PreDiff: Precipitation Nowcasting with Latent Diffusion Models
PreDiff: Precipitation Nowcasting with Latent Diffusion Models
Background
Traditional weather forecasting techniques rely on complex physical models, which are not only computationally expensive but also require deep expertise. However, with the explosive growth of spatiotemporal Earth observation data in the past decade, deep learning has paved a new way for constructing data-driven prediction models. While these models demonstrate great potential in various Earth system forecasting tasks, they still fall short in managing uncertainty and integrating domain-specific prior knowledge, often leading to ambiguous or physically implausible predictions.
To overcome these challenges, Gao Zhihan from the Hong Kong University of Science and Technology implemented the PreDiff model, innovatively proposing a two-stage process specifically for probabilistic spatiotemporal prediction. This process integrates conditional latent diffusion models (LDMs) with an explicit knowledge alignment mechanism, aiming to generate predictions that not only conform to domain-specific physical constraints but also accurately capture spatiotemporal variations. Through this approach, we expect to significantly enhance the accuracy and reliability of Earth system forecasting.
01 Model Introduction
1.1 Diffusion Model
Diffusion models learn data distribution by reversing a predefined noising process that corrupts the original data. The noising process is:
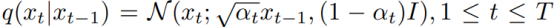
Formula 1
where x_0 ~ p(x) is the real data, x_T ~ N(0,I) is the random noise, and coefficient a_t is a fixed schedule. To apply DM to spatiotemporal prediction, p(x|y) is factorized and parameterized:
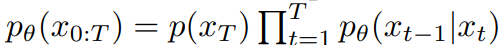
Formula 2
1.2 Conditional Diffusion in Latent Space
To improve the computational efficiency of diffusion model training and inference, PreDiff adopts a two-stage training process, leveraging the advantages of low-dimensional latent space representation. The first stage involves training a frame-wise variational autoencoder (VAE), and the second stage trains a conditional diffusion model to generate predictions in the latent space.
Frame-wise autoencoder: Pixel-wise L2 loss and an adversarial loss are used in training. Perceptual loss is excluded because there are no standard pre-trained models for perceiving Earth observation data. The encoder E is trained to produce latent representations, and the decoder D learns to reconstruct data from the encoded latent space.
Latent diffusion: The training objective of PreDiff is as follows:
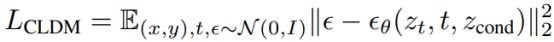
Formula 3
Compared to images, modeling spatiotemporal observation data in precipitation nowcasting is more challenging due to its higher dimensionality. The team replace the UNet in LDM with Earthformer-UNet. Earthformer-UNet adopts the UNet architecture and cuboid attention, removing the cross-attention structure connecting the encoder and decoder in Earthformer.
1.3 Incorporating Knowledge Alignment
Despite the potential of diffusion models in generating diverse and realistic styles, the generated predictions may violate physical constraints or disregard domain-specific expertise, leading to unreasonable results. One possible reason is that diffusion models are not necessarily trained on data adapted to domain knowledge. To address this issue, knowledge alignment is introduced to incorporate auxiliary prior knowledge. Knowledge alignment imposes a constraint on the prediction results. The purpose of knowledge alignment is to suppress the probability of generating violating predictions. However, due to noise in data collection and simulation, even the target values in the training data may violate knowledge alignment.
Knowledge alignment is implemented by training a neural network, starting from the intermediate latent variable z_t. The core lies in adjusting the probability transition matrix in each latent denoising step to reduce the probability that the sampled value z_t violates the constraint.
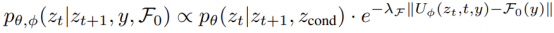
Formula 4
where λ_F is a guidance scaling factor. This training process is independent of LDM training. During inference, knowledge alignment is used as a plug-in module. This modular approach allows training lightweight knowledge alignment networks to impose different constraints without retraining the entire network.
1.4 Inference Process
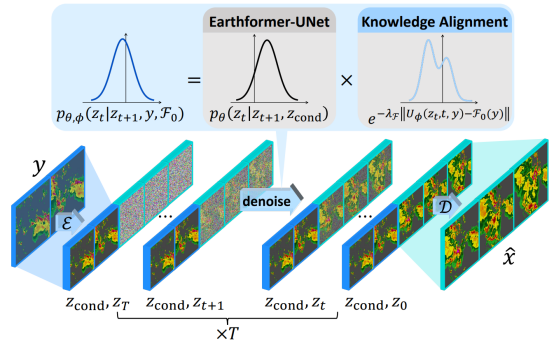
Figure 1 Network architecture
First, an observation sequence y containing multiple time steps is encoded into a latent context z_cond through a frame-wise encoder ℰ. This latent context captures the key information in the observation data, providing necessary guidance for subsequent steps.
Next, using this latent context z_cond, we introduce a latent diffusion model p_θ(z_t|z_t+1, z_cond), where z_t represents the latent variable at time step t. Based on the core neural network of Earthformer, this model constructs a UNet-style architecture to effectively capture long-term complex changes in the data.
In the reverse process of the diffusion model, starting from timestep T (usually the noisiest latent representation), the initial observed latent representation is gradually approached through a series of denoising steps. A key knowledge alignment mechanism is introduced in each denoising step. This mechanism trains a knowledge alignment network A, which can parameterize an energy function. This energy function adjusts the transition probability at each denoising step to ensure that the generated latent state not only conforms to the data distribution but also satisfies domain-specific physical constraints.
Specifically, at each denoising step, we estimate the deviation between the current latent state and the given physical constraints and adjust the transition distribution of the latent variables based on this deviation. In this way, we can suppress latent states that may violate physical laws while encouraging the generation of physically reasonable intermediate latent states.
Finally, when the denoising process is complete, we obtain a latent representation close to the initial observation but containing future prediction information. Through the decoder D, we can transform this latent representation back into the predicted future sequence x. This predicted sequence contains both the key information from the observed data and conforms to domain-specific physical constraints.
02 Results
We evaluate PreDiff on the task of predicting near-term precipitation intensity ("nowcasting") on the SEVIR dataset. We use the expected precipitation intensity as knowledge alignment to simulate possible extreme weather events, such as heavy rain and drought.
We find that knowledge alignment with expected future precipitation intensity can effectively guide the generation while maintaining fidelity and adherence to the true data distribution. For example, the third row in the figure below simulates the development of weather in extreme cases where the future average intensity exceeds μτ + 4στ (with a probability of approximately 0.35%). This simulation is valuable for estimating potential losses in extreme heavy rainfall scenarios.
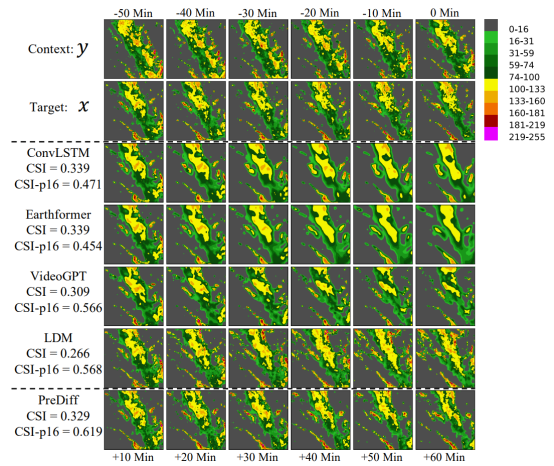
Figure 2 Performance of PreDiff in nowcasting
03 Reflections and Inspirations
By introducing the conditional latent diffusion model and combining it with an explicit knowledge alignment mechanism, PreDiff demonstrates a new approach to integrating data-driven and physical models in Earth system forecasting. This innovation not only emphasizes the importance of data in model training but also improves the physical rationality and accuracy of predictions through the introduction of physical constraints. This inspires us that when dealing with complex system prediction tasks, we should not rely solely on a single data-driven or physical model approach. We should also explore how to organically combine the two, making full use of their respective advantages. At the same time, the implementation of PreDiff also reminds us that the technical route for implementing and embedding differentiable numerical solvers for complex physical processes into AI models for training is one of the important directions for improving prediction accuracy in the future.
References
[1] Gao Z, Shi X, Han B, et al. Prediff: Precipitation nowcasting with latent diffusion models[J]. Advances in Neural Information Processing Systems, 2024, 36.
[2] gaozhihan/PreDiff: [NeurIPS 2023] Official implementation of "PreDiff: Precipitation Near casting with Latent Diffusion Models" (github.com)