Using Runtime to Perform Inference (C++)
Windows Linux Android C++ Inference Application Model Loading Data Preparation Intermediate Expert
![]()
Overview
After the model is converted into a .ms model by using the MindSpore Lite model conversion tool, the inference process can be performed in Runtime. For details, see Converting Models for Inference. This tutorial describes how to use the C++ API to perform inference.
To use the MindSpore Lite inference framework, perform the following steps:
Load the model: Read the
.msmodel converted by using the model conversion tool from the file system, import the model by using mindspore::lite::Model::Import, parse the model, and create theModel *. For details, see Converting Models for Inference.Create a configuration context: Create a configuration Context to save some basic configuration parameters required by a session to guide graph build and execution.
Create a session: Create LiteSession and configure the Context obtained in the previous step to the session.
Build the graph: Before performing inference, call the
CompileGraphAPI of LiteSession to build the graph. In the graph build phase, graph partition and operator selection and scheduling are performed, which takes a long time. Therefore, it is recommended that with the LiteSession created each time, one graph be built. In this case, the inference will be performed for multiple times.Input data: Before the graph is exed, data needs to be filled in to the
Input Tensor.Perform inference: Use
RunGraphof the LiteSession to perform model inference.Obtain the output: After the graph execution is complete, you can obtain the inference result by
outputting the tensor.Release the memory: If the MindSpore Lite inference framework is not required, release the created LiteSession and Model.
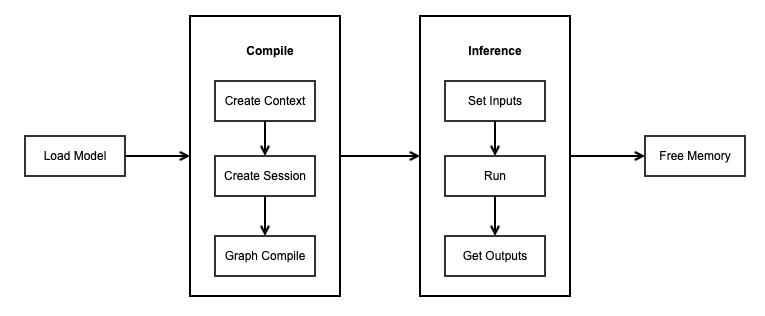
For details about the calling process of MindSpore Lite inference, see Simplified MindSpore Lite C++ Demo.
Loading a Model
When MindSpore Lite is used for model inference, the .ms model file converted by using the model conversion tool needs to be read from the file system and created from the memory data by using the mindspore::lite::Model::Import static function. Model holds model data such as weight data and operator attributes. For details, see Converting Models for Inference.
The Model instance returned by the mindspore::lite::Model::Import function is a pointer created through new. If the instance is not required, release it through delete.
The following sample code from main.cc demonstrates how to read a MindSpore Lite model from the file system and parse the model by using mindspore::lite::Model::Import:
// Read model file.
size_t size = 0;
char *model_buf = ReadFile(model_path, &size);
if (model_buf == nullptr) {
std::cerr << "Read model file failed." << std::endl;
}
// Load the .ms model.
auto model = mindspore::lite::Model::Import(model_buf, size);
delete[](model_buf);
if (model == nullptr) {
std::cerr << "Import model file failed." << std::endl;
}
Creating a Configuration Context
The context saves some basic configuration parameters required by the session to guide graph build and execution. If you use new to create a Context and do not need it any more, use delete to release it. Generally, the Context is released after the LiteSession is created. The parameters contained in Context are defined as follows:
thread_num_: MindSpore Lite has a built-in thread pool shared by processes. During inference,
thread_num_is used to specify the maximum number of threads in the thread pool. The default value is 2.allocator: MindSpore Lite supports dynamic memory allocation and release. If
allocatoris not specified, a defaultallocatoris generated during inference. You can also use the Context method to share the memory allocator in multiple Context. For details about the calling method, see the usage of Sharing a Memory Pool.device_list_: MindSpore Lite supports heterogeneous inference. The backend configuration information for inference is specified by
device_list_in Context. By default, the DeviceContext of the CPU is stored. During graph build, operator selection and scheduling are performed based on the backend configuration information indevice_list_. Currently, only CPU and GPU heterogeneity or CPU and NPU heterogeneity is supported. When the GPU’s DeviceContext is configured, GPU-based inference is preferentially used. When the NPU’s DeviceContext is configured, NPU-based inference is preferentially used.
device_list_[0]must beDeviceContextof the CPU, anddevice_list_[1]must beDeviceContextof the GPU orDeviceContextof the NPU. Currently, the CPU, GPU, and NPU cannot be set at a time.
Configuring the Number of Threads
The following sample code from main.cc demonstrates how to configure the number of threads:
auto context = std::make_shared<mindspore::lite::Context>();
if (context == nullptr) {
std::cerr << "New context failed while running." << std::endl;
}
// Configure the number of worker threads in the thread pool to 2, including the main thread.
context->thread_num_ = 2;
Configuring the CPU Backend
When the backend to be executed is the CPU, device_list_[0] is the DeviceContext of the CPU by default after Context is created. You can directly configure the enable_float16_ and cpu_bind_mode_ attributes in CpuDeviceInfo.
The following sample code from main.cc demonstrates how to create a CPU backend, set the CPU core binding mode to large-core priority, and enable float16 inference:
auto context = std::make_shared<mindspore::lite::Context>();
if (context == nullptr) {
std::cerr << "New context failed while running." << std::endl;
}
// CPU device context has default values.
auto &cpu_device_info = context->device_list_[0].device_info_.cpu_device_info_;
// The large core takes priority in thread and core binding methods. This parameter will work in the BindThread interface. For specific binding effect, see the "Run Graph" section.
cpu_device_info.cpu_bind_mode_ = HIGHER_CPU;
// Use float16 operator as priority.
cpu_device_info.enable_float16_ = true;
Float16 takes effect only when the CPU is of the ARM v8.2 architecture. Other models and x86 platforms that are not supported are automatically rolled back to Float32.
Configuring the GPU Backend
If the backend to be exed is heterogeneous inference based on CPUs and GPUs, you need to set DeviceContext for both CPUs and GPUs. After the configuration, GPU-based inference is preferentially used. GpuDeviceInfo contains the enable_float16_ public attribute, which is used to enable Float16 inference.
The following sample code from main.cc demonstrates how to create the CPU and GPU heterogeneous inference backend and how to enable Float16 inference for the GPU.
auto context = std::make_shared<mindspore::lite::Context>();
if (context == nullptr) {
std::cerr << "CreateSession failed while running." << std::endl;
}
// If GPU device context is set. The preferred backend is GPU, which means, if there is a GPU operator, it will run on the GPU first, otherwise it will run on the CPU.
DeviceContext gpu_device_ctx{DT_GPU, {false}};
// GPU use float16 operator as priority.
gpu_device_ctx.device_info_.gpu_device_info_.enable_float16_ = true;
// The GPU device context needs to be push_back into device_list to work.
context->device_list_.push_back(gpu_device_ctx);
Currently, the backend of GPU is based on OpenCL. GPUs of Mali and Adreno are supported. The OpenCL version is 2.0.
The configuration is as follows:
CL_TARGET_OPENCL_VERSION=200
CL_HPP_TARGET_OPENCL_VERSION=120
CL_HPP_MINIMUM_OPENCL_VERSION=120
Configuring the NPU Backend
When the backend to be exed is heterogeneous inference based on CPUs and GPUs, you need to set the CPU’s and NPU’s DeviceContext. After the configuration, the NPU’s inference is preferentially used. The NpuDeviceInfo contains the public attribute frequency_, which is used to set the NPU’s frequency.
The following sample code from main.cc shows how to create the CPU and NPU heterogeneous inference backend and set the NPU frequency to 3.
auto context = std::make_shared<mindspore::lite::Context>();
if (context == nullptr) {
std::cerr << "CreateSession failed while running." << std::endl;
}
DeviceContext npu_device_ctx{DT_NPU};
npu_device_ctx.device_info_.npu_device_info_.frequency_ = 3;
// The NPU device context needs to be push_back into device_list to work.
context->device_list_.push_back(npu_device_ctx);
Creating a Session
When MindSpore Lite is used for inference, LiteSession is the main entry for inference. You can use LiteSession to build and execute graphs. Use the Context created in the previous step to call the CreateSession method of the LiteSession to create the LiteSession.
The following sample code from main.cc demonstrates how to create a LiteSession:
// Use Context to create Session.
auto session = session::LiteSession::CreateSession(context.get());
// After the LiteSession is created, the Context can be released.
...
if (session == nullptr) {
std::cerr << "CreateSession failed while running." << std::endl;
}
The LiteSession instance returned by the function is a pointer that is created using
new. If the instance is not required, you need to release it usingdelete.After the LiteSession is created, the Context created in the previous step can be released.
Building a Graph
Before executing a graph, call the CompileGraph API of LiteSession to build the graph and parse the Model instance loaded from the file for graph partition and operator selection and scheduling. This takes a long time. Therefore, it is recommended that with the LiteSession created each time, one graph be built. In this case, the inference will be performed for multiple times.
The following sample code from main.cc demonstrates how to call CompileGraph to build a graph.
// Assume we have created a LiteSession instance named session and a Model instance named model before.
auto ret = session->CompileGraph(model);
if (ret != RET_OK) {
std::cerr << "Compile failed while running." << std::endl;
// session and model need to be released by users manually.
...
}
Inputting Data
Before executing a graph, obtain the input MSTensor of the model and copy the input data to the input MSTensor of the model using memcpy. In addition, you can use the Size method of MSTensor to obtain the size of the data to be filled in to the tensor, use the data_type method to obtain the data type of the tensor, and use the MutableData method of MSTensor to obtain the writable pointer.
MindSpore Lite provides two methods to obtain the input tensor of a model.
Use the GetInputsByTensorName method to obtain the tensor connected to the input node from the model input tensor based on the name of the model input tensor. The following sample code from main.cc demonstrates how to call
GetInputsByTensorNameto obtain the input tensor and fill in data.// Pre-processing of input data, convert input data format to NHWC. ... // Assume that the model has only one input tensor named 2031_2030_1_construct_wrapper:x. auto in_tensor = session->GetInputsByTensorName("2031_2030_1_construct_wrapper:x"); if (in_tensor == nullptr) { std::cerr << "Input tensor is nullptr" << std::endl; } auto input_data = in_tensor->MutableData(); if (input_data == nullptr) { std::cerr << "MallocData for inTensor failed." << std::endl; } memcpy(in_data, input_buf, data_size); // Users need to free input_buf.
Use the GetInputs method to directly obtain the vectors of all model input tensors. The following sample code from main.cc demonstrates how to call
GetInputsto obtain the input tensor and fill in data.// Pre-processing of input data, convert input data format to NHWC. ... // Assume we have created a LiteSession instance named session. auto inputs = session->GetInputs(); // Assume that the model has only one input tensor. auto in_tensor = inputs.front(); if (in_tensor == nullptr) { std::cerr << "Input tensor is nullptr" << std::endl; } auto *in_data = in_tensor->MutableData(); if (in_data == nullptr) { std::cerr << "Data of in_tensor is nullptr" << std::endl; } memcpy(in_data, input_buf, data_size); // Users need to free input_buf.
The data layout in the input tensor of the MindSpore Lite model must be
NHWC. For more information about data pre-processing, see Implementing an Image Classification Application (C++).GetInputs and GetInputsByTensorName methods return vectors that do not need to be released by users.
Executing Inference
After a MindSpore Lite session builds a graph, you can call the RunGraph function of LiteSession for model inference.
The following sample code from main.cc demonstrates how to call RunGraph to perform inference.
auto ret = session->RunGraph();
if (ret != mindspore::lite::RET_OK) {
std::cerr << "RunGraph failed" << std::endl;
}
Obtaining Output
After performing inference, MindSpore Lite can obtain the inference result of the model. MindSpore Lite provides three methods to obtain the output MSTensor of a model.
Use the GetOutputsByNodeName method to obtain the vector of the tensor connected to the model output MSTensor based on the name of the model output node. The following sample code from main.cc demonstrates how to call
GetOutputsByNodeNameto obtain the output tensor.// Assume we have created a LiteSession instance named session before. // Assume that model has an output node named Default/head-MobileNetV2Head/Softmax-op204. auto output_vec = session->GetOutputsByNodeName("Default/head-MobileNetV2Head/Softmax-op204"); // Assume that output node named Default/Sigmoid-op204 has only one output tensor. auto out_tensor = output_vec.front(); if (out_tensor == nullptr) { std::cerr << "Output tensor is nullptr" << std::endl; } // Post-processing your result data.
Use the GetOutputByTensorName method to obtain the corresponding model output MSTensor based on the name of the model output tensor. The following sample code from main.cc demonstrates how to call
GetOutputsByTensorNameto obtain the output tensor.// Assume we have created a LiteSession instance named session. // We can use GetOutputTensorNames method to get all name of output tensor of model which is in order. auto tensor_names = session->GetOutputTensorNames(); // Assume we have created a LiteSession instance named session before. // Use output tensor name returned by GetOutputTensorNames as key for (auto tensor_name : tensor_names) { auto out_tensor = session->GetOutputByTensorName(tensor_name); if (out_tensor == nullptr) { std::cerr << "Output tensor is nullptr" << std::endl; } // Post-processing the result data. }
Use the GetOutputs method to directly obtain the names of all model output MSTensor and a map of the MSTensor pointer. The following sample code demonstrates how to call
GetOutputsto obtain the output tensor.// Assume we have created a LiteSession instance named session. auto out_tensors = session->GetOutputs(); for (auto out_tensor : out_tensors) { // Post-processing the result data. }
The vector or map returned by the GetOutputsByNodeName, GetOutputByTensorName, and GetOutputs methods does not need to be released by the user.
Releasing Memory
If the MindSpore Lite inference framework is not required, you need to release the created LiteSession and model. The following sample code from main.cc demonstrates how to release the memory before the program ends.
// Delete model buffer.
// Assume that the variable of Model * is named model.
delete model;
// Delete session buffer.
// Assume that the variable of Session * is named session.
delete session;
Advanced Usage
Optimizing the Memory Size
If the memory is greatly limited, you can call the Free API to reduce the memory usage after the Model is compiled into the CompileGraph by the graph. Once the Free API of a Model is called, the Model cannot build graphs.
The following sample code from main.cc demonstrates how to call the Free API of Model to release MetaGraph to reduce the memory size.
// Compile graph.
auto ret = session->CompileGraph(model);
if (ret != mindspore::lite::RET_OK) {
std::cerr << "Compile failed while running." << std::endl;
}
// Note: when use model->Free(), the model can not be compiled again.
model->Free();
Core Binding Operations
The built-in thread pool of MindSpore Lite supports core binding and unbinding. By calling the BindThread API, you can bind working threads in the thread pool to specified CPU cores for performance analysis. The core binding operation is related to the context specified by the user when the LiteSession is created. The core binding operation sets the affinity between the thread and the CPU based on the core binding policy in the context.
Note that core binding is an affinity operation and may not be bound to a specified CPU core. It may be affected by system scheduling. In addition, after the core binding, you need to perform the unbinding operation after the code is performed.
The following sample code from main.cc demonstrates how to bind the large core first when performing inference.
auto context = std::make_shared<mindspore::lite::Context>();
if (context == nullptr) {
std::cerr << "New context failed while running." << std::endl;
}
// CPU device context has default values.
auto &cpu_device_info = context->device_list_[0].device_info_.cpu_device_info_;
// The large core takes priority in thread and core binding methods. This parameter will work in the BindThread
// interface. For specific binding effect, see the "Run Graph" section.
cpu_device_info.cpu_bind_mode_ = mindspore::lite::HIGHER_CPU;
...
// Assume we have created a LiteSession instance named session.
session->BindThread(true);
auto ret = session->RunGraph();
if (ret != mindspore::lite::RET_OK) {
std::cerr << "RunGraph failed" << std::endl;
}
session->BindThread(false);
There are three options for core binding: HIGHER_CPU, MID_CPU, and NO_BIND.
The rule for determining the core binding mode is based on the frequency of CPU cores instead of the CPU architecture.
HIGHER_CPU: indicates that threads in the thread pool are preferentially bound to the core with the highest frequency. The first thread is bound to the core with the highest frequency, the second thread is bound to the core with the second highest frequency, and so on.
MID_CPU: indicates that threads are bound to cores with the third or fourth highest frequency preferentially, which is determined based on experience. When there are no such cores, threads are bound to cores with the highest frequency.
Resizing the Input Dimension
When MindSpore Lite is used for inference, if the input shape needs to be resized, you can call the Resize API of LiteSession to reset the shape of the input tensor after a session is created and a graph is built.
Some networks do not support variable dimensions. As a result, an error message is displayed and the model exits unexpectedly. For example, the model contains the MatMul operator, one input tensor of the MatMul operator is the weight, and the other input tensor is the input. If a variable dimension API is called, the input tensor does not match the shape of the weight tensor. As a result, the inference fails.
The following sample code from main.cc demonstrates how to perform Resize on the input tensor of MindSpore Lite:
// Assume we have created a LiteSession instance named session.
// Compile graph.
auto ret = session->CompileGraph(model);
if (ret != mindspore::lite::RET_OK) {
std::cerr << "Compile failed while running." << std::endl;
}
...
auto inputs = session->GetInputs();
std::vector<int> resize_shape = {1, 128, 128, 3};
// Assume the model has only one input,resize input shape to [1, 128, 128, 3]
std::vector<std::vector<int>> new_shapes;
new_shapes.push_back(resize_shape);
session->Resize(inputs, new_shapes);
Parallel Sessions
MindSpore Lite supports parallel inference for multiple LiteSession. The thread pool and memory pool of each LiteSession are independent. However, multiple threads cannot call the RunGraph API of a single LiteSession at the same time.
The following sample code from main.cc demonstrates how to infer multiple LiteSession in parallel:
int RunSessionParallel(const char *model_path) {
size_t size = 0;
char *model_buf = ReadFile(model_path, &size);
if (model_buf == nullptr) {
std::cerr << "Read model file failed." << std::endl;
return -1;
}
// Load the .ms model.
auto model = mindspore::lite::Model::Import(model_buf, size);
delete[](model_buf);
if (model == nullptr) {
std::cerr << "Import model file failed." << std::endl;
return -1;
}
// Compile MindSpore Lite model.
auto session1 = CreateSessionAndCompileByModel(model);
if (session1 == nullptr) {
std::cerr << "Create session failed." << std::endl;
return -1;
}
// Compile MindSpore Lite model.
auto session2 = CreateSessionAndCompileByModel(model);
if (session2 == nullptr) {
std::cerr << "Create session failed." << std::endl;
return -1;
}
// Note: when use model->Free(), the model can not be compiled again.
model->Free();
std::thread thread1([&]() {
GetInputsByTensorNameAndSetData(session1);
auto status = session1->RunGraph();
if (status != 0) {
std::cerr << "Inference error " << status << std::endl;
return;
}
std::cout << "Session1 inference success" << std::endl;
});
std::thread thread2([&]() {
GetInputsByTensorNameAndSetData(session2);
auto status = session2->RunGraph();
if (status != 0) {
std::cerr << "Inference error " << status << std::endl;
return;
}
std::cout << "Session2 inference success" << std::endl;
});
thread1.join();
thread2.join();
// Get outputs data.
GetOutputsByNodeName(session1);
GetOutputsByNodeName(session2);
// Delete model buffer.
delete model;
// Delete session buffer.
delete session1;
delete session2;
return 0;
}
MindSpore Lite does not support multi-thread parallel execution of inference for a single LiteSession. Otherwise, the following error information is displayed:
ERROR [mindspore/lite/src/lite_session.cc:297] RunGraph] 10 Not support multi-threading
Calling Back a Model During the Running Process
MindSpore Lite can pass two KernelCallBack function pointers to RunGraph to call back a model for inference. Compared with common graph execution, callback execution can obtain additional information during the running process to help developers analyze performance and debug bugs. Additional information includes:
Name of the running node
Input and output tensors before the current node is inferred
Input and output tensors after the current node is inferred
The following sample code from main.cc demonstrates how to define two callback functions as the pre-callback pointer and post-callback pointer and pass them to the RunGraph API for callback inference.
// Definition of callback function before forwarding operator.
auto before_call_back = [&](const std::vector<mindspore::tensor::MSTensor *> &before_inputs,
const std::vector<mindspore::tensor::MSTensor *> &before_outputs,
const mindspore::CallBackParam &call_param) {
std::cout << "Before forwarding " << call_param.node_name << " " << call_param.node_type << std::endl;
return true;
};
// Definition of callback function after forwarding operator.
auto after_call_back = [&](const std::vector<mindspore::tensor::MSTensor *> &after_inputs,
const std::vector<mindspore::tensor::MSTensor *> &after_outputs,
const mindspore::CallBackParam &call_param) {
std::cout << "After forwarding " << call_param.node_name << " " << call_param.node_type << std::endl;
return true;
};
auto ret = session->RunGraph(before_call_back, after_call_back);
if (ret != mindspore::lite::RET_OK) {
std::cerr << "Inference error " << ret << std::endl;
}
Simplified CreateSession API Invocation Process
Create a LiteSession by invoking the static method CreateSession of the LiteSession based on the created Context and the read model buffer and buffer size. When this API is used to create a session, the model is loaded and the graph is built internally. You do not need to call the Import and CompileGraph APIs again.
The following sample code from main.cc demonstrates how to call the simplified CreateSession API to create a LiteSession.
auto context = std::make_shared<mindspore::lite::Context>();
if (context == nullptr) {
std::cerr << "New context failed while running" << std::endl;
}
// Use model buffer and context to create Session.
auto session = mindspore::session::LiteSession::CreateSession(model_buf, size, context);
if (session == nullptr) {
std::cerr << "CreateSession failed while running" << std::endl;
}
Viewing Logs
If an exception occurs during inference, you can view logs to locate the fault. For the Android platform, use the Logcat command line to view the MindSpore Lite inference log information and use MS_LITE to filter the log information.
logcat -s "MS_LITE"
Obtaining the Version Number
MindSpore Lite provides the Version method to obtain the version number, which is included in the include/version.h header file. You can call this method to obtain the version number of MindSpore Lite.
The following sample code from main.cc demonstrates how to obtain the version number of MindSpore Lite:
#include "include/version.h"
std::string version = mindspore::lite::Version();