MindSpore 2.2, Improving Foundation Model Compilation Efficiency and Supporting More Trending Pre-trained Models
MindSpore 2.2, Improving Foundation Model Compilation Efficiency and Supporting More Trending Pre-trained Models
After two months of development, the MindSpore community officially releases MindSpore 2.2 to continuously improve foundation model capabilities. The lazy inline method is provided to improve the compilation efficiency of foundation models. The domain-specific foundation model suite MindSpore Transformers supports more than 20 trending pre-trained models and more than 52 typical specifications out of the box. In addition, the generative domain-specific suite MindSpore One is released to integrate easy-to-use APIs and cutting-edge algorithm models. The AI4Sci most-frequently-used model suite MindSpore SciAI and earth science model suite MindSpore Earth are released, providing an efficient and easy-to-use AI4Sci general-purpose computing platform and more application scenarios. Here is a detailed look at the key features of MindSpore 2.2.
1. Lazy Inline: Significantly Improving the Static Graph Compilation Efficiency of Foundation Models
In the pipeline parallelism scenario of neural network models (especially LLMs), a conventional compilation process inlines hierarchical code expression into a flat graph for a compute unit that is repeatedly called. In lazy inline method, inline is not executed or is executed only in the last phase before execution. This significantly reduces the graph scale and improves compilation performance by multiples. We verified the lazy inline compilation efficiency improvement effect through the PanGu 13B network: The number of computational graph compilation nodes is reduced from 130 thousands to 20 thousands, the compilation time is reduced from 3 hours to 20 minutes, and the efficiency is improved by over 900%.
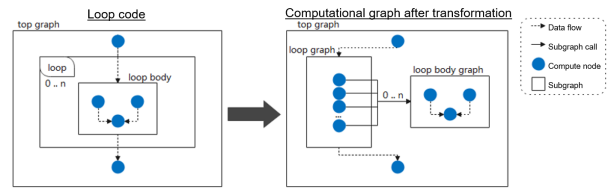
There is only one loop body graph. The subgraph is called for multiple times by using the lazy inline method.
2. MindSpore Transformers: Supporting 20+ Trending Pre-trained Models and 52+ Typical Specifications Out of the Box
MindSpore Transformers aims to build a development suite that covers the entire process of training, fine-tuning, evaluation, inference, and deployment within the lifecycle of a foundation model. It covers trending domains such as CV, NLP, and AIGC, provides quick development capabilities, and supports 20+ trending pre-trained models, 52+ typical specifications out of the box, and large-scale cluster training and deployment in AICC. In addition, MindSpore supports the configuration-based development of multi-dimensional storage optimization and multi-dimensional distributed hybrid parallel features.
2.1 Supporting Trending Pre-trained Models
MindSpore Transformers supports Llama 2, Baichuan 2, GLM2, InternLM, Ziya, SAM, CodeGeeX2, and BLIP-2 pre-trained models. The following table lists the supported models.
Model
Specification
Applicable Mode
GLM2
glm2_6b glm2_6b_lora
Pre-training, fine-tuning, evaluation, and inference/MSLite inference
Llama 2
llama2_7b llama2_13b
Pre-training, fine-tuning, evaluation, and inference/MSLite inference
Baichuan 2
baichuan2_7b baichuan2_13b
Pre-training, fine-tuning, evaluation, and inference
CodeGeeX2
codegeex2_6b
Pre-training, fine-tuning, and inference
BLIP-2
blip2_stage1_vit_g blip2_stage1_classification itt_blip2_stage2_vit_g_baichuan_7b itt_blip2_stage2_vit_g_llama_7b
Pre-training, fine-tuning, evaluation, and inference
GLM
glm_6b glm_6b_lora
Pre-training, fine-tuning, evaluation, and inference/MSLite inference
Baichuan
baichuan_7b baichuan_13b
Pre-training, fine-tuning, evaluation, and inference
Llama
llama_7b llama_13b llama_7b_lora
Pre-training, fine-tuning, evaluation, and inference/MSLite inference
BLOOM
bloom_560m bloom_7.1b bloom_65b bloom_176b
Pre-training, fine-tuning, evaluation, and inference/MSLite inference
InternLM
Internlm_7b Internlm_7b_lora
Pre-training, fine-tuning, evaluation, and inference
Ziya
ziya-13b
Pre-training, fine-tuning, evaluation, and inference
GPT
gpt2 gpt2_lora gpt2_txtcls gpt2_xl gpt2_xl_lora gpt2_13b gpt2_52b
Pre-training, fine-tuning, evaluation, and inference
PanGu-α
pangualpha_2_6_b pangualpha_13b
Pre-training, fine-tuning, evaluation, and inference
BERT
bert_base_uncased txtcls_bert_base_uncased txtcls_bert_base_uncased_mnli tokcls_bert_base_chinese tokcls_bert_base_chinese_cluener qa_bert_base_uncased qa_bert_base_chinese_uncased
Pre-training, fine-tuning, evaluation, and inference
T5
t5_small
Pre-training, fine-tuning, and inference
MAE
mae_vit_base_p16
Pre-training and inference
VIT
vit_base_p16
Pre-training, fine-tuning, evaluation, and inference
Swin
swin_base_p4w7
Pre-training, fine-tuning, evaluation, and inference
CLIP
clip_vit_b_32 clip_vit_b_16 clip_vit_l_14 clip_vit_l_14@336
Fine-tuning, evaluation, and inference
SAM
sam_vit_b sam_vit_l sam_vit_h
Inference
2.2 Online Pipeline Inference Experience
MindSpore Transformers provides convenient pipeline inference APIs. You can specify tasks and model specifications to complete foundation model inference.
import mindspore as ms from mindformers import pipeline ms.set_context(mode=0) pipeline_task = pipeline(task=text_generation, model=glm2_6b, max_length=193) pipeline_task ("Hello") # [{text_generation_text: [Hello! I am an artificial intelligence assistant ChatGLM2-6B. Its a pleasure to meet you, and welcome any questions you may have. ]}]
The preceding describes single-device single-batch inference. If multi-batch, distributed parallel, or MSLite inference is required, see the official GLM2 inference tutorial.
MindSpore Transformers also provides a convenient online LLM chat interface. You can experience the SOTA model chat capability by referring to the official tutorial. Multiple parameters can be adjusted, multiple prompt templates can be defined, and streaming inference can be displayed.
2.3 Trainer Task Scheduling
MindSpore Transformers provides high-level Trainer scheduling and development APIs to help users easily schedule foundation models that have been integrated into MindFormers or customized models. In addition, MindSpore Transformers supports features such as hyperparameter customization, evaluation during training, resumption training, and fine-tuning with fewer parameters.
from mindspore as ms from mindspore.dataset import GeneratorDataset from mindformers import Trainer, TrainingArguments # Set the running mode to graph mode and the running device to the Ascend AI Processor. ms.set_context(mode=0, device_target="Ascend") def train_data(): """train dataset generator.""" seq_len = 128 input_ids = np.random.randint(low=0, high=15, size=(seq_len,)).astype(np.int32) labels = np.random.randint(low=0, high=15, size=(seq_len,)).astype(np.int32) train_data = (input_ids, labels) for _ in range(32): yield train_data def eval_data(): """eval dataset generator.""" seq_len = 127 input_ids = np.random.randint(low=0, high=15, size=(seq_len,)).astype(np.int32) labels = np.random.randint(low=0, high=15, size=(seq_len,)).astype(np.int32) eval_data = (input_ids, labels) for _ in range(8): yield eval_data def main(run_mode="finetune", task=text_generation, model_type=glm2_6b, pet_method=lora): # Fine-tune the hyperparameter definition. training_args = TrainingArguments(num_train_epochs=1, batch_size=2, learning_rate=0.001, warmup_steps=100, sink_mode=True, sink_size=2) # Prepare data. train_dataset = GeneratorDataset(train_data, column_names=["input_ids", "labels"]) eval_dataset = GeneratorDataset(eval_data, column_names=["input_ids", "labels"]) train_dataset = train_dataset.batch(batch_size=2) eval_dataset = eval_dataset.batch(batch_size=2) # Define a Trainer task. task = Trainer(task=task, model=model_type, pet_method=pet_method, args=training_args, train_dataset=train_dataset, eval_dataset=eval_dataset) # Schedule training, fine-tuning, evaluation, and inference in one click. if run_mode == train: task.train() elif run_mode == finetune: task.fintune() elif run_mode == eval: task.evaluate() elif run_mode == predict: predict_result = task.predict(input_data="Hello") print(predict_result) #[{text_generation_text: [Hello. I am an AI assistant ChatGLM2-6B. The model Im using is GLM2-6B, a large language model with more than 200 billion parameters and supporting multiple tasks. ]}] if __name__ == __main__: # Fine-tune the GLM2-6B foundation model LoRA with fewer parameters. In addition, one-click evaluation and inference are supported. main(run_mode="finetune", task=text_generation, model_type=glm2_6b, pet_method=lora)
The preceding shows the training, fine-tuning, evaluation, and inference processes of a foundation model started by Trainer with a single device. If distributed parallel running is required, see the [official GLM2 tutorial](# %E5%BE %AE %E8%B0%83).
2.4 AutoClass: Quick Index Instantiation
MindSpore Transformers presets Tokenizer, Processor, ModelConfig and ModelClasses of multiple SOTA foundation model specifications. You can use from_pretrained of the AutoClass API provided by MindSpore Transformers to instantiate APIs and obtain the corresponding vocabulary and weight files, helping you easily customize and develop innovative foundation models.
from mindformers import AutoConfig, AutoModel, AutoTokenizer # Obtain the tokenizer of GLM2-6B. tokenizer = AutoTokenizer.from_pretrained(glm2_6b) # Tokenize words using the GLM2-6B Tokenizer. inputs = tokenizer("Hello")["input_ids"] # Method 1: Obtain the model instance to which the GLM2-6B model weight is loaded and enable the incremental inference function. model1 = AutoModel.from_pretrained(glm2_6b, use_past=True) # Method 2: Obtain the GLM2-6B model configuration and enable the incremental inference function. config = AutoConfig.from_pretrained(glm2_6b, use_past=True) model2 = AutoModel.from_config(config) # Generate the inference result. Multiple generation parameters are supported. outputs = model1.generate(inputs, max_new_tokens=20, do_sample=True, top_k=3) response = tokenizer.decode(outputs) print(response) # [Hello. I am an AI assistant. Welcome any questions you may have. ]
For more functions and documents, visit https://gitee.com/mindspore/mindformers.
3. MindSpore One: Generative Domain-specific Model Suite, Integrating Easy-to-Use APIs and Cutting-Edge Algorithm Models, Facilitating AI Development and Innovation
MindSpore One is a high-quality generative domain-specific algorithm model library based on MindSpore. It provides easy-to-use module APIs and built-in latest image and video generative models such as Wukong-Huahua, SD1.5, SD2.0, SDXL, and VideoComposer, efficiently supporting integrated deployment of training and inference. It features easy-to-use, efficient fine-tuning, and leading performance.
(1) Easy to use: APIs are simple. Built-in base modules such as CLIP, OpenCLIP, VAE, and UNet and multiple diffusion models are provided. You can easily build your own data processes and models out of the box.
(2) Efficient fine-tuning: Personalized fine-tuning methods are supported, such as LoRA and DreamBooth, to adapt to generative tasks in different domains and help you build personalized generative models.
(3) Leading performance: All-scenario inference is supported. MindSpore Lite is used for offline inference, and the average image generation time is 3 seconds.
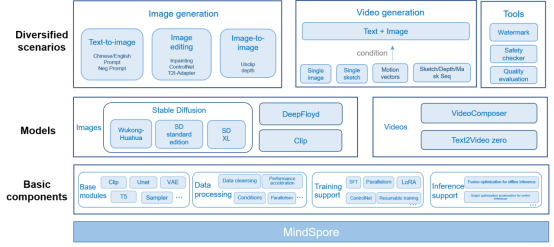
For details, visit https://github.com/mindspore-lab/mindone.
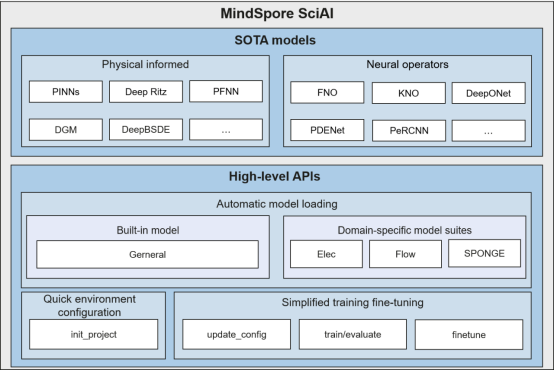
4. MindSpore SciAI 0.1: AI4Sci Most-Frequently-Used Model Suite, Ranking No.1 in Terms of Model Coverage in the World
MindSpore SciAI is an AI4Sci most-frequently-used model suite built based on MindSpore. It has more than 60 built-in most-frequently-used SOTA models, covering physical informed models (such as PINNs, DeepRitz, and PFNN) and neural operators (such as FNO, DeepONet, and PDENet) and ranking top No.1 in terms of model coverage in the world. High-level APIs (such as one-click environment configuration, automatic model loading, and simplified training fine-tuning) are provided for developers and users out of the box. MindSpore SciAI provides developers and users with an efficient and easy-to-use AI4Sci general-purpose computing platform. The following figure shows the MindSpore SciAI architecture.
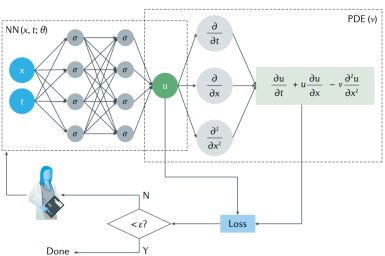
4.1 Physical Informed Models
A physical informed model is a type of model that integrates prior knowledge (such as equations/initial boundary conditions) in physics into a neural network. Typical models include PINNs (as shown in figure 2), Deep Ritz, PFNN, and the like. Advantages: No discrete grid is generated. Derivative calculation can be performed based on the automatic differentiation capability of the AI framework to avoid numerical differential discrete errors. This type of model is naturally applicable to inverse problems and data assimilation problems. Compared with data-driven models, this type of model has stronger extrapolation capability and fewer samples. Disadvantages: Lack of network structure design guidance makes it difficult to learn singularity problems. Loss functions contain multiple constraints, making training difficult to converge. Retraining is required when physical constraints change, lacking generalization. Calculation accuracy and convergence lack theoretical assurance.
To solve the preceding problems, the academia and MindSpore propose a series of improvement schemes, such as adaptive activation function, time & space decomposition, multi-scale optimization, and adaptive weighting. MindSpore SciAI has built-in SOTA physical informed models which are applicable to domains such as fluid, electromagnetic, sound, heat, and solid.
4.2 Neural Operators
Physical informed models such as PINNs mainly solve specific equations, while neural operator models can learn the mapping of infinite dimension function space and solve the entire PDE family at a time. Typical examples include FNO (as shown in figure 3), DeepONet, PDENet, and the like. FNO mainly uses the properties of Fourier transform to learn the mapping between functions in Fourier space, and then converts the result back to physical space. DeepONet learns the mapping between functions through the branch net and trunk net. A neural operator model has good performance in fluid, meteorology, and electromagnetic domains. Therefore, MindSpore SciAI also has built-in SOTA neural operator models.
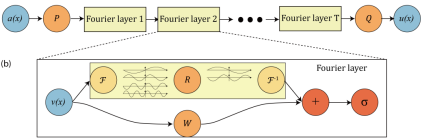
For details, visit https://gitee.com/mindspore/mindscience/tree/master/SciAI.
5. MindSpore Earth 0.1: Earth Science Suite, Covering Forecast Scenarios Such As Mid-term Weather Forecast and Short-term Precipitation at Multiple Spatiotemporal Scales
Weather forecast is closely related to peoples work and life, and is one of the most widely concerned application scenarios in the AI4Sci domain. MindSpore released MindSpore Earth, the Earth Science Suite 0.1. This suite integrates the AI weather forecast SOTA model at multiple spatiotemporal scales, provides tools such as data pre-processing and forecast visualization, and integrates ERA5 reanalysis, radar echo, and high-resolution DEM datasets. We are committed to efficiently enabling AI+ meteorology and ocean forecast convergence research.
The following figure shows the MindSpore Earth architecture planning. Multiple SOTA models, including GraphCast, ViT-KNO, FourCastNet, and DGMR, are used in scenarios such as short-term precipitation, mid-term weather forecast, and super-resolution. The model coverage is industry-leading, the forecast accuracy is higher than that of the traditional numerical mode, and the forecast speed is more than 1000 times higher than that of the traditional numerical mode.
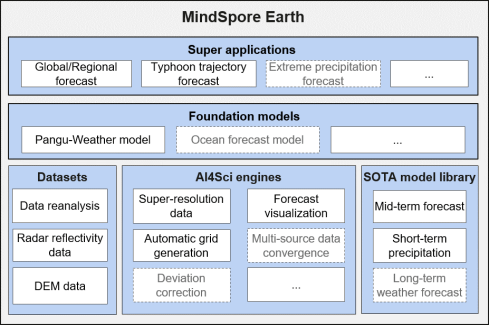
• Mid-term weather forecast: MindSpore Earth provides multiple SOTA AI mid-term forecast models, including FourCastNet and GraphCast, as well as ViT-KNO which is jointly launched by Huawei Advanced Computing and Storage Laboratory and Tsinghua University. Second-level inference can be implemented for factors such as temperature, wind speed, and humidity in the next week.
• Short-term precipitation forecast: MindSpore Earth provides the DGMR precipitation model. Based on MindSpore Earth and Ascend, you can perform efficient training and inference on precipitation intensity and spatial distribution.
• Data pre-processing: The MindSpore team, AI4Sci Lab, and Tsinghua University jointly launched the DEM super-resolution model applicable to global regions. This model outperforms the widely used super-resolution model in terms of RMSE indicators, definition, and details.
For details, visit https://gitee.com/mindspore/mindscience/tree/master/MindEarth.
6. BF16 Data Type
BF16, also called BFloat16 or Brain Float16, is a relatively new floating-point number format. It obtains larger numerical space by reducing a small amount of precision, improves performance, and reduces memory consumption.
MindSpore 2.2 supports network training using the BF16 data type. In addition, the BF16 data type can be configured for hybrid precision training to customize the parameter type.
Note: Currently, some operators do not support the BF16 type. Operator capabilities will be gradually supplemented in the future. Stay tuned!