Data Processing Overview
![]()
MindSpore Dataset provides two types of data processing capabilities: pipeline mode and lightweight mode.
Pipeline mode: provides the concurrent data processing pipeline capability based on C++ Runtime. Users can define processes such as dataset loading, data transforms, and data batch process to implement efficient dataset loading, processing, and batching. In addition, the concurrency and cache can be adjusted to provide training data with zero Bottle Neck for NPU card training.
Lightweight mode: Users can perform data transform operations (e.g. Resize, Crop, HWC2CHW, etc.). Data processing of a single sample is performed.
Pipeline Mode
Dataset pipeline defined by an API is used. After a training process is run, the dataset cyclically loads data from the dataset, processes data, and batch data, and then iterators for training.
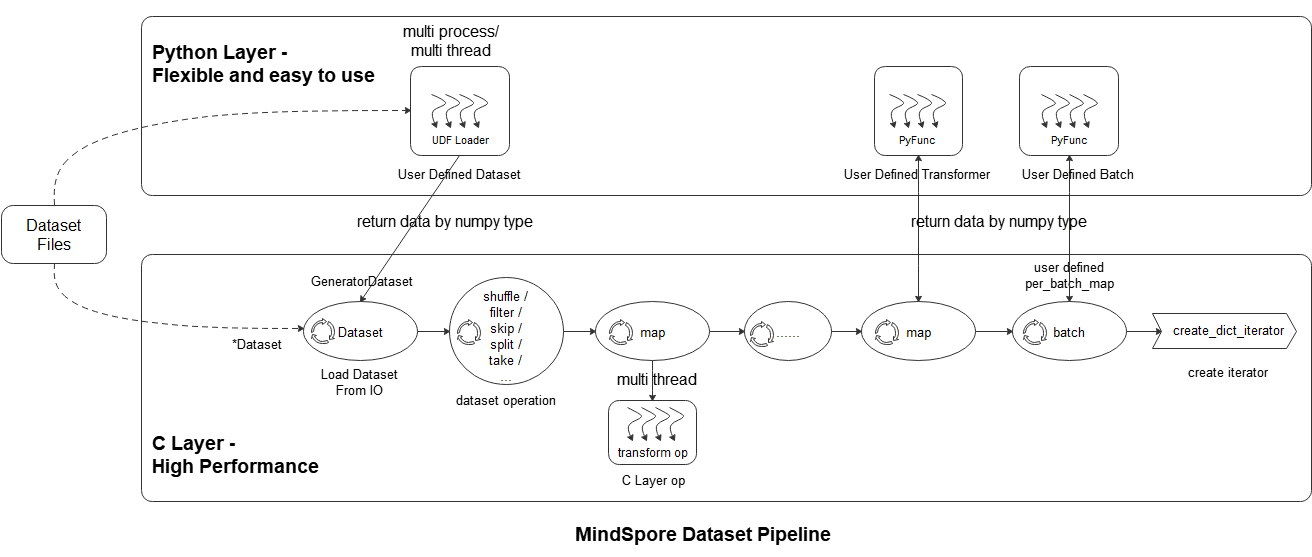
As shown in the above figure, the mindspore dataset module makes it easy for users to define data preprocessing pipelines and transform samples in the dataset in the most efficient (multi-process / multi-thread) manner. The specific steps are as follows:
Dataset loading: Users can easily load supported datasets using the Dataset class(Standard-format Dataset, Vision Dataset, NLP Dataset, Audio Dataset), or load Python layer customized datasets through UDF Loader + GeneratorDataset. At the same time, the loading class method can accept a variety of parameters such as sampler, data slicing, and data shuffle;
Dataset operation: The user uses the dataset object method .shuffle / .filter / .skip / .split / .take / … to further shuffle, filter, skip, and obtain the maximum number of samples of datasets;
Dataset sample transform operation: The user can add data transform operations (vision transform, nlp transform, audio transform) to the map operation to perform transforms. During data preprocessing, multiple map operations can be defined to perform different transform operations to different fields. The data transform operation can also be a user-defined transform pyfunc (Python function);
Batch: After the transforms of the samples, the user can use the .batch operation to organize multiple samples into batches, or use self-defined batch logic with the parameter per_batch_map applied;
Iterator: Finally, the user can use the dataset object method .create_dict_iterator or .create_tuple_iterator to create an iterator, which can output the preprocessed data cyclically.
Dataset Loading
The following describes common dataset loading methods, such as single dataset loading, dataset combination, dataset segmentation, and dataset saving.
Loading A Single Dataset
The dataset loading class is used to load training datasets from local disks, OBS, and shared storage to the memory. The dataset loading interface is as follows:
Dataset API Category |
API List |
Description |
|---|---|---|
Standard-format Datasets |
MindDataset, TFRecordDataset, CSVDataset, etc. |
MindDataset depends on the MindRecord format. For details, see Format Conversion |
Customized Datasets |
GeneratorDataset, RandomDataset, etc. |
GeneratorDataset loads user-defined DataLoaders. For details, see Custom DataSets |
Common Datasets |
ImageFolderDataset, Cifar10Dataset, IWSLT2017Dataset, LJSpeechDataset, etc. |
Used for commonly used open source datasets |
You can configure different parameters for loading datasets to achieve different loading effects. Common parameters are as follows:
columns_list: filters specified columns from the dataset. The parameter applies only to some dataset interfaces. The default value is None, indicating that all data columns are loaded.num_parallel_workers: configures the number of read concurrency for the dataset. The default value is 8.You can configure the sampling logic of the dataset by using the following parameters:
shuffle: specifies whether to enable shuffle. The default value is True.num_shardsandshard_id: specifies whether to shard a dataset. The default value is None, indicating that the dataset is not sharded.For more sampling logic, see Data Sampling.
Dataset Combination
Dataset combination can combine multiple datasets in series/parallel mode to form a new dataset object, see Data Operation.
Dataset Segmentation
The dataset is divided into a training dataset and a validation dataset, which are used in a training process and a validation process, respectively, see Data Operation.
Dataset Saving
Re-save the dataset to the MindRecord data format, see Data Operation.
Data Transforms
Common Data Transforms
Users can use a variety of data transformation operations:
.map(...)operation: transform samples..filter(...)operation: filter samples..project(...)operation: sort and filter multiple columns..rename(...)operation: rename a specified column..shuffle(...)operation: shuffle data based on the buffer size..skip(...)operation: skip the first n samples of the dataset..take(...)operation: read only the first n samples of the dataset.
The following describes how to use the .map(...).
Use the data transform operation provided by Dataset in
.map(...)Dataset provides a rich list of built-in data transform operations that can be used directly in
.map(...). For details, see the Map Transform Operation.Use custom data transform operations in
.map(...)Dataset also supports user-defined data transform operations. You only need to pass user-defined functions to
.map(...)to return. For details, see Customizing Map Transform Operations.Return the Dict data structure in
.map(...)The dataset also supports the return of the Dict data structure in the user-defined data transform operation, which makes the defined data transform more flexible. For details, see Custom Map Transform Operation Processing Dictionary Object.
Automatic Augmentation
In addition to the preceding common data transform, the dataset also provides an automatic data transform mode, which can automatically perform data transform processing on an image based on a specific policy. For details, see Automatic Augmentation.
Data Batch
Dataset provides the .batch(...) operation, which can easily organize samples after data transform into batches. There are two methods:
The default
.batch(...)operation organizes batch_size samples into data whose shape is (batch_size, …). For details, see the Batch Operation.The customized
.batch(..., per_batch_map, ...)operation allows users to organize multiple [np.ndarray, nd.ndarray, …] data records in batches based on the customized logic. For details, see Customizing Batch Operation.
Dataset Iterator
After defining the dataset loading (xxDataset) -> data processing (.map) -> data batch (.batch) dataset pipeline, you can use the iterator method .create_dict_iterator(...) / .create_tuple_iterator(...) to output data. For details, see Dataset Iteration.
Performance Optimization
Data Processing Performance Optimization
If the performance of the data processing pipeline is insufficient, you can further optimize the performance by referring to Data Processing Performance Optimization to meet end-to-end training performance requirements.
Single-node Data Cache
In addition, in the inference scenario, to achieve ultimate performance, you can use the Single-node Data Cache to cache datasets in the local memory to accelerate dataset reading and preprocessing.
Lightweight Mode
You can directly use the data transform operation to process a piece of data. The return value is the data transform result.
Data transform operations (vision transform, nlp transform, audio transform) can be used directly like calling a common function. Common usage is: first initialize the data transformation object, then call the data transformation operation method, pass in the data to be processed, and finally get the result of the process. For more examples, see Lightweight Data Transformation.
Other Feature
Supporting Python Objects in Dataset Pipeline
Dataset pipeline accepts any Python type as input for some operations(such as user-defined dataset GeneratorDataset, user-defined map augmentation operation, batch(per_batch_map=...). See Supporting Python Objects in Dataset Pipeline.