MindSpore 1.3: Extend AI to Wherever You Need It
MindSpore 1.3: Extend AI to Wherever You Need It

As midsummer approaches, we are thrilled to present the new MindSpore 1.3. This version is loaded with MindSpore Federated, integrates key features that have been enabling the PanGu model to process billions of parameters, and brings other new features for more hardware types, such as the optimization for inference performance, graph kernel fusion, and easy deployment. We are passionate about providing new features for AI developers. Now, let's have a quick look at the key features of MindSpore 1.3.
Federated learning is an encrypted distributed machine learning technology that allows participants to train an AI model together without sharing local data, thereby addressing issues such as data privacy and data silos. MindSpore Federated is suitable for the horizontal federated learning scenario where a large number of participants exist.
In the device-cloud scenario, the participants are mobile or IoT devices. These devices can be unreliable and bring challenges such as device heterogeneity, poor communication, privacy risks, and missing labels. The loosely coupled cluster processing mode, time-limited communication module, and fault-tolerant secure aggregation module of MindSpore Federated allow you to run federated learning tasks at any time as long as some clients are available. MindSpore Federated also addresses the long tail effect induced by device heterogeneity. These features significantly improve the learning efficiency.
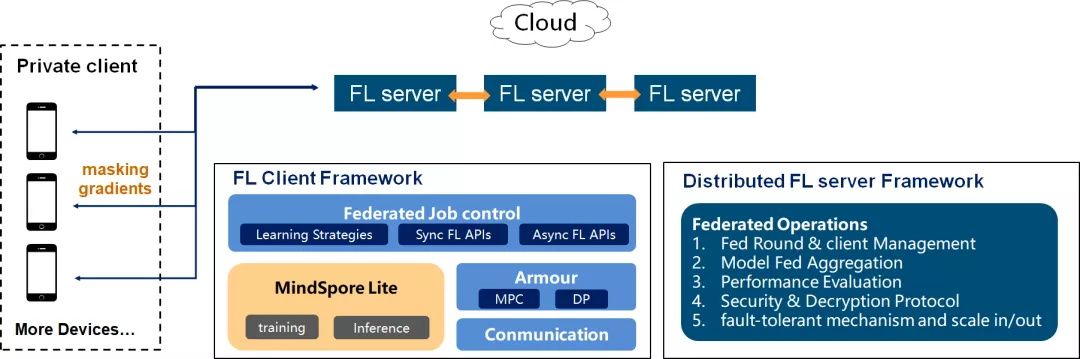
Built on MindSpore's unified device-edge-cloud all-scenario infrastructure, MindSpore Federated will provide more personalized decision-making based on user information while protecting user privacy.
Key Features of PanGu Going Open Source
The PanGu model by Peng Cheng Laboratory is the world's largest pre-trained Chinese language model. It was ranked first by the Chinese Language Understanding Evaluation Benchmark on April 23, 2021, and its key features are now open source in MindSpore 1.3.
1. Distributed Inference and Online Deployment
Using operator-level and pipeline model parallelism, MindSpore deploys models with a large number of inference parameters to multiple cards in a distributed manner.
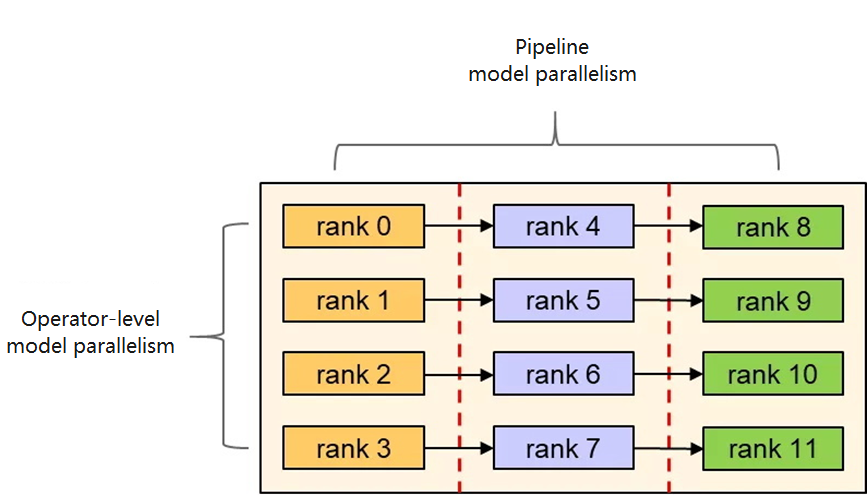
MindSpore Serving is a service module that assists the deployment of online inference services. Based on the model parallelism strategy, MindSpore Serving divides the model into multiple small graphs and deploys the graphs to each device accordingly.
2. Incremental Inference (State Reuse)
For an autoregressive language model, the length of the inference input increases as new words are generated. If such a model is executed in dynamic graph mode, the shape of each operator in the graph changes with each iteration, making it impossible to reuse the cached operator build information. As a result, performance is affected.
In MindSpore 1.3, we modified the inference script to implement the incremental inference function, a process that consists of two phases. In the first phase, the model takes a full-length input, which is a variable-length input padded to a fixed length, and saves the input state. In the second phase, the model takes the token generated in the previous step as an input, uses the token and the saved state for incremental inference, generates a new token, and updates the state. Such incremental inference is not equivalent to full inference, but has similar precision.
During incremental inference, the first phase is executed only once, while the second phase is executed multiple times. The overall performance of incremental inference is significantly higher than that of full inference.
MindSpore Serving supports the deployment of an incremental inference model in single-device and distributed modes.
MindSpore Lite Device-Cloud Training
To protect user privacy, the amount of data uploaded to the cloud is limited. Training on the user side is gradually becoming a trend, meanwhile device-cloud training can also fully leverage compute resources on the devices to further accelerate training. Currently, MindSpore Lite supports incremental training of models exported from MindSpore to achieve seamless switchover between device and cloud training. However, the hardware resource limitations on the devices pose another challenge to incremental training: how to perform training without affecting user experience?
MindSpore Lite uses methods such as training memory reuse, virtual batch, mixed precision training, online fusion, and quantization to reduce memory usage on the devices. Furthermore, MindSpore Federated allows the cloud to read and write weight information on the devices through transmission secured by differential privacy. This further strengthens data security during device-cloud training.

Debugger Usability Improvement: Graph-Code Debugging and Training Replay
MindSpore Debugger is a powerful debugging tool for training in graph mode, which provides various check rules for quick identification of common precision problems. To streamline script debugging in graph mode, we are launching two new features in MindSpore 1.3: graph-code debugging and training replay.
Script code errors have a significant impact on model accuracy. With the graph-code debugging feature of Debugger, code can be automatically associated with operator nodes in a graph, allowing users to easily pinpoint the corresponding code snippet based on the node or vice versa. By applying Debugger, algorithm engineers can consult the code logic and locate the accuracy problems efficiently.
The training replay function is available in offline debugging mode. In most cases, model accuracy problems are analyzed through online debugging while training is in progress, which is intuitive and requires no additional storage space. However, online debugging lacks a replay ability, which means that you have to repeatedly run training to debug past iterations, wasting time and hardware resources. With offline debugging, Debugger uses the dumped data on the disk to replay training without consuming valuable computing power, allowing you to analyze accuracy problems after the training is complete.
By simply feeding the dumped data into MindSpore, you can perform offline debugging to analyze and locate accuracy problems in the parallel training scenario (single-server multi-device). The check rules provided by Debugger, referred to as watchpoints, are also applicable in this scenario for monitoring training exceptions, such as vanishing gradients and activation function saturation.
Inference Performance Optimization for x86-64 PCs
To better support the inference on PCs of the x86_64 architecture, MindSpore 1.3 allows you to divide the blocks based on the dynamics of different shapes during convolution. Hardware resources such as registers are fully utilized to achieve optimal performance, and the inference latency is cut by 10% to 75% compared with the previous version.
More Inference Performance Optimization
An increasing amount of computing workload is a result of ever-larger datasets and networks. Moreover, interactive inference tasks require even lower latency, meaning more and more deep neural network inference tasks are deployed to AI acceleration devices, such as GPUs. Fortunately, MindSpore 1.3 provides more performance optimization to support these scenarios.
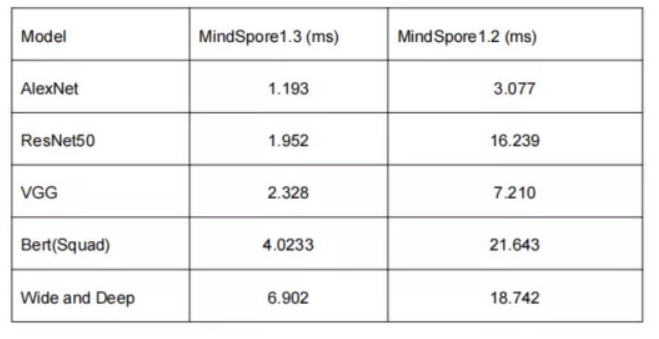
We tested how some typical networks run in ModelZoo using MindSpore 1.2 and MindSpore 1.3 and collected statistics on the average execution time of the inference requests. The results show up to an 8-fold inference performance boost.
Graph Kernel Fusion Accelerating Network Training
As a key technology of MindSpore, graph kernel fusion improves the network execution performance through the collaborative optimization of layer fusion and operator generation. In earlier versions of MindSpore, we enabled the basic capabilities of NPU/GPU-based graph kernel fusion and achieved satisfactory results on the benchmark networks. In MindSpore 1.3, the generalization capability of GPU-based graph kernel fusion is further enhanced. We tested the new version on more than 40 mainstream networks in ModelZoo and observed an average performance improvement of 89%.
In addition, MindSpore 1.3 allows you to control the function using an environment variable, improving performance provided by graph kernel fusion without any intrusive modification to the network code:
export MS_GRAPH_KERNEL_FLAGS="–opt_level=2"
MindSpore is an all-scenario AI framework aiming to provide easy development, efficient execution, and user-friendly design. It supports diverse device-edge-cloud scenarios and provides in-depth optimization for Ascend hardware platforms. MindSpore has been widely used in various industries, including scientific research, finance, and healthcare. MindSpore is committed to building an open source community for developers worldwide and a prosperous open source ecosystem of AI hardware/software applications.
