分布式训练通信融合
![]()
概述
在分布式并行训练场景下训练大规模参数量的模型(如GPT-3, Pangu-\(\alpha\)),跨设备甚至跨节点的数据传输是制约扩展性以及算力利用率的瓶颈[1]。通信融合是一种提升网络资源利用率、加速数据传输效率的重要方法,其将相同源节点和目的节点的通信算子打包同时执行,以避免多个单算子执行带来的额外开销。
MindSpore支持对分布式训练中三种常用通信算子(AllReduce、AllGather、ReduceScatter)的融合,并提供简洁易用的接口方便用户自行配置。在长稳训练任务支撑中,通信融合特性发挥了重要作用。
MindSpore提供两种接口来使能通信融合,下面分别进行介绍:
自动并行场景下的配置
config = {"allreduce": {"mode": "size", "config": 32}, "allgather": {"mode": "size", "config": 32}} ms.set_auto_parallel_context(comm_fusion=config)
在自动并行或半自动并行场景下,用户在通过
set_auto_parallel_context来配置并行策略时,可以利用该接口提供的comm_fusion参数来设置并行策略,输入格式为{“通信类型”: {“mode”:str, “config”: None int 或者 list}}。具体可以参考并行配置中的comm_fusion。在这种场景下,优先推荐此种配置方法。利用
Cell提供的接口无论在哪种并行模式场景下,用户都可以通过
Cell.set_comm_fusion接口为模型某layer的参数设置index,MindSpore将融合相同index的参数所对应的通信算子。
基本原理
本节首先以数据并行为例,介绍分布式训练中计算和通信之间的关系,其次介绍通信融合在分布式训练场景下的必要性。
分布式训练中的计算和通信
分布式训练的整个过程可以粗略地分为本地模型计算和跨设备的网络数据交互两个过程,下面以数据并行[2]为例来介绍整体训练流程,其它并行方式,如模型并行[3],流水线并行[4]等,请读者参考相关论文。
如下图所示,每个节点备份完整的神经网络模型,并利用本地的数据集分区训练一个mini-batch,进行前向和反向计算,反向计算得到的梯度跨节点进行同步,同步后继续下一个mini-batch的训练,如此循环迭代,直到accuracy/loss达到阈值,或者训练完一定数目的epoch。由此可见,在分布式训练过程中,计算和通信交替进行,目前已有工作研究如何将相互不依赖的计算和传输做流水化,以降低跨节点数据同步在整体训练时长中的占比[5][6],这里不再赘述。
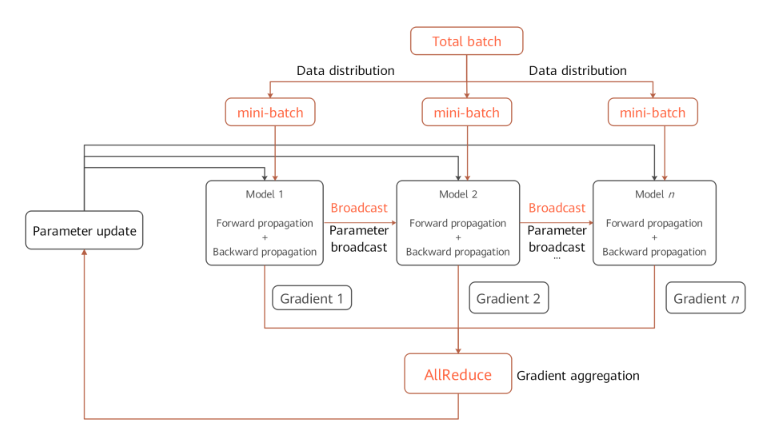
通信融合的必要性
网络通信的时间开销可以用以下公式衡量,其中,\(m\)是传输数据的大小,\(\alpha\)是网络传输速率,\(\beta\)是网络启动的固有开销。可见,当传输的message数变多,网络启动的固有开销占比会下降,并且传输小message,并不能有效利用网络带宽资源。即便是HPC领域的通信原语,如AllReduce,AllGather等,也遵循该原则。因此,通信融合技术能够有效提升网络资源利用率,降低网络同步时延。
通信融合的实现
当前支持对AllReduce,AllGather和ReduceScatter三种通信算子分别进行融合,配置项为一个dict类型。融合带有一个开关设置openstate,通过布尔值进行开关操作,如:
comm_fusion={“openstate”: True, “allreduce”: {“mode”: “auto”, “config”: None}}。其中,”mode”有三种选项:
“auto”:自动按照数据量阈值64MB进行算子融合,配置参数”config”为None。
“size”:按照手动设置数据量阈值的方式进行通信算子融合,配置参数”config”类型为int,单位MB。
“index”:仅”allreduce”支持配置index,表示按照通信算子序列号进行融合的方式,配置参数”config”类型为list。例如:[20, 35],表示将前20个AllReduce融合成1个,第20~35个AllReduce融合成1个,剩下的AllReduce融合成1个。
操作实践
样例代码说明
目录结构如下:
└─sample_code
├─distributed_comm_fusion
├── fusion_example_cell.py
└── run.sh
其中fusion_example_cell.py为利用Cell提供的接口进行通信融合的示例,run.sh为通信融合的启动脚本。
配置通信融合
下面通过实际样例,介绍两种使用方法如何进行配置。
comm_fusion参数
如下述代码所示,使用set_auto_parallel_context接口的comm_fusion参数,为AllReduce算子配置融合模式为auto,意味着默认设置fusion buffer的大小为64MB。
from mindspore.communication import init
from mindspore import nn
import mindspore as ms
ms.set_auto_parallel_context(parallel_mode=ms.ParallelMode.SEMI_AUTO_PARALLEL)
ms.set_auto_parallel_context(comm_fusion={"allreduce": {"mode": "auto", "config": None}})
init()
若将所有的同类通信算子融合成一个算子,在当前训练迭代中,传输需要等待计算完全结束后才能执行,这样会造成设备的等待。
为了避免上述问题,可以将网络参数进行分组融合:在下一组参数进行的计算的同时,进行上组参数的通信,使得计算和通信能够互相隐藏,可以通过限定fusion buffer的大小,或者index分区的方法进行分组融合。
更多使用方法,可以参考MindSpore的测试用例。
用户可以自行尝试
comm_fusion的size和index模式,本质上都是fusion buffer类的方法。
Cell.set_comm_fusion接口
本示例代码fusion_example_cell.py中采取此方法。如下述代码所示,针对实例化后的DenseLayer,调用set_comm_fusion方法,为每一层设置fusion值。
import mindspore as ms
from mindspore import nn
from mindspore.communication import init
ms.set_context(mode=ms.GRAPH_MODE)
ms.set_auto_parallel_context(parallel_mode=ms.ParallelMode.SEMI_AUTO_PARALLEL)
init()
class DenseLayer(nn.Cell):
def __init__(self):
super().__init__()
self.input_mapping = nn.Dense(10, 32)
self.output_mapping = nn.Dense(32, 10)
def construct(self, x):
x = self.input_mapping(x)
return self.output_mapping(x)
class Net(nn.Cell):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.head = nn.Dense(28*28, 10)
self.layer1 = DenseLayer()
self.layer2 = DenseLayer()
self.layer3 = DenseLayer()
def construct(self, x):
x = self.flatten(x)
x = self.head(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
return x
net = Net()
# 配置通信融合
net.head.set_comm_fusion(0)
net.layer1.set_comm_fusion(1)
net.layer2.set_comm_fusion(2)
net.layer3.set_comm_fusion(3)
for item in net.trainable_params():
print(f"The parameter {item.name}'s fusion id is {item.comm_fusion}")
数据集加载和训练过程
数据集加载和训练过程与单卡模式一致,代码如下:
import os
import mindspore as ms
import mindspore.dataset as ds
from mindspore import nn
def create_dataset(batch_size):
dataset_path = os.getenv("DATA_PATH")
dataset = ds.MnistDataset(dataset_path)
image_transforms = [
ds.vision.Rescale(1.0 / 255.0, 0),
ds.vision.Normalize(mean=(0.1307,), std=(0.3081,)),
ds.vision.HWC2CHW()
]
label_transform = ds.transforms.TypeCast(ms.int32)
dataset = dataset.map(image_transforms, 'image')
dataset = dataset.map(label_transform, 'label')
dataset = dataset.batch(batch_size)
return dataset
data_set = create_dataset(32)
optimizer = nn.SGD(net.trainable_params(), 1e-2)
loss_fn = nn.CrossEntropyLoss()
def forward_fn(data, target):
logits = net(data)
loss = loss_fn(logits, target)
return loss, logits
grad_fn = ms.value_and_grad(forward_fn, None, net.trainable_params(), has_aux=True)
@ms.jit
def train_step(inputs, targets):
(loss_value, _), grads = grad_fn(inputs, targets)
optimizer(grads)
return loss_value
for epoch in range(10):
i = 0
for image, label in data_set:
loss_output = train_step(image, label)
if i % 10 == 0:
print("epoch: %s, step: %s, loss is %s" % (epoch, i, loss_output))
i += 1
运行单机8卡脚本
接下来通过命令调用对应的脚本,以mpirun启动方式,8卡的分布式训练脚本为例,进行分布式训练:
bash run.sh
训练完后,日志文件保存在log_output/1/rank.*/stdout中,示例如下:
The parameter head.weight's fusion id is 0
The parameter head.bias's fusion id is 0
The parameter layer1.input_mapping.weight's fusion id is 1
The parameter layer1.input_mapping.bias's fusion id is 1
The parameter layer1.output_mapping.weight's fusion id is 1
The parameter layer1.output_mapping.bias's fusion id is 1
The parameter layer2.input_mapping.weight's fusion id is 2
The parameter layer2.input_mapping.bias's fusion id is 2
The parameter layer2.output_mapping.weight's fusion id is 2
The parameter layer2.output_mapping.bias's fusion id is 2
The parameter layer3.input_mapping.weight's fusion id is 3
The parameter layer3.input_mapping.bias's fusion id is 3
The parameter layer3.output_mapping.weight's fusion id is 3
The parameter layer3.output_mapping.bias's fusion id is 3
...
epoch: 0, step: 0, loss is 2.3004832
epoch: 0, step: 10, loss is 2.294562
epoch: 0, step: 20, loss is 2.2642817
epoch: 0, step: 30, loss is 2.1556587
epoch: 0, step: 40, loss is 1.804863
epoch: 0, step: 50, loss is 1.4092219
epoch: 0, step: 60, loss is 1.231769
epoch: 0, step: 70, loss is 1.1870081
...
第一部分表示了每层特定dense的fusion index值,第二部分表示训练的Loss结果。
参考文献
[1] Xu Y, Lee H J, Chen D, et al. GSPMD: general and scalable parallelization for ML computation graphs[J]. arXiv preprint arXiv:2105.04663, 2021.
[2] Li M, Zhou L, Yang Z, et al. Parameter server for distributed machine learning[C]//Big learning NIPS workshop. 2013, 6: 2.
[3] Dean J, Corrado G, Monga R, et al. Large scale distributed deep networks[J]. Advances in neural information processing systems, 2012, 25.
[4] Narayanan D, Harlap A, Phanishayee A, et al. PipeDream: generalized pipeline parallelism for DNN training[C]//Proceedings of the 27th ACM Symposium on Operating Systems Principles. 2019: 1-15.
[5] Zhang H, Zheng Z, Xu S, et al. Poseidon: An efficient communication architecture for distributed deep learning on {GPU} clusters[C]//2017 USENIX Annual Technical Conference (USENIX ATC 17). 2017: 181-193.
[6] Peng Y, Zhu Y, Chen Y, et al. A generic communication scheduler for distributed dnn training acceleration[C]//Proceedings of the 27th ACM Symposium on Operating Systems Principles. 2019: 16-29.