MindSpore 2.3.RC1, the Optimal AI Framework for Foundation Models, Released in the Open Source Community
MindSpore 2.3.RC1, the Optimal AI Framework for Foundation Models, Released in the Open Source Community
After several months of development and contributions by community developers, MindSpore 2.3.RC1 is now officially released. This version brings significant improvements in high-performance training on ultra-large clusters, leveraging multi-dimensional hybrid parallelism and deterministic checkpointing. It employs an integrated training and inference framework, streamlining the development, training, and inference of foundation models, making the process more efficient, stable, and user-friendly. Additionally, it utilizes various inference optimization techniques to minimize the inference costs of foundation models. The new version also enables kernel by kernel scheduling to further enhance static graph debugging and tuning. MindSpore continues to refine its Transformers foundation model suite and MindSpore One generative domain suite, which provide complete, out-of-the-box solutions for developing and verifying foundation models in a week. The AI + scientific computing (scientific intelligence) paradigm is revolutionized to develop foundation models in the scientific field. Now, let's delve into the key features of MindSpore 2.3.RC1.
1 Foundation Model Training: Fine-Grained Multi-Copy Parallelism, Enhancing Computation and Communication Concurrency to Significantly Boost Foundation Model Performance
In foundation model training, operator-level parallelism techniques are widely employed to reduce graphics memory overheads. However, this often results in a substantial increase in communication in model parallelism, consequently impacting the efficiency of foundation model training. From the perspective of network structure, communication in model parallelism is involved in both forward and backward propagation processes, and can cause both processes to stall because it cannot be overlapped with either. To address the overlapping issue of communication in model parallelism, MindSpore proposes the multi-copy parallelism technology.
In an earlier version of MindSpore, a network is split from data. As shown in the following figure, in a single card, the slice operator is used to split the batch dimension to generate multiple branches. The computation and communication of these branches have no dependencies on each other, and have concurrency potential. By suing the execution sequence scheduling algorithm, multiple branches of computation and communication can be controlled to proceed concurrently.
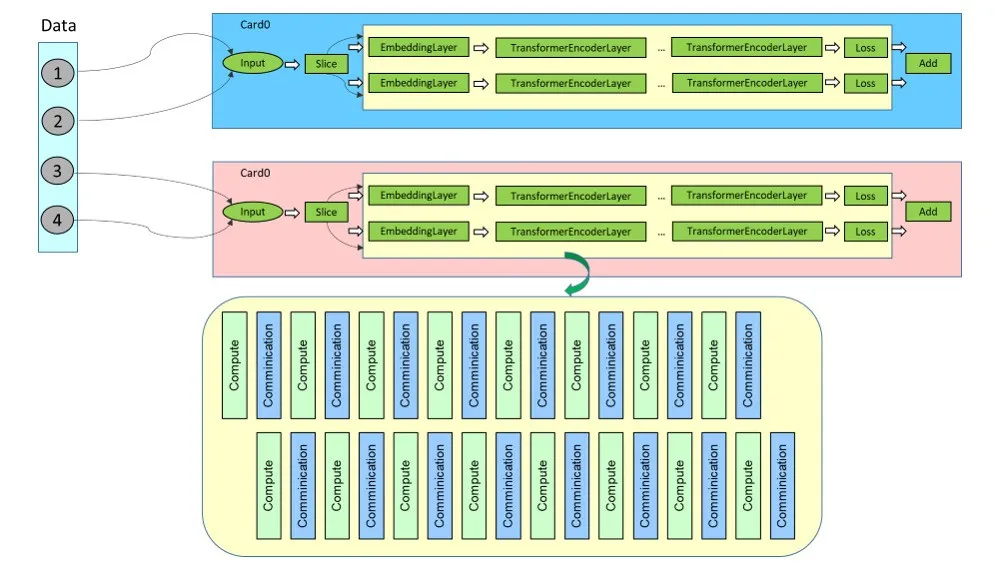
As the network scales up, limited by the graphics memory, the above approach of network-wide batch splitting is no longer feasible when the batch size on a single card can only be 1. Therefore, considering the position of communication in model parallelism, MindSpore 2.3.RC1 splits the AttentionProjection layer and FFN layer in the Transformer model to generate multiple branches, and controls fine-grained parallelism of these branches through the execution sequence scheduling algorithm. This split begins at the AttentionProjection layer and ends before the QKV computation of the next layer.
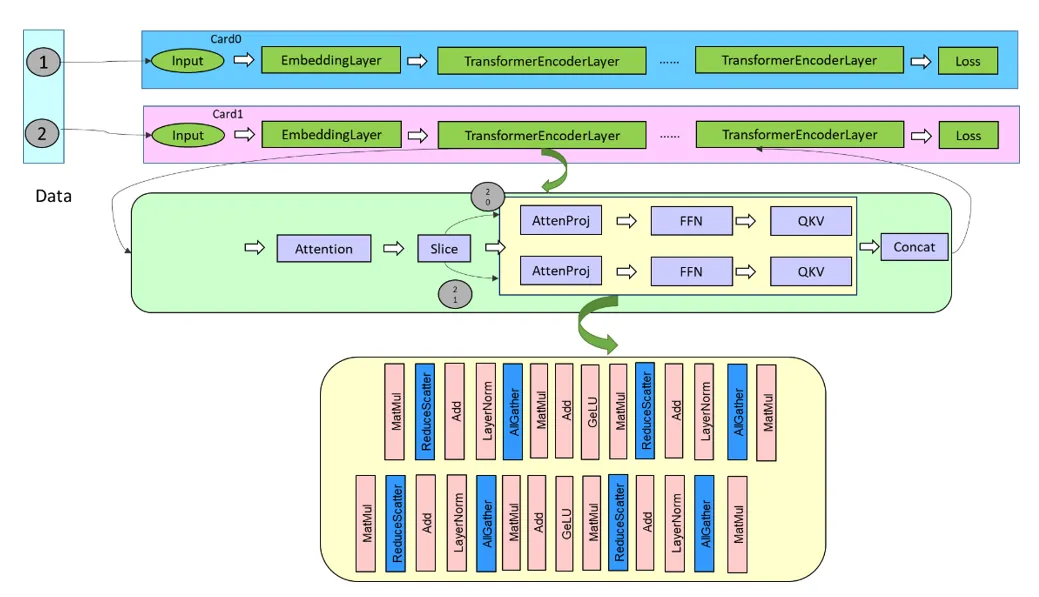
The figure above illustrates the basic idea of fine-grained multi-copy splitting and overlapping in a sequential parallelism scenario. Specifically, two copies are generated after the splitting, achieving over 50% communication overlapping in forward propagation. In backward propagation, by combining the overlapping between branch-based gradient computation and TP communication, 90% communication overlapping can be achieved. Currently, fine-grained multi-copy parallelism is only implemented in the LLaMA network of MindSpore Transformers, and requires manual restructuring of the model structure into multiple copies. In later versions, MindSpore will integrate the logic of automatic copy splitting, to achieve finer-grained multi-copy parallelism for easier use.
For details, visit https://www.mindspore.cn/tutorials/experts/en/master/parallel/multiple_copy.html.
2 Full-Stack Upgrade of Foundation Model Inference
As the adoption of foundation models for commercial applications increases, the demand for computing power during inference will become significant, resulting in high costs. Thus, the business viability of such models will depend on inference scale breakthroughs. While reducing the costs of foundation model inference, we must also balance the model accuracy and computation latency, without compromising user experience. MindSpore 2.3.RC1 provides a comprehensive suite of efficient inference solutions for users, spanning from top-layer inference services to model script optimization and the LLM Serving inference engine.
2.1 Integrated Training and Inference: Streamlining Deployment and Enhancing Efficiency with Unified Scripts for Foundation Model Training and Inference
The model scripts are enabled with incremental inference, FlashAttention/PagedAttention, and other inference acceleration technologies by default. This eliminates the need for a series of tasks such as model export, splitting, and inference script development, ensuring a faster and smoother transition from training to inference and ultimately reducing the deployment cycle to days.
2.2 Ultimate Performance: Continuously Enhancing Key Capabilities
Fused operator: More than 10 cutting-edge inference fused operator APIs have been added, enabling model developers to achieve acceleration quickly through the use of these operators.
Parallel inference: The parallelism policy APIs for training and inference are identical, offering checkpoint re-splitting APIs from parallel training to parallel inference, while also supporting dynamic-shape model splitting.
Model compression: The MindSpore Golden Stick has been upgraded to version 2.0, providing compression algorithms for state-of-the-art (SOTA) foundation models in the industry, including quantization, pruning, and other algorithms co-developed by MindSpore and Huawei Noah's Ark Laboratory, achieving over 10-fold compression of foundation models with 100 billion parameters.
The preceding technologies can be broadly applied to foundation models utilizing the Transformer architecture. After verification, it can be observed that the first token latency in the eight-card inference of Pangu or LLaMA 2 is at the 100 ms level, with an average token latency of less than 50 ms, maintaining a leading position in the industry.
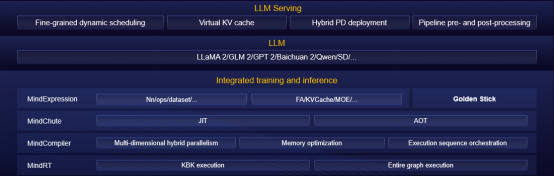
2.3 Service-Oriented High Throughput
By using continuous batch scheduling, Prefill/Decoding hybrid deployment, and other means, we strive to eliminate redundant computations, prevent computing power from being idle, and achieve a two-fold or more improvement in the inference throughput of foundation models.
For details, visit https://www.mindspore.cn/lite/docs/en/r2.3.0rc1/use/cloud_infer/runtime_distributed_python.html.
3 Static Graph Optimization: Enabling Multi-level O(n) Compilation and Kernel by Kernel Scheduling Execution, and Enhancing Static Graph Debugging and Tuning
Graph offloading is widely used due to its superior execution performance. However, as foundation models grow in scale and parameter count, the time it takes for graph offloading during graph compilation can be quite long. For instance, a foundation model with hundreds of billions of parameters can take 30 to 60 minutes to compile, leading to a low efficiency in debugging and tuning. To address the above issue, MindSpore 2.3.RC1 enables multi-level compilation, involving the O0 (native graph composition without optimization), O1 (automatic operator fusion and optimization), and O2 (graph offloading and optimization) compile options. By utilizing the O0 compile option and employing native graph compilation and kernel by kernel (KBK) execution, the compile time can be significantly reduced to less than 15 minutes. Additionally, we have developed the DryRun technology, enabling users to perform memory bottleneck analysis and parallelism policy tuning offline. Combining these two technologies can double the debugging efficiency of foundation models. Under the O0 compile option, we enable SOMAS, LazyInline, and Control Flow Inline to improve the memory overcommitment ratio, and enable multi-flow parallelism and asynchronous pipeline scheduling to enhance execution performance. Under the O1 compile option, MindSpore enables the operator fusion technology to further boost performance in KBK execution mode.
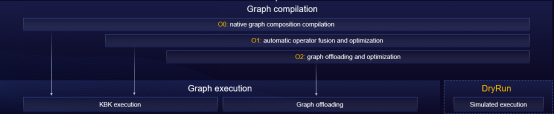
For details, visit https://www.mindspore.cn/docs/en/r2.3.0rc1/api_python/mindspore/mindspore.JitConfig.html.
4 JIT Features Ease-of-Use and High Performance with Unified Dynamic and Static Graphs, Enabling Flexible and Efficient Development
MindSpore supports two running modes: Graph mode (static graphs) and PyNative mode (dynamic graphs). Dynamic graphs are easy to debug, flexible to develop, and easy to use. Static graphs have limited syntax support but good execution performance. JIT balances performance and usability. It analyzes and adjusts Python bytecode, and captures and optimizes graphs in execution flows. Python code supported in graphs is executed in static graph mode, while unsupported code is automatically split into subgraphs and executed in dynamic graph mode, implementing unified static and dynamic graph execution, which is illustrated in the following figure.
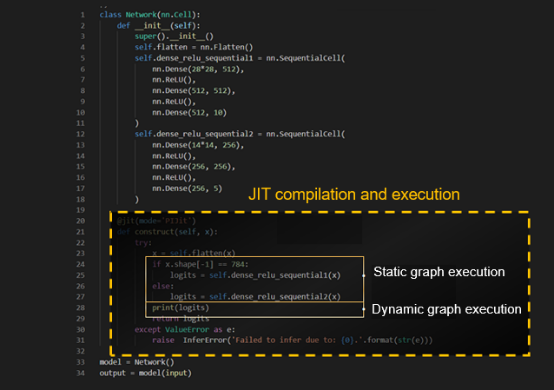
For details, visit https://www.mindspore.cn/docs/en/r2.3/design/dynamic_graph_and_static_graph.html.
5 MindSpore Elec: A New MT Intelligent Inversion Model
The MindSpore electromagnetic simulation suite, MindSpore Elec, is upgraded to version 0.3. It is a MindSpore-powered magnetotelluric (MT) intelligent inversion model developed by the team led by Professor Li Maokun from Tsinghua University and Huawei Advanced Computing and Storage Laboratory. The model, built with a variational autoencoder (VAE) that flexibly incorporates priori knowledge of multiphysics, has achieved the SOTA result in the industry. This achievement has been published in the prestigious journal Geophysics, a top international journal of exploration and geophysics, and has also been demonstrated at the MindSpore Artificial Intelligence Framework Summit 2024.
(1) Basic MT inversion: The horizontal length of the inversion area is 10 km, and the depth is 1 km. In the figure below, the target resistivity distribution (first column), conventional MT inversion (second column), and MT intelligent inversion (third column) are displayed, demonstrating that the precision of MT intelligent inversion is significantly improved compared with that of conventional inversion (the residuals of the former are 0.0056 and 0.0054, and the residuals of the latter are 0.023 and 0.024). As seen in figure 2, the overall performance of the MT intelligent inversion method also surpasses that of the conventional inversion method (the convergence iterations of the former are 4 and 4, while the convergence iterations of the latter are 6 and 4).
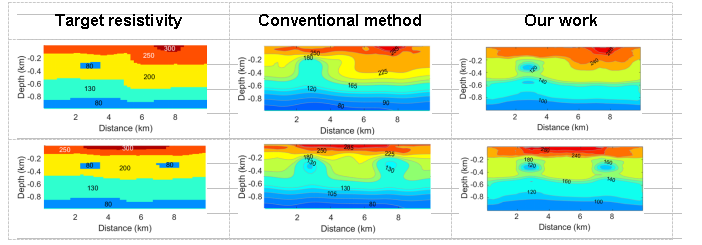
Figure 1 Comparison of MT inversion precisions
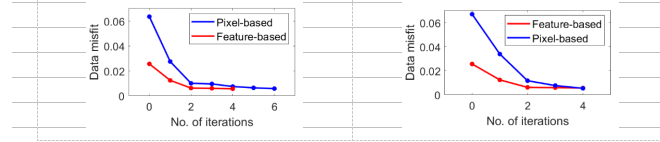
Figure 2 Comparison of convergence speeds of MT inversion (Pixel-based: conventional inversion; Feature-based: our work)
(2) MT inversion in Southern Africa: The MT intelligent inversion model has also been verified on the Southern African Magnetotelluric Experiment (SAMTEX). The inversion area is located near the west coast of Southern Africa with a length about 750 km and depth of 80 km. The area is characterized by a highly conductive structure that exists in a shallow area, which is located between 100 km and 400 km in the horizontal direction and at a depth less than 20 km. Due to the attenuation of low-frequency electromagnetic waves in conductors, the MT method exhibits low sensitivity towards the lower area of highly conductive structures. Therefore, it is challenging for conventional MT inversion without priori knowledge constraints to accurately reconstruct the lower boundary position of highly conductive formations. MT intelligent inversion provides a clear and accurate reconstruction of the lower boundary of highly conductive formations, as it effectively incorporates priori knowledge of formation thickness into the inversion process.
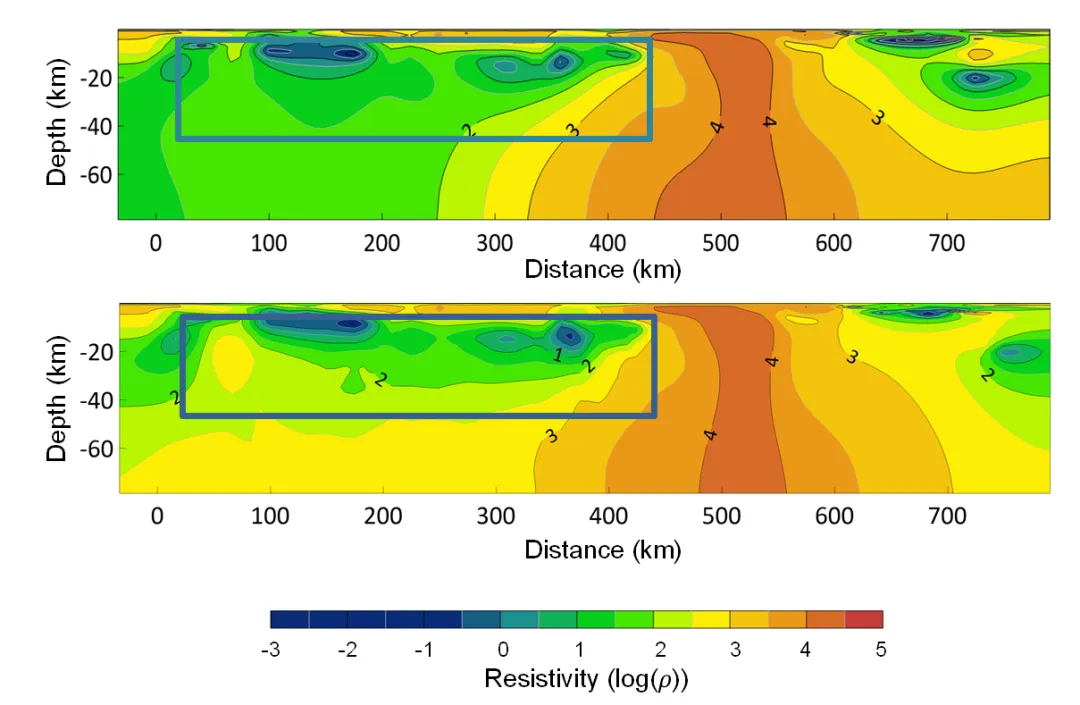
Figure 3 MT inversion in Southern Africa (above: conventional inversion; below: our work)
For details, visit https://gitee.com/mindspore/mindscience/tree/master/MindElec.