MindSpore 2.8 Is Officially Released, Featuring the HyperParallel Architecture Designed for Supernodes, Making Training and Inference More Flexible and Efficient
MindSpore 2.8 Is Officially Released, Featuring the HyperParallel Architecture Designed for Supernodes, Making Training and Inference More Flexible and Efficient
After months of development and contributions from the MindSpore open-source community, the MindSpore 2.8 framework is now available.
Facing the three urgent challenges of continuous model scale growth, increasingly irregular structure, and increasingly obvious heterogeneity, MindSpore launches the HyperParallel architecture through collaborative design with supernodes. This architecture treats supernodes as supercomputers for programming and scheduling. It is supported by three key technologies: HyperShard, a simplified declarative parallel programming framework; HyperOffload with the multilevel intelligent offloading capability; and HyperMPMD with irregular heterogeneous parallelism.
In terms of basic framework evolution, the Dispatch function is provided, the saved_tensors_hook mechanism and operator-level registration mechanism are introduced to enhance dynamic graph capabilities, and multiple framework customization capabilities are opened to provide a more flexible and efficient framework extension mechanism.
In terms of improving the inference capability of LLMs, MindSpore collaborates with the SGLang community to support and adapt to core features such as Radix Cache, upgrade and adapt to the latest version of vLLM v0.11.0, and integrate the graph offloading feature of Ascend ACLGraph.
In terms of scientific computing suites, the protein structure prediction model Protenix is supported, and high-performance training and inference are implemented.
Now, let's delve into the key features of MindSpore 2.8.
-- Enhanced LLM Training Capability --
1 HyperShard Declarative Parallelism, Creating a Triton Paradigm for Distributed Parallelism
To cope with the continuous expansion and increasingly complex structure of AI models, MindSpore 2.8 launches the HyperShard declarative parallel programming paradigm. As shown in the following figure, HyperShard aims to completely simplify distributed training and decouple parallel policies from model computing logic, so that users can free themselves from the burden of intrusive code modification to adapt to distributed systems and focus on model innovation.
HyperShard integrates supernode-aware scheduling and global resource collaboration, significantly reducing programming complexity while achieving parallel efficiency close to the theoretical limit. It is dedicated to creating a Triton paradigm that makes efficient parallelism as natural as writing serial code. In particular, it supports flexible assembly of multimodal LLM codec architectures, providing a truly user-centric parallel experience while ensuring optimal performance.
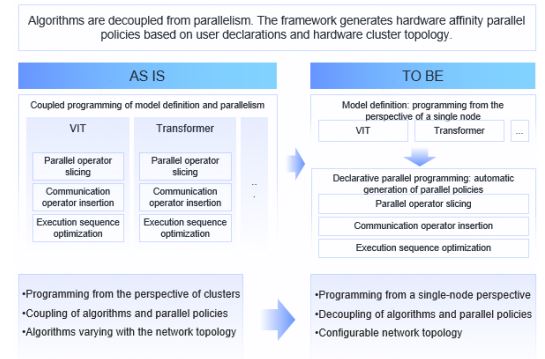
Built on the foundation of MindSpore's dynamic and static capabilities, HyperShard provides a highly decoupled and model-centric declarative parallel library. As shown in the following figure, the system offers three programming paradigms: manual, DTensor, and Shard, allowing users to flexibly choose between fine-grained control and global policy declaration. The basic parallel module, as a pluggable component, separates the single-device algorithm logic, parallel strategy description, graph compilation, and runtime scheduling. This enables non-intrusive parallel extension. Users only need to write PyNative dynamic graph code from the perspective of a single device, and the system will automatically derive distributed strategies, split subgraphs, map resources, and schedule hybrid parallelism. In this way, users can enjoy the experience of writing code for single-device training and running it in distributed mode. Users only need to specify what to do, and the system will automatically execute the task, achieving extremely easy-to-use and out-of-the-box optimal performance. Most of the dynamic graph capabilities mentioned above have been built in the HyperParallel sub-repository. Currently, a preview version is available, and the more stable capabilities will be provided in the future.
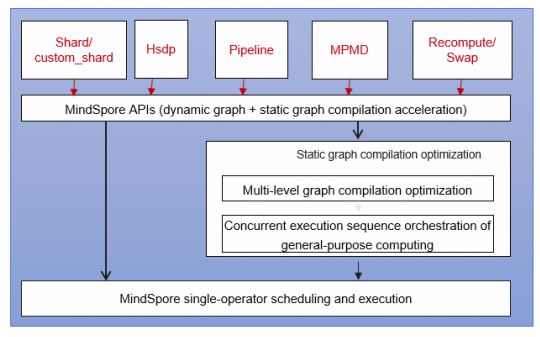
Reference: https://atomgit.com/mindspore/hyper-parallel
-- Continuous Evolution of the Basic Framework --
2 HyperOffload Enabling Automatic Hierarchical Data Management Across the Entire Graph, Significantly Improving Graphics Memory Utilization and Training Throughput
In the training and inference of ultra-large models, the storage capacity and data transmission bandwidth of hardware accelerators have become key bottlenecks that restrict system performance. To address this challenge, MindSpore 2.8 introduces and implements a hierarchical storage management solution called HyperOffload, which is based on full-graph orchestration. This solution aims to improve resource utilization and execution efficiency in heterogeneous computing environments through system-level architecture optimization.
The core innovation of HyperOffload lies in the operator-based abstraction of data transmission and pipeline parallelism. It breaks the traditional boundary between computing and communication, and abstracts data movement operations across different storage levels into operators at the graph level, integrating them into a unified computational graph orchestration system. With the Just-In-Time (JIT) compilation engine of MindSpore, the system can perform in-depth analysis and optimization on static computational graphs, and automatically build parallel pipelines for computing and communication. By prefetching subsequent data during the execution of computational tasks, this mechanism effectively masks the high-latency I/O overhead and significantly reduces the idle waiting time of computational units.
To meet the requirements of different development modes, HyperOffload provides the following flexible access modes:
- Static graph mode: achieves a high degree of automation. For most application scenarios, users do not need to modify the original training scripts. The framework can automatically reconstruct the computational graph and optimize memory through full-graph compilation. Benchmark tests show that after this feature is enabled, the model training throughput is improved by more than 10% on average.
- Dynamic graph mode: Considering the complexity and flexibility of dynamic execution, HyperOffload opens up the underlying storage management APIs. Users can manually call the APIs to precisely control the timing of offloading and loading model parameters and intermediate data based on the model logic. This fine-grained control capability can be used to optimize the graphics memory usage during dynamic graph debugging or specific algorithm implementation, implementing customized memory management policies.
Note: HyperOffload is currently in the experimental phase. Although preliminary verification has shown that this architecture has significant advantages in improving graphics memory efficiency and computing throughput, further verification is required for adapting to specific complex network structures. In the future, we will continue to optimize the memory scheduling algorithm and full-graph compilation policy, and strive to provide stable and efficient heterogeneous storage solutions in a wider range of production environments.
Reference: https://www.mindspore.cn/docs/en/master/api_python/mindspore/mindspore.jit.html
3 Enhanced Dynamic Graph Capabilities, Supporting More Flexible Execution and Extension Mechanisms
MindSpore continuously iterates in the dynamic graph (PyNative) mode. In MindSpore 2.8, three important enhanced features are introduced to address the core pain points of usability, computing power utilization, and large-scale parallel scenarios. These capabilities work together to provide users with a more efficient, flexible, and scalable deep learning development experience.
3.1Dynamic Graph Dispatch Function
The brand-new tensor dispatch capability supplements the core capability of dynamic graphs in supporting heterogeneous devices. Currently, this feature is used as a demo and can be enabled through environment variables. After this function is enabled, you do not need to perform additional coding for operator selection or device matching. You only need to place the tensor on the target device, and the framework can automatically dispatch and call the operator based on the storage location of the tensor. With this mechanism, MindSpore significantly improves the usability and consistency in multi-device collaboration scenarios.
Reference: https://www.mindspore.cn/docs/en/master/api_python/env_var_list.html?highlight=dispatch
3.2saved_tensors_hook for Dynamic Graphs
The saved_tensors_hook mechanism is introduced to incorporate the activation value lifecycle into the orchestration scope. With the help of the pack/unpack hook, the activation offload capability can be implemented without intruding into the core model logic. This not only provides more proactive and memory-efficient policies for LLM training, but also opens up space for more innovative memory optimization methods in the future, making training in dynamic graph mode more flexible, robust, and efficient.
3.3Dynamic Graph Operator-Level Registration Mechanism
The operator-level registration mechanism is provided to enhance the scalability of dynamic graphs to a new level. By inheriting tensors and implementing the fallback function in the subclass, various components can inject custom behavior into the operator execution link. This capability is particularly critical for declarative programming. Users can automatically insert parallel layouts or custom policies into operators without modifying the model code, accelerating the construction of complex distributed training systems.
With the release of these three capabilities, MindSpore's dynamic graphs have taken a significant step forward in terms of usability and compatibility, providing users with more efficient and deterministic workflows from operator debugging to LLM training.
4 Opening Multiple Framework Customization Capabilities to Flexibly and Efficiently Implement Custom Logic
As the AI model and hardware ecosystem become increasingly complex, users often face two major challenges when pursuing optimal performance and innovation. First, the fixed operator libraries of mainstream deep learning frameworks cannot cover all cutting-edge algorithms or operators required by specific fields (such as scientific computing). Second, the default optimization policies and runtime of the frameworks cannot fully unleash the full potential of dedicated hardware (such as new AI accelerator cards). This gap between framework universality and service/hardware specificity limits the depth and efficiency of technology implementation. MindSpore 2.8 significantly enhances the openness of framework customization capabilities, providing users with a more flexible and efficient framework extension mechanism in terms of custom operators, custom passes, and custom backends.
4.1Custom Operators
Custom operators provide simplified C++ development APIs and built-in multi-level pipelines. Once compiled, the user kernel can be seamlessly embedded into the MindSpore execution graph, automatically enjoying framework-level optimization such as memory overcommitment and asynchronous scheduling. With the CustomOpBuilder tool, the compilation and loading are completed in one step, and the operators are directly called like ordinary operators. In addition, the runners AclnnOpRunner, AtbOpRunner, and AsdSipFFTOpRunner are tailored for the ACLNN, ATB, and ASDSIP acceleration libraries, respectively. They can be integrated with high-performance operators at no cost. You can also inherit PyboostRunner to quickly encapsulate private kernels, enabling innovative operators to be quickly launched and performance to be immediately released in both scientific research and production lines.
Reference: https://www.mindspore.cn/tutorials/en/master/custom_program/operation/op_customopbuilder.html
4.2Custom Pass
MindSpore opens the APIs for writing and registering framework passes. You can write and register custom passes to insert custom graph optimization logic and transform computational graphs during compilation.
- The PatternToPattern Pass parent class and necessary tool methods are opened. You can inherit the PatternToPattern Pass to implement the pass logic such as the source pattern, target pattern, and additional matching conditions, achieving the target of computational graph transformation optimization.
- The custom pass registration API register_custom_pass is provided. You can register custom passes in different backends and phases as required.
Reference: https://www.mindspore.cn/tutorials/en/master/custom_program/custom_pass.html
4.3Custom Backend
MindSpore opens up the APIs for backend compilation and execution extension, allowing users to adapt to third-party backends.
- It provides an abstraction layer for core modules such as backend compilation and execution and backend management, allowing users to customize compilation and execution behaviors.
- Users can freely switch between different backends for compilation and execution.
Reference: https://www.mindspore.cn/tutorials/en/master/custom_program/custom_backend.html
MindSpore significantly enhances the openness and scalability of the framework by enhancing three customization capabilities. Users can flexibly customize the computing logic, optimization policies, and runtime support for specific algorithms, hardware, or scenarios. This enables users to fully leverage the potential of software-hardware collaboration while maintaining the framework's consistency, thus accelerating AI application innovation and implementation.
-- Enhanced LLM Inference Capability --
5 Supporting SGLang and Adapting to the Latest Version vLLM v0.11.0 After Upgrade
As an inference service framework designed for production-level deployment, SGLang features low latency, high throughput, and quick adaptation to SOTA models such as DeepSeek-V3.2 Exp and Qwen3-Next, making it another mainstream LLM inference engine following vLLM. In November 2025, after multiple rounds of solution discussions and technical verification, the SGLang community has integrated the MindSpore inference backend code, supporting accelerated inference of LLMs based on Ascend and MindSpore.
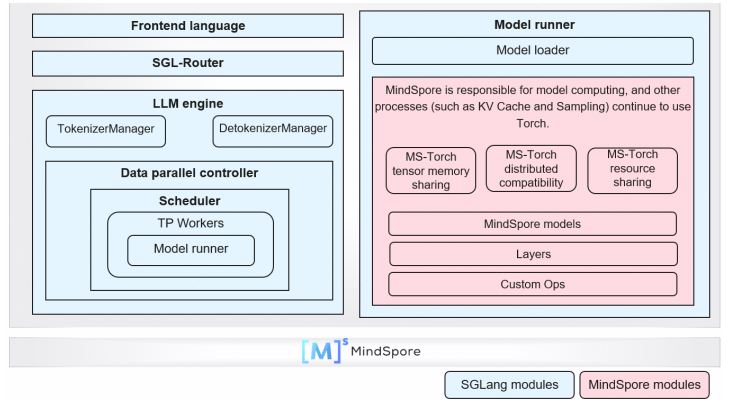
As shown in the preceding figure, SGLang uses the backend component-based access solution to support the inference of MindSpore LLMs. This solution reuses the service modules of SGLang, including the frontend language, router, and data parallel controller. Only in the model execution module, the MindSpore inference model is encapsulated into the MindSporeForCausalLM class to replace the SGLang model class.
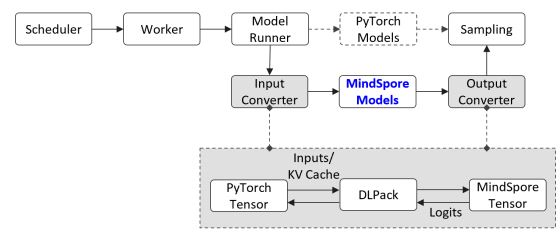
As shown in the preceding figure, this project adapts to the DLPack function library to implement efficient reuse of data structures such as PyTorch tensors and HCCL communication groups between MindSpore and PyTorch across AI frameworks. As such, MindSpore inference models can be seamlessly embedded into the functional processes that involve PyTorch API calls. With only simple API adaptation, features such as Radix Cache, data and tensor parallelism, PD separation, and speculative inference of SGLang can be supported.
Currently, SGLang 0.5.6 has been equipped with the MindSpore inference backend, supporting DeepSeek-V3/R1 and Qwen3 models, and core service features such as Radix Cache, hybrid parallelism, and PD separation. To improve project maintainability, MindSpore inference model scripts are developed in an independent repository. Currently, the scripts are temporarily hosted in the MindSpore-Lab organization (https://github.com/mindspore-lab/sgl-mindspore). After verification, the scripts will be moved to the SGLang community organization (https://github.com/sgl-project).
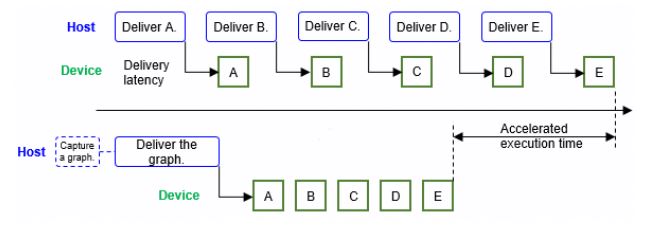
MindSpore inference has been upgraded to adapt to vLLM v0.11.0, following the upstream community's architecture evolution. The outdated V0 architecture code has been removed, and the Ascend ACLGraph function has been integrated. As shown in the preceding figure, ACLGraph can capture multiple operators to be executed into a graph and deliver them at a time, effectively eliminating the problem of low NPU resource utilization caused by host bound. According to the test result, when the DeepSeek-V3/R1 W4A8 quantization inference service is deployed using vLLM and MindSpore, and the ACLGraph function is enabled, the throughput of the entire network is improved by about 5%, and the average operator delivery latency is reduced from 30 ms to 10 ms. In addition, this upgrade supports SOTA models such as GLM-4.1V-Thinking, Qwen3-VL, and MiniCPM4.
-- Scientific Computing Suite Enhancement --
6 Protenix: A Protein Structure Prediction Model for High-Performance Training and Inference
Protenix is a high-performance open-source reproduction model of AlphaFold3. It uses an advanced diffusion generation architecture, complete open-source code, and weights to provide global biomedicine researchers with an efficient tool that can be directly trained and fine-tuned and has performance comparable to that of top closed-source models. MindSpore 2.8 supports Protenix and implements high-performance training and inference on the Ascend hardware platform.
In terms of model training, the compute modules such as Triangle Attention, Triangle Multiplication, and smooth_lddt_loss, which involve a large number of activation values, are recalculated. Before the optimization, only sequences with a length of 64 can be trained with 64 GB of graphics memory, and the peak dynamic graphics memory usage is about 20,152 MB. After the optimization, the maximum sequence length can be increased to 768, and the peak graphics memory usage can be reduced to 7,025 MB. This optimization is one of the key technologies that enable Protenix to support long-sequence training on the Ascend hardware platform.
In terms of model inference, the performance bottleneck caused by the Unfold operator is eliminated by operator reconstruction. In addition, the EvoformerAttention operator is developed and the logic of the Einsum operator is optimized. When the two operators are used together, the single-device inference performance can be improved by more than 100%. For long-sequence inference, MindSpore addresses the memory bottlenecks in modules such as msa_attention, triangle_multiplication, and transition_block. It uses the block-based computation mode and avoids the dimensions involved in non-linear operations such as LayerNorm and Softmax. This successfully increases the maximum token length of single-device inference on Ascend hardware to more than 3,000, without changing the inference accuracy. Finally, the JIT compilation of the Transformer core module is optimized, and the module is compiled into static graphs in advance. During execution, the static graphs are delivered in the form of large operators at a time, greatly reducing the operator scheduling cost. As a result, the end-to-end acceleration ratio is 57%.
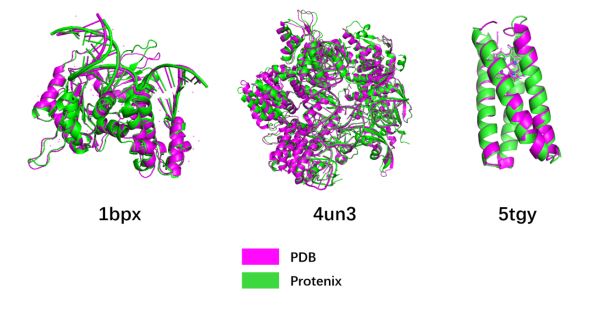
According to the preceding optimization strategy, the Protenix model can achieve a maximum training length of 768 on a 64-GB single-device Ascend hardware, and the maximum inference length on a single device exceeds 3000. As shown in the figure above, the inference result of the Protenix model based on Ascend hardware is consistent with the spatial structure of the actual protein data bank (PDB).