MindSpore 1.9 Further Improves Usability and Efficiency
MindSpore 1.9 Further Improves Usability and Efficiency
MindSpore 1.9 has been launched thanks to the constant effort of our community developers. This version includes converged programming capabilities that combine functional programming (FP) and object-oriented programming (OOP) paradigms, performance visualization for large-scale training, and improved efficiency of parallel training performance analysis. MindPandas, an efficient distributed table analysis framework, is also launched with MindSpore 1.9. Now, let's check out the highlights of this update.
Easy-To-Use OOP + FP Improves Usability
MindSpore 1.9 adopts a converged programming paradigm that combines the advantages of FP and OOP. With this version, you can enjoy the usability and low learning costs of OOP and leverage the mathematical expression advantages of FP while avoiding the steep learning curve of pure FP. In terms of framework design, we give equal importance to scientific computing and AI instead of using a core framework with secondary development libraries.
The entire training process is optimized in the following aspects:
Ÿ Network construction: MindSpore 1.9 accommodates your OOP habits and allows you to construct layers as if you were using PyTorch.
Ÿ Forward computation and backpropagation: Functional automated differential is applied in accordance with mathematical semantics. The forward computation process can be constructed as a function and transformed into a grad function, which is then used to obtain the gradient corresponding to the weight.
Ÿ Support of pure FP: You can construct scientific computing algorithms like those in Jax.
The following figure shows the comparison between user scripts before and after the optimization:
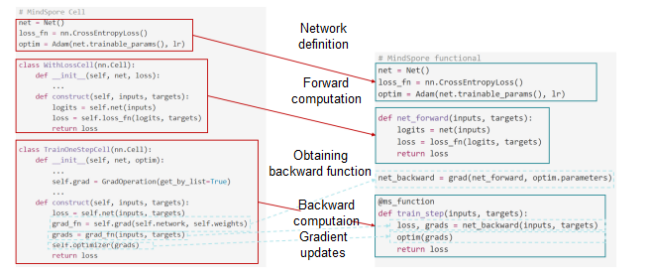
Scripts before and after the optimization
The optimized approach is more in line with mathematical semantics. It eliminates the need for secondary framework development and makes the code more concise and easy to understand, all while increasing the framework's usability and minimizing the complexity of getting started.
For more, visit https://www.mindspore.cn/tutorials/en/master/beginner/quick_start.html.
MindPandas, an Efficient Distributed Table Analysis Framework
Data processing and analysis are important parts of the deep learning process, where tables are commonly used for data representation. Pandas, a popular data analysis framework in the industry, provides simple and rich interfaces but performs poorly when processing massive amounts of data because it can only run as a single thread. Furthermore, due to memory constraints, Pandas cannot handle data volumes larger than the local memory; therefore, in practice, for different data volumes, data analysts often switch between different frameworks, incurring the cost of learning multiple languages and managing multiple frameworks. At the same time, because data analysis frameworks are separate from AI frameworks like MindSpore, data must be stored on the drive and formatted before being processed, which has a significant impact on efficiency.
MindPandas, developed to overcome the weak points of Pandas, is a data analysis platform that supports Pandas APIs and provides distributed processing capabilities. It is dedicated to offering high performance and large-volume data processing capabilities, as well as smooth integration with training. MindPandas enables MindSpore to support the entire AI model training process.
Ÿ Easy-to-use data processing APIs
MindPandas is compatible with Pandas APIs. You only need to slightly modify the script to switch to MindPandas, like this:

MindPandas supports more than 100 distributed APIs, including the DataFrame and Series APIs, with more on the way.
Ÿ Efficient distributed data processing
By slicing the table data, MindPandas implements parallel computation of data slices to fully utilize the computing power of multiple CPU cores, thus achieving a multiplicative increase in computing performance. The slicing details are hidden from the users for simple user operations. For example, the parallel computing process of the DataFrame.sum API is as follows:
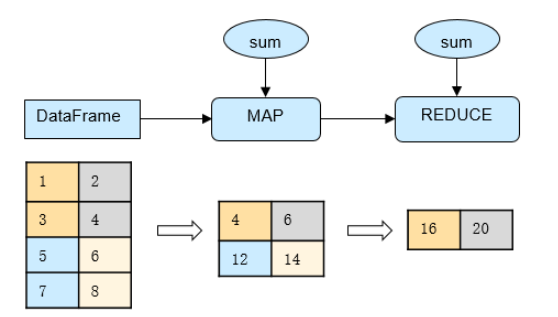
Parallel computing process of DataFrame.sum
When the data to be processed cannot be stored in the memory of a single machine, MindPandas provides a scalable distribution capability that leverages the shared memory of multiple machines, removing the barrier that hinders Pandas from handling large amounts of data. In addition, MindPandas supports one-time development for single-node and distributed execution, reducing the cost of use.
Ÿ Unified and efficient data transfer
Users do not need to be concerned with specific data formats. The calculation results of MindPandas do not require saving to drives. Through shared memory, data can be directly provided to MindSpore in a unified format for training, bridging the gap between the data analysis framework and the training framework.
Ÿ Performance comparison
MindPandas and Pandas each process 4 GiB of data on a 56-core Linux machine using the default number of slices (which can be configured via set_partition_shape). Some MindPandas APIs perform more than 10 times better than their Pandas counterparts.
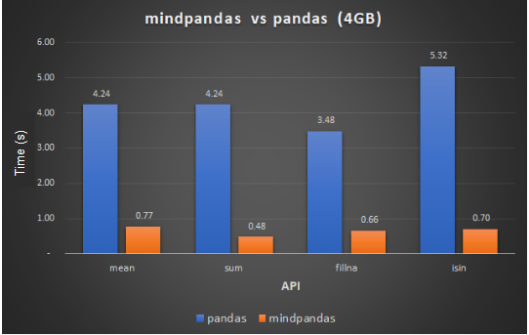
API performance comparison
As the volume of data increases, the performance benefits of MindPandas become more evident.
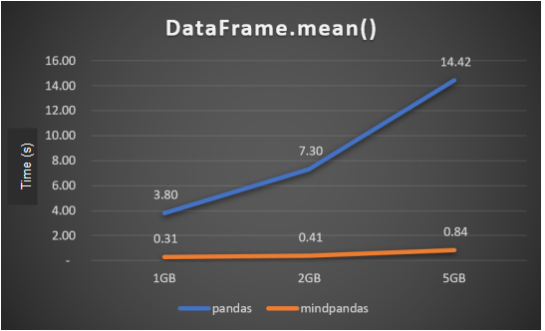
API performance with different data volumes
The tests were conducted using the default number of concurrencies. You can change the configuration as required to achieve even better performance.
Repository: https://gitee.com/mindspore/mindpandas
Performance Visualization for Large-Scale AI Training
With the exponential growth in the number of neural network model parameters and dataset size, the cluster size required for training is getting larger and larger, and the choice and combination of parallel strategies for multiple devices are diverse, making it difficult to locate the root causes of performance bottlenecks. MindSpore collaborates with Professor Chen Wei's team at Zhejiang University to create the large-scale AI training performance visualization module, helping improve the efficiency of parallel cluster training performance analysis.
For details, visit https://www.mindspore.cn/mindinsight/docs/en/master/performance_profiling_of_cluster.html.
Ÿ Parallel training strategy analysis
In MindSpore 1.9, we introduced a computational-communication bipartite graph scheme. All communication operators in the computational graph are extracted to the top layer of the canvas. The computational graph also displays information about the parallel strategies. You can clearly observe the execution sequence of the parallel strategy-related operators and the computational graph and thus confirm the rationality of the communication operators. The figure below shows the parallel training of a Pangu model using K-level clusters, where the green ellipses represent redistribution operators and the different branches of the computation-communication nodes show the corresponding parallel strategies.
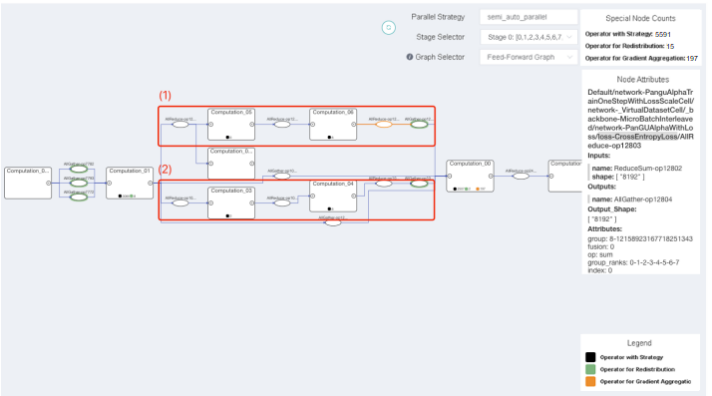
Parallel training strategy analysis of a Pangu model
In the next figure, the namespace nodes are expanded. By combining the nodes and the strategy matrix, you can see the shard method of a specific operator. According to the node attributes, the Load-op2 input tensor (parameter) is not sharded, while the StridedSlice-op10856 input tensor (data) is sharded into two at the first dimension. As stated in PengCheng·PanGu Model Network Multi-Dimension Hybrid Parallel Analysis, when the word list range is large, it is advised to choose a model parallel strategy for word_embedding. In this example, data is split. The training performance can be improved by using model parallel.
Reference: https://mindspore.cn/tutorials/experts/en/master/parallel/pangu_alpha.html
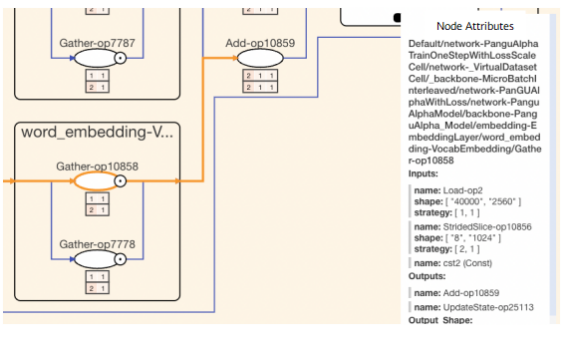
Example of the operator strategy matrix
Ÿ Cluster performance analysis
MindSpore 1.9 combines performance data with computational graph parallel strategies to provide a performance visual analysis link that includes analysis at multiple levels, including the cluster, card, and operator levels, greatly assisting you in identifying common problems in the parallel training process of large models and understanding the parallel training execution process.
For example, when tuning the parallel training of a ResNet-50 model running on 4 cards, devices 2 and 3 spend a long time communicating. Select the two devices in the communication graph. In the displayed adjacency matrix, you can see that the abnormal communication node allReduce_237_245 occupies most of the bandwidth of this communication link.
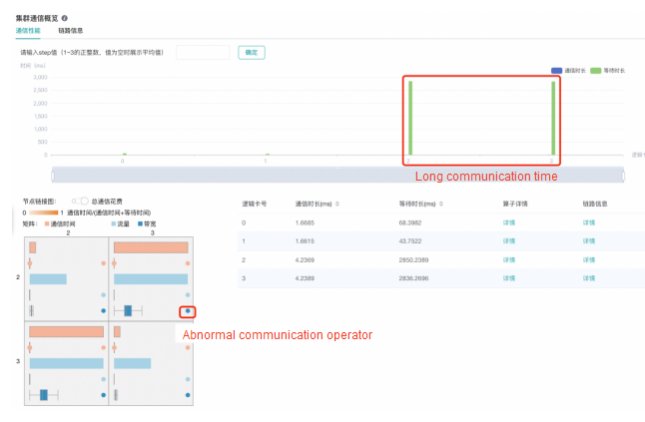
Cluster communication component
In the Marey view of the Execution Overview tab, devices 2 and 3 are in stage1. You can find communication operators that take a long time communicating in areas where the operator density is high. This could be the result of the unreasonable setting of the communication operator fusion or shard strategy. You can try to modify the all_reduce_fusion_config parameter to optimize the performance. In the parallel strategy view, you can see that the pipeline parallel strategy is used for training. The pipeline parallel bubble can be further analyzed based on the minimap and Marey view below.
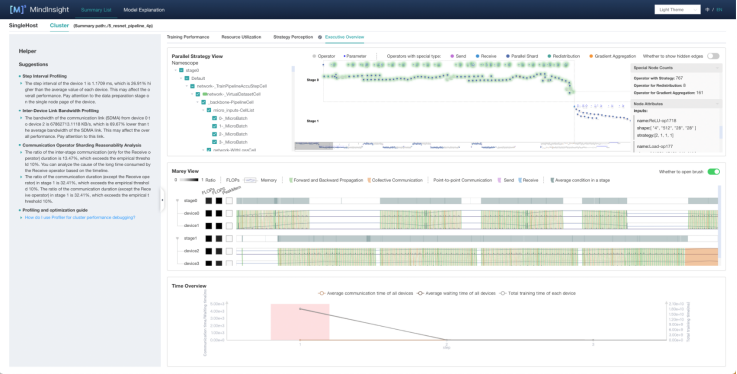
Execution Overview tab