilation optimization, operator selection, and operator compilation. The initial performance is poor. To improve the performance, MindSpore 2.3.0 proposes the approach of directly calling operators. That is, forward operators are directly called to underlying operator APIs, reducing the overall process and data structure conversion overhead. Different APIs improve the performance by 0.5 to 4 times, and the E2E performance of Stable Diffusion text-to-image training is improved by more than 2 times.
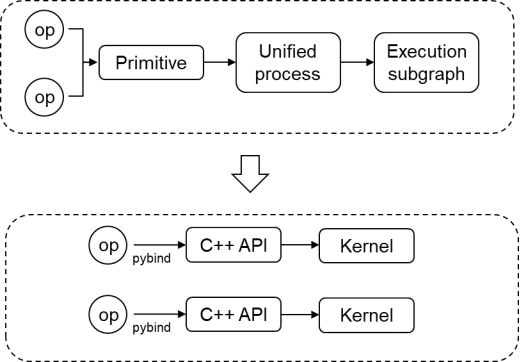
In addition, basic distributed APIs are provided.
Hardware-related APIs (for device, stream, event, and memory management): https://www.mindspore.cn/docs/en/master/api\_python/mindspore.hal.html
Recompute API: https://www.mindspore.cn/docs/en/master/api\_python/mindspore/mindspore.recompute.html
Communication APIs: https://www.mindspore.cn/docs/en/master/api\_python/mindspore.communication.comm\_func.html
2 O(n) Compilation Levels in Static Graphs Improving Debugging and Optimization (Default: O0)
Graph offloading is widely used due to its superior execution performance. However, as foundation models grow in scale and parameters, the time it takes for graph offloading during graph compilation can be quite long. To address the above issue, MindSpore 2.3.0 enables multi-level compilation, involving the O0 (native graph composition without optimization), O1 (automatic operator fusion and optimization), and O2 (graph offloading and optimization) options.
With the O0 option (native graph compilation), the compilation performance of most models is improved by more than 50% compared with that of O2. In addition, by utilizing the DryRun function, users can analyze memory bottlenecks and optimize parallel policies offline. The combination of these two technologies doubles the debugging efficiency of foundation models. In terms of memory overcommitment, SOMAS, LazyInline, and Control Flow Inline are enabled to improve the memory overcommitment ratio. The virtual memory defragmentation technology is implemented to greatly solve the training OOM problem caused by memory fragments. In terms of execution performance, the multi-stream parallel and runtime pipeline asynchronous scheduling technologies are enabled for computing and communication. In addition, the operator fusion technology is used in the O1 option, greatly improving the execution performance.
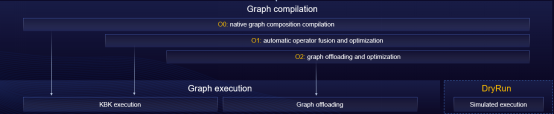
Static graphs natively have great debugging and optimization capabilities. Therefore, the default option of static graphs is O0 in mainstream training products in MindSpore 2.3.
Reference link: https://www.mindspore.cn/docs/en/master/api_python/mindspore/mindspore.set_context.html?highlight=jit_level
-- Comprehensive Improvement of Foundation Model Training --
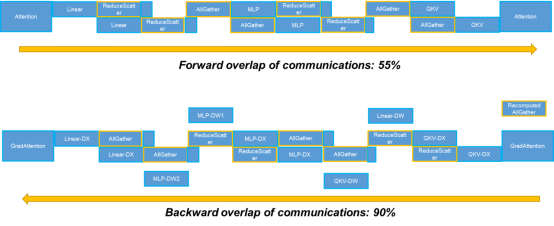
3 Optimizing the Overlap of Communication and Computation in Foundation Models
In earlier versions, MindSpore proposes two overlap technologies for tensor parallel communication: multi-copy parallelism as well as backward gradient computation and backward tensor parallelism, which greatly overlap tensor parallel communication. However, in a scenario with a larger model scale, recomputation is performed on AllGather communication in short sequence parallel. This part of recomputed communication cannot be effectively overlapped by MatMul. For this part of communication, MindSpore 2.3.0 effectively adjusts the execution time to overlap the communication with the backward operator of FlashAttention, achieving the ultimate overlap of communication and computation.
4 FlopsUtilizationCollector Collecting Statistics on the Computing Power Utilization
The computing power utilization is usually a performance metric of the foundation model training framework, and the GPU/NPU utilization directly affects the foundation model training overhead. In the industry, the model FLOPS utilization (MFU) and hardware FLOPS utilization (HFU) metrics are widely used to evaluate the computing power utilization of GPUs/NPUs. In MindSpore 2.3, the callback API FlopsUtilizationCollector is added for users to obtain the MFU and HFU information at the end of each epoch.
For details, visit https://www.mindspore.cn/docs/en/master/api\_python/train/mindspore.train.FlopsUtilizationCollector.html.
5 Optimized Algorithms and Operators Improving Foundation Model Inference Performance
MindSpore 2.3.0 provides the inference optimization solution for LLMs. In addition to using the static graph compilation mode at the framework layer to optimize a computational graph and using the kernel-by-kernel scheduling mode to reduce the model compilation time, it also integrates acceleration technologies, such as the quantization model compression algorithm of Golden Stick, mainstream Flash Attention and Paged Attention algorithms in the industry, and operator fusion, to reduce the GPU/NPU memory usage and improve the inference performance of foundation models.
5.1 Golden Stick Model Compression Algorithm Helping LLM Inference Reduce Overhead and Improve Efficiency
To meet the GPU/NPU memory requirements of LLM inference, Golden Stick supports the RoundToNearest weight quantization algorithm. The weight of a linear layer on a network is quantized from the floating-point domain to the integer domain, and then dequantized to the floating-point domain for computation. The GPU/NPU memory overhead of LLM inference can be significantly reduced, and the memory bound problem in the LLM incremental inference phase can be alleviated, thereby improving performance. RoundToNearest is a training-free and data-free quantization algorithm, and has a relatively low use cost. Since LLM weights are more normalized and easier to quantize compared to activations, RoundToNearest can achieve almost lossless accuracy. In a word, the easy-to-use RoundToNearest has almost lossless accuracy and brings benefits to the GPU/NPU memory and performance.
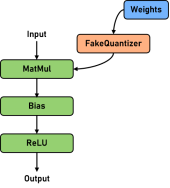
By testing the Llama2 series networks, it is found that the network parameters are generally reduced by more than 40%, the accuracy is almost lossless, and the inference performance is improved by up to 15%.
For details, visit https://www.mindspore.cn/golden\_stick/docs/en/master/ptq/round\_to\_nearest.html.
5.2 Ascend High-Performance Fusion Operators Achieving Ultimate LLM Inference Performance
MindSpore 2.3.0 supports mainstream Transformer optimization algorithms and cross-boundary operator fusion technologies. It fully utilizes hardware architectures such as cube/vector computing units and multi-level buffers of Ascend chips and develops the backend computing implementation with Ascend hardware affinity to meet the performance requirements of low latency and high throughput in LLM inference scenarios.
(1) Attention fusion and optimization: Based on the FlashAttention and PagedAttention optimization algorithms and the KV cache mechanism, the Tiled Attention algorithm is redesigned for the Ascend AI Processor features. In this way, the high bandwidth of the buffer between cube and vector are maximized and the amount of data migration and vector computation is reduced. Multi-level pipelines are constructed to greatly reduce the inter-core waiting time and maximize pipeline parallelism. Queries are reorganized and calculated under the grouped query attention mechanism to further improve operator performance.
(2) Rotary position embedding (RoPE) combines the idea of absolute position coding and relative position coding, multiplies the rotation matrix to assign position information to a token, and makes better use of the context token information. In this version, MindSpore provides high-performance RoPE fusion operators by simplifying the computing logic and optimizing the data layout mode of position encoding, and maximizes the unified buffer usage of Ascend chips during operator implementation.
(3) Convergence and optimization of matrix multiplication and vector computing: LLM involves a large number of matrix multiplication computations. MindSpore 2.3.0 optimizes graph fusion in the compilation phase and works with high-performance operators to improve matrix multiplication performance. Pipeline parallel optimization is fully considered in operators to reduce waiting bubbles so that the computing time is overlapped by the data transfer time as much as possible. Matrix multiplication data access is scheduled and rearranged in Swizzle mode to improve the data cache hit ratio and overall memory access efficiency. The Ascend Cube/Vector parallel feature is used to support backward fusion computation of multiple matrices, reducing the vector computation time. In addition to matrix multiplication, MindSpore combines adjacent Element-wise, Normalization, and Reshape operators in LLMs to reduce memory overheads for data migration, simplify runtime pipeline, and accelerate inference computing. In addition, in terms of operator optimization, this version explores the optimization technology based on the tensor language model to implement automatic optimization of key configurations such as intra-operator sharding, build a high-performance sharded database, and improve the performance of the LLM fusion operator.
6 MindSpore Transformers: Improving Inference Performance and Usability and Supporting Ultra-long Sequence Training
MindSpore Transformers (MindFormers) 1.2.0 is officially released. It supports multiple mainstream models in the industry, further improving suite usability.
6.1 Framework-based Inference and Service-oriented Deployment: Improving the Usability and Performance of Foundation Model Inference to Meet Service-oriented Requirements
MindFormers 1.2.0 supports MindSpore inference with frameworks. Currently, MindFormers 1.2.0 supports efficient inference of mainstream foundation models such as LLaMA2, LLaMA3, GLM3, Mixtral, Baichuan2, and InternLM2. The maximum sequence length is 32k. Unified training and inference parallel policy APIs and encapsulated inference acceleration APIs implement smooth migration from training to high-performance inference, reducing the overall deployment period to days.
MindFormers 1.2.0 fully interconnects with the MindIE service-oriented deployment framework. Mainstream LLMs in the suite support service-oriented inference. The standard Ascend service-oriented APIs provided by MindIE are compatible with third-party framework APIs such as Triton, OpenAI, TGI, and vLLM. Scheduling policies such as Continuous Batching are used to eliminate redundant computing, ensure that the computing power is not idle, and improve the inference throughput performance of foundation models. The recomputation and swap functions are supported to ensure that services are not interrupted in scenarios with a large number of concurrent requests and long sequences.
6.2 Ultra-long Sequence Training: Helping Train Ultra-long Contexts Conveniently and Efficiently
From generative AI to models used in scientific research, the significance of long sequence training is increasingly pronounced. Existing parallel methods such as data, tensors, and pipelines cannot be sharded in a sequence dimension. When the sequence dimension (S) increases, the training memory overhead increases at a rate of O(S2). Therefore, specific optimization needs to be performed for the long sequence scenario to meet the training requirements of the long training scenario. MindSpore provides a sequence parallel method with efficient GPU/NPU memory and the attention mask compression feature, which greatly reduces the length limit of input sequences and effectively supports the training of ultra-long sequences.
The parallel method shards the QKV vectors along the sequence dimension based on context parallel. Each device handles only one shard of the QKV vectors for self-attention computation, eliminating the need for a single device to store the entire sequence. The relationship between the attention matrix and the sequence length is changed from square to linear, which effectively reduces the GPU/NPU memory pressure of each computing device. At the same time, the method is compatible with most existing parallel technologies (such as data parallelism, pipeline parallelism, and tensor parallelism).
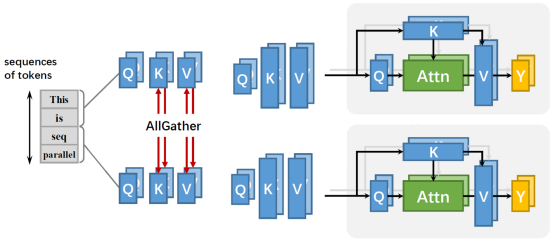
The attention_mask compression is to mask the Score matrix in Self-Attention. Its memory size is proportional to S2. For example, in the 32k sequence length, a single attention_mask matrix of the uint8 type occupies 1-GB GPU/NPU memory. After the compression is enabled, the input attention_mask is compressed into a triangular matrix (2048 x 2048). In addition to memory benefits, some networks generate the attention_mask matrix on a device. The attention_mask compression can effectively avoid the performance overhead caused by the generation of an ultra-large matrix.
-- Scientific Computing Suite Enhancement --
7 MindSpore Flow: Adding the PDEformer Model and Spectral Neural Operator (SNO)
7.1 PDEformer
PDEformer is a neural operator model that can accept any PDE form as direct input. It can quickly and accurately solve most one-dimensional PDEs by generating PDE computational graphs, encoding graph data, and decoding solutions. PDEformer-1 is pre-trained on large-scale one-dimensional PDE data. In training data distribution, zero-shot prediction accuracy is higher than that of expert models (such as FNO and DeepONet) specially trained for an equation. For data distribution outside the training set, PDEformer-1 also exhibits excellent few-shot learning capability, which can quickly generalize to new downstream tasks through few shots. At the same time, PDEformer-1 can be directly applied to inverse problems as a proxy model of a direct problem operator.
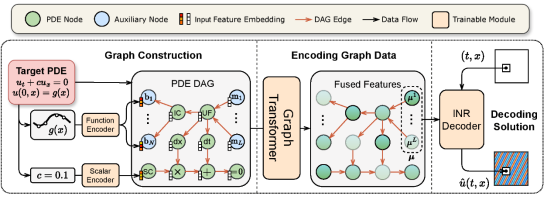
For details, visit https://gitee.com/mindspore/mindscience/tree/master/MindFlow/applications/pdeformer1d.
7.2 SNO
An SNO is an FNO-like architecture that transforms computation into spectral space by using polynomials (such as Chebyshev and Legendre). Compared with FNO, the system deviation caused by aliasing error is small in SNO. One of the most important benefits is that the base selection in SNO is broader, and you can find a set of polynomials that is most convenient to represent. In addition, when the input is defined on unstructured grids, neural operators based on orthogonal polynomials are more competitive than other operators.
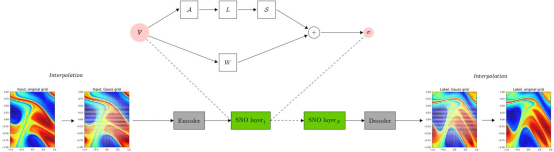
For details, visit https://gitee.com/mindspore/mindscience/blob/master/MindFlow/mindflow/cell/neural\_operators/sno.py.