MindSpore 1.8: Implements High-Performance Training while Lowering Deployment Threshold with Rich Algorithm Sets and Suites
MindSpore 1.8: Implements High-Performance Training while Lowering Deployment Threshold with Rich Algorithm Sets and Suites
August 16, 2022
New Version Release
After two months of continuous efforts, MindSpore 1.8 has been released.
In this version,
MindSpore Golden Stick is released to provide various model compression algorithms.
The MindSpore Transformer suite for training open source foundation models and the MindSpore Recommender suite for recommendation network training are provided, so as to help developers implement high-performance model training.
The custom operator capability is continuously upgraded to unify operator expressions on multiple platforms.
Image processing APIs are unified, and the advanced Model.fit API and the EarlyStopping function are provided, improving API usability.
Functional APIs are added to more than 180 operators, which support the NPU, GPU, and CPU platforms for developers to use.

Video link
Here is a detailed look at the key features of MindSpore 1.8.
1. MindSpore Golden Stick
Lowering the threshold for AI deployment on devices
MindSpore Golden Stick is an algorithm set for model compression. Developed by Huawei Noah's Ark Lab and MindSpore team, it provides various model compression algorithms, such as pruning and quantization, to reduce the number of model parameters and lower the threshold for deploying models on devices.
In addition, a set of easy-to-use algorithm APIs is provided for developers to reduce the application cost of the model compression algorithms.
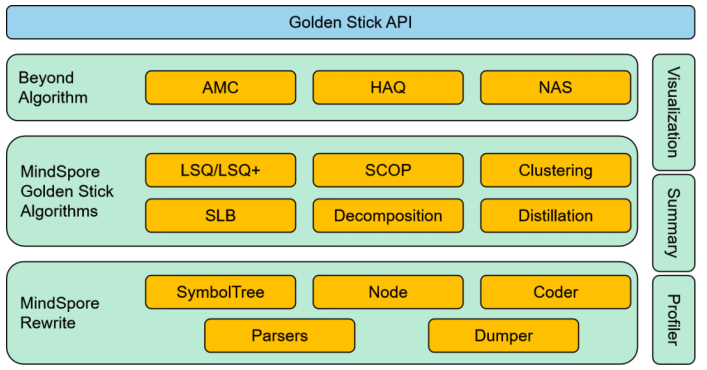
MindSpore Golden Stick architecture
1.1 Unified Algorithm APIs and Image Modification Capability
There are various types of model compression algorithms, and applications of different algorithms vary a lot, which increases learning costs of the algorithms. MindSpore Golden Stick streamlines and abstracts the algorithm application process and provides a set of unified algorithm APIs to minimize the learning cost of algorithm applications. Based on different algorithms, it facilitates the exploration of high-level technologies such as automatic model compression.
In addition, MindSpore Golden Stick supports modifying front-end networks through interfaces. Based on this capability, algorithm developers can formulate common image modification rules to implement algorithm logic instead of specifying them for different networks, improving algorithm development efficiency.
1.2 Pruning Algorithm: SCOP[1] Reducing Model Power Consumption by 50%
A structured pruning algorithm provided by MindSpore Golden Stick is Scientific Control for Reliable Neural Network Pruning (SCOP) developed by Huawei Noah's Ark Lab. Driven by data and with a comparison experiment, it introduces control features to reduce the interference of irrelevant factors to the pruning process to improve the reliability of the pruning result.
SCOP is applied to the ResNet-50 model, which uses the CIFAR-10 dataset for evaluation. The following table lists the experiment results. When the pruning rate is 45%, the precision loss is within 0.5%, and the number of model parameters decreases by more than 50%, the deployment power consumption is reduced by more than 50% and the inference performance is doubled.
Results of SCOP pruning algorithm for ResNet-50 CIFAR-10 dataset
Model
Pruning Rate
Parameters
Accuracy
ResNet-50
-
24 M
93.2%
ResNet-50 with SCOP pruning
45%
11 M
92.7%
1.3 Quantization Algorithm: SLB[2] Compressing Models to 1/8 – 1/32
A quantization algorithm provided by MindSpore Golden Stick is Searching for low-bit weights (SLB) developed by Huawei Noah's Ark Lab.
For low-bit network quantization, there are fewer effective solutions for quantizing the network weight. Therefore, the network quantization may be implemented through weight search, that is, the quantization process is converted into a weight search process. Compared with the traditional quantization algorithm, this algorithm avoids the inaccurate gradient updating process, improves accuracy, and has more advantages in very low bit quantization.
We have performed a simple experiment on the SLB algorithm and the result is shown as follows. In the current task, the model size is reduced to 1/8 of the full-precision model after 4-bit weight quantization without compromising the top 1 accuracy (the precision loss of 1-bit weight quantization is within 0.6%). In this case, the compression effect is increased by 32 times.
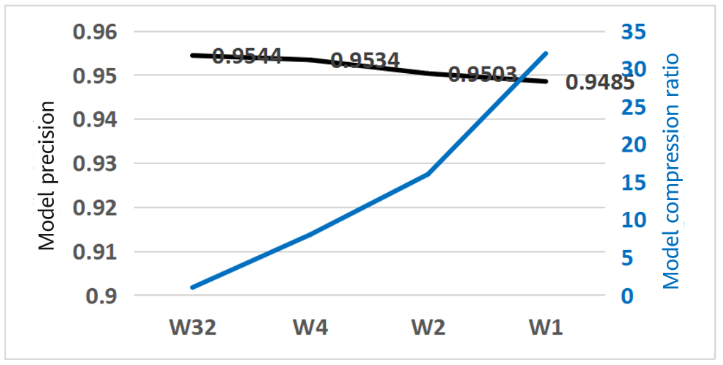
The SLB weight quantization algorithm is used to quantize the CIFAR-10 dataset result of ResNet-18, in which:
· W32 indicates the full-precision model.
· W4, W2, and W1 correspond to the 4-bit, 2-bit, and 1-bit weight quantization models, respectively.
2. High-performance Foundation Model Training Suite
MindSpore Transformer
Transformer has been widely used in various fields of deep learning. To utilize the robust parallel capabilities and high-performance optimization features of MindSpore and enable developers with a quick start of Transformer network training, MindSpore Transformer is open-sourced for transformer network as a training and inference suite.
The suite provides training capabilities for basic models such as GPT, T5, and ViT on typical networks, and you can implement high-performance parallel model training based on the rich parallel training capabilities of MindSpore. Experiments show that MindSpore outperforms Megatron by more than 18% under the same hardware conditions.
2.1 Multi-dimensional Hybrid Parallelism and Optimization for Graph Kernel Fusion
MindSpore Transformer uses the following technologies:
(1) Multi-dimensional hybrid parallelism, including optimizer parallelism and multi-copy parallelism: The training performance of the network can be effectively improved by cutting redundant parameters in the data parallel dimension and optimizing concurrent communication and computing.
(2) Graph kernel fusion optimization: The graph kernel fusion function of MindSpore can automatically fuse operators and optimize compilation, improving the memory efficiency and model training speed. In the model or data/model parallel modes of MindSpore Transformer, graph kernel fusion has been widely used and achieved remarkable results.
2.2 Performance Comparison
We test the 10-billion-scale GPT (hiddensize = 5120, num_layers = 35, and num_heads = 40) performance on the 8-socket, 16-socket, and 32-socket A100 clusters. The number of parallel channels is set to 8, parallel data channels to 1, 2, and 4, and global batches to 1024.
For Megatron, set Micro Batch Size to 2 (the upper limit). For MindSpore, set Micro Batch Size to 8 (the upper limit). The memory utilization of MindSpore is higher than that of Megatron, indicating a larger batch can be trained.
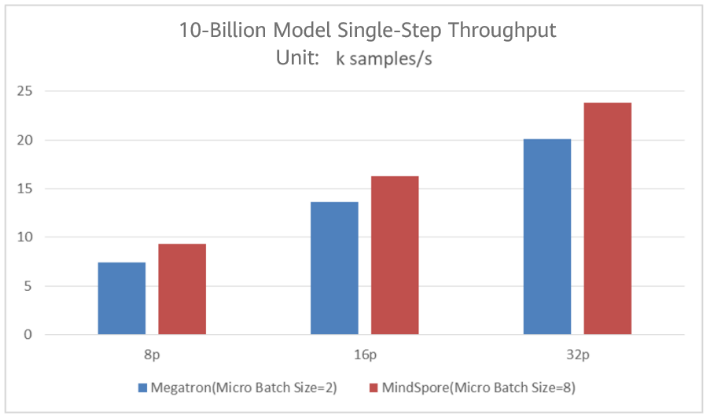
Throughput Comparison
As shown in the figure,
· The maximum throughput of 8P Megatron is 7,400 samples/s, and that of MindSpore is 9,300 samples/s, a 25% increase by Megatron.
· The maximum throughput of 16P Megatron is 13,600 samples/s, and that of MindSpore is 16,900 samples/s, a 24% increase by Megatron.
· The maximum throughput of 32P Megatron is 20,100 samples/s, and that of MindSpore is 23,800 samples/s, an 18% increase by Megatron.
3. High-performance Suite for Recommendation Network Training
MindSpore Recommender
Multiple click-through rate (CTR) models are deployed in the recommendation system. To improve the CTR, the deep CTR model needs to be trained efficiently. The training performance of the recommendation network is one of the important factors for real-time performance of the model.
MindSpore 1.8 integrates MindSpore Recommender, the suite for training recommendation network foundation models. With basic capabilities on MindSpore, including automatic parallelism, graph kernel fusion, and distributed embedding cache, it achieves high training performance.
The suite provides an end-to-end training process for mainstream recommendation network models (such as Wide&Deep), including dataset preprocessing, model training, and benchmark, providing developers with one-stop training capabilities.
3.1 Architecture of Recommendation Foundation Model Training
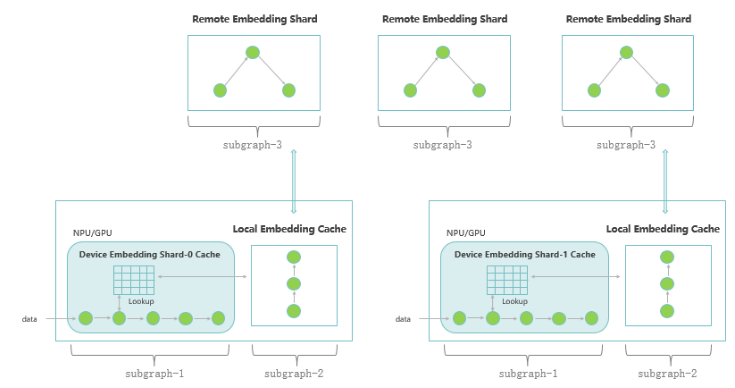
Technical Architecture
(1) Automatic parallelism: uses model parallelism to implement automatic segmentation of multiple cards for sparse computing (Embedding), and uses data parallelism to concurrently execute dense computing and collective communication, effectively improving the overall training performance.
(2) Distributed embedding cache: uses multi-level embedding cache and computing pipeline design to store large-scale feature vectors and achieve high performance in training.
(3) Distributed computing graph: uses distributed computing graph segmentation and execution, to implement distributed storage and high-performance local computing of large-scale feature vectors.
3.2 Unified Algorithm APIs and Image Modification Capability
The following figure shows the Wide&Deep model training based on the GPU V100 cluster (batch_size = 16000, and vocab_size = 5860000)
The throughput of MindSpore on a single server with eight GPUs is 35% higher than that of HugeCTR.
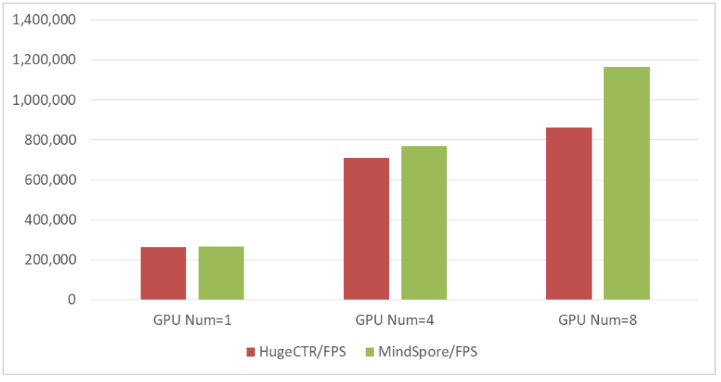
Wide&Deep training throughput
4. Continuous Custom Operator Upgrade
Unified expression for efficiently adding operators
MindSpore 1.6 released at the beginning of this year integrates Custom, the unified operator development API for multiple platforms, which can quickly define and utilize different types of custom operators.
To further improve the usability of custom operators, MindSpore 1.8 provides a unified MindSpore Hybrid DSL expression, which supports unified operator development expression on multiple platforms, including Ascend, GPU, and CPU. Quick verification and real-time compilation are supported on all platforms.
In addition, version 1.8 provides a new custom operator mode for accessing the Julia operator, making it the industry's first AI framework that supports the Julia language.
4.1 Unified Cross-Platform MindSpore Hybrid DSL Expression
MindSpore Hybrid DSL allows operators to be developed with a unified expression on different platforms. Operators can be used at all backends once developed. In addition, when a developed operator is connected to the custom API, it can be compiled and run in hybrid mode, or interpreted and run in pyfunc mode to facilitate quick verification.
In addition, using new scheduling primitives provided by MindSpore Hybrid DSL, hybrid custom operators can enable the domain-specific architecture (DSA) scheduler of polyhedral models at the Ascend backend to implement manual and automatic operator scheduling and assist code generation, accelerating scientific computing tasks on the backend for developers.
4.2 Industry's First AI Framework Supporting Julia
Julia is a high-level general-purpose programming language that is both efficient and easy to use. It was initially designed for scientific computing. Due to its efficiency and usability, Julia has got wider recognition in recent years and gradually becomes a mainstream.
MindSpore 1.8 integrates the Julia mode in the Custom API for operator development to combine Julia-based operators with Ascend-based models.
Developers can use Julia operators to accelerate computing or use the Julia ecosystem to efficiently develop operators. In this way, the Julia operator can be enabled in scenarios such as model porting, quick verification, and model acceleration, bringing benefits to computing in MindSpore-based models.
5. Unified Image Processing APIs of MindSpore Data
Improving API usability
On MindSpore 1.8, the MindSpore Data module redesigns and reconstructs image data preprocessing operations. The original c_transforms and py_transforms operations are combined into a unified interface: transforms. In addition, various data processing operators are normalized and combined to avoid too many conversions of mixed operators. And the operator output format is automatically converted based on the context to be concise and usable, while reserving the choice of manually selecting operator policies for senior developers.
In order to help you build your own algorithms related to variational quantum, we have open-sourced more simulator APIs.
5.1 Implementation
The same functions of c_transforms and py_transforms are combined into one API. Two bottom-layer implementations are reserved internally. During execution, layer C is preferentially used to ensure high efficiency. Different functions are reserved at the low level of layers C and Python. Only one execution mode is available.
5.2 Summary After Implementation
(1) Package import is unified, as shown in the following figure.

(2) Data processing APIs are unified, as shown in the following figure.
(3) The following figure shows an example of the running mode.

6. Support Simultaneous Inferring and Training and EarlyStopping
6.1 Advanced Model.fit APIs
In early version, training and inference are performed respectively through the Model.train and Model.eval APIs. However, to monitor model effects during training, you need to view the evaluation indicators of the validation dataset through manual operations.
MindSpore 1.8 provides the Model.fit high-level API and encapsulates Model.train and Model.eval to simplify the development process while retaining the original functions. Developers only need to pass the corresponding parameters and use one line of code to implement automatic training and inference.
6.2 EarlyStopping and ReduceLROnPlateau
To monitor the model status and parameter changes in real time, and implement customized operations during training, MindSpore provides the callback mechanism. MindSpore 1.8 adds the EarlyStopping and ReduceLROnPlateau callback functions, which can be used in Model.train and Model.fit to implement epoch-level verification of specified indicators.
When the indicators show performance deterioration and the values fall below the tolerable threshold, or the waiting time outnumbers the tolerable epochs, EarlyStopping stops the training process and ReduceLROnPlateau changes the learning rate based on the attenuation rule specified by the developer.
For details, click here or here
7. Adjustable Network Constant Input
Improving compilation efficiency
In the current graph compilation mechanism, the input of all top-level networks (except tensors) is regarded as constant values, such as scalars, tuples, lists, and dicts. Constant values cannot be derived and are folded by constants in the compilation optimization phase.
In addition, when the network input is tuple[Tensor], list[Tensor], or dict[Tensor], even if the shape and dtype of the tensor do not change, the network will be recompiled for multiple times. When a network is continuously called to obtain a result, the input is processed as a constant value and the specific value of the tensor cannot be ignored. As a result, the training efficiency is reduced.
To solve the problem, the mutable API is added to MindSpore 1.8 for setting the constant input of the network to variable. That is, the input is regarded as a variable like a tensor. In this way, the gradient can be calculated and the network can be prevented from being compiled repeatedly. The API is user-friendly: use the mutable interface to encapsulate the network input when passing parameters, as shown in the following figure.
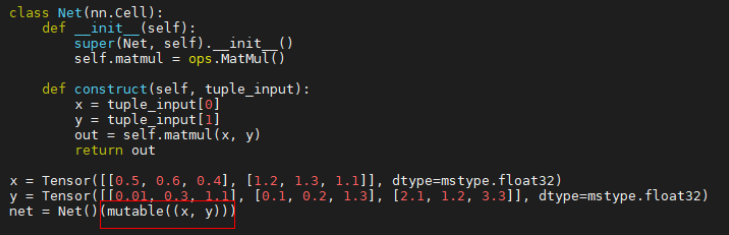
Encapsulating the input of the tuple[Tensor] type
8. MindSpore Reinforcement
High-performance distributed training and native Monte Carlo Tree Search algorithms
8.1 Flexible High-performance Distributed Training with Dataflow Fragments
The distributed reinforcement learning framework mainly uses Python functions to implement algorithms. Despite intuitive programming APIs, it is challenging to implement multi-machine parallelism and heterogeneous acceleration.
MindSpore Reinforcement v0.5.0 provides a distributed policy (DP) based on Dataflow Fragment. It can divide the deep reinforcement learning algorithm into multiple data flow segments and map them to heterogeneous devices for execution. The same algorithm can be deployed on a single device with multiple GPUs or multiple devices with multiple GPUs based on the DP.
The following figure shows the Dataflow Fragment–based DP and the corresponding training acceleration effect. When deployed on multiple devices with multiple GPUs, the algorithm speeds up greatly.
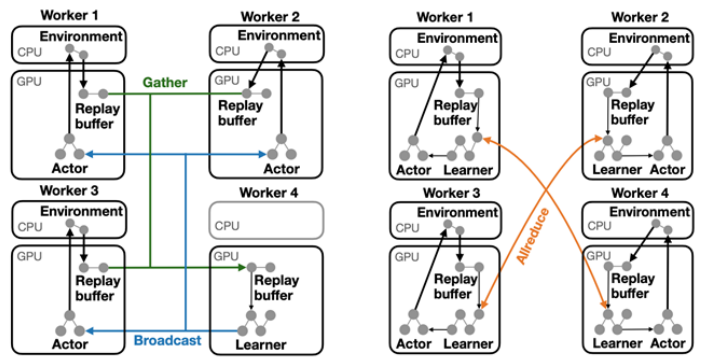
Two DPs
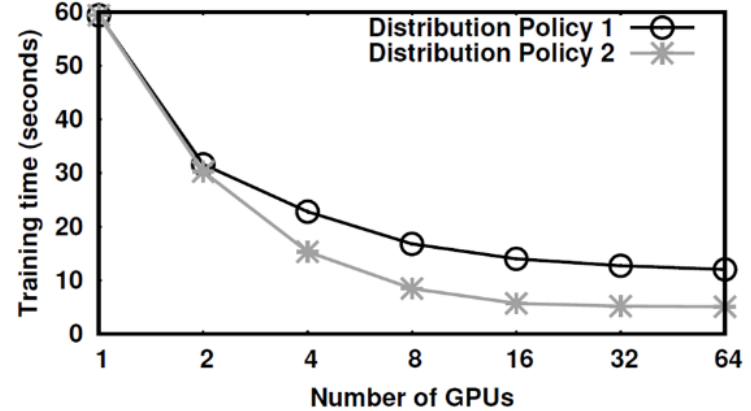
Training time under different DPs
8.2 Monte Carlo Tree Search
Monte Carlo Tree Search (MCTS) is a decision search algorithm. After the success of MCTS-based reinforcement learning algorithms (such as AlphaGo), MCTS is increasingly used in reinforcement learning algorithms.

Pseudo-code of the MSTC algorithm
MindSpore Reinforcement v0.5.0 provides a common extensible MCTS algorithm. Developers can either use Python to directly invoke the embedded MCTS algorithm for the reinforcement learning algorithm, or customize logic through extension. The framework automatically compiles the algorithm into a computation graph for efficient execution.
References
[1] Tang, Yehui, et al. "Scop: Scientific control for reliable neural network pruning." NeurIPS 2020: 10936-10947.
[2] Yang Z, Wang Y, Han K, et al. Searching for low-bit weights in quantized neural networks. NIPS, 2020.