使能自动混合精度
Linux Ascend GPU 模型训练 中级 高级
![]()
![]()
概述
混合精度训练方法是通过混合使用单精度和半精度数据格式来加速深度神经网络训练的过程,同时保持了单精度训练所能达到的网络精度。混合精度训练能够加速计算过程,同时减少内存使用和存取,并使得在特定的硬件上可以训练更大的模型或batch size。
对于FP16的算子,若给定的数据类型是FP32,MindSpore框架的后端会进行降精度处理。用户可以开启INFO日志,并通过搜索关键字“Reduce precision”查看降精度处理的算子。
计算流程
MindSpore混合精度典型的计算流程如下图所示:
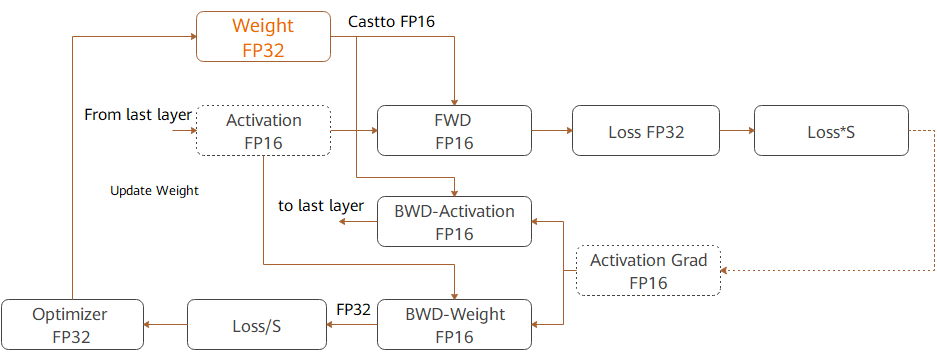
参数以FP32存储;
正向计算过程中,遇到FP16算子,需要把算子输入和参数从FP32 cast成FP16进行计算;
将Loss层设置为FP32进行计算;
反向计算过程中,首先乘以Loss Scale值,避免反向梯度过小而产生下溢;
FP16参数参与梯度计算,其结果将被cast回FP32;
除以Loss scale值,还原被放大的梯度;
判断梯度是否存在溢出,如果溢出则跳过更新,否则优化器以FP32对原始参数进行更新。
本文通过自动混合精度和手动混合精度的样例来讲解计算流程。
自动混合精度
使用自动混合精度,需要调用相应的接口,将待训练网络和优化器作为输入传进去;该接口会将整张网络的算子转换成FP16算子(除BatchNorm算子和Loss涉及到的算子外)。可以使用amp接口和Model接口两种方式实现混合精度。
使用amp接口具体的实现步骤为:
引入MindSpore的混合精度的接口
amp;定义网络:该步骤和普通的网络定义没有区别(无需手动配置某个算子的精度);
使用
amp.build_train_network接口封装网络模型、优化器和损失函数,设置level参数,参考https://www.mindspore.cn/doc/api_python/zh-CN/r1.2/mindspore/mindspore.html#mindspore.build_train_network。在该步骤中,MindSpore会将有需要的算子自动进行类型转换。
代码样例如下:
import numpy as np
import mindspore.nn as nn
from mindspore import Tensor, context
import mindspore.ops as ops
from mindspore.nn import Momentum
# The interface of Auto_mixed precision
from mindspore import amp
context.set_context(mode=context.GRAPH_MODE)
context.set_context(device_target="Ascend")
# Define network
class Net(nn.Cell):
def __init__(self, input_channel, out_channel):
super(Net, self).__init__()
self.dense = nn.Dense(input_channel, out_channel)
self.relu = ops.ReLU()
def construct(self, x):
x = self.dense(x)
x = self.relu(x)
return x
# Initialize network
net = Net(512, 128)
# Define training data, label
predict = Tensor(np.ones([64, 512]).astype(np.float32) * 0.01)
label = Tensor(np.zeros([64, 128]).astype(np.float32))
# Define Loss and Optimizer
loss = nn.SoftmaxCrossEntropyWithLogits()
optimizer = Momentum(params=net.trainable_params(), learning_rate=0.1, momentum=0.9)
train_network = amp.build_train_network(net, optimizer, loss, level="O3", loss_scale_manager=None)
# Run training
output = train_network(predict, label)
使用Model接口具体的实现步骤为:
引入MindSpore的模型训练接口
Model;定义网络:该步骤和普通的网络定义没有区别(无需手动配置某个算子的精度);
创建数据集。该步骤可参考 https://www.mindspore.cn/tutorial/training/zh-CN/r1.2/use/data_preparation.html;
使用
Model接口封装网络模型、优化器和损失函数,设置amp_level参数,参考https://www.mindspore.cn/doc/api_python/zh-CN/r1.2/mindspore/mindspore.html#mindspore.Model。在该步骤中,MindSpore会将有需要的算子自动进行类型转换。
代码样例如下:
import numpy as np
import mindspore.nn as nn
from mindspore.nn.metrics import Accuracy
from mindspore import context, Model
from mindspore.common.initializer import Normal
from src.dataset import create_dataset
context.set_context(mode=context.GRAPH_MODE)
context.set_context(device_target="Ascend")
# Define network
class LeNet5(nn.Cell):
"""
Lenet network
Args:
num_class (int): Number of classes. Default: 10.
num_channel (int): Number of channels. Default: 1.
Returns:
Tensor, output tensor
Examples:
>>> LeNet(num_class=10)
"""
def __init__(self, num_class=10, num_channel=1):
super(LeNet5, self).__init__()
self.conv1 = nn.Conv2d(num_channel, 6, 5, pad_mode='valid')
self.conv2 = nn.Conv2d(6, 16, 5, pad_mode='valid')
self.fc1 = nn.Dense(16 * 5 * 5, 120, weight_init=Normal(0.02))
self.fc2 = nn.Dense(120, 84, weight_init=Normal(0.02))
self.fc3 = nn.Dense(84, num_class, weight_init=Normal(0.02))
self.relu = nn.ReLU()
self.max_pool2d = nn.MaxPool2d(kernel_size=2, stride=2)
self.flatten = nn.Flatten()
def construct(self, x):
x = self.max_pool2d(self.relu(self.conv1(x)))
x = self.max_pool2d(self.relu(self.conv2(x)))
x = self.flatten(x)
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.fc3(x)
return x
# create dataset
ds_train = create_dataset("/dataset/MNIST/train", 32)
# Initialize network
network = LeNet5(10)
# Define Loss and Optimizer
net_loss = nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction="mean")
net_opt = nn.Momentum(network.trainable_params(),learning_rate=0.01, momentum=0.9)
model = Model(network, net_loss, net_opt, metrics={"Accuracy": Accuracy()}, amp_level="O3")
# Run training
model.train(epoch=10, train_dataset=ds_train)
手动混合精度
MindSpore还支持手动混合精度。假定在网络中只有一个Dense Layer要用FP32计算,其他Layer都用FP16计算。混合精度配置以Cell为粒度,Cell默认是FP32类型。
以下是一个手动混合精度的实现步骤:
定义网络:该步骤与自动混合精度中的步骤2类似;
配置混合精度:通过
net.to_float(mstype.float16),把该Cell及其子Cell中所有的算子都配置成FP16;然后,将模型中的dense算子手动配置成FP32;使用TrainOneStepCell封装网络模型和优化器。
代码样例如下:
import numpy as np
import mindspore.nn as nn
from mindspore import dtype as mstype
from mindspore import Tensor, context
import mindspore.ops as ops
from mindspore.nn import WithLossCell, TrainOneStepCell
from mindspore.nn import Momentum
context.set_context(mode=context.GRAPH_MODE)
context.set_context(device_target="Ascend")
# Define network
class Net(nn.Cell):
def __init__(self, input_channel, out_channel):
super(Net, self).__init__()
self.dense = nn.Dense(input_channel, out_channel)
self.relu = ops.ReLU()
def construct(self, x):
x = self.dense(x)
x = self.relu(x)
return x
# Initialize network
net = Net(512, 128)
# Set mixing precision
net.to_float(mstype.float16)
net.dense.to_float(mstype.float32)
# Define training data, label
predict = Tensor(np.ones([64, 512]).astype(np.float32) * 0.01)
label = Tensor(np.zeros([64, 128]).astype(np.float32))
# Define Loss and Optimizer
loss = nn.SoftmaxCrossEntropyWithLogits()
optimizer = Momentum(params=net.trainable_params(), learning_rate=0.1, momentum=0.9)
net_with_loss = WithLossCell(net, loss)
train_network = TrainOneStepCell(net_with_loss, optimizer)
train_network.set_train()
# Run training
output = train_network(predict, label)
约束
使用混合精度时,只能由自动微分功能生成反向网络,不能由用户自定义生成反向网络,否则可能会导致MindSpore产生数据格式不匹配的异常信息。