MindSpore New Features: Powerful In-depth Scientific Computing
MindSpore New Features: Powerful In-depth Scientific Computing
This blog introduces a range of new features of MindSpore 1.5, which include the scientific computing kits MindScience, affinity algorithm library MindSpore Boost, Mixture of Expert (MoE) and heterogeneous parallelism, cluster optimization for large-scale distributed training, optimized control flow, and new open mechanisms.
I. MindScience
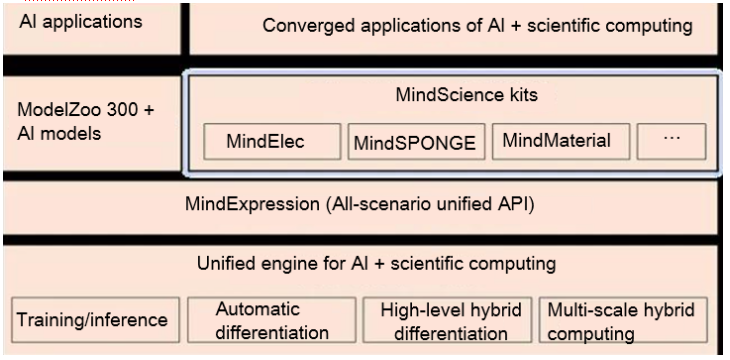
Currently, combined computing power is fueling the development of cross-domain applications, of which AI is at the forefront. MindSpore innovates multi-scale hybrid computing and high-level hybrid differentiation to upgrade its original AI computing engine to a unified engine for AI + scientific computing, accelerating the unified convergence. Based on this new feature, we plan to build MindScience kits for eight scientific computing industries. These kits include industry-leading datasets, basic models, preset high-precision models, and pre- and post-processing tools, to fuel application development in scientific computing. Currently, the MindElec kit and the MindSPONGE kit, for the electronic information industry and life science industry, respectively, have been launched, boosting the electromagnetic simulation performance 10-fold and the simulation efficiency of biopharmaceutical compounds by 50%.
For details about MindScience, visit https://www.mindspore.cn/mindscience/en.
1. MindElec v0.1
MindElec provides functions such as multimodality data transformation, high-dimensional data encoding, multi-frequency signaling network optimization, and basic model library, and supports time-domain and frequency-domain electromagnetic simulation. This is calculated as follows: Use the multimodality data transformation function to convert complex CAD structures into AI-affinity tensor data, compress the high-dimensional tensor data through encoding, so that the storage and computing workload are reduced, and then train the compressed tensor data in the innovative AI electromagnetic simulation basic model. During training, the multi-frequency signaling network optimization is performed to improve model accuracy.
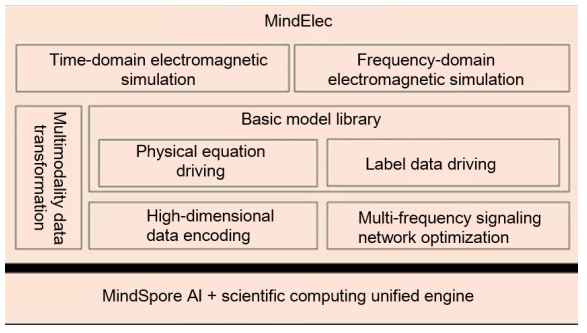
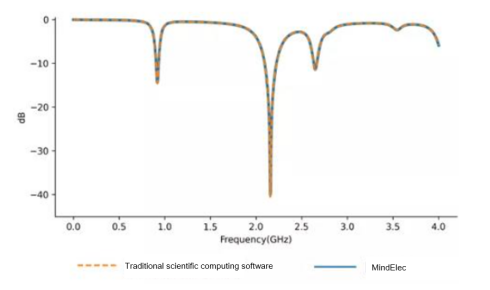
MindElec v0.1 has improved the performance by 10 times in mobile electromagnetic simulation and achieved simulation precision comparable to conventional scientific computing.
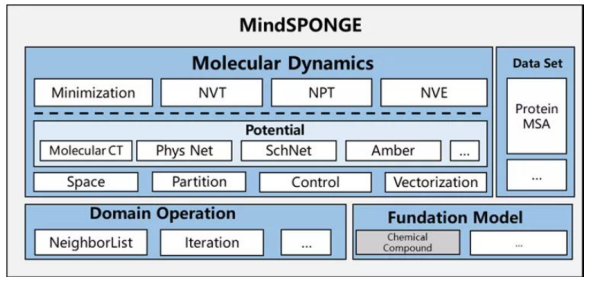
2. MindSPONGE v0.1
MindSPONGE is a molecular simulation library developed in cooperation with the Gao Yiqin research group of PKU & Shenzhen Bay Laboratory and the Huawei MindSpore team, and is loaded with high-performance, modularization, and other features. MindSPONGE v0.1 supports the two commonly used simulation ensembles NVT and NPT, supporting such molecular simulation case as the COVID-19 Delta variant simulation. MindSPONGE also integrates AI and conventional molecular simulation, supporting AI neural networks such as Molecular CT and SchNet. It is an ideal fit for potential energy functions. For example, the AI force field simulates the Claisen rearrangement for effective dynamic AI molecular simulation, showing the conversion between 7-membered rings and 3-membered rings.
MindSPONGE has made great strides in biopharmacy. The discovery of antibiotics has helped prolong human life, but bacteria resistance has increased, making the demand for cathelicidins, which are next-generation antibiotics that could effectively kill drug-resistant pathogens, even higher. The Peng Cheng-Shennong platform, created by the MindSpore team and Peng Cheng Laboratory, is capable of generating amino acid sequence by pre-training and fine-tuning the PCL-L model, which may significantly accelerate the discovery of new cathelicidins.
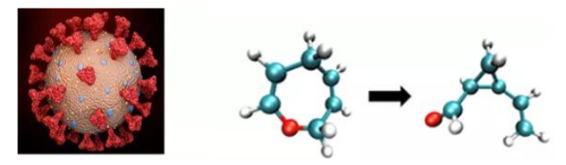
(coronavirus) (Claisen rearrangement)
II. MoE and heterogeneous parallelism
The MindSpore team and the Chinese Academy of Sciences released the world's first three-modal model - Zidong Taichu, which is used for automatic segmentation of super-resolution images in the remote sensing field.
1. MoE and its parallel architecture
Most fundamental models are created based on the transformer architecture, of which MoE has played a major part in improving. As illustrated in the left figure, each layer in the transformer architecture consists of two basic structures: Attention and FeedForward (FFN). In the expert-parallel MoE structure, FFN is regarded as an expert. It enters through a router that is responsible for distributing tokens to experts through multiple routing policies (such as top and top 2), and its output is weighted summation.
MoE is the base of trillion-parameter fundamental models, and several tasks have demonstrated its effectiveness. MindSpore 1.5 adopts the MoE structure and expert parallel mechanism, which allows multiple "experts" to be concurrently executed on multiple devices. From the figure on the right, we can see that the router (data parallelism) uses the AllToAll operator to allocate tokens to experts on each device for calculation, and then uses the AllToAll operator to aggregate the results.
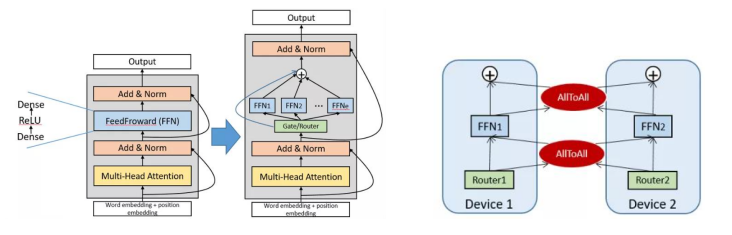
For details about the code implementation of MindSpore MoE, visit https://gitee.com/mindspore/mindspore/tree/r1.5/mindspore/parallel/nn.
2. Heterogeneous parallelism
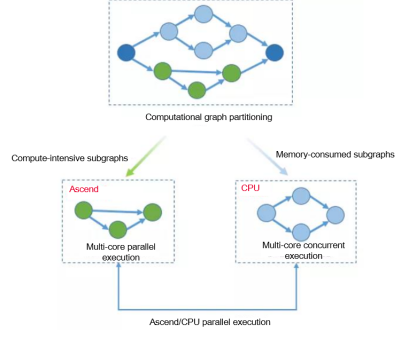
To overcome the memory bottleneck of GPU/NPU devices, the memory of the host can be used, becoming a feasible way to expand fundamental models. During heterogeneous parallel training, a framework is used to collaborate with the training of different subgraphs, fully utilizing heterogeneous hardware features to effectively enlarge the single-server training scale. Specifically, this method partitions operators that consume large memory and are suitable for CPU processing into CPU subgraphs, and compute-intensive operators that consume a small amount of memory into hardware accelerator subgraphs.
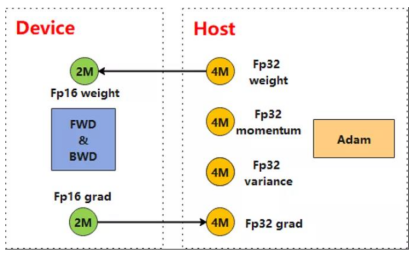
For a large-scale pre-trained model, the main bottleneck is that a large number of parameters cannot be stored into device memory. When processing a large-scale pre-trained network, MindSpore 1.5 can specify an optimizer to the CPU through optimizer heterogeneity to reduce the memory usage of the optimizer status and expand the scale of the model to be trained. In the following figure, the Adam optimizer that is compatible with FP32 is placed on the CPU for computing, cutting the parameter's memory usage by more than 60%.
3. MoE and heterogeneous parallelism enabling the fundamental model on 32 NPUs to be trained
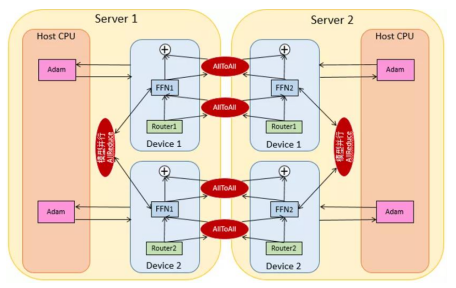
The PCL-L model [1] is designed based on the MoE structure and adapts to the expert parallelism, heterogeneous parallelism, data parallelism, and model parallelism. As shown in the following figure, the optimizer-related status and calculation are stored and performed on CPUs. In the MoE structure, model parallelism and expert parallelism are processed simultaneously. That is, the same expert is allocated to both servers. To be specific, FFN1 on Server 1 is allocated to two devices, so the model parallelism (AllReduce) occurs inside the server. Devices on different servers adopt data parallelism and expert parallelism. Specifically, Device 1 on Server 1 and Device 1 on Server 2, as well as Device 2 on Server 1 and Device 2 on Server 2, run in parallel mode. AllToAll, a collective operation that processes conversion between data parallelism and expert parallelism, occurs between servers.
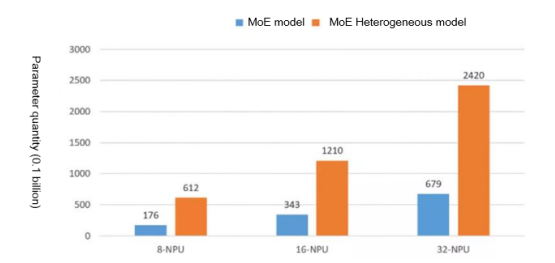
We have successfully tested the effect of optimizer heterogeneity and expert parallelism on the scale of the model to be trained on 8-NPU, 16-NPU, and 32-NPU Ascend devices. The experiment showed that the model scale expanded three times when optimizer heterogeneity was used. 61.2 billion parameters were able to run on 8 NPUs, 121 billion parameters on 16 NPUs, and 242 billion parameters on 32 NPUs.
4.Automatic parallel processing of super-resolution remote images
Super-resolution images are usually very large. For example, the resolution of a remote sensing image is 4 x 30,000 x 30,000, and the size of such an image is about 14 GB. Due to memory limitations, training cannot be performed on a single device. Therefore, multi-server multi-device parallel training is required. In terms of processing large-scale remote sensing images, MindSpore provides the decoding and data augmentation functions. For a single sample with a large size, the framework automatically partitions it into appropriate sizes (for example, H and W dimensions) based on the cluster scale and distributes each part to different compute nodes, to solve the problem of insufficient memory. During training and inference, the network performs a large number of convolution operations on images. After the H and W dimensions of an image are partitioned, some edge feature information may be stored on other nodes for each compute node. The framework automatically identifies the distribution of edge feature information and integrates the information distributed on the adjacent nodes using communication technologies, to ensure that the network execution result is as accurate as possible.
III. MindSpore Boost
End-to-end training is a highly complex process, whereby computing optimization in different AI scenarios needs to be performed based on multiple modules. For MindSpore 1.5, Huawei Central Media Technology Institute and the MindSpore team launched the affinity algorithm library MindSpore Boost 1.0 to provide users with efficient acceleration algorithms in terms of data, network, communication, training policy, and optimizer while maintaining the training accuracy. In addition to the affinity algorithms, simple mode (O1, O2, and O3) is available for encapsulating algorithms. From O1 to O3, the acceleration ratio increases. In this mode, users do not need to understand the algorithm's details, and only need to enable the acceleration switch and select a level when invoking the model training entry.

(End-to-end training process)
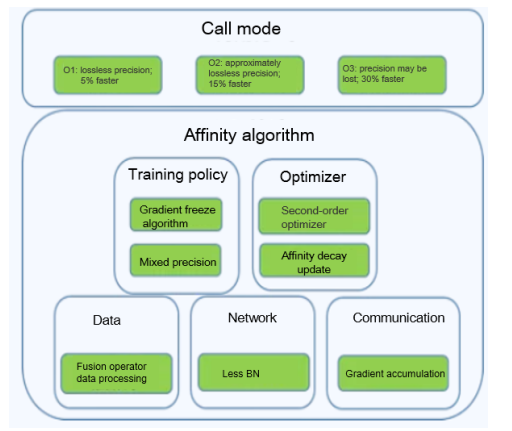
(MindSpore Boost 1.0 architecture)

(Simple mode)
IV. Cluster debugging and optimization
Fundamental models have become a widely discussed research topic in the field of deep learning, and the quantities of model parameters and the sizes of training datasets have been increasing exponentially. For example, the PCL-L model has 200 billion parameters, and it takes several months to traverse 2,000 clusters for training. Therefore, model performance optimization is critical to reducing training time and costs. MindSpore 1.5 releases a tool chain for cluster debugging and optimization, which supports one-click collection of performance data from thousand-level clusters and provides multi-dimensional performance analysis and visualization capabilities, such as slow node/slow network in a cluster, computing communication ratio, and memory heat map. Based on intelligent cluster optimization suggestions, the tool chain can locate performance bottlenecks within hours.
1.Cluster iteration and communication performance analysis
The cluster iteration trajectory analysis component aggregates multiple key performance data and provides functions such as analysis and sorting, helping users quickly find the slow node and link from thousands of clusters and locate the problem on the corresponding device page to identify the minimum performance bottleneck.
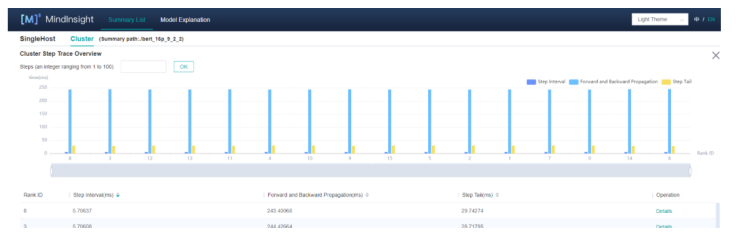
2. Communication ratio analysis
Communication is an important factor that affects performance during cluster parallel training. The computing communication ratio indicator helps developers analyze whether the network segmentation policy is proper and whether there is room for optimization. As shown in the following figure, the 87 ms consumed in the non-overlap scenario can be optimized to improve performance.
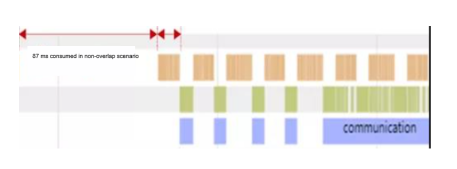
For details, visit https://www.mindspore.cn/mindinsight/docs/en/r1.5/performance_profiling_ascend_of_cluster.html.
V. New open access mechanisms
In this version, MindSpore Lite supports two open access mechanisms: southbound custom operator access and third-party AI framework access through Delegate. The southbound custom operator access allows users to customize graph optimization to generate model files supported by specific hardware in the offline phase. Additionally, special hardware operators can be connected to MindSpore Lite Runtime to implement high-performance inference on third-party hardware. Currently, the Hi3516 and Hi3559 chips are connected to MindSpore Lite, making AI application development in intelligent vision even more convenient.
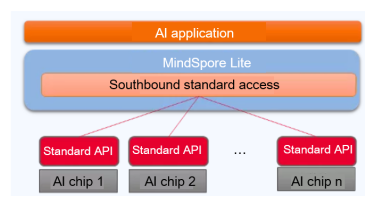
(AI chips accessing to MindSpore Lite)
Delegate allows third-party AI frameworks with image building capabilities to quickly access MindSpore Lite, so that MindSpore Lite can utilize their hardware operator libraries and inference performance. Delegate combines MindSpore Lite and other AI frameworks for heterogeneous execution, ensuring consistent offline models. Currently, Delegate supports Kirin NPUs and other heterogeneous hardware.
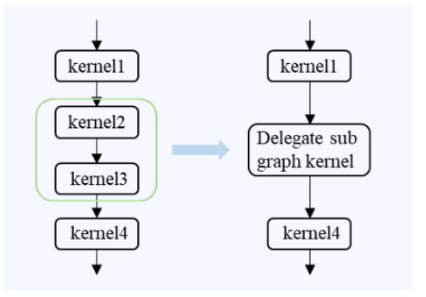
(Accessing to MindSpore Lite using Delegate)
For details, visit https://www.mindspore.cn/lite/docs/en/r1.5/use/delegate.html
VI. Flexible expression
In MindSpore 1.5, the control process statement is optimized:
- The control flow of a static graph is enhanced by executing control flow operators based on the VM mechanism, which resolves the graph recursive execution problem in the non-tail recursion scenario of a control flow and supports backward computing in the loop. In addition, by expanding the control flow syntax, expressions such as if, while, for, break, and continue are supported.
- The static graph compilation process is optimized, and the subgraph quantity of a control flow network is reduced, improving the compilation and execution performance of some complex control flow networks.
- Importing and exporting the control flow MindIR is supported. MindIR can be exported from the control flow network on cloud and can be imported to the device for inference.
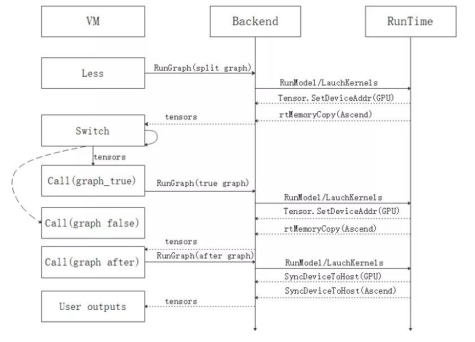
(if statement of a control flow based on the VM mechanism)
For details, visit https://www.mindspore.cn/docs/programming_guide/en/r1.5/control_flow.html.
References:
[1] Zeng, Wei, et al. "PanGu-$\alpha $: Large-scale Autoregressive Pretrained Chinese Language Models with Auto-parallel Computation." arXiv preprint arXiv:2104.12369 (2021).