Building an LLM Inference Network from Scratch
![]()
Model Development Modes
MindSpore provides two model running modes:
Static graph mode: The model network is compiled into a complete network graph for convergence and optimization, improving the model execution performance. However, due to some syntax support issues, model development has certain limitations, affecting the usability.
Dynamic graph mode: Python statements of network scripts are executed one by one, facilitating printing and debugging (by using the PDB) at any time. This mode is easy to use, but its performance is not as good as that of the static graph mode.
In MindSpore, you are advised to use the dynamic graph mode to develop a model and then convert dynamic graphs to static graphs as required to obtain the maximum model performance.
Backbone Network Used for Development in Dynamic Graph Mode
Most mainstream LLMs use the Transformer-based backbone network, where core computing relies on the self-attention mechanism. The following figure uses the Qwen2 LLM as an example to show the backbone network architecture.
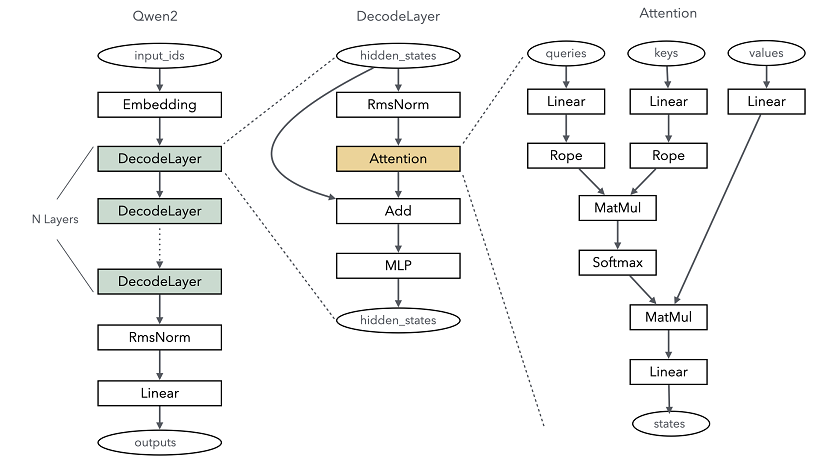
The core layer of Qwen2 consists of the following parts:
Embedding: converts the index corresponding to each token into a vector to implement feature dispersion. Similar to one-hot vectorization, the embedding weights are involved in the training process, which can better adapt to the context semantics in the LLM. This process is implemented through the embedding operator.
DecodeLayer: refers to the Transformer structure, which is a key compute module of the LLM. Generally, multiple layers of computation are configured as needed. Each layer is actually a Transformer structure.
RmsNorm & Linear: linearly normalizes the output of each layer to the same dimension as the model vocabulary after computation by the transformer structure and returns the probability distribution of each token.
You can use the MindSpore LLM to build a network for inference. The network can be assembled as required using operators provided by MindSpore. The following uses the Qwen2 model as an example to describe how to build a model. For details about the complete end-to-end example, see qwen2.py.
Basic Common Network Layer
The Qwen2 LLM has many configurations and parameters. To manage them more conveniently, you need to define the Config and Input classes to be used by the model. In addition, note that the Linear and RmsNorm operators are frequently used in each functional layer of the network. You can build these common layers in advance.
Config & Input
import json
from dataclasses import dataclass
from typing import Optional, Type, List, Tuple, Union
from mindspore import Tensor, dtype
@dataclass
class Qwen2Config:
"""Qwen2 Config, the key-value is almost the same with config.json in Hugging Face"""
architectures: Optional[List[str]] = None
attention_dropout: float = 0.0
bos_token_id: int = 151643
eos_token_id: int = 151645
hidden_act: str = "silu"
hidden_size: int = 3584
initializer_range: float = 0.02
intermediate_size: int = 18944
max_position_embeddings: int = 32768
max_window_layers: int = 28
model_type: str = "qwen2"
num_attention_heads: int = 28
num_hidden_layers: int = 28
num_key_value_heads: int = 4
rms_norm_eps: float = 1e-06
rope_theta: float = 1000000.0
sliding_window: Optional[int] = 131072
tie_word_embeddings: bool = False
torch_dtype: str = "bfloat16"
transformers_version: str = "4.41.2"
use_cache: bool = True
use_sliding_window: bool = False
vocab_size: int = 152064
param_dtype: Optional[Type] = dtype.bfloat16 # this is mindspore datatype as hugging face use str as dtype
@classmethod
def from_json(cls, json_path: str) -> 'Qwen2Config':
with open(json_path) as f:
data = json.load(f)
config = cls(**data)
return config
@dataclass
class Qwen2ModelInput:
input_ids: Tensor
positions: Tensor
batch_valid_length: Tensor
is_prefill: bool
attn_mask: Tensor
k_caches: List[Tensor]
v_caches: List[Tensor]
slot_mapping: Tensor = None
block_tables: Tensor = None
hidden_state: Optional[Tensor] = None
residual: Optional[Tensor] = None
q_seq_lens: Optional[Tensor] = None
The Qwen2Config configuration is basically the same as that of Hugging Face. For details, see the official Qwen2 documentation. Note that param_dtype is used to replace torch_dtype in Qwen2Config because the data types of MindSpore are different from those of PyTorch. Qwen2ModelInput defines the model input, including the word ID, KVCache, and Attention fused operator, which are required by MindSpore inference optimization features.
RmsNorm
RmsNorm is a normalization algorithm commonly used in most LLMs. MindSpore provides operators that can be directly used. You only need to create the corresponding weights. In addition, RmsNorm often involves residual computing. The RmsNorm class implements residual converged computing at the network layer. The following is a code example:
from typing import Optional, Type, Union, Tuple
from mindspore import nn, ops, mint, Parameter, Tensor
class RmsNorm(nn.Cell):
def __init__(self, config: Qwen2Config) -> None:
super().__init__()
self.rms_norm = ops.RmsNorm(config.rms_norm_eps)
self.weight = Parameter(
mint.ones(
config.hidden_size,
dtype=config.param_dtype
),
requires_grad=False
)
def construct(self, x: Tensor, residual: Optional[Tensor] = None) -> Union[Tensor, Tuple[Tensor, Tensor]]:
if residual is not None:
x = x + residual
residual = x
output = self.rms_norm(x, self.weight)[0]
if residual is None:
return output
return output, residual
Linear
The Linear layer is actually a linear transformation. Its main computing logic is matrix multiplication (MatMul). However, bias correction may be required for addition depending on the specific application scenario (bias is required during query, key, and value conversion). The following code integrates these computations into a network structure:
from typing import Optional, Type
from mindspore import nn, ops, mint, Parameter, Tensor
class Qwen2Linear(nn.Cell):
def __init__(self, input_size: int, output_size: int, param_dtype: Optional[Type], enable_bias: bool) -> None:
super().__init__()
self.param_dtype = param_dtype
self.input_size = input_size
self.output_size = output_size
self.enable_bias = enable_bias
self.matmul = ops.MatMul(transpose_b=True)
self.weight = Parameter(
mint.zeros(
(self.output_size, self.input_size),
dtype=self.param_dtype
),
requires_grad=False
)
if self.enable_bias:
self.bias_add = ops.Add()
self.bias = Parameter(
mint.zeros(self.output_size, dtype=self.param_dtype)
)
def construct(self, input: Tensor):
origin_shape = input.shape
x = self.matmul(input.view(-1, origin_shape[-1]), self.weight)
if self.enable_bias:
x = self.bias_add(x, self.bias)
return x.view(*origin_shape[:-1], -1)
Because multi-batch computation is required, the input shape may be n times of input_size. To ensure correct computation, the original input shape is saved. After the computation is complete, shape is restored through the view.
Qwen2ForCausalLM
The Qwen2 model is usually encapsulated for specific services. For example, Qwen2ForCausalLM is an encapsulation of Qwen2 for language processing and dialog services.
The Qwen2ForCausalLM class is used to clearly define the main APIs of the model. The following shows the specific implementation:
from glob import glob
from typing import Optional, Type
from mindspore import nn, Tensor, load_checkpoint, load_param_into_net
class Qwen2ForCausalLM(nn.Cell):
def __init__(self, config: Qwen2Config) -> None:
super().__init__()
self.model = Qwen2Model(config=config)
self.lm_head = Qwen2Linear(
input_size=config.hidden_size,
output_size=config.vocab_size,
param_dtype=config.param_dtype,
enable_bias=False
)
def load_weight(self, weight_path: str) -> None:
weight_dict = {}
for path in glob(weight_path + "/*.safetensors"):
weight_dict.update(load_checkpoint(path, format="safetensors"))
load_param_into_net(self, weight_dict, strict_load=False)
def construct(self, model_input: Qwen2ModelInput) -> Tensor:
hidden_state = self.model(model_input.input_ids, model_input.positions,
model_input.batch_valid_length, model_input.is_prefill,
model_input.k_caches, model_input.v_caches, model_input.slot_mapping,
model_input.block_tables, model_input.attn_mask, model_input.q_seq_lens)
logits = self.lm_head(hidden_state)[:, -1]
return logits
As shown in the code, Qwen2ForCausalLM has two core APIs:
load_weight: loads weights from the Hugging Face official website model and injects them into the model based on the network script.
construct: performs inference and computing, and calls submodules to complete computing layer by layer. As shown in the construct, the core of the model is the backbone network computing and the linear computing of the last lm_head, which converts the features of hidden_size into the vocabulary probability distribution of vocab_size.
Qwen2Model
Qwen2Model is the main network of the Qwen2 model. It consists of two parts: the embedding layer that converts the input into features and the decoder structure of n Transformer layers.
Embedding
The logic of the embedding layer is simple. It obtains the feature data (which is also a part of the training weight) of hidden_size based on the input word ID through a gather operator. The code is as follows:
from typing import Optional, Type
from mindspore import nn, ops, mint, Parameter, Tensor
class VocabEmbedding(nn.Cell):
def __init__(self, config: Qwen2Config) -> None:
super().__init__()
self.num_embeddings = config.vocab_size
self.embedding_dim = config.hidden_size
self.gather = ops.Gather()
self.weight = Parameter(
mint.zeros(
(self.num_embeddings, self.embedding_dim),
dtype=config.param_dtype
),
requires_grad=False
)
def construct(self, input_ids: Tensor):
return self.gather(self.weight, input_ids, 0)
DecoderLayer
DecoderLayer is the core computing unit of the Transformer network. Most of the computing operations are performed at this layer. As shown in the Qwen2 network structure diagram, the network layers include RoPE, Attention, and MLP. To facilitate development, these network layers are constructed first.
RoPE
The rotary position embedding (RoPE) operator is used to enhance the Attention mechanism's capability to perceive the distance between words by adding positional encoding information to the features of the query and key. Due to the features of RoPE, the result can be pre-computed and directly obtained by querying the table, thereby achieving efficient computation. This can be implemented using the gather and the RoPE operators. For details about the calculation method, see the related documents of RoPE.
import numpy as np from typing import Optional, Type from mindspore import nn, ops, mint, Parameter, Tensor class Qwen2RotaryEmbedding(nn.Cell): def __init__(self, head_size: int, rotary_dim: int, max_position_embeddings: int, base: int, dtype: Optional[Type]) -> None: super().__init__() self.head_size = head_size self.rotary_dim = rotary_dim self.max_position_embeddings = max_position_embeddings self.base = base self.dtype = dtype # format 2 is neox style self.rotary_embedding_op = ops.ApplyRotaryPosEmb(2) self.gather = ops.Gather() self.freqs_cos, self.freqs_sin = self._compute_cos_sin_cache() def _compute_inv_freq(self) -> Tensor: freqs_base = mint.arange(0, self.rotary_dim, 2).astype(np.float32) freqs = 1.0 / (self.base ** (freqs_base / self.rotary_dim)) return freqs def _compute_cos_sin_cache(self) -> Tuple[Tensor, Tensor]: freqs = self._compute_inv_freq() t = np.arange(0, self.max_position_embeddings, 1).astype(np.float32) freqs = np.outer(t, freqs) emb = np.concatenate((freqs, freqs), axis=1) freqs_cos = np.cos(emb) freqs_sin = np.sin(emb) freqs_cos = Tensor(freqs_cos, dtype=self.dtype) freqs_sin = Tensor(freqs_sin, dtype=self.dtype) return freqs_cos, freqs_sin def construct(self, positions: Tensor, query: Tensor, key: Tensor, batch_valid_length: Tensor, is_prefill: bool): query = query.contiguous() key = key.contiguous() if is_prefill: freqs_cos = self.freqs_cos freqs_sin = self.freqs_sin else: freqs_cos = self.gather(self.freqs_cos, positions.view(-1), 0) freqs_sin = self.gather(self.freqs_sin, positions.view(-1), 0) return self.rotary_embedding_op(query, key, freqs_cos, freqs_sin, batch_valid_length)
Attention
An attention layer consists of multiple Linear and RoPE operators, and attention score calculation. MindSpore provides two fusion operators, FlashAttention and PagedAttention, to enhance the inference performance of attention score calculation.
However, because these native operators are oriented to multiple scenarios and the input is complex, they are encapsulated here to simplify the usage. For details about the code, see the following:
import numpy as np from typing import Optional, Type from mindspore import nn, ops, mint, Parameter, Tensor class FlashAttention(nn.Cell): def __init__(self, scale: float, num_heads: int) -> None: super().__init__() input_layout = "TH" scale = scale pre_tokens = 2147483647 next_tokens = 2147483647 self.flash_attention = ops.operations.nn_ops.FlashAttentionScore(head_num=num_heads, scale_value=scale, pre_tokens=pre_tokens, next_tokens=next_tokens, input_layout=input_layout) def construct(self, q: Tensor, k: Tensor, v: Tensor, attn_mask: Tensor, batch_valid_length: Tensor) -> Tensor: _, _, _, output = self.flash_attention( q, k, v, None, None, None, attn_mask, None, batch_valid_length, batch_valid_length ) return output class PagedAttention(nn.Cell): def __init__(self, head_num: int, scale: float, num_kv_heads: int) -> None: super().__init__() self.head_num = head_num self.num_kv_heads = num_kv_heads self.paged_attention = ops.auto_generate.PagedAttention( head_num=head_num, scale_value=scale, kv_head_num=num_kv_heads ) def construct(self, q: Tensor, k_cache: Tensor, v_cache: Tensor, block_tables: Tensor, batch_valid_length: Tensor, attn_mask: Tensor, q_seq_lens: Tensor) -> Tensor: output = self.paged_attention(q, k_cache, v_cache, block_tables, batch_valid_length, None, None, attn_mask, q_seq_lens) return output
The code of the attention layer may be implemented by using the constructed network layer. For details about the code, see the following:
import numpy as np from typing import Optional, Type from mindspore import nn, ops, mint, Parameter, Tensor class Qwen2Attention(nn.Cell): def __init__(self, config: Qwen2Config) -> None: super().__init__() self.hidden_size = config.hidden_size self.num_heads = config.num_attention_heads self.num_kv_heads = config.num_key_value_heads self.head_dim =config.hidden_size // self.num_heads self.q_size = self.head_dim * self.num_heads self.kv_size = self.head_dim * self.num_kv_heads self.scaling = float(self.head_dim ** -0.5) self.rope_theta = int(config.rope_theta) self.param_dtype = config.param_dtype self.max_position = config.max_position_embeddings self.flash_attn = FlashAttention(self.scaling, self.num_heads) self.paged_attn = PagedAttention(self.num_heads, self.scaling, self.num_kv_heads) self.reshape_and_cache = ops.auto_generate.ReshapeAndCache() self.q_proj = Qwen2Linear( input_size=self.hidden_size, output_size=self.q_size, param_dtype=self.param_dtype, enable_bias=True ) self.k_proj = Qwen2Linear( input_size=self.hidden_size, output_size=self.kv_size, param_dtype=self.param_dtype, enable_bias=True ) self.v_proj = Qwen2Linear( input_size=self.hidden_size, output_size=self.kv_size, param_dtype=self.param_dtype, enable_bias=True ) self.o_proj = Qwen2Linear( input_size=self.q_size, output_size=self.hidden_size, param_dtype=self.param_dtype, enable_bias=False ) self.rotary_emb = Qwen2RotaryEmbedding( head_size=self.head_dim, rotary_dim=self.head_dim, max_position_embeddings=self.max_position, base=self.rope_theta, dtype=self.param_dtype ) def construct(self, hidden_state: Tensor, positions: Tensor, batch_valid_length: Tensor, is_prefill: bool, layer_idx: int, k_cache: Tensor, v_cache: Tensor, slot_mapping: Tensor, block_tables: Tensor, attn_mask: Tensor, q_seq_lens: Tensor) -> Tensor: bs, seq_len, hidden_dim = hidden_state.shape q = self.q_proj(hidden_state).view(-1, self.q_size) k = self.k_proj(hidden_state).view(-1, self.kv_size) v = self.v_proj(hidden_state).view(-1, self.kv_size) q, k = self.rotary_emb( positions, q, k, batch_valid_length, is_prefill ) k = k.contiguous() v = v.contiguous() cache_out = self.reshape_and_cache( k, v, k_cache, v_cache, slot_mapping ) q = ops.depend(q, cache_out) if is_prefill: attn_output = self.flash_attn( q, k, v, attn_mask, batch_valid_length ) else: attn_output = self.paged_attn( q, k_cache, v_cache, block_tables, batch_valid_length, attn_mask, q_seq_lens ) output = self.o_proj(attn_output).view(bs, seq_len, -1) return output
MLP
An MLP layer, consisting of multiple Linear operators and an activation function (usually silu), is responsible for implementing non-linear computation of the network. The MLP layer can project problems to multiple non-linear spaces, thereby enhancing network capabilities. For details about the implementation, see the following code:
import numpy as np from typing import Optional, Type from mindspore import nn, ops, mint, Parameter, Tensor class Qwen2MLP(nn.Cell): def __init__(self, config: Qwen2Config) -> None: super().__init__() self.up_proj = Qwen2Linear( input_size=config.hidden_size, output_size=config.intermediate_size, param_dtype=config.param_dtype, enable_bias=False ) self.gate_proj = Qwen2Linear( input_size=config.hidden_size, output_size=config.intermediate_size, param_dtype=config.param_dtype, enable_bias=False ) self.down_proj = Qwen2Linear( input_size=config.intermediate_size, output_size=config.hidden_size, param_dtype=config.param_dtype, enable_bias=False ) self.act_fn = ops.silu def construct(self, x: Tensor) -> Tensor: output = self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x)) return output
DecoderLayer may be constructed as follows by referring to the preceding network layer:
from typing import Tuple
from mindspore import nn, Tensor
class Qwen2DecoderLayer(nn.Cell):
def __init__(self, config: Qwen2Config) -> None:
super().__init__()
self.hidden_size = config.hidden_size
self.self_attn = Qwen2Attention(config=config)
self.mlp = Qwen2MLP(config=config)
self.input_layernorm = RmsNorm(config=config)
self.post_attention_layernorm = RmsNorm(config=config)
def construct(self, hidden_state: Tensor, residual: Tensor, positions: Tensor,
batch_valid_length: Tensor, is_prefill: bool, layer_idx: int,
k_cache: Tensor, v_cache: Tensor, slot_mapping: Tensor,
block_tables: Tensor, attn_mask: Tensor, q_seq_lens: Tensor) -> Tuple[Tensor, Tensor]:
if residual is None:
residual = hidden_state
hidden_state = self.input_layernorm(hidden_state)
else:
hidden_state, residual = self.input_layernorm(hidden_state, residual)
hidden_state = self.self_attn(hidden_state, positions, batch_valid_length, is_prefill,
layer_idx, k_cache, v_cache, slot_mapping, block_tables,
attn_mask, q_seq_lens)
hidden_state, residual = self.post_attention_layernorm(hidden_state, residual)
hidden_state = self.mlp(hidden_state)
return hidden_state, residual
Model
After the embedding and decoder layers are constructed, you can construct the Model class by referring to the following code:
from mindspore import nn, ops, mint, Parameter, Tensor
class Qwen2Model(nn.Cell):
def __init__(self, config: Qwen2Config) -> None:
super().__init__()
self.vocab_size = config.vocab_size
self.hidden_size = config.hidden_size
self.num_hidden_layers = config.num_hidden_layers
self.embed_tokens = VocabEmbedding(config=config)
self.layers = nn.CellList()
for i in range(config.num_hidden_layers):
layer = Qwen2DecoderLayer(config=config)
self.layers.append(layer)
self.norm = RmsNorm(config=config)
def construct(self, input_ids: Tensor, positions: Tensor, batch_valid_length: Tensor,
is_prefill: bool, k_caches: List[Tensor], v_caches: List[Tensor],
slot_mapping: Tensor, block_tables: Tensor, attn_mask: Tensor,
q_seq_lens: Tensor) -> Tensor:
hidden_state = self.embed_tokens(input_ids)
residual = None
for i in range(self.num_hidden_layers):
layer = self.layers[i]
hidden_state, residual = layer(hidden_state, residual, positions, batch_valid_length,
is_prefill, i, k_caches[i], v_caches[i], slot_mapping,
block_tables, attn_mask, q_seq_lens)
hidden_state, _ = self.norm(hidden_state, residual)
return hidden_state
KVCacheManager
Since KVCache is usually used to optimize LLMs, to use KVCache with FlashAttention and PagedAttention provided by MindSpore, some parameters need to be specified additionally, including:
k_cache & v_cache: The kv_cache object can be considered as a cache table, which is used to store the keys and values in the previous iteration. In the next iteration, these values can be directly read, avoiding repeated computation of the keys and values of the first n words, thereby improving performance.
block_tables & slot_mapping: PagedAttention stores KVCache by block using a mechanism similar to paging, so that the same words can be concentrated in the same block, thereby improving graphics memory utilization.
According to the preceding description, these parameters can be encapsulated in a management class. The code can be referenced as follows:
import math
from collections import deque
from mindspore import nn, ops, mint, Parameter, Tensor, mutable
class CacheManager:
def __init__(self, config: Qwen2Config, block_num: int, block_size: int, batch_size: int) -> None:
self.block_num = block_num
self.block_size = block_size
self.batch_size = batch_size
head_dim = config.hidden_size // config.num_attention_heads
self.k_caches = mutable([ops.zeros((block_num, block_size, config.num_key_value_heads, head_dim), dtype=config.param_dtype) for _ in range(config.num_hidden_layers)])
self.v_caches = mutable([ops.zeros((block_num, block_size, config.num_key_value_heads, head_dim), dtype=config.param_dtype) for _ in range(config.num_hidden_layers)])
self.block_tables = [[] for _ in range(batch_size)]
self.acc_slot_mapping = [[] for _ in range(batch_size)]
self.free_block_ids = deque(range(block_num))
def step(self, start_pos_idx: int, token_num_per_batch: int) -> Tuple[Tensor, Tensor]:
for i in range(self.batch_size):
block_table = self.block_tables[i]
total_block_num = math.ceil((start_pos_idx + token_num_per_batch) / self.block_size)
now_block_num = len(block_table)
for _ in range(total_block_num - now_block_num):
block_id = self.free_block_ids.popleft()
block_table.append(block_id)
start_slot_id = block_id * self.block_size
self.acc_slot_mapping[i].extend(list(range(start_slot_id, start_slot_id + self.block_size)))
now_block_tables = Tensor(self.block_tables, dtype=dtype.int32)
now_slot_mapping = Tensor([self.acc_slot_mapping[i][start_pos_idx: start_pos_idx + token_num_per_batch]
for i in range(self.batch_size)], dtype=dtype.int32).view(-1)
return now_block_tables, now_slot_mapping
Sampler
After the backbone network is computed, the network output is a vocabulary with shape in the range [batch_size,vocab_size], which indicates the probability distribution of the next word in multiple inference requests in the batch. You need to select a word from the vocabulary as the final result. To simplify the selection and eliminate randomness, you need to select the word with the maximum probability as the output each time, that is, perform argmax computing. The following is a code example:
from mindspore import Tensor
def sample(logits: Tensor) -> Tensor:
next_token = logits.argmax(axis=-1, keepdims=True)
return next_token
Converting Dynamic Graphs to Static Graphs
MindSpore can convert dynamic graphs to static graphs using JIT to improve inference performance. In terms of code implementation, you can use the following simple decorator for conversion:
from mindspore import nn, ops, mint, Parameter, Tensor, jit
class Qwen2Model(nn.Cell):
def __init__(self, config: Qwen2Config) -> None:
super().__init__()
self.vocab_size = config.vocab_size
self.hidden_size = config.hidden_size
self.num_hidden_layers = config.num_hidden_layers
self.embed_tokens = VocabEmbedding(config=config)
self.layers = nn.CellList()
for i in range(config.num_hidden_layers):
layer = Qwen2DecoderLayer(config=config)
self.layers.append(layer)
self.norm = RmsNorm(config=config)
@jit(jit_level="O0", infer_boost="on")
def construct(self, input_ids: Tensor, positions: Tensor, batch_valid_length: Tensor,
is_prefill: bool, k_caches: List[Tensor], v_caches: List[Tensor],
slot_mapping: Tensor, block_tables: Tensor, attn_mask: Tensor,
q_seq_lens: Tensor) -> Tensor:
hidden_state = self.embed_tokens(input_ids)
residual = None
for i in range(self.num_hidden_layers):
layer = self.layers[i]
hidden_state, residual = layer(hidden_state, residual, positions, batch_valid_length,
is_prefill, i, k_caches[i], v_caches[i], slot_mapping,
block_tables, attn_mask, q_seq_lens)
hidden_state, _ = self.norm(hidden_state, residual)
return hidden_state
Add the mindspore.jit decorator to the construct method of nn.Cell to execute the computation of the cell in static graph mode. The parameters are described as follows:
jit_level: specifies the compilation level. Currently, MindSpore inference supports O0 and O1 levels (some operator fusion optimization is involved).
infer_boost: enables inference acceleration optimization. After this option is enabled, some scheduling optimization and stream optimization are performed during runtime to improve inference performance.
In addition, due to the limitations of the static graph mode of MindSpore, dynamic-to-static conversion may fail in some scenarios. The following lists some common causes:
setattrs usage: The setattrs syntax of Python is not supported during MindSpore graph capture. Therefore, parameters cannot be encapsulated using an encapsulation class. For example, Qwen2ModelInput in the preceding example cannot be directly passed to Qwen2Model whose graph is converted to a static graph. Otherwise, the static graph execution fails.
List value: If there are list parameters when the graph is converted to a static graph, the parameters must be wrapped by mutable to ensure that MindSpore can correctly process the parameters, for example, k_caches and v_caches in the preceding example. Otherwise, the fallback to Python is triggered, which affects the inference performance. In some scenarios, the computation may fail.
Graph input name: If the PagedAttention operator of MindSpore is used, the two graph inputs must be named batch_valid_length and q_seq_lens. Otherwise, the PagedAttention operator fails to be initialized.
If you plan to use static graph inference in the future when developing models with MindSpore, you are advised to pay attention to the preceding limitations during dynamic graph development and debugging to avoid extra costs in subsequent migration and debugging.